Search the Community
Showing results for tags 'parallel'.
Found 3 results
-
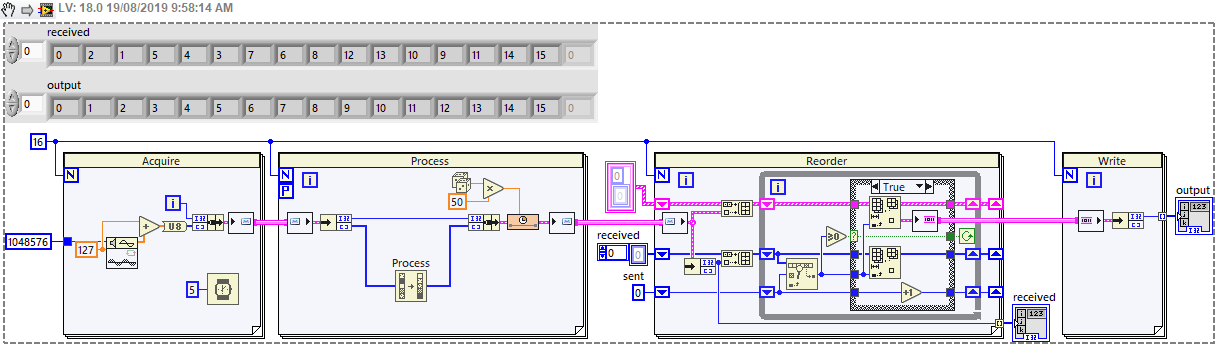
The Parallel For Loop is perfect for parallel processing of an input array, and reassembling the results in the correct order, however this only works if the array is available before the loop starts. There is no equivalent "Parallel While Loop" which might process a data stream - so what is the best architecture for doing this? In my case, I'm streaming image data from a camera via FPGA, acquiring 1MB every ~5ms - call this a "chunk" of data - and I know I will acquire N chunks (N could be 1000 or more). I then want to process (compress) this data before writing to disk. The compression time varies, but is longer than the acquisition time. So I'd like to have a group of tasks which will each take chunks and return the results - however it's no longer guaranteed that the results are in the same order, so there's a bit of housekeeping to handle that. I have a workable architecture using channels, but I'd be interested in any better options. Easiest to explain with a simplified code which mimics the real program: It requires the processing to use a Messenger channel (i.e. Queue) because a Stream channel cannot work in a Parallel For Loop, but this doesn't maintain order. And the reordering is a little messy - perhaps could be tidied using Maps but I don't have 2019 at the moment. The full image is too large to keep in memory (I'm restricted to 32-bit because the acquisition is from an FPGA card), so I need to process and write the data as it becomes available. I've considered writing a separate file for each chunk, but writing millions of small files a day is not particularly efficient or sustainable. Is there a better approach? Have I missed something? I feel like this must be a solved problem, but I haven't come across an equivalent example. Could there be a Parallel Stream Channel which maintains ordering, or a Parallel While Loop which handles a defined number of tasks? Thanks. Greg

-
Hi all, I've been maintaining and improving a LabVIEW project which controls and automates a prototype microscope array for 2 years. I'm an engineering apprentice so I don't have that much experience with LabVIEW. The current framework of the project is a simple "Producer/Consumer" which has served well but is no longer future proof and scalable. I want to revamp the program which is quite big and complex. And I need help since this will be the first time of actually starting a real project from the ground up. The most modular and scalable framework I found was the QMH (Queued Message Handler). It's similar to the basic P/C loop and has the possibility to have multiple parallel consumer loops. But I have no experience on starting from 0. If any you have docs or give advice on starting the project would be appreciated. Especially something on codding with a QMH structure would be helpful. Cheers from France!
-
 Hi, I’m having issues with a LabVIEW application that I made. Quick summary: The application is used for reliability tests. Users can configure profiles/experiments. These are translated to a voltage/current output. Experiments can be started to run parallel on a rack of power supplies. More Details: The application is OO-based. Each active experiment is an ‘experiment executor’ object which is a class with an active object. The process vi is a very simple statemachine which handles init of the hardware (VISA (Powersupplies connected via Ethernet, VISA TCP/IP)), iteration handling of the test, summary logfiles, UI and a few other things. Typical usage of the application is: 16 samples tested in parallel. Most of them run the same experiment (== same output) but on different powersupplies. These samples are tested simultaneously, and started at the same time. System details: LabVIEW2011 SP1 (32bit) // VISA 5.4.1 Observations: In development: I can simultaneously start 16 samples summary file of the experiment settings are written to disk (16times in parallel == 16 samples and all vi’s are set to reentrant) duration is about 10s for each file. (depends on the length of the experiment, different profile steps that are used etc) it is a simple ini format file, about 136KB size Experiments start execution. (== output and measurement on the power supplies) Parallel reentrant VISA communication with power supplies works perfect, internal looprate in the ‘avtive’state of the process is about 500ms (with 16 parallel samples) In runtime: When I start the samples, the parallel processes are started BUT: Writing if the ini summary file gets slower and slower each time a new clone/sample is launched. I see this, because for debug I open the FP of that vi. Writing of the file gets slower and slower… fastest file == 30s, slowest (== last sample started == 250s) Parallel reentrant VISA communication, looprate is 20-30 SECONDS (iso 500msec in development) Can someone help me with this ? 16 parallel process isn ‘t that much. I always thought that runtime would be faster than development env.
Hi, I’m having issues with a LabVIEW application that I made. Quick summary: The application is used for reliability tests. Users can configure profiles/experiments. These are translated to a voltage/current output. Experiments can be started to run parallel on a rack of power supplies. More Details: The application is OO-based. Each active experiment is an ‘experiment executor’ object which is a class with an active object. The process vi is a very simple statemachine which handles init of the hardware (VISA (Powersupplies connected via Ethernet, VISA TCP/IP)), iteration handling of the test, summary logfiles, UI and a few other things. Typical usage of the application is: 16 samples tested in parallel. Most of them run the same experiment (== same output) but on different powersupplies. These samples are tested simultaneously, and started at the same time. System details: LabVIEW2011 SP1 (32bit) // VISA 5.4.1 Observations: In development: I can simultaneously start 16 samples summary file of the experiment settings are written to disk (16times in parallel == 16 samples and all vi’s are set to reentrant) duration is about 10s for each file. (depends on the length of the experiment, different profile steps that are used etc) it is a simple ini format file, about 136KB size Experiments start execution. (== output and measurement on the power supplies) Parallel reentrant VISA communication with power supplies works perfect, internal looprate in the ‘avtive’state of the process is about 500ms (with 16 parallel samples) In runtime: When I start the samples, the parallel processes are started BUT: Writing if the ini summary file gets slower and slower each time a new clone/sample is launched. I see this, because for debug I open the FP of that vi. Writing of the file gets slower and slower… fastest file == 30s, slowest (== last sample started == 250s) Parallel reentrant VISA communication, looprate is 20-30 SECONDS (iso 500msec in development) Can someone help me with this ? 16 parallel process isn ‘t that much. I always thought that runtime would be faster than development env.