Leaderboard

Popular Content
Showing content with the highest reputation on 04/29/2024 in all areas
-
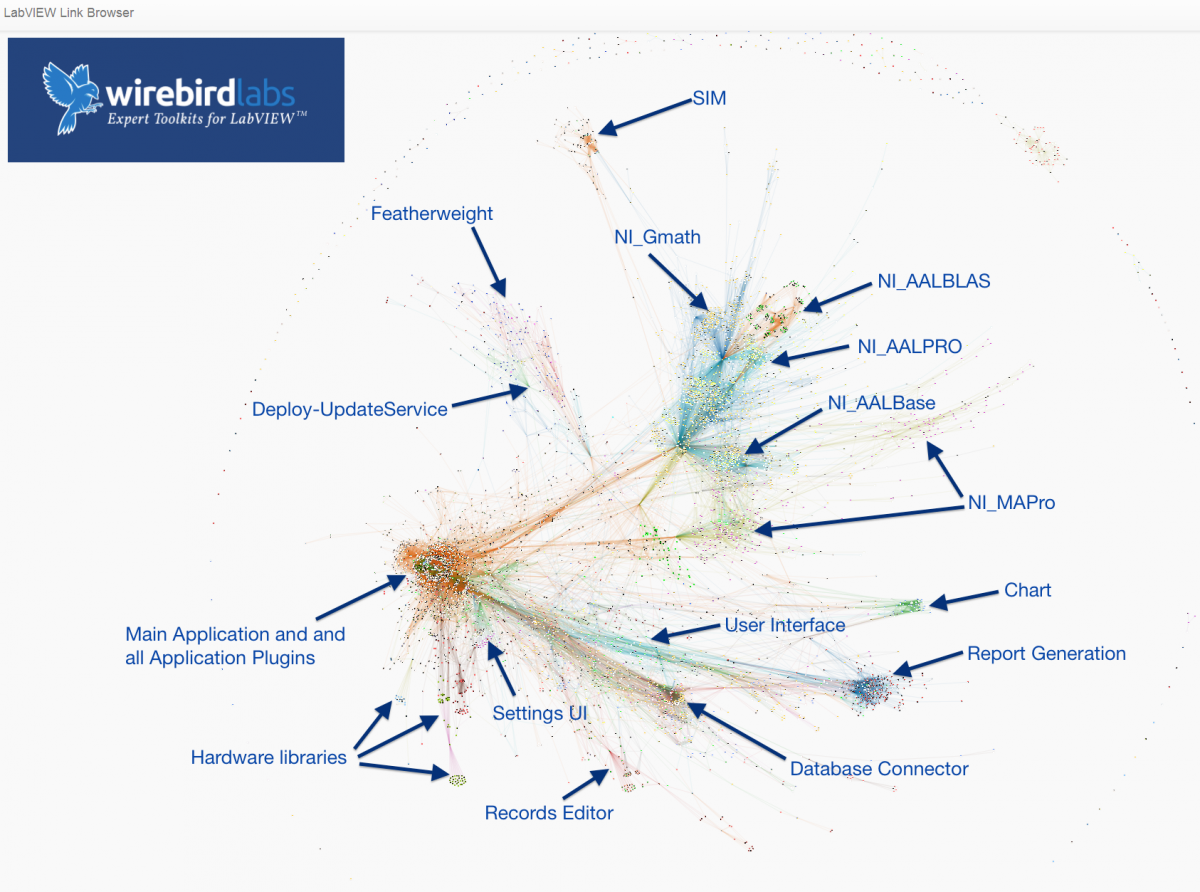
LLBs and LVLibs solve different problems (and create different problems), and are not interchangeable or really related beyond sharing the word "library" in their acronyms. Here are some characteristics and comparisons of the two: LLB provides physical packaging containment of members, and does not address namespacing (nor scoping). LVLIB provides namespace containment of members (and also scoping), and does not address physical packaging. Both LLB and LVLIB impose static linkages that can be incidental and undesirable. These negatively affect load times (IDE and run-time), build times, and compile times. Anecdotally, it's greater than O(n) time complexity, especially when circular linkages exist between multiple such hierarchies, and most especially if the library hierarchy is nested (e.g., LVCLASS within an LVLIB, or nested LVLIBs) An LVLIB can be built into an LVLIBP. An LVLIBP is different from an LLB in that an LLB packs writeable, cross-platform* VIs capable of mutating to future LabVIEW versions, while an LVLIBP is a read-only, platform- and version-specific byte code distributable (which may contain the block diagram for debugging, except still remaining platform- and version-specific). An LLB may be used to pack libraries/plugins for deployment as application plugins, or as reusable libraries in development. An LVLIBP effectively is only used for the former. Neither LVLIBP nor LLB can pack non-LabVIEW-source filetypes as resources. Be mindful to account for both renaming/name-mangling resources, and also changes in relative path. LVLIBs (and LVLIBPs) render nicely in the LVProj tree, while LLB members appear indistinguishable from POVIs (plain ol' VIs). LLBs cannot pack two VIs of the same filename. This prevents packaging multiple LVCLASS hierarchies that use dynamic dispatch methods. This represents a few LabVIEW design limitations: 1) LLB's lack of an internal directory hierarchy for organization and packing of two filenames, and 2) LVCLASS using OS filename as the only unique identifier for method identification in a class (filename represents a good default value, but we need one more degree of indirection as a field within the LVClass XML; it's another discussion why this is so highly desirable to decouple source from OS convention). For actively-developed libraries, LLBs are bad because they exist a monolithic binary file. LVLIBs are bad because there exists no diffing or merging capabilities (this also applies to LVPROJ, LVCLASS, XCTL, XNODE filetypes. This is especially insidious, because popular DVCS clients autodetect the file format as XML and think "Aw yeah dude, I got this!" MERGE FAIL. Corrupted source. Be sure to turn off this autodetection for these filetypes.) LVLIBs can apply icon overlays to members. LVLIBs may be carefully designed to include strategic static linkages, including non-LabVIEW source files. This is one strategy to avoid managing the "Always Include" section of AppBuilder for distributables, especially as a convenience for end-user-developers of re-use libraries. But this fails by default because of the setting "Remove unused members of project libraries". Unchecking that often causes failure to build for non-trivial-sized applications linking to gargantuan LVLIBs shipping in vi.lib and as add-ons. So, the strategy may or may not work (it's coupled to whether or not you're keenly aware of and properly managing all application static dependencies) The reason I want to like LLBs is their ability to provide packaging constructs that provide higher performance on actual hardware. It's faster to load 1 file of size 100 units than 100 files of size 1 unit. It's also a more convenient distribution format -- a single file. (Also, I can't think of another language that effectively enforces a 1:1 relationship between method and physical file. LabVIEW requires substantially more clerical work to develop and refactor, for this reason) The reason I want to like LVLIBs is to enable namespacing and scoping beyond the LVCLASS level. Though, this namespacing always comes with the cost of static linking, which is perhaps the #1 problem for codebases of non-trivial size (do you see busy cursors while editing and wiring? long build times? load times? type prop errors? corruptions from application refactoring? heartache and heartburn generally?) Also, LVLIBP is neat in practice, but so narrowly scoped to specific deployment scenarios where it's acceptable to target version- and platform-specfic targets (version-specificity is definitely the bigger problem. every 12mo, we are afforded the opportunity to choose between obsolecense/migration/revalidation or just-plain-outdatedness). And without arbitrary namespace composition (namespace B and namespace C may both declare using namespace A; with namespace A unaware and none-the-wiser), it's not necessarily a compelling feature to begin with. (Corollary: an LVCLASS's ability to namespace and scope its members is desirable and good; but it becomes less necessary and more-likely-incorrect to continue namespacing and scoping at higher abstraction levels without namespace composition) Do LVLIBs Scale? Using LVLIBs in source on an actively-developed project raises barriers to both team scale and application scale. The cost of not using them is loss of scoping, which is avoided through communication and convention, and easily-detected if any actual problem were to exist. Another cost is loss of namespace, easily avoided through filenaming conventions (which is incidentally an industry standard on the web; prefixing library APIs with library-specific prefixes to avoid collision). Said another way, ROI diminishes and reverses to negative at scale, and opportunity cost has simple workarounds. I choose the opportunity cost. But... LVLIBPs! Another apparent opportunity cost of avoiding LVLIB in source is the inability to have LVLIBP as a distributable. Though, if you treat build/distribution as a second toolchain from the dev toolchain, the dev source can remain unencumbered by LVLIB, which is only added as part of the build process. I have mixed feelings on ROI here, but if LVLIBP makes sense for you, consider this strategy to make your dev experience noticeably more pleasant. Here's a real-world case study. This is from a Wirebird Labs client who gave permission to release this screenshot of a bird's eye view of their application analyzed using Links. What we're looking at in the screenshot below is an application with over 8000 application VIs (not including third-party dependencies). Libraries are identified by labels. Nodes represent a source file (mostly VIs, but also including LVLIB and LVCLASS and CTL), and connections between nodes represent static links as detected by the LabVIEW linker. This is a static screenshot of the application, but while running the physics engine lays out nodes as a force diagram. The strength of the force is based on number of static links existing between nodes, and a negative force is applied to nodes with no static links. This causes nodes to form clusters in space where strong coupling exists. What is the value of analyzing the application like this? Here is a list of issues we needed to solve: It took a long time to build. This made iterating costly, both in time and morale. Oftentimes, the build failed (anecdotally, a fresh warm boot of LabVIEW helped) The IDE was painfully slow during development; the cursor continually was "waiting" during wiring operations. The way we solved both problem was simply by taking a pair of "scissors" and snipping links between nodes. The types of links that we snipped were these incidental links introduced by packaging and namespacing facilities in LabVIEW: removing LVLIBs altogether removing VIs from LLBs calling concrete instances of polymorphic VIs rather than the parent removing public type definitions and utility VIs from LVCLASSes Within a couple days, we went from "kick off a build and go grab lunch" to "kick it off and get a coffee". The application and application framework had not changed to see these improvements; just the logical and physical packaging of dependencies. (In addition to solving the main performance pain points, additional areas for architectural consideration are easily visualized; that's beyond the scope of this conversation) Without LVLIBs, how do I avoid name collisions? I prefer this filenaming convention: Project-Class-Method.vi or Application-Class-Resource-Action.vi ... or generally, LeastSpecificNamespace-...-SpecificThing-...-VerbActingOnASpecificThing.vi For instance, Deploy-UpdateService-CheckForUpdates.vi or FTW-JSON-Deserialize.xnode. The name of the owning class just drops the -Method postfix. Is it ideal? It's neither terrible nor great. Some benefits are that filenames sort nicely, and it's easy to spot anomalous linkages. Semantic naming makes it easier for development tools outside the IDE (SCC client and provider, build toolchains). One downside is that your hand is forced on naming Dynamic Dispatch methods in classes (again, I desire to see this coupling separated by a degree of indirection in future LabVIEW versions). Conclusion? This area of LabVIEW does not have a general solution or general best practice. Be aware of tradeoffs of different strategies, and ensure they map successfully to your application space, stakeholder's needs, and team's sanity. Standing offer: Send me a message if you feel some of the scaling pain points: busy cursor while wiring build times lasting longer than 10min mass compile times lasting longer than 10min LVProj takes longer than 1min to load and within 2hrs of screensharing I reckon we could substantially improve your LV dev experience. I'm interested to further build tribal knowledge and provide feedback to NI on taking LabVIEW applications and teams to scale.
 1 point
1 point