

mje
-
Posts
1,068 -
Joined
-
Last visited
-
Days Won
48
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by mje
-
-
Yeah, the LV XML parser actually uses the Xerces DOM implementation. I'm going for more of a SAX style, and I'm evaluating whether or not you can even use Xerces SAX in LabVIEW...I've only ever played with it in C++, but that was long ago and I abandoned it before completion in favor of something else. From what I remember, the Xerces SAX event model requires you to derive from an exported class to receive event notification (opposed to registering callback functions or delegates), though I could be wrong.
As for the JKI toolkit, we own it, but I don't think it has quite what we need.
Ultimately, I'm siding on still using the .NET XmlReader and doing the data serialization via a C# assembly, which will expose a few methods to allow me to get the data back in LabVIEW. The XmlReader is really quite elegant, and much easier to use than an old-school SAX implementation.
-michael
-
Thanks, Brian, that's some great information.
Ultimately, I think what will doom this application from being coded in LV is my requirement to keep the memory footprint inline. Balooning out to several hundred megabytes to load a huge XML file isn't an option. Hence the XmlReader, which allows very frugal use of memory, but at the expense of many iterative calls. The overhead in those calls adds up I imagine, to the point where using LV just isn't practical.
This shouldn't be too much of a problem, I can easily work in C# to get the main serialization done. It's actually my preference, I find LV code with excessive amounts of property/invoke nodes rather "clunky" when looking at the block diagram.
Quick question though since many of you seem to have the .NET experience in LV that I lack. As long I keep my data in the form of arrays of primitives, data moving across the application boundaries shouldn't be too much of an issue, just a simple* copy, correct?
*And by "simple" I mean a "painful" copy of a few hundred megabytes...
Thanks everyone for the input!
-Michael
-
QUOTE (jlokanis @ Aug 20 2008, 02:11 AM)
LabVIEW is wildly more inefficient when calling .NET functions than C#...I do know to never make a large number of calls to .NET functions in a loop in LabVIEW...I'm beginning to realize this. Simply moving the XmlNodeType.Element read outside the loop reduces execution time by four seconds (!). That's a read of a simple enum constant.
My limited experience with .NET in LV (this single application) has left a sour taste in my mouth. Yes, LV can use .NET, but I'd hardly call it acceptable performance for anything but the most basic functionality. NI's implementation is rather disappointing, regardless of reasons. I'm going to hunt down that blog though.
-michael
-
QUOTE (Ton @ Aug 19 2008, 01:17 PM)
Well, the XML data is from disk. Save for a few kilobytes of header information, the entire XML file is read via a re-used string buffer allocated in LV (technically, a U16 array since .NET uses wide characters instead of multibyte characters). I've tracked the problem down by literally removing all processing:
http://lavag.org/old_files/monthly_08_2008/post-11742-1219171064.png' target="_blank">
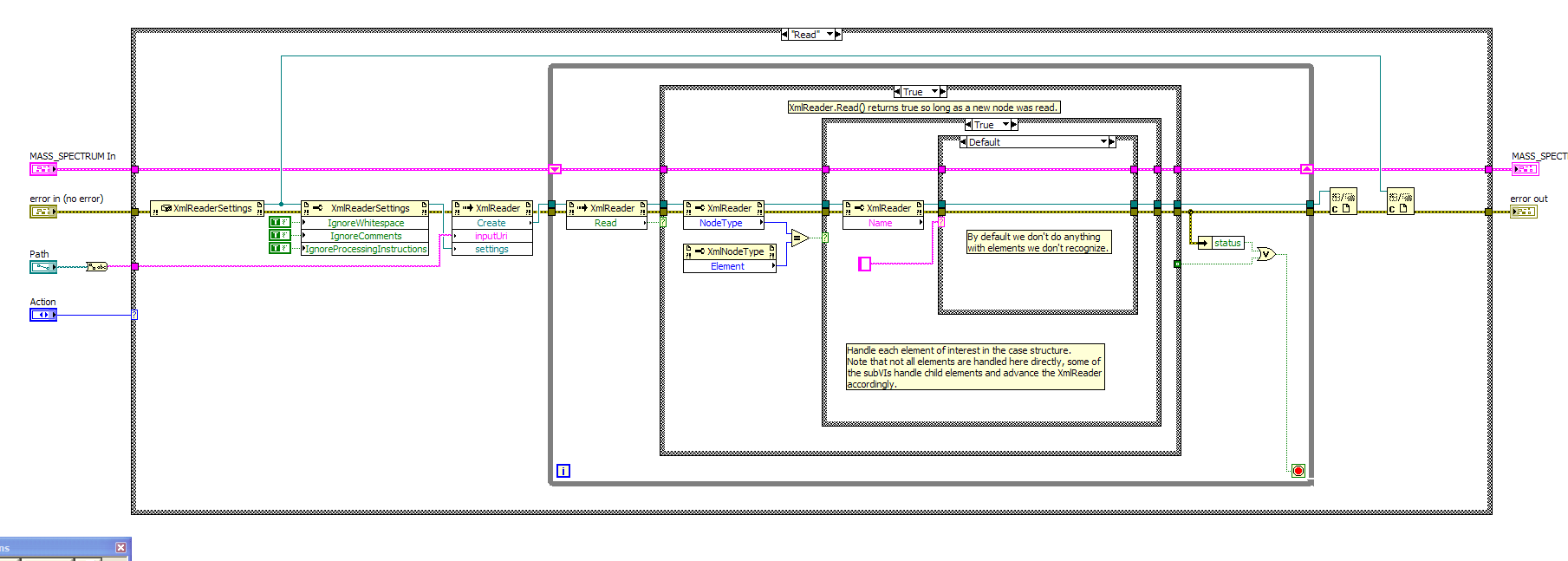
All this VI does is iterate over every element in the XML file and literally does nothing with it. It takes around 37 seconds to execute on my system. The XML structure is pretty simple. Save for a kilobyte or two of header data contained in maybe a few dozen nodes, most of the file is "flat", just a whitespace delimited list of numbers contained within a "data" node (yes, I know it's a not a good use of XML and a terrible waste of space, but it's not my data format).
I'm going to whip up a .NET binary to see if it takes the same time to do "nothing". I should hope that .NET isn't pre-fetching the file, the whole point of using the XmlReader class is to use buffered reading methods such as ReadValueChunk to avoid using strings hundreds of megabytes in size.
Something's fishy. The attached C# code is functionally equivalent to the LV code posted above and executes in under a second.
using System; using System.Xml; namespace XmlTestReader { class Program { static void Main(string[] args) { if (args.Length < 1) { Console.WriteLine("Please provide an input file as a command line argument."); return; } DateTime start_time = DateTime.Now; XmlReaderSettings rs = new XmlReaderSettings(); rs.IgnoreWhitespace = true; rs.IgnoreComments = true; rs.IgnoreProcessingInstructions = true; XmlReader r = XmlReader.Create(args[0], rs); while (r.Read()) { if (r.NodeType == XmlNodeType.Element) { String name = r.Name; } } DateTime end_time = DateTime.Now; Console.WriteLine(String.Format("Elapsed Time: {0}", end_time - start_time)); } } }Conclusion: it's not the .NET implementation.
-
Quick question with regards to profiling metrics and .NET interop for LV. The short of it is, where does time spent outside of the LV process show up when using the profile tools in the LV development environment?
I have a VI proof of concept I'm working on, this is the first time I've used .NET in LabVIEW. I'm serializing some pretty hefty XML data. When I profile the current concept, I get a run time on the order of 40 seconds for a moderate sized XML file (150 MB), yet the SubVI time only registered as 1.5 seconds, see below:
Profile Data: all times in milliseconds, memory usage in kilobytes. Begin: Tue, Aug 19, 2008 11:19:16 AM. End: Tue, Aug 19, 2008 11:20:08 AM. VI Time Sub VIs Time Total Time # Runs Spectrum XML.vi 37125.0 1500.0 38625.0 1 LE_DATA Parse and Append.vi 937.5 250.0 1187.5 579 Spectrum XML Read - LE_DATA.vi 265.6 1187.5 1453.1 1 Trim Whitespace.vi 218.8 0.0 218.8 87144 LE_DATA Resize.vi 31.2 0.0 31.2 176 Spectrum XML Read - APEX3D.vi 15.6 0.0 15.6 1 Spectrum XML Read - FORMAT.vi 15.6 0.0 15.6 2 Spectrum XML Read - PARAMS.vi 15.6 0.0 15.6 1 Build Error Cluster__ogtk.vi 0.0 0.0 0.0 0 Spectrum XML Read - MASS_SPECTRUM.vi 0.0 0.0 0.0 1 Spectrum XML Read - PROCESSING_PARAMETERS.vi 0.0 0.0 0.0 1 Wide String to String.vi 0.0 0.0 0.0 579
The main VI (Spectrum XML.vi) is most definitely not using the processing time shown in the profile, it's job is simply to call a few SubVIs. I'm wondering if all the .NET time is put into the main VI's entry since it is the one that created the original .NET reference that is passed to all subVIs, and it's that object that creates any new instances of .NET objects? Anyone seen this type of behaviour before? I'm considering redoing the little project in C# just to compare performance, to see if the performance hit is coming from the .NET/LV communication.
I'm still working with 8.5, haven't gotten around to 8.5.1 let alone the 8.6 disks yet...
Regards,
-Michael
-
It's a waveform data serialization VI, you'll find it in the Waveform :: Waveform File I/O palette. The code below illustrates your problem, it will generate five newline sequences in the file specified. Note I'm supplying no waveform data to the VI.
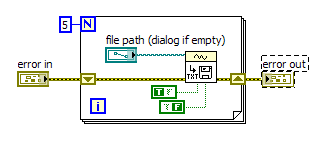
What happens in your example is your read VI is returning however many samples are ready in your input buffer, which could be zero if you read too fast (this is because of the -1 value supplied to Number of Samples per Channel) . The VI will happily return an empty waveform when the buffer is empty, and in response to this, the serialization VI will write a blank line to disk.
You can mitigate this by requiring the loop to obtain a certain number of samples, checking for an empty waveform, retrieving only the number of samples in the buffer, or whatever works best for your situation.
-michael
-
I'd expect that mac's have gone to the 80bit standard as well now that they're Intel, but it's no more than a hunch.
Easiest way to find out would be watch the memory footprint of a VI increase as you make a large array of EXT numbers on a mac system. I don't have one handy to test though...
-
QUOTE (mballa @ Aug 6 2008, 06:08 PM)
Wow, thanks, mballa. That does exactly what I want. It's way more involved than I'd have ever imagined it being!
-
Yeah, if they do end up opening up TLDs as is being discussed, the filter will need to change. As it is I was too lazy to look up all the valid current TLDs, let alone what the proposed restrictions for the open TLDs will be.
I've only ever implemented email validation in web scripting, and never bothered actually testing the existence of the email server via ping or look-up, since ultimately, if the email fails to get delivered, it's all the same (null) result, regardless if it was a non existing server, a non-existing daemon, or a non-existing user.
-
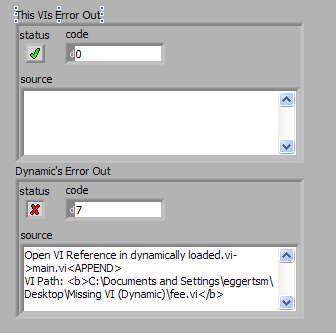
Ah, I better understand the problem. So they dynamically loaded VI is failing to load a subVI. Is that subVI by chance also dynamically loaded? Forgive me if I'm running through the obvious, but one thing I've noticed, see the diagram/panel below:

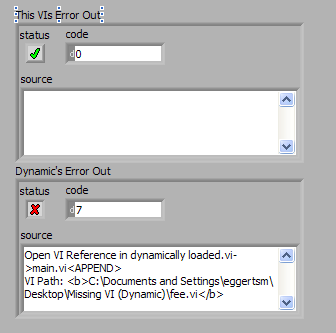
If the reference to the dynamically loaded VI is successfully found, no error is returned through the reference and call by reference call chain. It will be the responsibility of the called VI to pass on any errors, including failure to load, and it tells me what failed to load. I suppose you don't have the ability to check the error state of the called VI?
-
I guess I'm a little lost as to the question. By saying you're dynamically calling a VI, I'm assuming you mean calling it by reference, which there are multiple ways of doing. Some code showing how you're loading would help clear the situation up.
A few stabs in the dark:
Are you referring to VIs that load when you're in the development environment, but not when compiled and using the runtime? If so, and you're using a relative path to obtain a reference to the VI, keep in mind there's an extra path level for VIs when in the runtime environment (something located at ../foo.vi during development becomes ../../foo.vi in the runtime). The other possibility is if you're not using a strict reference to the VI, the compiler won't know to include the VI (or any of it's subVIs) into the final application since you never directly reference it. You'll need to specify in the build options to include the VI, at which point the compiler should include it and all its subVIs (except of course, other non-strictly referenced VIs).
-
Hehe, I've been burned by stuff like that. In general, one shouldn't obtain a reference (to anything) inside a loop, especially if that reference isn't closed on the same iteration.
-
I've always disliked how LabVIEW never had an equivalent to the break command in a for loop (or a continue for that matter), and when I heard they added the conditional for loop in 8.5 I was impressed. Your article pretty much summed up how it was done before, with the good old shift register and case structure combination, and gave a good example of how the same thing can be done now.
Granted, the use of such a conditional for loop may run contrary to many design paradigms in LabVIEW, especially for the auto-indexed nodes as already mentioned, but I always found the alternative work-arounds to be messy and franky, I'm surprised NI took so long to implement such a construct that is so common in most (if not all?) text languages.
-
Neat, I completely overlooked those VIs. That could definitely do the job. Thanks, Mikael.
I still haven't found a way to receive the actual events though. I'm starting to think it's a general issue with how the operating system windowing model works, I'm not even sure if LabVIEW is sent the events by the OS if the cursor isn't over the window.
-
I have an application that uses pairs mouse down/up events to control some external hardware. It works great, on a down event a start command is sent, and a stop command is sent when the mouse button is let go. The problem is if the up event is only received if the mouse button is released while the cursor is over the client area of the window. Is it possible to have LabVIEW capture the event if the cursor is outside the client area (say over the window border, or entirely outside of the window)?
It turns out that in this particular case I could do a work around by using value change events instead, but that might not always be possible so I'm wondering if there's any way of addressing the problem by continuing to use the up/down events?
Regards,
-michael

Tip strip
in User Interface
Posted
As the others have mentioned, there are ways of implementing your own from within LV. As Aristos mentioned, it's not really that much of a hack...tooltips themselves are just another window that gets shown and moved around as necessary.
The main reason you won't be able to control it from the OS level is most controls don't actually derive from a Windows window (that is a the window class defined by the Windows OS) if I recall. Since they're not a "real" window, they won't have an hWnd, there won't be a native tool tip class to display, let alone the inability to actually post the corresponding message to the window (TTM_ACTIVATE) or call whatever .NET voodoo would do the same.
Now, if you're talking about an ActiveX window, or something that actually has an hWnd, there might be a slim chance of wrangling up some code...