AlexA
-
Posts
225 -
Joined
-
Last visited
-
Days Won
2
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by AlexA
-
Hi James, I was imagining that perhaps a performance boost could be obtained by keeping it as 3 different files, but making the TDMS files the responsibility of the process driving each relevant hardware component, rather than having a process (or actor) which functions purely as a File IO engine. For the most part, I don't imagine there is much to be gained. In either case, a data copy must be made as the data is simultanesouly being displayed to the user (at reduced rate) and saved to disk (at full rate). If there is a difference, I'd be surprised and would attribute it to some low-level functionality like the ones you mentioned. Incidentally, I've never heard of being able to read a DVR from an FPGA target. Do you have a link to a white paper or similar where I could read about how this works? I don't understand how one passes DVR's of data from FPGA to host? Or am I misunderstanding the level at which the DVR is created? Is it instead created at the point the host first receives the data (a DMA fifo perhaps)? Many thanks for your help. Cheers, Alex
-
Hi Sorry to necro this thread. Is this quote from @Hoovahh correct? Specifically the part about not requiring CPU intervention? If that is true, does it mean that when running parallel processes, it's better to let them maintain their own .tdms files, rather than message the data to a central "File IO" process which is maintaining a number of independent .tdms files? If it helps make the context clearer, I'm saving data from 3 different sources at different rates into 3 different .tdms files on a solid state drive.
-
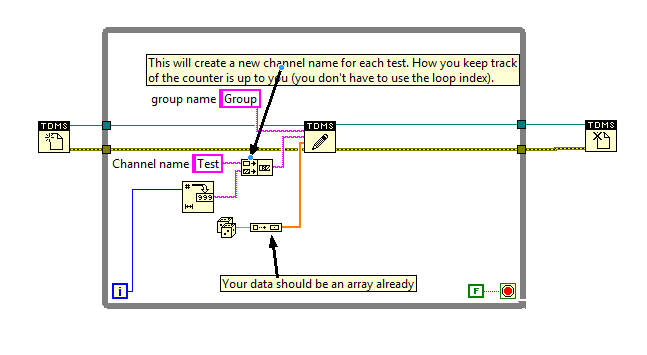
Gday, I would advise you to use the .tdms files. Then you can create a channel for each test write. It's stored as binary so it's small, and the read/writing of these files is great for streaming. Something like this should work:

-
I can't edit, but I've since found out that the issue was because for a computation to complete without a continuous stream of data equal to or greater in length than the FFT latency, the Throughput can not be 1. Which incidentally, cripples the rate of computation.
-
Just to bump this, because I happened to run up against the same problem (which I had forgotten about). I can't believe the FPGA IP was written in such a way that it would leave computations half finished. Now I have to hack up some sort of stupid counter logic to ensure all the data gets processed.
-
Hi Neville, Thanks for the thoughts. Addressing things: 1) The globally shared reference seems interesting. Do you encapsulate it in a functional global or just a raw global? 2) I don't open multiple references continuously. I open one for one loop, one for the other. In the past I've tried just opening a single reference and branching the wire, but that seems to be even more unreliable. 3) Whether or not FPGA inputs update is dependant on whether at least one Open Ref manages to complete. (Because of my architecture/separation of responsibility). In some cases, one ref will acquire succesfully while the other will fail. 4) FPGA outputs are internalised in this case. 5) Memory & CPU is stable while running. This is a restart to restart problem (or appears to be). When I say they become unresponsive "after a while", I mean that, after a random number of system restarts, one or more Acquire Reference operations can fail. Thanks again for your thoughts on this.
-
God I hate Labview FPGA so much. Still having to deal with this crap after all this time. The FPGA spontaneously goes unresponsive. As in, it will work for an hour or two and then suddenly just refuse to operate. Note, I didn't say refuse to connect, it connects just fine, but the controls are just completely unresponsive. No error, just unresponsive. The issue persists across system reboots. Across forced redownloads. I can't figure out any way to stop the issue. I'm at a loss. The only thing keeping in a long stream of invective are my colleagues sitting around me.
-

LabVIEW Solid State Drive (SSD) Benchmarks
AlexA replied to JamesMc86's topic in Database and File IO
Hey guys, sorry to reanimate this topic. Just wondering if since last year, anyone has had a chance to play with Solid-State discs in a PC based, LV-RT set up? We're about to get a Solid-State drive at my lab. I'll try chuck it in the RT machine and see what can be done with it in terms of high-speed, high-volume file IO. Before I do though, was just wondering if anyone has had an success with it before? Cheers, Alex -
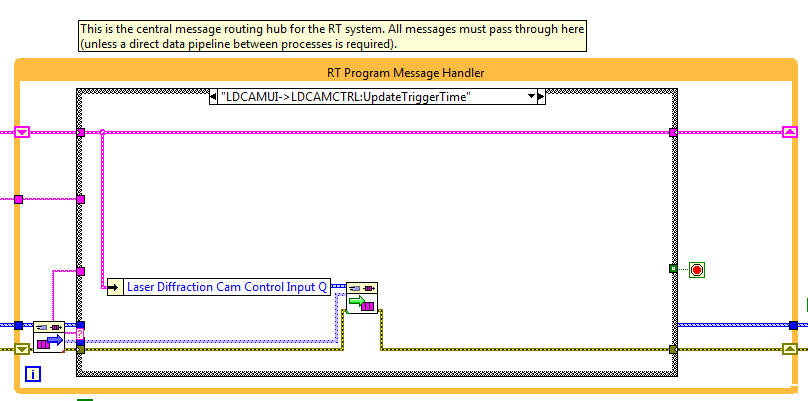
Hi Guys, I've started sending some really big messages around my application and I was wondering if memory is allocated at each message handler? See the following code pic for an example: More generally, what are the best ways to pass around massive data blocks (100s of MB) between processes? Cheers, Alex
-
Ok, I've managed to get it working without interrupt handling initially, I've noticed that the VISA service seems to be quite slow (relatively). I've tried searching for best practises for VISA interfaces, have discovered and used the memmap->peek/poke approach which created a noticeable speed up. I can't find any other suggestions for speeding it up though, do you guys have any experience with this?
-
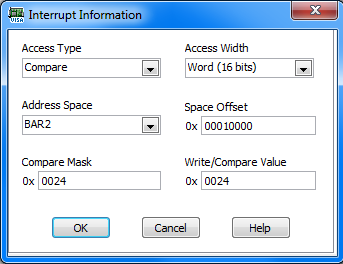
Hi guys, sorry to necro this thread. I've just come back to this idea after much time dealing with the headaches of tapping the hardware interface on the card. Rolf, your last paragraph matches very closely what the tech-support at Agilent implied would be a good course of action, i.e. reading the registers directly. He didn't make mention of NI-VISA, as I understand, VISA would just simplify constructing the framework code involved with addressing a PCI device? So, I'm attempting to use the Device Wizard and I'm a little stuck on the steps involved in handling the various interrupts the device can generate. Specifically, we are asked to set up a number of sequences, each containing at least one compare step, to read interrupts, as shown in the screeny below. So, my question is, the register map header file provided by the manufacturer lists a number of interrupt mask in the following format: #define N1231B_NO_SIG_1 0x00010000 #define N1231B_GLITCH_1 0x00020000 #define N1231B_AXIS_SAMPLE_DATA_RDY_1 0x00000004 /* Read Only */ #define N1231B_AXIS_SAMPLE_OVERRUN_1 0x00000008 Am I right in assuming these fields correspond to the compare value in the screen shot above (if I were to select 32bit mask)? If so, the implication is that I need to create a compare step for each of the interrupts listed? Does this sound right? Secondary to that, the access type can be one of "Read, Compare, Write, NotEqualsCompare, and Masked R/W" I don't imagine that the answer to which one to use is obvious to you, but maybe you have some insight? I assume compare is the correct action for the majority of the interrupts. Finally, the space offset value. The register map header file has the following definitions: #define N1231B_OFST_CHN_INTRMASK 0x0024 /* bmE1 word read/write */ #define N1231B_OFST_CMP_INTRMASK 0x0124 /* bmE2 word read/write */ These definitions are listed in a section called "Register Map", do you think these are meant to go in the space offset field? If so, which one? Or both and use the appropriate one depending on whether we're at the 16 msb or lsb? I know you guys probably aren't going to know the answer to these questions, they're kind of low-level questions about how to handle interrupts which I expect I need to dredge the information from the product information somehow, but I thought I'd put it here just in case some of it sounded familiar to you guys. Kind regards and thanks in advance, Alex
-
Sequencing alternatives to the QSM
AlexA replied to PHarris's topic in Application Design & Architecture
Ahhh, I was thinking about that, make the "Set MessageSender" to be an append type method rather than a replace. Thanks! -
Sequencing alternatives to the QSM
AlexA replied to PHarris's topic in Application Design & Architecture
Of course... Edit: Well, actually, that doesn't really work. Ack messages come back from the same sender, regardless of whether it was the sequencer or a person who triggered it. -
Sequencing alternatives to the QSM
AlexA replied to PHarris's topic in Application Design & Architecture
Hmm, another thought struck me, though this might be more work than it's worth. Perhaps I should extricate the sequencer from the Windows Routing Loop and make it it's own process. Then if it's online Ack Messages which may normally flow to the respective UIs are also copied to the sequencer. Thoughts on this idea? -
Sequencing alternatives to the QSM
AlexA replied to PHarris's topic in Application Design & Architecture
Hey guys, Bumping this a bit because I'm in a similar scenario. I've developed a distributed app for controlling an instrument. The UI runs on a Windows machine and connects to an LVRT machine via TCP. Up till now, I've driven it manually, pressing all the buttons to test all the functionality. Now I'm trying to actually use it to do experiments and have hit on the idea of writing simple .csv files in plain text which are parsed to generate a list of the commands and as with Paul, I'm struggling a little bit on exactly how to handle the sequencing logic. Specifically, how do I handle the distinction between messages sent as part of a sequence, and the same messages when they're sent by the user just pressing a button? I've injected the sequencer at the level of the main message routing loop running in Windows (if Daklu is watching, I've also refactored to use a stepwise routing schema so the Windows routing loop has access to all messages). The sequencer generates an array of commands which is stepped through one by one (in theory). So far, I've tried setting a flag "Sequencing?", but that's not really sufficient to deal with the cases where a message may arrive as part of a sequence, but then also arrive when the user pushes the button, resulting in a superfluous call to the sequencer to grab another job. Perhaps I should disable UI interactions which generate the events I'm passing as part of a sequence (i.e. "enable motors")? I know the distinction between "Command" and "Request" messaging has been discussed a lot recently, and as I understand it, there doesn't seem to be much in the way of a hard distinction for telling whether a message is a "Command" or a "Request". What I'm wondering is, should I perhaps bump the "Sequencing?" flag, or something similar, down to the level of the individual process? So that the individual processes only send "CommandAcknowledged" when they're sequencing? Intuitively, I'm rejecting that idea because what if I want to do things with "CommandAcknowledged" type messages while the instrument is being driven manually? What techniques do you guys use to distinguish when a message is sent as part of a command sequence or when it's sent manually? Alternatively, how do you avoid the issue entirely? -
Ok, so I just hit against the limitation of Onion routing that I think you were talking about earlier Daklu, and it comes as a result of this question: What about if I want to script the operation of the app and run it headless? With my current implementation, I can't script it headless and still save data. I have to open up the UIs for the respective processes to save the data (the decision whether or not to save data has been made in the UIs so far). I've easily got 100+ messages, really, really don't want to re-factor them to not use Onion routing . I think I can get away with just refactoring a couple of data messages that need to be either displayed or saved, or both. Anyways, just jumping on to say I understand why you'd avoid Onion now .
-
Hey just an update, I switched to the obtain reference for every loop approach. It appears to have solved my problems, both with responsivity and with deployment after making changes to the RT code.
-
Best way to mimic fixed-size array use in clusters?
AlexA replied to RCH's topic in Object-Oriented Programming
Hmm, I can't really help with your specific question, but is it possible to break out the fixed size array (unbundle) and just use that with the RT FIFO and update whatever the integer is (channel number?) in the same command (perhaps via control), right before you load the array in? Alternatively, but slightly messier, you could have FIFOs that dequeue at the same time, one for the array, one for the int. -
Hi James, Thanks for the insight. The use case for the FPGA is pretty complicated, it's responsible for a number of hardware interactions (motor control, electrical stimulator control) as well as monitoring a laser interferometer. These processes are all relatively independant on the fpga itself (separate loops), and I want to be able to do things with them independantly, so I have things like a timed loop in RT which is responsible for computing drive commands and updating the AO connected to the FPGA, and another timed loop which polls the interferometer indicators on the FPGA and sends the info out to a UI. This is why I've split the FPGA reference. It appears that I wouldn't be able to interact with the FPGA like this if each loop opened its own FPGA reference (the others would return an error?). Could you clarify on that last point. Cheers, Alex
-
Dealing with State in Message Handlers
AlexA replied to AlexA's topic in Application Design & Architecture
Hmm food for thought. With #2 (different message handler per state), what do you do with a message that arrives that you don't want to handle in your current state, but you do want to handle it when you're next ready to? You could: 1) Ack and request resend with some sort of delay (potentially blocking somewhere as you wait) 2) Store in some sort of buffer to be re-enqueued as part of a state transition (perhaps potential for messages to get "LOST IN SPACE") 3) Preview queue (effectively re-enqueing, likely to be CPU intensive unless you introduce some sort of blocking wait, which will in turn affect messages you DO want to handle). -
Another note for anyone that happens to stumble across this for a similar problem. In the previous post I made a note about the things I have changed to get it to work. This solves the problem of the unresponsive FPGA, but it seems to introduce another problem. "Deployment Completed With Errors". I didn't receive this error when "Run on load" was set to true and "Start on Run" to false (noting that the FPGA did actually work sometimes when configured like this). Now, I'm getting it all the time whenever I make a modification to the RT code which deals with the 7813R reference and then hit the run arrow again, restarting the RT machine fixes this problem. I'm guessing it has something to do with dangling references again, but I've made every effort to ensure it's closed before exiting, so I don't know why this is happening.
-
Ok, to follow this up. Currently it looks like it is now behaving itself. What I did: Removed "Run on load" from the compile flags. Set Obtain Reference to "Start on Run" and made ABSOLUTELY sure that when I closed the reference there was no possibility of that reference still being actively used by one of the worker loops that interacts with the FPGA. I haven't conclusively proved it, but I think the key is to make sure the reference is closed after all loops that could possibly be using it have exited. Hope this helps someone else in the future!
-
Ahh ok, I thought you were specifically advocating against having something like an enum (state) which is maintained in the process data cluster and is passed into a function (subVI) to change the way it performs.
-
@ShaunR Just to clarify, when you talk about having a stateful function, what mechanism are you proposing to maintain this state? Is the state encapsulated via something like an FGV? @Daklu: Ahh, thanks for helping me understand that decision, it makes sense when you put it like that.
-
Hey guys, I'm at my wits end here trying to interface with an FPGA. I've currently got it configured as follows: 7813R FPGA card in a LV-RT machine, running LV2012 on host and Real-Time machines. Compile: Run when loaded = True Obtain Reference: Linked to bitfile FPGA ref bound to typedef Run the FPGA VI = False FIFOs (2 host-to-target DMAs) depth initialized after reference obtained. Code then utilises reference to read indicators, send values to FIFOs and update controls. On Shutdown: FIFOs stopped, but reference not closed. My problem: All subsequent runs after shutting down the program (via the shutdown method) will successfully obtain a reference to the FPGA and init FIFOs (no errors generate), but attempts to read any of the indicators, or update any of the controls do nothing. Indicators show default values, and controls are unresponsive. In the past, I've fixed this by recompiling the FPGA, also sometimes by just redownloading it. Since I made some changes to the way data is loaded into the FIFOs (absolutely no changes to anything that ever touched the FPGA reference, purely to the way the arrays are formatted), nothing I do seems to recover the responsiveness. I've tried: Restarting the RT machine, re-downloading the FPGA (in different orders). I've added close FPGA reference and "Start on Run" to the obtain reference and then restarting and re-downloading. Absolutely nothing has worked. I'm currently in the process of removing "Run on load" (performing a recompile), after which I will add "Start on Run" back into the Obtain reference vi. I'm at my wits end. Has anyone encountered this sort of problem before, does anyone know what causes it?