

AlexA
-
Posts
225 -
Joined
-
Last visited
-
Days Won
2
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by AlexA
-
-
Can you elaborate? Do you create custom message types for each command? I had thought of using the built-in native and array types, with variants used for more complex data (clusters etc), but can see that custom message types could be a lot neater. Also, I can't quite see why the locked classes is an issue - once the message types are defined, I thought they shouldn't need to be edited??
Hi,
Yeah, for some commands that carry with them data (specifically things that interact with the image receive a message which contains the header information and the image data), I create custom messages. The locked classes is only an issue when you haven't finalised the object data of some custom message. You're right, with good design, it shouldn't be an issue.
-
Hey Greg,
One minor issue I've had with sending lapdog type messages over the network (especially custom message types), is that running the program to test will lock out the classes and prevent editing. As such, I use lapdog on the RT machine, but avoid sending any lapdog messages over the network.
-
Hi guys, thanks for the insights! A lot of good information from you guys, sorry it took so long for me to get back to it. I did a few tests to kind of side-step the issue. One of the biggest reasons that I was doing file IO on the RT system was the fact that 100 Hz at 512kb per image is ~50MB/s throughput, this was too much to just get everything onto the host computer via the network (when I was on the Uni network). I linked up my host and RT computers with a cross-over cable and ran a simple test that shows I should be able to get images over the network at a rate of about 80Hz without loss (does this seem right to you guys?).
Combined with the fact that the windows machine file IO takes ~4ms to save a file and I've chosen to side step the problem like that. Sorry I didn't take it further and really investigate what could be done on the RT system to speed things up!
-
Ok, further to my previous testing I did some more testing of my own based on some investigation on the forums. I'm working in a PC based LV-RT environment, I think the disc is formatted as Fat32? Anyway, I ran the profiler on my code till the spikes were reaching about 400ms. It turned out that the open file operation was taking a really long time. One of the suggestions on the forums said that Fat32 doesn't handle long file names well. So I removed all the fluffy information and just wrote the pure count as the file name. That resulted in MUCH greater stability, except that now, the profiler didn't record the spikes, but they were observable on the trace. Less frequent, but still increasing in duration.
Another suggestion was that you can't have too many files in a directory (as you mentioned James), so I modified the code to create a new directory every 40 images. This stopped the monotonic increase in spike duration, and reduced the random fluctuations in spikes, but I still get periodic spiking (I think it may be related to the first access in each directory as the spikes are spaced every 40 writes). Just to be clear, I'm not recording the creation of a directory in this timing information. That operation is sent as a separate command after 40 images and then the write is clocked.
Anyway, the results currently look like this:
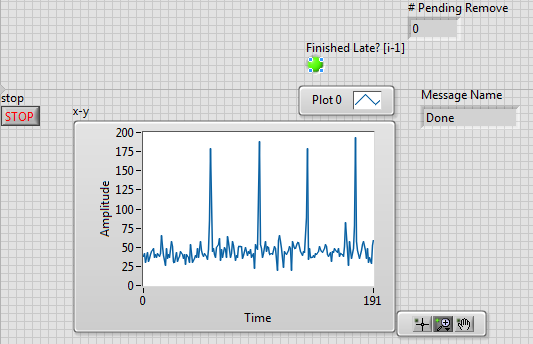
I'll try preallocating for files, it was something I was doing originally but I stripped it out to benchmark a type of basic file IO. I'll put it back in and see if I can get those write times down.
I'm still stumped by these spikes, they don't show up in the profiler as being due to one particular sub VI...
Ok, further to my previous post, I modified the code to preallocate a file size (524800 bytes, enough for the image and the header), the results are below.
Note that I haven't actually solved the monotonic spike increase as I thought, I just didn't observe for long enough.
The write time is down to about 20ms but the spikes are really bad.
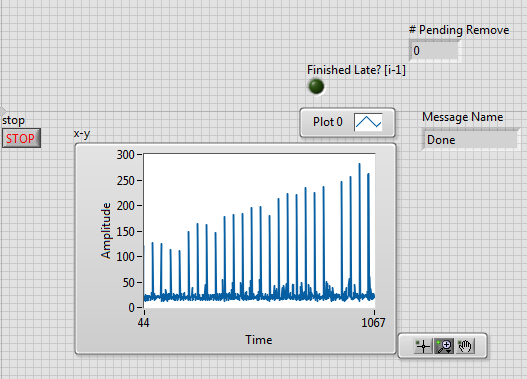
-
Hey guys,
So, a quick question. Suppose I have the High-Throughput FFT in a single-cycle timed loop performing transforms on data-sets 1024 points long. For each set of 1024 points, which should be considered completely independent of each-other, do I need to trigger the reset line on the FFT?
I ask because I'm seeing a weird periodicity in the results of a "find max" type algorithm which is hunting through the magnitude of the frequency spectrum. At worst, the result of this "find max" should be random, not periodic in nature. My guess is that there is some sort of index shifting going on which could be a result of a bad indexing operation (something I can check and fix myself) or as a result of some sort of accumulation in the FFT.
Edit: A quick note, there is definitely no periodic shift in the data itself, it should be more or less constant.
Can anyone shed light on the matter?
Cheers,
Alex
-
Hi Matin,
To answer your specific question, you can set the FP.Open property to false, which means the front panel will not be opened. Yes you are on the right track if your program requires run-time variability. You can set up each data source as a SubVI which accepts an "output queue" as input to the VI. Make this queue of type "Variant Message" where Variant Message is a bundle consisting of a string and a variant. In this way, each SubVI can send a message on its output queue saying whatever you want it to in the text field and loading its data in the variant field.
In your main code, you create a message handler loop which monitors this output queue (into which all your SubVIs are placing their data messages) reads the text field to figure out what to do (a string based "state machine", probably more accurately, but less commonly called a message handler), and then processes the data as you require. For each data message, you will require a Variant to Data of the appropriate type to be able to process the data.
Launch each Sub VI in a separate loop using the Run method with wait until done set to false, something like below:
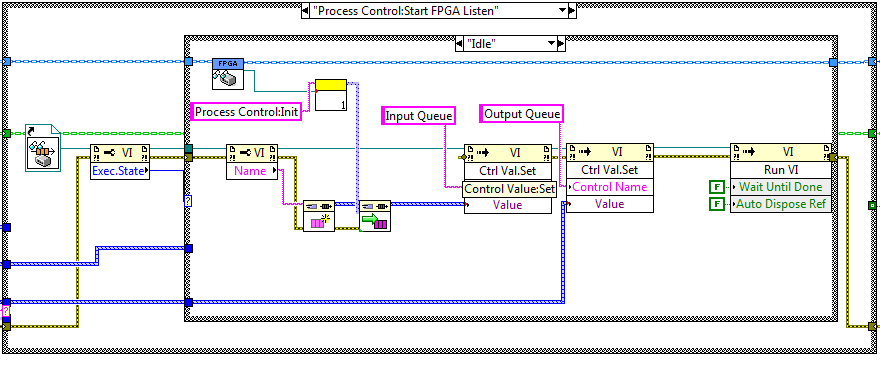
You don't have to have an input queue if your Subs are self initialising.
You may run into troubles stopping the SubVI's, there are many approaches you can take to deal with this, the simplest to use a global Stop Boolean (make sure that only one loop writes to this and all others read it).
-
Ahh ok, makes sense!
-
Just a quick question Daklu, why do the message types have an "xxxx message constant.vi"? Along with an associated type def?
-
Hey Daklu,
Yeah you nailed it, it actually just struck me that since I don't care about losing specific frames to the UI, I can just fix the length of a single UI queue (not priority), and load the frame info into the queue with say 1-5ms timeout. If it timesout, no biggy that frame gets discarded. For more important UI messages, I'll double the timeout to say 10ms.
Thanks for the link about the file permissions!
-
Hi Daklu,
Thanks as always for the prompt answers! I did go have a look at the library in both explore (the windows directory) and in the project window. I couldn't find anything explicit in the project window to change the file privileges (I didn't look at it files view). In windows, it appeared to have modify privileges enabled, but I may have been looking at the wrong settings. I'm sure I can figure that out.
The problem with trying to deploy to real-time is that you can't choose NOT to save it if you still want to deploy (while in the dev environment). The only options are save or cancel.
I'm not using the messaging in any time critical applications so I'm not worried about potential for jitter, but thanks for the heads up!
Yes, you have answered my questions very clearly.
To expand on my intention for the priority queue, I think I am possibly using it in what you call a Work Queue. My UI update queue (the one that takes messages and sends info via network to my host code) is a Priority queue. The high priority queue is for important status updates, the lower priority queue is used to send image data. It's a fixed size, and enqueued in a lossy sense (I don't really care exactly what image the user sees, as long as it's updating at 30 FPS and correct in order). I perform important file IO on the real-time machine.
The reason for this is that the connection can handle 30FPS without lagging (building up a backlog of image information), but I may want to run the camera a lot faster (potentially as high as 100Hz). The image data is pulled from FPGA in a sub-loop, then sent to the main message handling loop, and from there to the UI update loop (or simultaneously to file IO). I may be trying to step around the problem of rate limiting (down sampling) the UI update in kind of a brutal fashion, or it may be more elegant, I'm not sure..?
Thank you very much!
-
Hey Daklu,
I've bombed you with a series of messages, sorry about that! Anyway, in case you're more a forum guy than a PM guy, I'll repeat my questions here, along with another question I have.
First, the most recent question (didn't send it to you via PM):
I'm trying to deploy the messaging system to a real-time system. When I started placing the various VI's, it is asking to save (recompile) the NAtive Arrays and Native Types libraries, but when I tell it to accept and save, it says the library exists and I do not have permission to modify it, can you help me out with this?
A Re-cap of PM questions (with the dumb ones sorted out):
1.) Is it ok to use the deprecated version of Priority queue? (I already know you have to manually create messages, which isn't a big deal).
2.) Are there plans to reinstate Priority Queue in future releases? If so, do you have an ETA on that?
Kind regards and thanks for all your help!
-
So for anyone that's interested. The FFT will not finish a computation when input valid goes false, even if it has previously received the correct amount of data points to do so. I'm not sure why this decision was made, and frankly find it to be more than a little stupid but that was the reason for my problem.
-
Thanks mike, I thought it'd be something simple I hadn't understood. Thanks for the insight.
-
Yeah that was what I was doing, with the added difficulty that different processes could register for the same data queue (not simultaneously). Looking at my code now, I think I had a problem of too much separation of functionality. For example, almost sequential functionality such as reading in a data set from the FPGA and calculating its average, were separated, the reader read the data then passed it to a whole other process that basically existed to calculate the average and subsequently pass it to the UI. Needless complexity.
I'm busily trying to create a logical construct, but its very much a learning process for me, I'm still struggling with the fundamental discussion of this thread, the problem of componentising code. I wish I could wrap my head around the whole "write a story where the nouns become objects and the actions become methods" but it just doesn't gel with me at the moment.
-
Yeah Daklu, after reading James post and letting a few things percolate that had already bothered me (the fact that a "cast to more specific" call feels very similar to a "variant to data" call), I've come to the conclusion that I was wasting my time.
Thankfully though, I've largely gotten over my irrational aversion to passing data via the messaging architecture. Contingent on the architecture being able to keep up with my data update rates!
-
I was doing some light reading and I noticed that Labview apparently stores Boolean data as bytes, where 8 zeros indicates false and anything else is true.
Does anyone have any insight into the logic behind this decision? This is not an important question just a curiosity. It seems like an awful waste of space for embedded applications like FPGAs.
-
Hey Daklu and James,
Very interesting discussion, lots of insightful stuff. Thanks Daklu for your reply, yes in answer to your question, it was extremely helpful!
The following is tangentially related to the discussion at hand, just musings on my part with any insight very welcome:
I've spent a few hours trying to figure out how best to build a database of different queue types, and have come up with the idea of using a Class (Object Queue Class) whose private data is a Queue Reference to a queue of LV Objs. This Class has methods "Init Queue" and "Get Queue Ref" at the moment, Init queue takes an Object as input, where the object is whatever Data Class I want to make the queue.
Get Queue Ref gives me the reference, then I can enqueue an element of type Data Class and dequeue, cast to more specific then read.
This works for my test case, I was musing on whether it makes more sense to create an individual Object Queue class for each data type, haven't tested it but I imagine it would allow me to see mis-wirings at edit time rather than at run time which the current case does.
Anyway, the whole point of the exercise is that encapsulating the queue references allows me to store them in an array and I guess search it for a specific reference by trying to cast to the reference and handling errors, though there may be an even better way to do this taking advantage of inheritance.
More play to come.
-
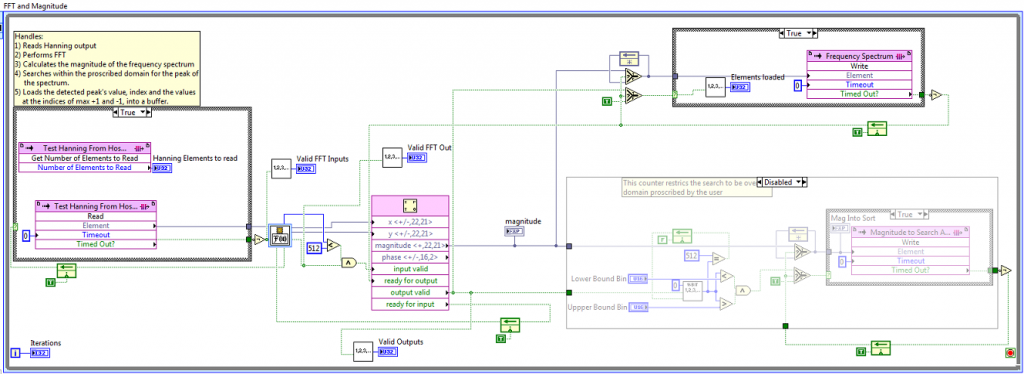
Hi Guys,
I currently have an issue where I'm feeding a relativeley large data set into the FPGA FFT (524288 points) which are computed as 512 1024 sample length transforms (rows of image data).
Despite receiving the correct number of valid inputs (I've checked), the FPGA only returns 522240 points (it's two rows short), can anyone illuminate why this is happening?
The code snippet is shown below.
-
Hi Daklu,
I imagine you're busy but I was wondering if you could weigh in on the following question (from an earlier post).
What would you do if you wanted to be able to close and reopen your slave loop without locking your code up? What I'm getting at here is, what is the OOP equivalent to launching a sub-vi using a Run VI method with "Wait Until Done" set false? Or, as an even more abstract question, how does one implement a plug-in type code structure where the functionality is determined at run-time?
Also, if you're slave process should be continuous except when handling messages, do you utilise a timeout method, or do you separate the behaviours within the slave by adding another layer via a separate message handler?
Thanks for your insight!
-
So, due to my inexperience with LVOOP, I'll just say what I've done so far in trying to recreate what you guys are saying, and you can tell me if I'm on the right track.
I've created a library for my singleton which contains a parent class called "Abstract Queue". The data of this class contains a generic queue reference (the default happens to be string). This class has child classes, I32 Queue, DBL Queue, etc. The library also has a VI called "Get Singleton Data Base.VI" set to private scope. This VI obtains a queue of type "Array of Abstract Queue" (it has to be an array to store as a database right?).
The parent class has a method "Add Queue" which takes an "Abstract Queue" and "Array of Abstract Queue" as input and uses the build array prim to add the former to the latter. I anticipate over-riding this method for each child class. Am I thinking of this right, or have I got turned around somewhere? Each child classes "Add Queue" method takes "I32 Queue" and "Array of Abstract Queue" (or equivalent) as input.
There will be a VI in the library which is called Add Queue or something similar, which will take call the Add Queue method (which is over-ridden for each child).
Things I'm worried about but haven't had a chance to test yet.
1) Does the typecasting dot which appears on the "build array" prim mean that the information contained in the child queue objects will be lost when it's built into the array of type "Abstract Class"?
-
Hmmm, Ok, worth playing with. I think I'm about 80% of the way to what we're talking about with the AE (FGV) approach. If I turn it into a singleton as mentioned above (I'm pondering whether it can be done without LVOOP) it should work.
-
Yep thanks James, the handshaking has been on my list of things to do, the 3.5 hour compile times for the code have been putting me off!
-
Hi Mikael,
That idea was something I was playing around with in a blank project. How would you handle the fact that only one VI should be able to "subscribe" to a queue at any given time. You can't just base it on the singleton lock out idea as there are other operations which might need to take place (such as adding a new queue ref to the "data base").
-
Hey guys,
I'm faced with the challenge of having a plug-in type architecture where one of the primary plugins is responsible for listening to an FPGA DMA FIFO and placing the data extracted into a set of queues which can be obtained and then destroyed by any number of consumer VI's (in sequence, not simultaneously).
The way I've been doing this is to maintain a "database" of queue references encapsulated inside clusters, the database is maintainted inside an AE. So the input to the AE is of type "Data Queue Handle" which is a single element cluster of type "variant". The data queues created are loaded into these clusters and then added to an array inside the AE. To obtain a data queue, a consumer will search through the array for the variant type which matches the queue type it needs (the one that doesn't return an error when the cluster is passed into the "variant to data" block).
This is functional, but makes me feel icky for some reason. I would like to just pass the raw references into some sort of database, which can then be chosen by a simple Equal? comparison. I can't figure a way to do this inside an AE though, as you can't build an array of different data types and you couldn't have a single input to accept all possible Data Queues.
Maintaining clusters of clusters of clusters is impractical and even more icky.
So, to summarise the question. How would you construct a routing house type function for queue references, which can be searched by any function which knows the right command?
I guess I could manually maintain a Typedef of the different data queue types as they're added to the project, then simply talk through that type def. Hmmmm
-
 1
1
-
ElijahKing - MVC+MAL+HAL+Actors+Command+Factory+Plugins
in Application Design & Architecture
Posted
God I wish I{d seen this about 200 years ago.