Mark Smith
-
Posts
330 -
Joined
-
Last visited
-
Days Won
5
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Mark Smith
-
I like LabVIEW and NI - but this could be a little too close to home for those guys to feel entirely comfortable

-
I understand exactly where you're coming from and 99% of the time I agree - I want the app to start kicking and screaming if it can't load the proper configuration. But I have seen a couple of cases where my customers need to build large, custom configuration files. They then use the app for six months and realize they want to add some new functionality that logically gets configured in that file (that contains six months of user-defined data they will be royally p****d if they have to recreate). In these few cases, the auto-adapting behavior can be a good thing as long as you, the developer, know to expect it. But with great power, comes great responsibility
-
This may be getting too far from the original question, but I seem to be on a roll for de-railing threads If you use the LabVIEW Schema XML Flatten and Unflatten VI's with LabVIEW classes, older versions of a flattened instance can be read into a newer class instance (I'm sure I'm not using the best terminology here). So if you have the data you want to serialize to file as the data members of a class and the class definition changes, the unflatten from XML still works reading the old class definition into the new. When the unflatten reads the old xml into the new data structure (the class private data), it just ignores any extra data members in the xml (this happens if you deleted or renamed a control in the class data definition) and places the class default data into any controls that exist in the new data definition that aren't found in the xml. If you try reading a cluster from an xml file created from an earlier definition, it just fails. This can be both very handy and very dangerous if you're not aware of this behavior. I point this out here because it's one way to avoid creating the mess Ben warns about. And is another reason one might want to use classes instead of type-defs - wait - that was another thread
-
No, and that's one point I wanted to make in my earlier post. If you have a real, legal or moral grievance, there are proper ways to try to right the wrongs. I'm not naive enough to think that is an easy course. I'm sure more than one person has sabotaged their career by taking this route when they were driven by conscience to do what was right. But I still think that an anonymous action whose only apparent motive is to indiscriminately embarrass and impede a company, government, or whatever does not meet this standard. I also think that any activity to try to muzzle Wikileaks is a waste of time - one, you'd probably be on legal shaky ground and two, someone else would be up and running with the same information available within 15 minutes.Sorry about the thread derail...
-
I don't think it matters much if Wikileaks broke the law. The ones that clearly broke the law are the ones that provided classified information to them. There's not much question on this point. If one agrees to protect the information as a condition of having access, I don't think that an individual can then just decide not to abide by the law/his contract/etc. If there's a real specific instance of wrongdoing, the I might see releasing that information to an attorney in confidence who could then build a case. Just anonymously dumping massive amounts of classified and sensitive data to Wikileaks is the action of a disgruntled coward. I'm putting on my flame suit now..... Mark
-
OK - so this may or may not answer your question, but if all you really need is to serialize a data structure and write it to disk in a semi-human readable form, then you can use the Flatten to XML, Write to XML File. Then use Read From XML File and then Unflatten From XML to reload the data structure. This doesn't preserve a "spreadsheet" style look and feel. It's not clear to me if you have to create a file that you want to load into a spreadsheet and edit and then reload, or if you just want something a human could read to confirm that values are correct or such. You could also use some tools that serialize to .ini style files, like the ones from OpenG or MooreGoodIdeas (http://www.mooregood...iteAnything.htm) As far as your data structure, if I read correctly, you could use an array of clusters that contain arrays - so index 0 - 7 would be an array of clusters, each cluster will contain a 2D array of variable size (and other stuff, if needed). If you really need to export as a spreadsheet and then edit and import back into the data structure, it might be easier to use a spreadsheet and an automation interface (like Excel and ActiveX, although I think if you dig here someone contributed some tools for OpenOffice) Mark
-
Data allocation under OOP design patterns
Mark Smith replied to Jubilee's topic in Application Design & Architecture
Just t add my 2 cents worth (and that's about what it's worth) As Felix pointed out, this gets complicated - LabVIEW doesn't copy data any more often than it thinks it has to. For instance, the standard LV OO Vi ( a LabVIEW method) has input and output terminals. But whether or not LabVIEW creates a copy of the data depends on what happens inside the VI. For example, if the VI indexes into a class member that is an array, gets an element, operates on that element and does not write back to the array, no copy is made. It just looks like dereferencing a pointer. So no copy is made of the instance of the class and no copy is made inside the array - everything happens "in-place" without any extra effort on the part of the programmer. There's lot's more to know but the simple answer is that until you start operating on really large data sets LabVIEW's automatic memory management works well without any help. If you use large data sets, search for the white papers on-line about managing large data sets in LabVIEW. I'm guessing here since I'm not sure I understand the question, but I think the answer is that any particular wire at any point in time will effectively allocate enough memory for the instance of the current type. The wire type determines what type of object instance can be carried. That instance will include the parent data (if there is any) and when that wire has no more data sinks, LabVIEW will know it can deallocate all of that memory for that instance. Nope - a simple LabVIEW array doesn't contain indices. It just contains the size of each array dimension and the data. So if you do something that could be implemented as pointer manipulation (like replacing array elements) no reallocation is required. See http://zone.ni.com/r...data_in_memory/ You mean something like "x=x++" ? To something similar in LabVIEW then you'd use a shift register and an increment function. I can't imagine this operation not being atomic. I've never seen anything about thread pools in LabVIEW. Also, LabVIEW threads are part of the LabVIEW execution engine and the LabVIEW scheduler does all the heavy lifting. This is another complicated subject that the developer typically can ignore as the execution system will allocate resources. http://www-w2k.gsi.d...tithreading.htm http://forums.ni.com...-work/m-p/73733 I'm with Felix - I don't get this Mark -
Or look on WikiLeaks Mark
-
Data allocation under OOP design patterns
Mark Smith replied to Jubilee's topic in Application Design & Architecture
As of LabVIEW 2009 (at least that the version where I use this feature), you can declare methods that must be overridden by the child and whether or not the parent must be called in the child's implementation. So there's no "abstract" or "interface" keyword but the effect is the same. You still have the limitation that a class can't implement multiple interfaces since the "interface" is still a LabVIEW class and there's no multiple inheritance. Mark -
I'm a little late to this thread, but I have a complete project (except the DNS lookup) around the WinSock functions so LabVIEW can support IPv6 in the code repository http://lavag.org/fil...ls-for-labview/ This could be a useful reference if you're looking at how to get to low-level socket functions. It's VisualC++ instead of .NET. Mark
-
OK - so this isn't about any specific design feature - but I find that I don't use any of those things that are designed to help me "wire faster". One is because of habit - there were no "quick drops" or "auto tools" in LV4 (as least I don't think there was an auto tool - but I'm old and memory often fails me!). The second is because without any of those features I can wire a lot faster than I can think - LV's graphical environment is so easy to use that my limiting factor is figuring out what to do next ("is it the difference of the integrals I need here?") rather than anything relating to coding speed. I am in awe of those of you that can design code fast enough to efficiently use these tools Mark
-
From the LabVIEW help Configuring for Multiple Thread Operation In a multithreaded operating system, you can make multiple calls to a DLL or shared library simultaneously. You can select the thread to execute the library call from the Thread section on the Function tab of the Call Library Function dialog box. The thread options are Run in UI thread and Run in any thread. If you select Run in UI thread, the Call Library Function Node switches from the thread the VI is currently executing in to the user interface thread. If you select Run in any thread, the Call Library Function Node continues in the currently executing thread. By default, all Call Library Function Nodes run in the user interface thread. Before you configure a Call Library Function Node to run in any thread, make sure that multiple threads can call the function simultaneously. In a shared library, code can be considered thread-safe when: * It does not store any global data, such as global variables, files on disk, and so on. * It does not access any hardware. In other words, the code does not contain register-level programming. * It does not make any calls to any functions, shared libraries, or drivers that are not thread safe. * It uses semaphores or mutexes to restrict access to global resources. * It is called by only one non-reentrant VI. Note All calls to LabVIEW-built shared libraries should specify Run in any thread. If you configure the Call Library Function Node using LabVIEW-built shared libraries and specify Run in UI thread, LabVIEW might hang and require you to restart. So, if the LabJack guys distribute a VI that calls their DLL with the Run in UI Thread checked, maybe they know it isn't thread safe. You could always try, but don't be surprised if there's a major crash And if it will run in any thread, then you might want to consider increasing the execution systems setting (I think that's the correct terminology) in LabVIEW to five, since each DLL call will consume a thread and with the default four threads per processor, one call might have to wait. Unless you have dual-core machine, then you already have 8 execution systems. Mark Shaun's faster than I am
-
OK - so I lied - I'm back for more I think this confuses highly coupled with statically loaded. I don't write code I consider highly coupled but I seldom if ever run into this kind of issue because I don't use much code deployed as dynamic libraries. I do have a bunch of classes and OO frameworks that I use and re-use but I use them by creating a unique project file for each deployed app and then adding those components that I need. So, I have a class library that is immutable (within the context of that project) that I drag into the project explorer - this is not a copy of the code, just a "link" to where the class is defined. Now, if I use any of that class in any capacity in that project, the class gets loaded into memory (and if I'm not using it, it shouldn't be there). But, the only "coupling" between the classes I use is that they are all called at some point by something in my application-specific project. My classes often include public typedefs for creating blocks of data that benefit from logical organization. But these typedefs get updated across all callers because of the specific project (not a VI tree, in this case). I realize the project doesn't force a load into memory, but once again, using the class does and that's the only reason they're in the project. I'm still forced to deal with other users of the classes that might not be loaded, but that's what an interface spec is for - any changes to a public API shouldn't be taken lightly. The big difference is that all my code is typically statically linked so everything the project needs is there at compile and build time. But this does NOT mean it's highly coupled as each class has a clear interface, accessors, protected and private methods, and so on. Just to help derail this thread, I'll state that I'm not a big fan of using the plug-in library architecture just because you can. Sometimes it's really helpful, but if an application can be delivered as a single executable (and that includes with 8.6 style support folders) then I find it much easier to maintain since I don't get LabVIEW's version of DLL hell. I don't care if my installer is 160 Mb or the installed app is 60 Mb. The performance under LabVIEW's memory manager is more than adequate. Mark
-
A couple of last comments and then I'll get out of the way. First, LabVIEW native OOP is absolutely dataflow (and not just by-val). No VI runs without all data present at its inputs There are no "variables, pointers, etc" - all data is "on the wire". Copies of data are made at wire branches when required. Or, in OOP jargon, No METHOD runs without all data present at its inputs There are no "variables, pointers, etc" - the INSTANCE is "on the wire". Copies of the INSTANCE are made at wire branches when required. As always, one can break dataflow when necessary. Second, a typedef is just a logical container for datatypes that is a convenience to the programmer. It should represent a group of data that belong together - like maybe the IP address and port for a TCP/IP server connection. The programmer typically needs both in the same place at the same time. The fact that LabVIEW auto-propagates seems to me to be desirable because LV doesn't have separate link/compile operations. If you changed a typedef in C, the changes would propagate at link and then compile - LAbVIEW needs to detect the change and then force a recompile everywhere because of the JIT compiler. Mark
-
OK, you clearly don't work where I work We've got no end of people around here that use all of those languages as well as LabVIEW and consider themselves programmers - this is especially true of the researchers (PHD's in many scientific disciplines). But many have no idea how to architect code (notice I avoid saying most, since I can't provide hard data ) and no matter the language, they write spaghetti code. And there are more than a few around here who's job is to architect and develop code in LabVIEW - and we're trained in many disciplines but we all have comp sci education as well. But in the end, what matters to our customers is "do our test and measurement systems work" and that's why we have to recruit people for our team with varied backgrounds (heck, my undergrad was in ME) because it's not enough to understand code development, you have to understand the problem you're trying to solve. Mark
-
Since I was in on the original thread, I thought I'd weigh in here as well. First, let me say I'm following this thread because I know from all of their contributions to LAVA both ShaunR and Daklu will have something intelligent and interesting to say. Second, I feel like I'm positioned somewhere between you two on the LVOOP question. I (and my team, since I make them) do all of our development in native LV OOP. I seldom use any class as by-ref as it does break the dataflow paradigm, although as we all know there are times when breaking dataflow is necessary or at least desirable. But I may not be an OOP purist. I use typedefs - I even find occassion to use them in private class data. My typical use is something like this - create a typedef and add it to the class as a public control - place the typedef in the private class data cluster - create a get/set for the typedef in the class. This is typical of a class that I may write to enable a specific DAQmx functionality. The user may need to select a DAQ channel, sample rate, and assign a name but nothing else. So I create a typedef cluster that just exposes this. Now, the developer can drop the public typedef on the UI, wire the typedef to the set method (or an init method if you really want to minimize the number of VIs), and have a newly defined instance on the wire. Then wire that VI to a method that either does the acquisition or launches the acquisition in a new thread. What I like is that the instance is completely defined when I start the acquisition - I know this because I use dataflow and not by-ref objects - and I know exactly which instance I'm using (the one on the wire). So this leverages data encapsulation and dataflow, both of which make my code more robust and only adds one or two VIs (the get/set and maybe the init) to the mix. So I don't think by-val LVOOP compromises dataflow and doesn't add (to me at least) excessive overhead. But, I clearly have not designed the above class as a reuse library since my get/set and init depend on a typedef. If I try to override any of these methods in a child, I'll find it difficult since the typedef can't be replaced so I'm stuck with whatever the parent uses. But that's OK - not everything can (or should) be designed for general reuse. At some point, one has to specialize the code to solve the problem at hand. A completely general re-use library is called a programming language. But there are real candidates for general classes that should support inheritance and LVOOP gives us the ability to leverage that tool when needed. A recent example was a specialized signal generator class (decaying sines, triangles, etc). Even I could see that if I built a parent signal generator class and specialized through inheritance this would be a good design (even if it took more time to code initially). And it proved to be a good decision as soon as my customer came back and said "I forgot that I need to manipulate a square wave as well" - boom - new SquareWave class in just a few minutes that integrated seamlessly into my app. I guess my point is that dataflow OOP is a whole new animal (and a powerful one) and one should try to figure out the best ways to use it. I don't claim to know what all of those are yet, but I am finding ways to make my code more robust (not necessarily more efficient, but I seldom find that the most important factor in what I do) and easier to maintain and modify. I do feel that just trying to shoehorn by-val OOP into design patterns created for by-ref languages isn't productive. It reminds me of the LV code I get from C programmers where the diagram is a stacked sequence with all of the controls and indicators in the first frame and then twenty frames where they access them using locals. They've used a dataflow language as an imperative language - not a good use of dataflow! Mark
-
OK, here's my opinion (and it's only an opinion ) First, there's nothing wrong with having a class method that just does some helper function that doesn't need direct access to the class data. If the method only makes sense to use in that class, make it private so you know not to try to use it elsewhere. Second, don't worry too much about having a function that sorts the waveforms by attribute and using it on every call. If the size of the waveform array is relatively small (tens of waveforms) I don't think you'll ever notice the overhead. And this approach is robust - if on any sort you don't find what you're looking for, you might throw an error. Or the maybe the data doesn't get displayed - at least you know that your data is not what you expected. If the overhead cost seems high, then maybe use the on first call primitive, but my experience has been that using that tool is perilous because my interpretation of what should be first call doesn't always agree with the run-times interpretation. Third, if you need the data from a specific instance of a class to operate (like the "getAccelerometerLocations" method) , then pass that class instance in and use an accessor to get the data. I presume you're launching the child window with an invoke node, so just set the class control value before you start the VI and you have the class instance to read. Or better yet, include the DAQ class instance in the class data for the display class, initialize the DAQ class instance, and then pass the display class instance in on startup of the display method. I don't think this creates any kind of unwanted class dependency because your display class doesn't have any utility unless there's an active DAQ class object. If a background scan class isn't running (your DAQ class), then there's no data being enqueued. Of course, if you go this route then you should use what I think jgcode suggested where you do the sort routine once when the DAQ channels are defined and then set these sort tables (data members of the DAQ class - I would use an array of typedef clusters (sorry, daklu). Each cluster contains the waveform name and an array of indices from the waveform array that contain data of that particular name. This approach can be completely dynamic as you can create as many of these sort tables as you need.). Then use that array in the display VI by searching for the desired name (this will be quick, since the array of clusters probably won't be more than single digits) and index into the waveform array using the sort table. As always, YMMV, grain of salt, yadda, yadda, Mark
-
I'm with Daklu here except that if you're using the waveform type this isn't quite true - you can add anything you want to the waveform as a waveform attribute (metadata) and LabVIEW still treats it as a waveform data type and the queue is still valid. Mark
-
How To Properly Cast Object to Child Class?
Mark Smith replied to lvb's topic in Object-Oriented Programming
<P> </P> -
How To Properly Cast Object to Child Class?
Mark Smith replied to lvb's topic in Object-Oriented Programming
<P> </P> -
How To Properly Cast Object to Child Class?
Mark Smith replied to lvb's topic in Object-Oriented Programming
Brian, First, the VI snippet probably breaks because it gets de-coupled from its class library (the snippet probably claims to be part of the library but the library doesn't think so). Second, here's an example project that demonstrates the technique I would use to have a single general purpose constructor that can create any subclass with the parent class data you define and also includes a single method that lets you create any new subclass instance from a parent instance and preserves the parents data ( a deep copy but looks a lot like type casting the parent to a child). Mark DeepCopyExample (LV2009).zip -
How To Properly Cast Object to Child Class?
Mark Smith replied to lvb's topic in Object-Oriented Programming
First, LabVIEW does not support multiple inheritance (thank God!)- you can have an ancestor tree for a given subclass, but multiple inheritance implies that a subclass inherits from more than one distinct superclass. Secondly, you can minimize the work done making a deep copy by wrapping the parent class (and subclass) data members in a cluster and then accessing that cluster in the unbundle/bundle nodes. Typedef that cluster and include it in your class (subclass) library. Then, if you add/remove data to the cluster everything updates and the copy is still valid because the bundel/unbundle operates on the cluster. You will need one specific method for each subclass that looks a lot like my screenshot above that unbundles the data from the direct parent of that class and copies it into a new instance of the child class. Mark -
How To Properly Cast Object to Child Class?
Mark Smith replied to lvb's topic in Object-Oriented Programming
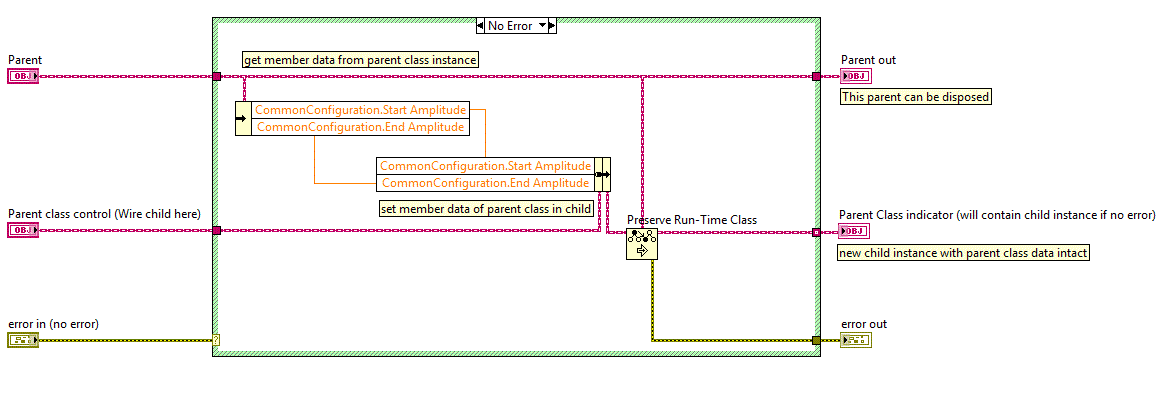
Here's an example of how to do what Mikael suggested Wire the parent instance to the "Parent" and a new child constant to the "Parent class control (Wire child here)". Now, the data you initialized the parent instance with gets copied to the child instance. All you have to do at runtime is wire the correct child class constant in a case statement or such to this method and you can create a "deep copy" of the parent into a new child and dispose of the original parent. It behaves as if you cast the parent to a child, but you don't (because you can't - a cast of an instance implies you just change the type pointer (reference) to an object in memory. A cast from a child to parent is allowed because all of the parent's data is there to access. If you were allowed to cast a parent to a child the child's data members would be undefined and nowhere in memory. If you then tried to access the child's data members, you'd be pointing to some memory location that likely has been allocated to something else (or not allocated at all)). So you create new instances of the child with a copy of the parent's data so all data members of the child are defined in memory. Mark
-
How To Properly Cast Object to Child Class?
Mark Smith replied to lvb's topic in Object-Oriented Programming
Try this - I think this is what the deleted example does. The class controls and indicators are all parents. If you wire a child to the control indicated, then you'll get a instance of the child on the parent class indicator with the parent data members set. (LV2009 - may not be available in 8.x - I can't remember) Mark
-
dynamically loading VIs from an application
Mark Smith replied to PA-Paul's topic in LabVIEW General
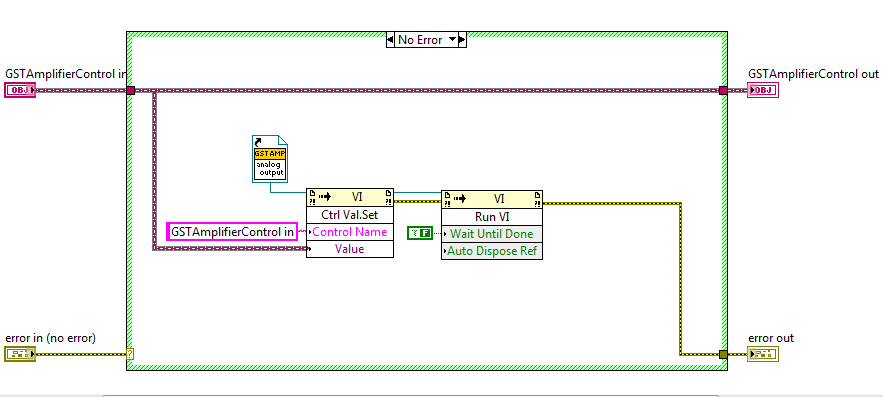
How about this? Use the Control Value Set method to pass data to the controls and then run the VI with the wait until done flag set to false. It's particularly easy with classes because all of the current values of the class data get passed with one call the the Set method. Mark