

jdunham
-
Posts
625 -
Joined
-
Last visited
-
Days Won
6
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by jdunham
-
-
I took a short look and was intimidated! Do you have any favorite/recommended tutorials to get me started?
Nothing that you can't Google as well as I can. This one does look useful: https://decibel.ni.com/content/docs/DOC-15025. You'll want search the dark side forums as well.
Like you, I'm much more familiar with the 2D picture control, but this really blows it out of the water, which I think is one of the reasons the 2D control doesn't seem to get a lot of love from NI in terms of new features.
-
Are you referring to test program permission (e.g., modify test plans and calibrate) or operating system permission (e.g., directory/folder and device access)?
I'm not sure if I understand your question exactly, but I was commenting on the OP's idea of implementing test program permissions by means of the operating system permissions.
-
The downside is that it's all controlled through Windows admin utilities.
That's not a downside. This puts the ongoing maintenance of permissions on IT where it belongs. You just document that it they need to control write access to your designated folder. I would probably put it in a folder called <Public Application Data>/Company/AppName/AdminSettings.
Your idea of testing the ability to write before accepting input from the user is very polite.
-
If you want to draw with good performance, the LabVIEW 3D Picture control uses OpenGL which should be using your machine's GPU. The learning curve looks a bit intimidating, but I think once you get going it won't be too bad.
-
 1
1
-
-
You can make it a strict typedef, which will lock everything. I don't think there's a way to lock just some parts.
-
Peter, I've used LabVIEW for a long time and played with various architectures. I'm like Daklu in that I don't think state machines are very good at all, but I do use message handler engines for a lot of code (apologies to Dave if I'm misrepresenting him). Anyway I agree with you that I would much rather send my messages over a queue than the event structure, since if you get into a bind, you can always write code to inspect the queue or change its behavior, whereas you don't have any ability to mess with event structure events until they come back out the other side.
If you looking for a groundswell of support, why don't you set up a poll on LAVA? A lot of people like me probably have opinions but don't have time to compose a detailed thesis, but you can crowdsource us to get what you need.
-
From my experience, auto-scaling front panels in LabVIEW rarely produces good results. I always set the boundaries of my front panel first (in your case you would need to find the parameters that cause the panel to fit the screen for your resolution) and then I start developing the UI accordingly.
Splitters and panes are a big help in implementing resizable interfaces. Basically you use splitters to get one control per pane, and you can control how the splitters move as the window is resized (via right-click options on the splitters). Then if your controls have the "Size Object to Fit Pane" option checked, then they will resize reasonably well. The splitters can be resized to be very thin so they don't look as goofy.
It still takes some effort to get things working well, so don't do it unless you need to.
-
2
-
-
Rant time... (sorry)
Slowdowns! Damn you...
Been tinkering away at a project for about a month now, and the IDE has just gotten slower and slower and slower... Simple wire edits take several seconds to execute. This is LV2010 SP1 32-bit on Win7 (64-bit).
<sorry for yelling> WHAT THE HE..
One thing I have seen intermittently with our large project is that using Ctrl-F in the Project Window to search for VIs by name can result in the system slowing down until LabVIEW is shut down. In this state, most mouse clicks take several seconds, and any time a different window is selected, the Z-order of my open windows is shuffled in a seemingly random way, which takes 30-90 seconds to sort itself out and accept any more mouse or keyboard input.
However it only happens sometimes, and the link to control-F is only suspected, not proven, so I've been having trouble reproducing it for a support ticket. Have you seen anything like that?
-
I've been on vacation and I haven't looked at the VIRegister library at all, but I did want to share how our team stops loops.
All of our code has something like the following architecture, and all loops are stopped by destroying a reference to a queue or notifier, which is a pattern we call "scuttling". It doesn't matter whether the wait functions have timeouts or not, it works immediately and all you have to do is filter out the error (error 1 or error 1122) that it throws. Usually the code is split into many VIs, but as long as you make sure that any queue or notifier reference is eventually destroyed (we try always to do that at in the same VI as the creation), then all the loops will stop.
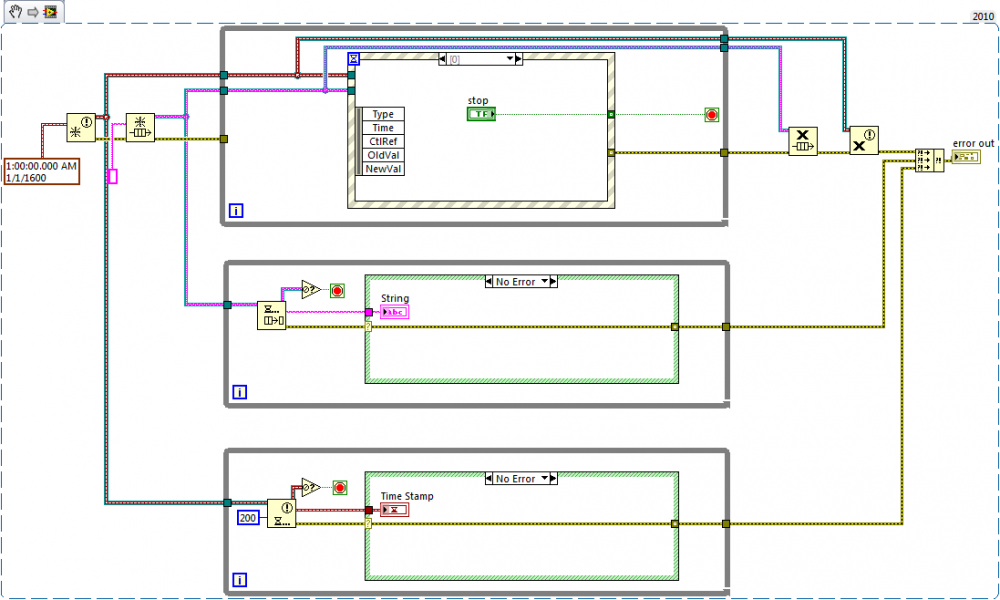
-
(Or maybe not... I'm not sure there's a good business case for putting work into making it easier for competitors to obtain their CLA.)
Well the business case is seeing the forest for the trees. Turf wars over libraries will never help LabVIEW become a mainstream programming language. CLAs should be banding together and working with NI to compete with C# and Java. Part of that work is sharing the libraries that make a bare-bones LabVIEW installation actually productive for large-scale app development. Kudos to all OpenG and LAVA contributors for getting us that far.
I know everyone has proprietary libraries and has a right to keep them, I'm just saying that this is an issue that is holding the whole ecosystem back.
-
1
-
-
in this case though I'm not entirely sure.
The problem is the realtime output is continuous.
So to make a simple semaphore work I would have to:
Periodically stop the realtime task
Release Resources
Release the Semaphore
Reacquire the Semaphore
Reacquire the resources
Resume output
Playback from the file only occurs rarely. So I would constantly have the overhead of releasing the resources and then reacquiring them and 99% of the time it would just simply release and immediately reacquire. I'm not a DAQmx genius (in fact I know very little about it, just the basics) but I have to think that would chew up a lot of CPU time/resources. It kinds seems like polling versus being more event driven.
It seems that even if I were to use a semaphore I would have to use some sort of notifer/event (or something similar) as well to stop the continuous output task so that I am not constantly stopping and starting it.
Hence I was thinking that if I have to incorporate both a notifier and a semaphore that bundling them in a class might make sense.
Am I still making it more complicated or is there an easier solution?
oh and to add another wrench into the works
there is talk of building the part of the program that does playback from files into its own seperate application, which opens a whole new can of worms.
With the caveat that I may not be totally clear on your concept, here are my thought.
You can poll the semaphore to see if anyone else is waiting on it. If you keep the reference open, this is a very quick operation (even if not, it's probably still quite fast). So there's no reason to release the resources from your main process unless you detect that someone else is waiting (that is, another thread has requested the semaphore).
With regard to "chewing up a lot of resources", the processor has to run anyway. Sure, events are cooler than polling, but unless your app is actually not performing adequately, then worrying about polling is not the best use of your time.
If you have to share the resource with a separate app, then I would recommend writing a third app (a driver of sorts) to manage the resource and then have both of your apps request it's service rather than trying to have the apps communicate with each other directly to manage the resource sharing. This may mean you have to expose an API with some of these functions like "tell me whether someone else is requesting the resource."
You can do it all with LabVIEW and build your driver into a DLL, and use CLF nodes, or else you can use VI Server calls into the driver app and it will be a lot like LabVIEW.
Jason
-
Crikey, thanks very much Yair for the post, I hadn't realised that a new reference was called each time (I now see it is written in the help, I just hadn't read it).
I am busy implementing your proposed method at the moment...
Martin, why aren't you using a global variable? I mean, you are using a global variable, just one that is a lot more complex than the built-in version, but appears to have the same functionality.
I suppose if you have multiple places modifying the channel list the queue will act as a semaphore (mutex) but you could just use a semaphore for that.
-
I would like to implement an OOP solution. I'm still trying to wrap my mind around the problem, but I'm thinking about having some sort of arbiter class. It would decide who gets control of the resources....
Any thoughts? Am I on the right track? Would you use a different approach?
Normally to arbitrate a shared resource, you use a "mutex". You can use the LabVIEW Semaphore as a mutex. If one process holds the mutex, any other process requesting it will have to wait until the first one releases it.
I don't see how OOP will buy you anything extra in this case.
Jason
-
If you agree that Tau should be added to LabVIEW, please vote for it on the Idea Exchange.
In the meantime, I have attached a VI version of the constant
 so you can start replacing that other pesky constant right away.
so you can start replacing that other pesky constant right away.For more information, see the The Tau Manifesto
When we say that “π is wrong”, we mean that π is a confusing and unnatural choice for the circle constant.
Happy Tau Day, everyone!
-
Well... you can build an exe that does whatever you want. If that "whatever" is a compiler that generates something that happens to be executable by your hardware, I don't see how that could be a problem.
Well it's a potential problem if it violates your license agreement with NI. The current license has a term that I paraphrase as "you may not use LabVIEW scripting to create a knock-off version of LabVIEW". The OP would be sensible to discuss his intentions with NI and a lawyer.
LabVIEW C Code Generator - http://sine.ni.com/n...g/en/nid/209015
LabVIEW for ARM - http://www.ni.com/labview/arm/
Oh, I keep forgetting about that stuff. Stuck in the past, I am.
-
Hi Paul:
I hope you realize LAVA is not the best source for your answers. First you should talk to NI, since they own the intellectual property in question. Second, you should consult a lawyer. To my knowledge there are no lawyers actively posting on this board, so no one here is qualified to give you advice about how your plans conform to the policies and licenses of NI.
That being said, NI seems to like to control the hardware platform, and is not keen to have other people generate executable code based on LabVIEW diagrams. I'm guessing that you would find it difficult and possibly illegal to target LabVIEW at your own platform without permission and technical assistance from NI. Of course if you can do this in a way that makes money for them and doesn't cannibalize their other sales channels, they may want to team up with you.
Good luck,
Jason
-
I have a repository on a network drive that I created at the start of this project. I am the only person who has ever had a working copy, and I only have 1 working copy on my local hard drive. I commit changes on a regular basis and I dont believe I have ever done a "revert" , it is possible I may have done an "update" at one time but I am not sure. I always make sure that I end each day with all changes committed so I can start the next day "all green".
Currently, everything is up to date in the repository and I will not need to merge, revert, or update so is it ok to delete these merge files?
Yes, I think you could delete them. They came from the repository so even if it turns out that there is something you overwrote and is missing in the current version, you could go dig the older version out of the repository.
At some point if this keeps happening you need to look at what you are doing wrong, because this should never happen with the setup as you describe it. You should be able to do "update" as often as you like, and it should never actually do anything. It wouldn't hurt to do an update right after every commit, but again it shouldn't have any effect. The benefit is that you should find out sooner rather than later if something is screwed up about your setup or your workflow.
Good luck!
-
An example: You modify a file (e.g., save a VI), then ask Subversion to do an update. Subversion will indicate that there is a conflict because your working copy is newer than the checked-in version.
That's not right. You only get a conflict if your working copy has changed and the server copy has also changed independently (you or someone else committed a change from a different working copy). If the OP is the only one using the repository, there is something wrong with his workflow.
Daryl, do you have more than one working copy on your hard drive? There is no limit to the number of identical copies you can check out, and if you change them separately you will end up with conflicts. Can you tell us a bit more about exactly how you are modifying and committing files?
-
Hi Jason,
Is there some way that I can contribute to a new release? If I moved through the code and replaced the lagacy with the new function, could I then submit the code for you guys for a release? Seriously, I do a LOT of work with TS and these formatting tools, and if I forget to overwrite this library Iget phone calls late at night!
Jed
I was actually talking about my own code, but I'd be glad to contribute it to the OpenG too. This code handles the Waveform data type, checks if it is a timestamp, and formats it in an ODBC-complaint string. The other thing I would say is that it's important to store the string in UTC rather than the local time zone,. My code doesn't do by default, but it could be fixed, though if I remember correctly this was harder to do in previous versions of LabVIEW and the toolkit probably needs to be 8.0 compatible. I'll try to get my code together later today.
Jason
-
Could it be something like a global variable?
Could the diagram be off-screen, like on a second monitor that's no longer around?
Is Menu->Window->Show Block Diagram grayed out?
Is there a Windows task bar item for the diagram?
Is there a Run arrow in the toolbar?
Under the File menu is control-i the shortcut for "VI Properties" or "Global Properties" or something else?
-
I'll try to save the architecture-related questions for later, but how would you build a large application without (or with as little as possible) parallelism, or in such a way that byRef objects don't end up being used everywhere?
My first few LabVIEW apps were not parallel. I used plenty of subvis, so it's wasn't bad spaghetti code, but I very quickly ran up against difficulties making the apps easy to develop and maintain. I don't think that a big software system that accomplishes many things and is not frustrating for humans to use can be mapped into a straight dataflow model containing nested loops and cases. It would be nice, but I don't think it's possible.
As Daklu said, attempting a monolithic program like this will increase the coupling between your modules and makes the app harder to build and maintain.
-
1
-
-
Bit bucket looks cool because I can have issue tracking, wiki and all kinds off cool features that are web based. Great for customers, no installations, and I can manage this easily.
I've been using WebFaction. Bitbucket is free for 5 users, but when you start to add more users, it quickly gets more expensive. At webfaction, you just pay based on disk and bandwidth usage, so the minimum account should be plenty.
Here's a link with my referral code. If you use it, I'll donate anything that comes in back to LAVA.
-
As ShaunR pointed out, 20000 points are too much to display - simply there are no monitors with that many pixels.

Furthermore, the human eye will see as continuous anything refreshed faster than 16 Hz, so it's pointless to update the display at any faster rate than that - it's simply a waste of time and valuable computer resources.
Except for very display sensitive applications (multi-media, simulation and very few others) simply just use the most practical method to display for your case (refs, sub-panels, queues, globals, functional globals, etc., it depends on what you're doing and how), decimate data AND updated displays only every 60 msec - 50 if you really cannot settle for less - but even 100 msec should be enough.
That being said, LabVIEW graphs have excellent decimation where they can take 20,000 points and draw them on a graph that is better than simple decimation, tending to favor the outliers. I would only try to improve on this if you are having a real performance problem, and I would first slow your update rate down before trying any fancy footwork with the dataset.
-
1
-
-
I am using version 7.0 for SPARC. There is no graphical compare available for this version I am aware of...
Oho, very interesting! You started this thread with a rather intriguing philosophical question, but now we've drawn you into admitting that you're stuck in a specific situation because some business externality is forcing you to use 8-year-old tools? I mean, even if NI came up with a textual representation, you'd still have to upgrade to use it.

Strategies for implementing station admins?
in LabVIEW General
Posted
I think I agree that those should be separate, but you should leverage the OS infrastructure to implement the test program permissions.
If you use your own password system, it's totally insecure. The OS people put tons of work into a secure infrastructure for authentication, and you can't really hope to compete with that. Once two people need to know the same password, they are going to write it down, usually on a post-it affixed to the monitor, or if they want extra security, they will tape it to the back of the monitor!
It's much better to use per-person authentication and the assignment of roles, rather than just having an "admin" password. If some person is fired, their access to your test system will cease as soon as IT shuts off their login. If IT is too slow to change users' test program roles when needed, they can give local supervisors a limited admin role on those folders and control the access, but it's still all done on the OS side. All of this comes for free and all the developer needs to do is set up the roles.