
LogMAN
-
Posts
655 -
Joined
-
Last visited
-
Days Won
70
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by LogMAN
-
-
Class-editing is broken in so many major ways in LabVIEW. I know of people not using OO in LabVIEW for this exact reason - one of them is an employee of mine, and I'm actually forcing him to give up his resistance and just suck it up. But that's no fun I tell you

Could you go more into details? What are the reasons?
Abandoning classes just because they don't integrate with the SCC sounds like bad reasoning. Rather consider abandoning the SCC and go with ZIP backups instead.
-
Generally I can't get manual namespaces to work. The teams I work in aren't structured enough to adhere to one convention, and they are typically those middle-of-the-road programmers that have enough experience to boost their self confidence but not enough to make them put their egos aside and stick to the plan. Something like that. I want namespaces in LabVIEW, and I hate that I have to stick my VIs into a library to get that - or I hate what I must lug around as well when I just want namespaces.
Amen.
Namespacing through the physical file name also has its advantages - one being that you can identify a VI's purpose without the context of its library. But namespacing in file names create long file names, and it creates long paths due to all the duplicate information (the file name being almost the sum of folders leading into the file location). And we have some limitation to maximum path length in characters when we build executables and load VIs dynamically (~230 chars IIRC).
My arguments follow the same line, however I recently "discovered" that having namespaced files in namespace folders over-determines the namespace and therefore makes no sense. Thus all files can be put into a single folder without loosing information, or rather putting all files into a single folder would increase readability. At the same time you don't increase the path length: 'Library/Function.vi' vs. 'Library-Function.vi'.
However the initial problem remains: Programmers stick to their own plan.
@JackDunaway: I would like to see how you organize the files on disk. VIs are one thing, but classes and especially dispatch VIs are a whole different story. So how do you prevent the name-conflict and path-length issues?
Without LVLIBs, how do I avoid name collisions? I prefer this filenaming convention: Project-Class-Method.vi or Application-Class-Resource-Action.vi ... or generally, LeastSpecificNamespace-...-SpecificThing-...-VerbActingOnASpecificThing.vi
-
Do you know where this recording can be found? Mark doesn't seem to have the US CLA Summit 2014 videos online currently...
/Steen
Haven't seen them anywhere and the friendly search engine has no clue too. However the presentation material is available: https://decibel.ni.com/content/docs/DOC-36232
-
 1
1
-
-
How about Register? You can read and write an register, but you could never add another element to it.
-
1
-
-
I've followed this thread closely to learn more about libraries, classes and dependency injection. Thanks for sharing all your thoughts so far. Now, I don't just want to lurk in the shadows, but participate to this discussion.
So, let me reply to the initial question: Should I abandon LVLIB libraries?First of all, I don't consider the correctness of the dependency tree as a problem. If you only want your hierarchy in the dependency tree, than you cannot use any type of library. So the only thing I'm concerned about is loading time and responsiveness of the IDE. This is what I think:
You should not abandon libraries, if you have a collection of VIs, like utility VIs, that do not call any subsequent libraries. An example would be a library that wrapps functions to call an external DLL. Such a library is completed as one entity. There is a slight loading overhead, but it is acceptable in my opinion.
You should consider to abandon libraries if they contain optional functions that call to other libraries (other lvlibs or classes to be precise). Then again, if all of the VIs in the library call to the same external library, there is nothing gained by abandoning it.
You should abandon libraries, if they heavily depend on other libraries and the dependencies are different on a VI basis. Calling one VI will load the entire hierarchy into memory which cannot be desireable, unless all sublibraries are in private scope. In the latter case you try to namespace items, which adds dependencies that are undesirable for other functions.
---
In the end you'll have to choose by yourself which way is the best. As for me, I'll stick with libraries, but refactor some of my code to a more 'flat' layout (if possible no sub-libraries).
For someone like me who loves namespaces, the namespacing JackDunaway recommends (namespace in filename) is somewhat undesirable (no offence, I just preffer namespaces even if they try to slow me down ). I would rather see something like a "Namespace" type of object in LabVIEW.
). I would rather see something like a "Namespace" type of object in LabVIEW.-
1
-
-
As someone who's always thinking about naming everything "correct" (and continuously failing to get the perfect name
 ), I think the name should describe what it does and 'is' in few words possible. ShaunRs suggestion to suffix the current name with "Framework/Library/Toolkit" feels more correct in my opinion. And that's because it just is a Framework/Library/Toolkit for Messenging... (You could go as far to say it is a Framework/Library/Toolkit for Messaging between parallel processes, so a Parallel Messaging Framework/Library/Toolkit...)
), I think the name should describe what it does and 'is' in few words possible. ShaunRs suggestion to suffix the current name with "Framework/Library/Toolkit" feels more correct in my opinion. And that's because it just is a Framework/Library/Toolkit for Messenging... (You could go as far to say it is a Framework/Library/Toolkit for Messaging between parallel processes, so a Parallel Messaging Framework/Library/Toolkit...)
I would even say it like "I'm using the Messenging library". However if you choose to stick with the current name it will be fine too (a little bit awkward though). Here my votes to your brainstorming:
Brainstorming...
SendMSG Library(SendMSG.lvlib is my core library, and sending a message is the core function of the entire package)
Messenger Library
Messaging LibraryMessengersCouriersSend Message Library
Send Message Toolkit
SendMSG Toolkit"Messaging Library" is number one on my list, since it is grammatically correct (at least I think it is
 )
) -
Now I'm a little bit stuck and out of ideas. With the error occurring in "New Data Value Reference" that eliminates all the traps related to array memory allocation in contiguous blocks that could trigger an out of memory error...
I'm not sure of that one. You stated that you add items to a dynamically growing array. Now in your RAM you need a contiguous chunk of memory that is large enough to hold the entire array. Even if you have 16GB RAM in your computer, if the largest chunk is 500MB, than that is the maximum amount of memory your array can allocate. Otherwise you get an "out of memory" exception. Also be aware, that with dynamically allocated arrays, if the chunk is to small to harbor the next element, the entire array will be moved in memory to a location that is large enough to harbor it. This will double the amount of required memory for some time, as a copy is made in the process.
Could you initialize your array with a decent amount of elements and try again?
I presume you meant that you are running a 64-bit OS. However, note that a 32-bit application running in 64-bit Windows is still limited to 2 GB RAM by default
That's not entirely true. LabVIEW 32-bit running on a 64-bit OS can allocate up to 4GB of memory as stated in this document: http://digital.ni.com/public.nsf/allkb/AC9AD7E5FD3769C086256B41007685FA
On a 64-bit Windows operating system, LabVIEW 32-bit can access up to 4 GB of virtual memory without modification.
-
Uh oh. Does anyone know what happened to ftp://ftp.ni.com/support/softlib ???
Yeah, it seems that the server has been reorganized. Might take a while to figure out the new places. However most files should be in similar locations under '/support' instead of '/support/softlib'. (example: '/support/softlib/labview/labview_runtime' is now '/support/labview/runtime')
Whats supposed to be there? From the sound of it, it looks its stuff that is supposed to be accessible over at ni.com/downloads. Is something not there?
No, everything should be alright on ni.com/downloads, however it is easier to directly access the FTP server and fetch files, than clicking through a couple of pages.
-
1
-
-
Some time ago I tried to launch the On-Screen keyboard that ships with Windows on a 64bit system from 32bit LabVIEW (starting "osk.exe" via shell command or console in LabVIEW). That didn't work even though I explicitly pointed to %windir%\SysWOW64. The issue is Windows redirecting calls to the system32 and SysWOW64 folder depending on your application bitness. This is called File System Redirection. Disabling File System Redirection allows you to call files in the SysWOW64 folder instead of being redirected to the system32 folder.
Call this function and try it again: http://msdn.microsoft.com/en-us/library/windows/desktop/aa365743(v=vs.85).aspx
Don't forget to revert redirection once your call is finished: http://msdn.microsoft.com/en-us/library/windows/desktop/aa365745(v=vs.85).aspxRead more here: http://msdn.microsoft.com/en-us/library/windows/desktop/aa384187(v=vs.85).aspx
Oh yeah, be sure to execute your VI as well as the DLL calls in one specific thread, or else these functions will have no effect!
-
So blockage #1 is that VITs don't register on the palette

A VI template is not intended to be placed inside a VI, therefore you cannot put it on the palette. If you try to put a template into a VI it is like trying to call the template from the VI if that makes sense.
Being sneaky I thought I'd make a VI and embed the VIT in it, calling it from the function palette with the Place VI contents (merge VI to us old hands)

Blockage #2 is that it drops it on the block diagram as a VIT!!!!
:angry: :angry:..And that's exactly what happened here

This is how you can create a VI from the template:
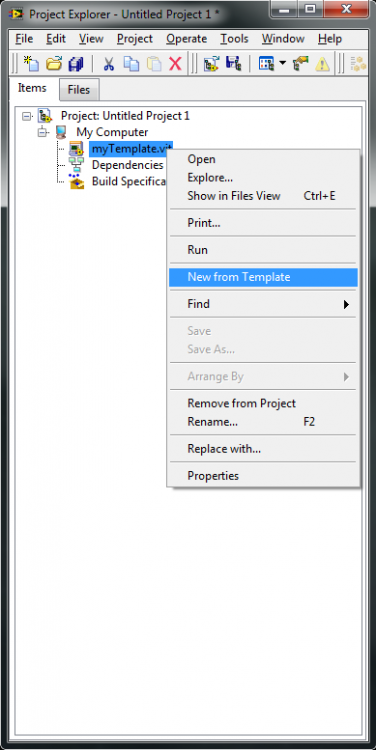
If you try to create a project template with more than one *.vit, there is a solution for LabVIEW 2012+ well described over here: http://ekerry.wordpress.com/2012/11/09/creating-and-distributing-custom-templates-with-the-new-create-project-dialog/
There might be other options though.
Other than that you can put VIs on the palette and check the "Place VI Contents" option (as you did before). Now if you create an VI and place the content from the palette it is similar to a template function. However this lacks the ability of template hierarchies.
-
In one of my recent projects I used an actor (based on NI's actor model) to update UI elements. It basically consists of a class with all necessary control references in the private data (accessible only before launching the actor by using property nodes). Messages were implemented to update each specific control. Due to that it was possible to update the UI without blocking tasks, since the UI thread was handled by the actor core.
-
There is no premium anymore an thus the limits no longer apply.
-
Check in your application build script if the 8.x file layout is activated: http://zone.ni.com/reference/en-XX/help/371361H-01/lvconcepts/referencing_files_in_applications/
If you enable the Use LabVIEW 8.x file layout option on the Advanced page of the Application Properties, Shared Library Properties, or Web Service Properties dialog boxes, the Application Builder stores source files inside the application as a flat list. Because of this file structure, LabVIEW moves any files with conflicting filenames to different folders. National Instruments recommends you only enable this option if the application you build relies on the legacy behavior to store files in a flat list inside the application.
-
Browsing for updates just revealed this:

See you guys in a couple of month

-
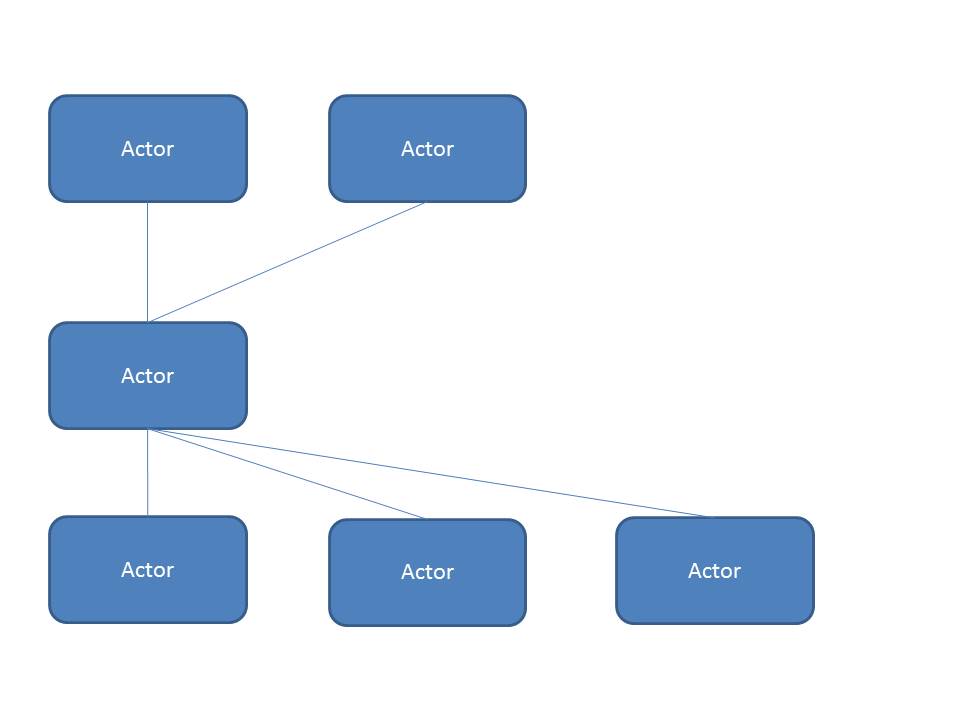
Wouldn't this result in even more classes? I would need the abstract interface class and then concrete class for every actor? Or am I misunderstanding you?
You're right, the total number of classes increases. I should have written "..reduce the number of classes in your current project..". You'll of course have to implement the Actor in another project.
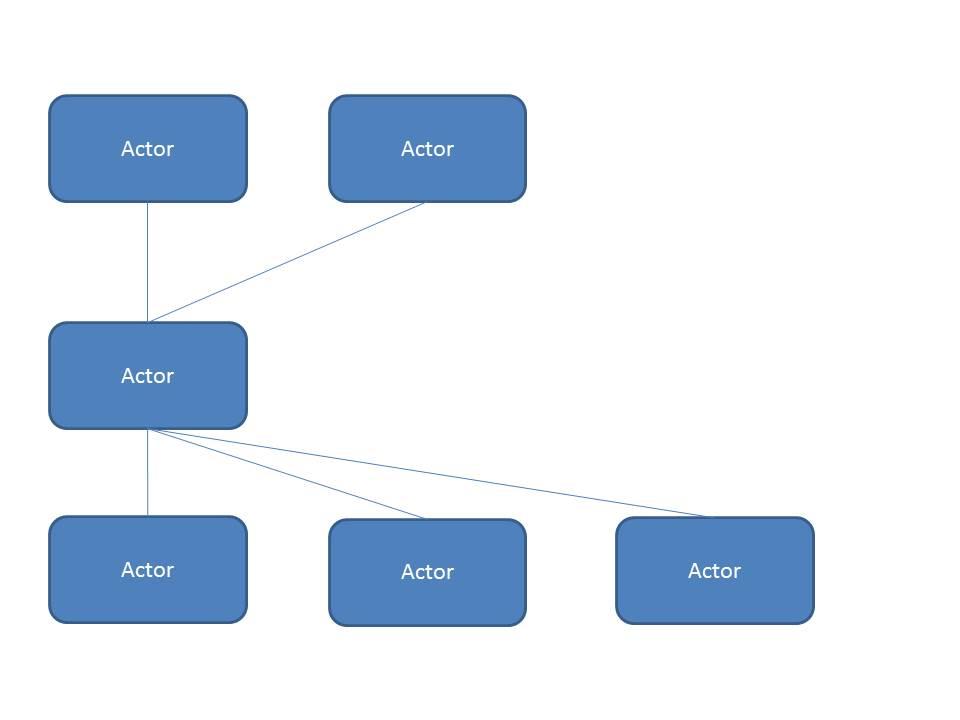
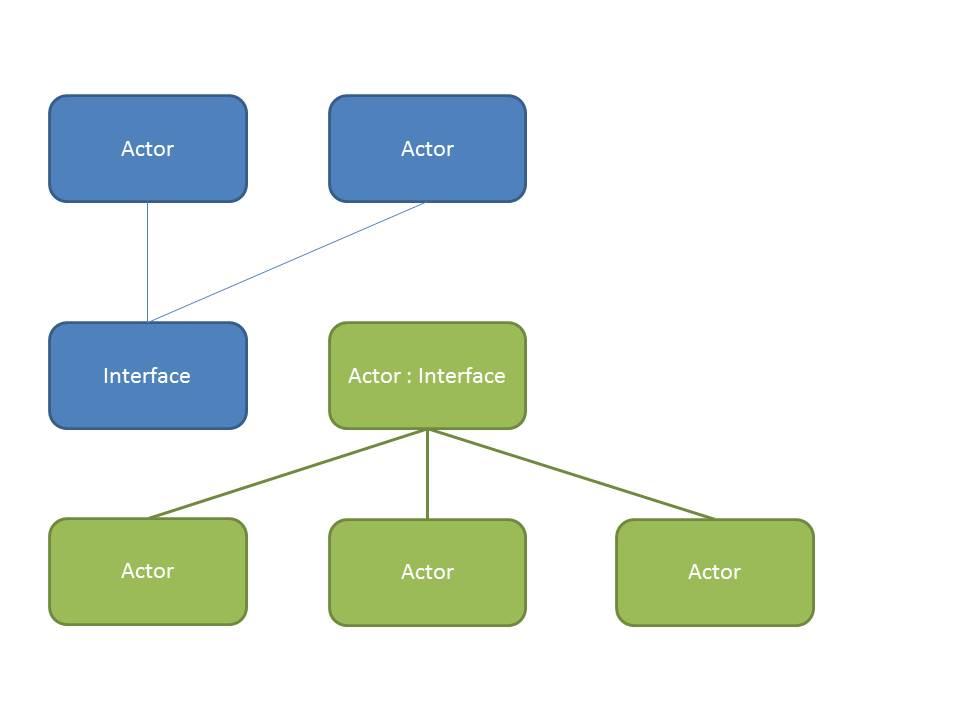
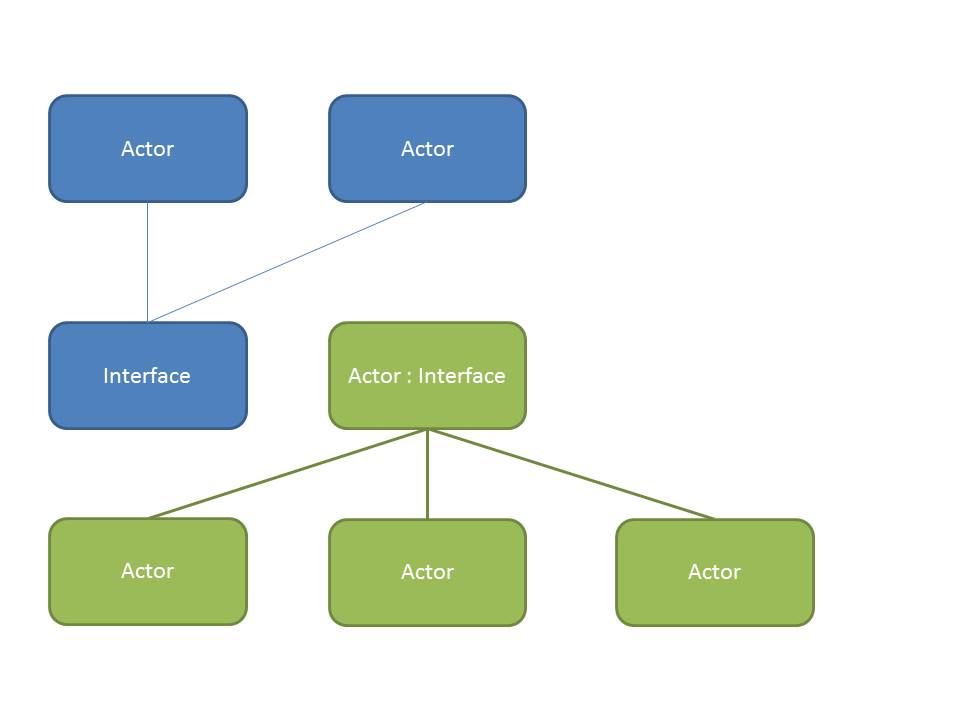
I've attached two pictures to clarify what I mean. Left(top) is the current situation, right(bottom) is the example with an interface. Blue is one project, green another.
-
If Actor A has a message (that in turns calls a method in Actor A) to create an instance of Actor B, then adding Actor A to a project create a static dependency on Actor B. This makes it impossible to test Actor A in isolation with a test harness. The recent VI Shots episode about AOP discussed the need to isolate Actors so they could be built and tested as independent 'actors'. If Actor B also has the ability to launch Actor C, then Actor C also becomes a dependency of Actor A. And if Actor B sends a message to Actor A, then the static link to that message (required to construct it) will create a dependency on Actor A for Actor B. So, the end result is adding any actor in your project to another project loads the entire hierarchy of actors into memory as a dependency and makes testing anything in isolation impossible.
How about making Actor B an interface and use the factory pattern?
If Actor B were an interface it would not have any dependencies to Actor C, since that would imply implementation. Now if you test Actor A in isolation it would in fact load the interface of Actor B into memory (cannot be avoided due to a static dependency), but the actual implementation of Actor B (that causes more dependencies to load) is not necessary. I have little experience with AF, but in my opinion using interfaces and the factory pattern should drastically reduce the number of classes in your project (you would "only" need the interfaces and all Message classes which belong to them). The actual implementation can be done seperately.
-
I recently ran into a similar problem and solved it by installing the NI-IMAQdx driver based on this document: http://digital.ni.com/public.nsf/allkb/0564022DAFF513D2862579490057D42E
The NI-IMAQdx driver software is needed to use third-party image acquisition devices
-
Thanks for the feedback guys!
Now to the Moderators/Administrators: Can we expect a solution any time soon? EDIT: Maybe there is something we could help with?
they've crippled my name

I can now place funny characters in your name
and see what happens if I quote you? You loose even more characters 
-
...Anyways, I know that other people have run into this problem, and that they found various solutions once they started encountering the problem. Examples of solutions are shortening paths (which was not possible in my case because modifying the layout of external code would have caused a lot of problems), building with the "8.x filepath layout" option, or changing the build directory. In some ways, these are all workarounds and not actual solutions...
This is exactly the point. You can find a way to solve the immediate issue, however the initial problem remains.
...I ended up solving this problem by changing my build directory to somewhere where all filepaths ended up being short enough, but I ended up violating the rules my group had laid out for how we structure our repository. ...
When you talk about 'repository' do you mean a repository as in SCC? If that's the case, how can a change on your local checkout violate anything in the repository? If that's not the case your file/folder structure now has a known issue

...What I was wondering is if anyone has any ideas/recipes (project layout architecture for instance) that helps totally avoid this problem from the start of the project, not the end.
Carlo
There are many ways to solve that problem. First of all, the issue is related to long path names, so you want to have a short absolute path to your project and short relative path in your project directory.
I have a local directory on a secondary HD 'B:\projects' which is the root path for all of my projects. I checkout my projects from SVN, but only a a specific branch, or the trunk (else the hierarchy is to extensive). So one project could have the absolute path 'B:\Projects\MyProject'. Short enough.
Next we need a clean project structure to minimize file paths. In my case that would be:
..\Builds <- not under SCC
..\Documentation
..\Examples
..\Resources
..\Sources
..\<project>.lvproj
All VIs, classes, etc... are placed within the Sources directory (either the sources are in the 'Sources' directory, or somewhere in the LabVIEW installation folder). So let me count characters and I got 'B:\projects\MyProject\Sources\' => 30 plus, minus the length of my project name.
Now since I follow this layout, there have been no more problems with path length. However this requires that any files which are placed under 'Sources' are named properly (don't try to tell a story in the file name!). Also there is a rule of having at most two more directory levels (which is fine, since the project is fully capable of organizing sources using virtual folders). As example: All files related to a class are placed into a single folder, thus even with long file names it is not likely to hit the 256 character limit.
-
Since a couple of days some pages show strange behavior with unprintable characters. The same pages were fine before. Here are two examples:
http://lavag.org/topic/17783-continuous-measurement-and-logging-redone-with-“messengingâ€-actors/

http://lavag.org/topic/10729-labview-idea-exchange/page-5#entry110225

Is this problem visible to all, or is it just me?
-
Okay, I start again by reading your initial post and ignoring any reply (except yours). Please be aware that this post is a pure brainstormer from my side and is in no way implemented by myself. Also you should know that I always brainstorm beginning with the basics and without limitations on changing entire structures. Since I don't have your current implementation at my disposal, my brain might get a bit out of control, but I try to stick as close to your situation as possible:
First of all, we want to decouple implementations between sender and receiver. This requires a common 'language' between the systems. We don't want to go down to string handling and already have some sort of messaging system implemented which allows transmission of objects. Let me jump into your last post for now:
I should have entitled the original thread 'Decoupling LVOOP class based message systems that communicate across a network' or perhaps been even more generic and asked: 'How to best decouple a class from it's implementation?'
...Decoupling a class from it's implementation is just not possible by design! A class provides its own set of variables and implementation of behaviour. From an opposite point of view:
Since a couple of years my collegues and I implement anything in LabVIEW without classes. Instead we define a typedef and a couple of functions that work on that typedef. As you can tell, a class would be a far better solution to implement such functions as it defines fields (typedef) and methods.
You currently have a set of data that is common between server and client, packed into the private field of a class. As you mentioned the MVC before, that would be our Model. I see two ways of implementing that kind of model. First a class which must only define the data and provides no methods (except for accessors). The second option is a plain typedef. We'll settle for the class from here on.
Next we want two implementations for the same model (server/client). That is easily archived if we just share the model as we specified above. We don't inherit and just use the class as model which is a parameter for our Controller.
So the flow would be:
Server Side : Controller -> Model >> [NetworkMessage] >> Model -> Controller : Client Side
* Notice that NetworkMessage relates to your entire messaging system.
That somewhat 'covers' the data transfer (will make more sense in a moment; maybe less). Next we want the receiver to do something with these information. I'll try to stick as much to your example as possible:
...
An example would be a client and a server. The client needs to message requests to the server and the server needs to push data to the client.
...The server doesn't know what the client intends to do with the information. So the client must provide some 'meta-data' to the server which is send back in the reply. The client knows how to handle the 'meta-data' in the reply and will act accordingly. (It's the client telling itself what to do with the reply from the server)
...
The problem arises when you add a 3rd or fourth application or even a plugin library to the mix and wish to decouple those from the other applications. You must either extend the current set of messages and the abstract methods in the network message execution class, having each entity maintain a copy of all of the messages and the network message execution class even though they never send or receive most of those messages, or you must add additional variables to your application to store different implementations of the network message execution class for each link between entities.
...I also want to get rid of the ridiculous amount of messages the client needs to implement...
Basically there should only be a single receiving loop that receives messages from the server and checks if the client implements a method to handle the given data. If that's not the case, it could either throw an error or just ignore the message.
Assume we implement a class. That class is for use by the Messaging system and provides the means to transport a Model. Let's call it RelayMessage. The RelayMessage class has two fields, the Model (we need a parent Model!) and a Message (we need a parent Message similar to the Actor Framework). As the RelayMessage is received by the server, it'll do whatever it has to do, insert the Model and send the RelayMessage back to the caller. The caller can than execute whatever is implemented in the Message class.
* I hope that makes sense to you...
So we need to share a couple of classes between server and client:
MessageBase : Is overridden by the client to implement a specific action (Do.vi); The server does not know or care about this! <-- This is actually the decoupling!
ModelBase : Defines the base class of a Model which is used by the RelayMessage (as data)
RelayMessage : Defines a single Message between server and client (with MessageBase and ModelBase as fields)
<Model> : The specific Models which are supported by the server and may or may not be implemented by the clients. Of course the server must know about all Models (not necessarily, but we'll stick to that assumption)
If my guessing is somewhat sane, this should give you a more or less decoupled system, where the server knows all Models. The clients implement the necessary models and define their own actions.
The missing link right now is how to tell the server what to do...
My idea is that the RelayMessage implements a method for each function of the server (we require an implementation of MessageBase for each method, which is put on another field of the RelayMessage). Each method can have parameters and require an implementation of MessageBase from the client (for reply-handling of the client).
Now that I think about it, this can even be used to implement a couple of MessageBase classes that are common throughout all systems and allow for the server to issue tasks without request from the clients... Last but not least, if the server should be flexible and scalable in functionality depending on the client (like the client specified what the server has to do), the server could implement a Messaging system where the client implements the functions, which the server executes (so basically the actor framework, but the actor is on the server).
Now please don't ask me how to implement all of this... It sounds like fun to me, but also like a lot of work
If this post makes no sense, forget it -
You should take a look into this: http://lavag.org/files/file/220-messenging/
It is the first thing that got into my mind while reading this topic. Here is some more information about the inner workings: http://lavag.org/topic/17783-continuous-measurement-and-logging-redone-with-“messengingâ€-actors/
-
On the functions palette go to Express >> Signal Manipulation >> To DDT
Place the function and it will show you which data types can be connected to the offending terminal.
Change your cluster to an array, connect it to the To DDT function and your VI should be executable.
-
1
-
-
Yes, interfaces cannot be instanciated. You can find a good explaination on interfaces & abstract classes here: http://stackoverflow.com/a/1913185
Anyways, you could create your own implementation of ISldWorks in C#, build the .NET assembly and call it from LabVIEW. Depending on what you try to archive it might be easier to stick to C# entirely.


The nightmare that is renaming a class and its folder
in Object-Oriented Programming
Posted
I totally agree. I was actually trying to understand the logic behind the decision, but I guess my text is quite misleading (even for me as I read it again now ).
).
Maybe I don't understand the initial post correctly, but if I have a problem with the SCC, than I would try to fix it. If I cannot fix the problem, I would rather finish the product and live with a complete SCC history that has certain complications (like renames that are tracked as delete/add commits for example), than overthinking my entire software architecture.
Or maybe the initial post is absolutely not related to the SCC discussion but rather to the topic at hand that is "The nightmare that is renaming a class and its folder". In that case the employee might want to rename folders from within the project and fix the SCC in manual labor.