

Mark Smith
-
Posts
330 -
Joined
-
Last visited
-
Days Won
5
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Mark Smith
-
-
I avoid this problem by not including my installers or exe's in the source code repository. If you version the project (which includes all the build info for the exe/installer) then you should be able to rebuild that version of the exe/installer any time you need one. With that said, I still move my released installers to another directory, zip them up with version numbers in the file names, and then commit them. This insures I can quickly supply a new installer to a customer and avoids the hassles you have encountered.
I do think this is a common problem - I've learned not to include any of the auto-generated stuff (all of the debug databases, object code, support files, etc) from my VS projects, either. If I did want to keep certain items, one way around this in VS is to include a post-build script that copies the files to a location where the compiler or install build won't touch them, and then version control that folder.
Also, not including installers really helps my commit/update times when I'm at a remote site and on a slow connection!
Mark
-
QUOTE (Tim Erickson @ Jan 8 2009, 02:31 PM)
http://technet.microsoft.com/en-us/sysinte...s/bb896653.aspx
and get the Process Explorer app - you can get detailed info on any process on your system including memory usage.
-
John,
I agree with jdunham - use named queues and notifiers. The overhead of getting/releasing references hasn't caused any problems for me (as long as I remember to close the ref nums - on a long running app you can leak a lot of memory a few bytes at a time
 ). I contributed some thoughts on this thread about why I like named queues. -they can really make your code very modular.
). I contributed some thoughts on this thread about why I like named queues. -they can really make your code very modular.http://forums.lavag.org/VI-communication-b...&hl=mesmith
Mark
-
John,
It's been a while since I've used ADO.NET (and then I used it in a .NET application) but it performed seamlessly when connecting to a SQLServer database. Indeed, ADO.NET and SQLServer are both MS's latest technology and are behind a whole bunch of data-driven applications that seem to perform well. I don't know what the current development cycle is on ADO (the ActiveX one) but I doubt that it gets a whole lot of attention from MS these days - for example, this page
http://support.microsoft.com/kb/183606
is almost two years old now and it looks like one of the latest MS support pages for ADO.
But I think you seem to have narrowed down your problem to LabVIEW/.NET overhead, which I find reasonable given my experience. I don't think the .NET interface gets the attention from NI anymore that it used to now that Brian T's not there (I would be happy to be wrong about this!). But I have successfully solved similar problems by defining exactly what I expect .NET to do for me and using the most loosely coupled interface possible. This almost always requires writing a .NET DLL to reduce the calls to/from LabVIEW. In this case, I don't think I would access the ADO.NET namespace from LabVIEW, what I would do is just use some structure to pass the data to/from a method defined by my DLL that then uses all of the .NET magic to write to and read from the database and reduce the LabVIEW/.NET interaction to an absolute minimum.
I also used (years ago!) Jeffrey Travis' LabSQL and it worked as advertised - they are wrappers around the ADO ActiveX objects so this would save you a lot of time since he's already exposed LabVIEW interfaces. You could create some quick and dirty tests and maybe decide if this would increase the performance of your app.
Lastly, there's NI's Database Connectivity Toolkit. I don't have any experience with it or have any idea what's under the hood.
Mark
-
QUOTE (Jeff @ Dec 19 2008, 04:39 PM)
Is it possible to dynamically recast a parent object to a child object? Here's what I am trying to do: I am testing two types of parts, call them Part A and Part B. I have a "Part A" class and "Part B" class, each of which inherit from a "Part" class. I create a "Part" object, and call its method to get the part's serial number (the procedure is the same for all part types). Once I know its serial number, I can determine which type of part it is. So at this point, I want to cast my "Part" object to a (say) "Part A" object.From all the examples I have seen, you have to create your object with the create method from whatever class you are trying to create, and it forever stays that class (even if sometimes it is represented by the wire type of a parent class--in this case you can use the "To More Specific Class" primitive to get the wire of the class that was created).
I think this recasting could be theoretically done using LVOOP with a VI that creates a new child object, copies the data from the input parent object to the new child object, and sends the child object out via a parent object terminal; but the compiler doesn't allow this. I'm not really sure how I would go about this using GOOP (I'm using GOOP Developer Suite 3). I see that there is a function for "cast to more specific" in the GOOP Kernel VI, but I'm not sure how to use it (if it should be used).
The fact that this is forbidden by the LV compiler (for LVOOP) leads me to believe that there is a good reason to not do what I am trying to do. Does anyone have any suggestions on how to do it, or some better implementation? Thanks.
The reason you can't cast a parent object to a child is because there's no way for the parent object to be created with all of the methods/properties any of its children may have. So, if you were to cast the parent object to the child and then call some method specific to the child (or try to access some property) it simply would not exist. That's not true of casting a child to a parent where you can always be sure the properties/methods of the parent do exist in the child. So in this case, it sounds like an approach would be to find the type of the parent and then just instantiate a child object of the correct type with the given S/N and then discard the parent (it did its job of carrying the S/N info).
Mark
-
QUOTE (Val Brown @ Dec 18 2008, 01:25 PM)
Part of my frustration is over the continuing "by-ref" vs "by-value" discussions and the implications that, unless one uses OOP etc, then one isn't a "real" programmer. BUt the essence of my frustration is with how NI has, IMO, gone off mission in dropping over the years true cross-platform development in favor of a Windows-centric approach that again, IMO, takes them off mission in additional ways.Where I work one isn't a real programmer unless they do embedded development in C or VHDL! So every community has its bias. But I do fail to see where the OOP push in LabVIEW makes it less cross-platform compatible - is the LabVIEW OOP implementation (the native one) not supported on Mac and/or Linux?
Mark
-
QUOTE (shoneill @ Dec 18 2008, 10:17 AM)
I'm no OOP guru, but how will implementing by-ref LVOOP lead to portable code?...Here, I just meant that if the by-ref implementation were part of native LabVIEW, if you tried to use a class that used by-ref, you wouldn't have to worry about which third-party toolkit was being used and whether or not you had it installed. And you wouldn't have to try to figure out some hacker's (like mine
 ) home-grown implementation.
) home-grown implementation.Mark
-
Like Ben, I have created my own "by-reference" functionality in LabVOOP since I found places where I really needed it - and I agree with Val that all of these versions make it more difficult to make portable code with OOP in LabVIEW. That's why I'm hoping that the next release of LabVIEW will support by-ref objects in LabVOOP. Then we'll have a complete and portable version.
Mark
QUOTE (Val Brown @ Dec 18 2008, 08:47 AM)
QUOTE (neB @ Dec 18 2008, 08:04 AM)
...the "by-reference issue" (not built-in) is a non-issue for me since I just implemented my own version in LVOOP.Ben -
I learned how to do OOP using .NET (C# and C++/CLI) where all of the objects are passed by reference - and most everything is an object! I was an experienced LabVIEW developer when I started using .NET, so I was used to dataflow. The first time I passed in an object reference, copied that object into a new object, performed some operation on the new object, returned the new object from the function (or I thought it was a new object!), and saw my orginal object had been modified, I was surprised to say the least. I quickly learned what "deep copy" means in a by-reference context! With that said, once I learned how to properly handle objects in a by-reference context, I found this to be a powerful programming paradigm. Now, when I try to use the by-value objects in LabVOOP (native labview OOP tools), I feel like I'm fighting with one hand tied behind my back. But this may only be because to use by-value objects properly would probably require me to re-learn some design patterns and techniques. But I think my important point is that if you are a LabVIEW only developer, then it might make sense to learn the proper LabVOOP by-value techniques and patterns. Otherwise, I would choose one of the by-reference toolkits because what you learn there is more directly applicable to almost any other OOP development environment.
But, I'm using LabVOOP right now on a project because I think it's important to learn how this toolkit works. In this project, I see a good use for inheritance so LabVOOP may prove its worth. I used the orginal Endevo toolkit (the one for LV6) on a previous project a few years ago and I did find it worked as advertised, but my opinion was that it's a lot of extra effort - and this version did not support any kind of inheritance. I'm counting on (hoping for?) NI to offer the option of by-reference objects in the next version of LV.
Mark
QUOTE (Val Brown @ Dec 17 2008, 10:58 PM)
So, in a sense, it's like using componentized code from MS, eg COM object and ActiveX. You can use them but not edit them.OK far enough but what really then is the difference?
-
QUOTE (jenssona @ Dec 10 2008, 07:18 AM)
I have an exe of a VI that we use to test air handling products at my work. Once a test is sucessfully completed, the VI prints 3 labels to a label printer. This all works fine. Recently, I tried adding an SMTP e-mail procedure to e-mail me this label (in an .xls file format) - this works, but also e-mail me a PDF of one of the graphs (all data gets sent to a blackberry phone as well, and that cannot open an .xls file formatted graph, the data is fine, but the graphs won't display). In the VI, using the "Print Report.vi" command, a pop-up will come up and ask me where I'd like to save my PDF, and this all works fine - it will e-mail me this file as well. BUT the pop-up never happens in the exe and the program gets an error when it trys to e--mail me this PDF file that doesn't exist (at least in the directory from which the exe is looking for it.Any advice?
Thanks,
Andrew
Andrew,
Sure sounds like the app builder is removing the front panel for the Print Report.vi. If it's not set as a Startup VI in the build specification, then it gets its panel removed. Go to the Source File Settings in the App Builder and disable the Remove Front Panel for this VI (the Print Report.vi) and rebuild. This might be all you have to do.
Mark
-
QUOTE (Phillip Brooks @ Dec 8 2008, 11:08 AM)
You can get access to the raw socket usingvi.lib\Utility\tcp.llb\TCP Get Raw Net Object.vi
http://forums.ni.com/ni/board/message?boar...ssage.id=232025
Just be aware that LabVIEW doesn't know what you're doing to the socket, so tread lightly

I'm a little late to this thread, but I have to admit I did not know you could get the socket handle from a LabVIEW function (thanks for the info Philip!). My TCP IPv6 toolkit in the Code Repository already uses the socket handle as the connection ID, so one can use this LV function to get the socket handle and then connect to any of those VIs. I never thought about returning the socket properties until this thread, but it seems like it could be useful so I added the following (from the ReadMe for this toolkit)
"GetType, Get Address, and GetPort functions - these functions take a socket handle and return the type (IPv4 or IPv6), the connected address, and the connected port. These may be used as part of this toolkit or can be used to return the same information from the native LabVIEW TCP/IP toolkit (Windows only). One needs to get the socket handle using the "TCP Get Raw Net Object.vi" found in "vi.lib\Utility\tcp.llb". Pass the Raw Net Object (socket handle) into these VIs."
Mark
-
QUOTE (Norm Kirchner @ Dec 9 2008, 01:37 PM)
This was your original problem.Why not have a Q Reference manager (assuming that they are string based (as they should be)).
This would be a LV2 Style Global from which you could pass in an enum which would dictate which ref you passed out.
Inside of this you would register the slave and master Q and as the slaves go dead and are replaced w/ another one you just register the new ref.
That way everyone can access everyone elses q's as needed in the same manner.
Also then each plug-in has a standard method of registration of Q and access to the master.
Whadayathhink?
So maybe I didn't exactly answer the original question, but I think that named queues in LabVIEW are one of the more overlooked tools. I use these most anytime I need interthread communication inside LabVIEW. I even discovered that they make a reasonable way to create a functional global for sharing data among a single group of reentrant VIs - kind of like a private instance variable in a class so that methods of that instance can share data. But I digress...
Anyway, I have explored the idea of creating queue managers (or something like that) inside LabVIEW but I think appropriate use of named queues makes it kind of redundant. LabVIEW is internally keeping track of the named queues - if I need to know if a queue ref is dead I only need to try to obtain that queue. If I manage the queues correctly - for instance, force destroy if I know I want the queue ref to die - I can always just 1) get all VI's in memory and 2) try to open their queues (if I expect them to have one). Then I effectively have a queue manager and I don't have to exert any effort to make sure I keep it up to date - LabVIEW gives me that for free :thumbup: . So now, all I have to do is have a consistent naming convention for my VIs with queues - maybe something like Queued_DoSomething.vi and consistent names inside those VIs for the queues - something like Input_Queued_DoSomething.vi and Output_Queued_DoSomething.vi. Also, keeping to your suggestion to keep everything strings (which I usually do), then any VI that needs to communicate can try to open the queue and if the queue exists, put something on it or take something off and new VIs are easy to introduce.
Which brings us to the next issue with queues - queues don't broadcast to all registered listeners. Whoever gets there first consumes the data. This can be a real can of worms and kind of argues against a queue manager with unfettered access to anybody else's queue. It's all too easy to introduce problems when a new VI starts consuming data that you expected to have available for another VI.
At any rate, it's good we can have these discussions because I'm always learning something!
Mark
-
QUOTE (Greg Hupp @ Dec 9 2008, 12:07 PM)
http://lavag.org/old_files/monthly_12_2008/post-1322-1228852101.png' target="_blank">
-
QUOTE (ragglefrock @ Dec 9 2008, 11:01 AM)
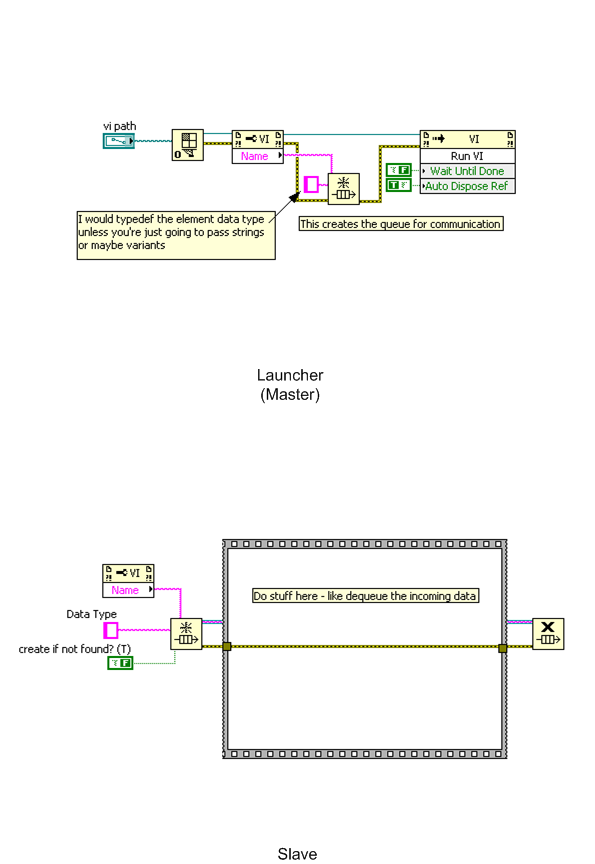
The downside here is that it is difficult to know what the proper name will be if the spawned slave VIs are reentrant clones of each other. You'd need to have some sort of ref count to know which reference to obtain. For instance, your queue name might be Slave Ref %d, where %d represents an incrementing number unique to each spawned slave. But then you need to pass the slave that unique number somehow, which invalidates the whole situation.If the spawned slave VIs are all different VIs, then this is a perfectly good solution.
Just a thought...
This is a good point - if you launch multiple copies of a reentrant clone, you have to make sure you communicate with the correct one. But one way to do this is when you launch the reentrant VI, get the VI Clone name - this is available thru the VI properties using the ref you just opened. Use this to build the Queue Name string (like InputQueue_%s formatted into string, which becomes something like InputQueue_My_VI:1). Then have the spawned VI get its own Clone name thru VI Properties and open the same queue. Then you have a unique one-to-one association without ever actually passing anything on a wire to the spawned VI.
Mark
-
Don't pass queue references at all - used named queues. The master creates the queues as named queues and then the slave can just get a reference to the queue using the Obtain Queue function. This completely removes any data flow dependency - that's good for asynchronous processes (threads) but one should always be careful because it's really easy to step on your ****. You can set the Create if Not Found in the slave to false if you want to make sure the Master has created the queue before the slave tries to access it. Also, make sure and close the queue reference in your slave when you exit or you will leak memory - the queue ref created here will remain in memory until all queue refs are closed unless you explicitly close it.
Mark
-
Move the DAQMx Write into the loop and then execute the loop as many times as required to recreate the complete waveform as many times as you want. If you start the task outside the loop, the device shouldn't reinitialize on every iteration (see the Start Task topic here http://zone.ni.com/devzone/cda/tut/p/id/2835#toc5). Stop the task outside the loop, and then clear. It may appear that the device is resetting depending on the end condition of your waveforms - are they continous if called back-to-back? If you've already tried this and it didn't work, to quote Emily Latella ( http://en.wikipedia.org/wiki/Emily_Litella ) "Never Mind"
 I don't actually have any hardware handy to try this so take this FWIW.
I don't actually have any hardware handy to try this so take this FWIW.Mark
-
You can open a PDF file from LabVIEW (at least starting in 8.2, that's the first time I used it) using the "Open Acrobat Document.vi" in \vi.lib\Platform\browser.llb\. Look at that for an example of how to use DDE (http://zone.ni.com/devzone/cda/tut/p/id/4531) to communicate with external applications. You might be able to do something similar calling third party document conversion tools.
Mark
-
I second jcarmody - these are all good suggestions. This UI scheme that I frequently use demonstrates in more detail how the keep the current UI state up to date without locals or polling by using events and bundling or unbundling into a cluster.
Mark
Download File:post-1322-1228401271.zip
-
Use the C String Pointer type in the Call Library Function for the LPSTR type (long pointer to string, where long means 32 bits - leftover from 16-bit Windows!) and the same type with the Constant box checked for LPCSTR (long pointer to constant string).
Mark
-
Yair,
I think you're probably correct that as you open the front panel it will take focus but if you leave it open and then don't invoke the "Show Front Panel when Called" method I don't think it will take focus on subsequent calls. So once the sub VI is open the user can bring the main VI to the top and it will stay there. I can't try this right now and confirm this to be true (since I'm not at a computer with LabVIEW) but I think this is correct.
Mark
QUOTE (Yair @ Nov 29 2008, 09:14 AM)
I'm not sure, but if memory serves, you can't open a VI's front panel without it taking focus, even if you use the method Mark mention, unless the caller is modal. It's possible that this will work with a floating VI, but I'm not sure.Here are some ideas for workarounds. I'm not sure if they're all workable:
- Use the input VIs to read the keyboard all the time, regardless of control and VI focus. This will require polling and some additional logic.
- Use the IsFrontmost VI property and KeyFocus property to return the VI and the control to focus automatically. This is probably bad, as this could happen while the user was typing.
- Use a subpanel to display the subVI instead of a popup.
- Use the input VIs to read the keyboard all the time, regardless of control and VI focus. This will require polling and some additional logic.
-
I don't think that key focus is the right thing to consider here - what I think is happening is that you probably have "Show Front Panel When Called" enabled in the sub VI or in the SubVI Node Setup, so all LabVIEW knows to do is switch the panel (window) focus to that sub VI whenever your main routine calls it. As soon as that happens, the Main VI is in the background. You might want to dynamically open the subVI panel (don't enable "Show Front Panel When Called" in the sub VI or the SubVI Node Setup) and then when you execute the sub VI it will show its current data but it won't bring the panel to the front or cause a control in use on the main panel to lose focus.
Mark
-
Every time I've encountered this error message
"Error loading "C:\blah_blah_debug.dll". This application has failed to start because the application configuration is incorrect. Reinstalling the application may fix this problem."
It has been when a DLL was built with the debug switch on and is linking to the debug version of a Microsoft run-time DLL. In your case, you're probably using msvcrtd.lib which links to the msvcrXXd.dll, where XX is the version (80 is typical). The msvcrXXd.dll is not part of the standard windows install where the msvcrXX.dll, which is linked to by the msvcrt.lib, is - that's why the release version runs and the debug doesn't. Make sure you're not using a /MDd compiler switch (the default release build does not but the Debug build does).
I've found this app
http://www.dependencywalker.com/
to be pretty useful in discovering which run-time component is missing when a DLL won't load.
As far as
"Error 13 occurred at dll_name.dll
Possible reason(s)
LabVIEW: File is not a resource file"
I don't know - I don't have any experience with this error message in the context of loading a dll - I have seen it in other circumstances but none seem related to your case.
Mark
-
The TCP IPv6 Toolkit in the Code Repository has been updated to support Buffered and CRLF modes in the TCPIPv6_Read.vi. The original toolkit only supported Immediate and Standard modes.
Mark
-
Build your LabVIEW VI as a DLL and then call it from C++ - see these links
http://zone.ni.com/devzone/cda/tut/p/id/2719
http://zone.ni.com/devzone/cda/epd/p/id/1515
Or, if you're using managed code in VisualC++, check out
http://zone.ni.com/devzone/cda/epd/p/id/6050
Mark
Base64 decoding problem and Open G zip error combo
in LabVIEW General
Posted
I can't help you with the zip file issue, but if you want to try a different base64 encoder/decoder and see how that works, you can get the ones that are part of the XML-RPC Server for LabVIEW in the Code Repository (http://forums.lavag.org/XML-RPC-Server-for-LabVIEW-file156.html). The XML-RPC standard must support base64 encoding/decoding so I wrote these implementations for that toolkit.
Mark