

Ton Plomp
-
Posts
1,991 -
Joined
-
Last visited
-
Days Won
38
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Ton Plomp
-
-
Hello Randy,
you're more than welcome to participate with OpenG.
Currently Jonathaon Green is the lead developer of OpenG, so you can send him a direct message if you want some 'tasks'.
For instance you could have a look at the bugs posted at sourceforge, and see if you can tackle them (I advise you to take a SF account in the process as well).
Another way to participate is to go over the proposals in the OpenG forum, and give your opinion, try to find weak spots or improvements.
If you have code you feel is general enough you can add that to the proposal forums as well!
Ton
-
 1
1
-
-
There should be some Terms and Conditions for uploading, however that won't solve the issue.
One way is to use the Code Capture Tool for your uploads and customize the header, and the embedded meta data to include some sort of copyright/licensing.
Yes, I know it's not easy to see the embedded meta-data, but that doesn't mean it doesn't exist and isn't valid.
There are special fields for copyright and disclaimers.
Ton
-
I think that th OpenG sourcebase at sourceforge has the utilities you look for.
Most likely this folder.
Ton
-
Yep, the Instance close? filter event is the right one.
If you don't close withing N seconds, the user will be shown a 'This app is not responding, end now?' function.
What was the reason you didn't directly looked for this event?
For future references, here's a snippet of the event.
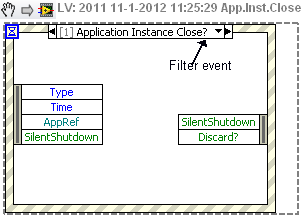
Ton
-
1
-
-
Recently I realized that I'm starting to use the conditional for loop more and more as an 'Error' catcher.
I try to come up with the number of possible resolvers for an error situation, and run these in a for-loop, as soon as any of these resolvers, resolved the issue, I exit the for loop.
One example is found in LVDIFF2, where Mercurial outputs mixed paths (using / and \ as path separators), in for different states I try to fix this path:
- Use a standard string to path function
- Use a function to read a linux path (only / separators)
- Use a function to replace / with \ (works on Windows)
- Use a function to replace \ with / (works on Linux/Mac)
After each iteration I check to see if the created path actually exists, and exit the loop if the path is found.
If the path is not found at all the code will fail, but at least we tried the best we could.
Here's a snippet (with screenshots) of that section:
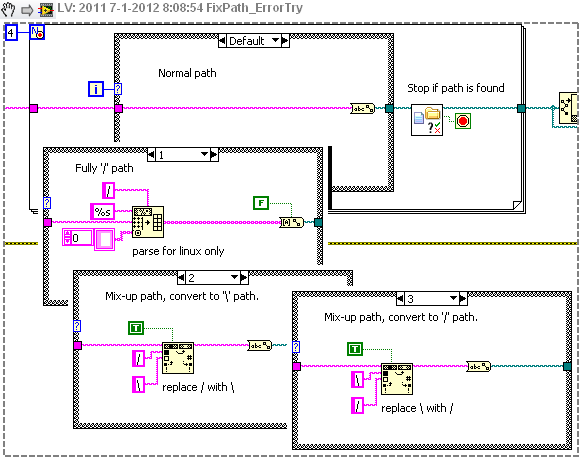
Is anybody else using the conditional for loop in such a way?
Other alternatives could be using an array and auto-indexing to limit the number of iterations of the for loop.
Ton
- Use a standard string to path function
-
Hello MrMike,
sorry to hear that it's confusing you. I can understand how that happenend. Currently I am resaving the library for LV2009, and I'll look at your comments and incorporate them in the code.
Ton
-
- Popular Post
I've never used it, but I've seen rabbit MQ code in Python and LabVIEW as well.
RabbitMQ is a message broker, so should be able to bridge the gap.
Ton
-
3
-
I start to use more-and-more the 'quick reply' editor below a thread.
The only time I switch over to the full editor is when I want to add an image with code.
I'm not sure if it's possible (I think it is), but adding the 'attach files', is a good addition to that reply 'window'
Ton
-
One of the mayor ups for our company is the possibility of adding meta-data (descriptions), these can be very flexible and extendible.
By configuring the DIADem data finder, you can harvest these meta-data like a database.
One of the downsides is that we had several cases of bad tdms-indexes. Those are really hard to nail down, and we never got a good explaination. It probably comes from the fact that you'll only copy the tdms file without the accompanying tdms_index file, and you can get a mix up of various data-formats, the solution is always easy: delete the tdms_index file (it will be auto-generated again upon opening the file).
There is a discussion of HDF5 vs. TDMS, from what I remember is that at the moment of development HDF5 wasn't fast enought for single-writes.
(Idea-exchange link, but there should be more)
One thing that I like of TDMS is that it limits you to groups and channels, one way or another it's always been possible to store the relevant data in that structure. But I would love to have (at least) 2-dimensional arrays.
Ton
-
Nice idea (I had written a similar tool just a few months ago).
I remember two bugs/issues.
- DIAdem is quite strict about the allowed characters for property names, '.' (period) is not allowed. Upon resaving the TDMS file the period will be replaced by an underscore '_'. (the list is quite long).
- A boolean is stored as an U8 after a resave with DIAdem, the TDMS routine of LabVIEW can read the boolean, if they receive an explicit boolen. However if they receive a variant with a boolean as data-type, the returned variant is an U8. And a variant to data function will fail. (your code has a specific case for each data-type so it will not break).
One thing about your code, why don't you use the VI reentrantly? By allowing 'Share clones', you can drop the VI strait into itself, without the need of explicit VI-server calls.
Another addition would be to have basically the same code for waveform attributes (I have that around as well).
Ton
- DIAdem is quite strict about the allowed characters for property names, '.' (period) is not allowed. Upon resaving the TDMS file the period will be replaced by an underscore '_'. (the list is quite long).
-
One of the things that needs to be done is have good unit -test VIs.
The current set I have is created by the NIST and is very thourough. Currently all the functions pass these, however I need make that a single-test routine (running about 5-10 minutes).
Ton
-
Yes, back on topic...
So the 'hamming distance' is that it counts the non-zero characters?
Perhaps any of these implementations are faster:
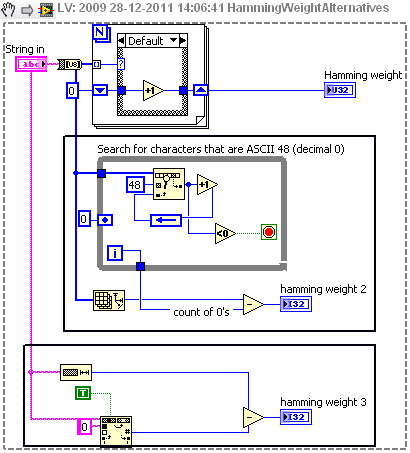
Ton
-
Hi Wouter,
that looks nice, I think we should include it in the MD5 package (together with the SHA hashes I've created).
However I would use an array of U8 instead of U32.
Ton
-
One standard that I try to follow is that every time I use a for loop with auto-indexing, I show the label of that for loop and add a 'for each .....' title to the for loop. This has helped me greatly in getting back after a while to the exact 'why is this for-loop auto-indexing' questions.
-
could it be that the 'Exit Indicator' is True so that the while loop only runs once?
Ton
-
I can see the package. One thing to note is that the company name is 'Openg_org' instead of 'Openg.org'
Ton
-
Name: HTML Report Embedded images
Submitter: Ton Plomp
Submitted: 17 Dec 2011
Category: *Uncertified*
LabVIEW Version: 2010
License Type: BSD (Most common)
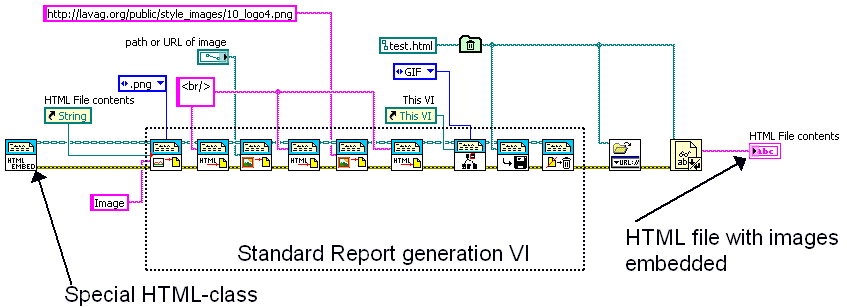
This class adds a special version for the HTML-report generation VIs.
By using this class you can use the normal report generation functions, however images will be embedded in the HTML file inside the <IMG> tag.
This tool adds a special override class for the Report Generation toolkit. With this class come 3 overrides for the following functions:
- Append Control Image to report
- Append Image to report (path)
- Append Image to report (string)
These functions allow you to embed the added image into the HTML IMG tag. With this functionality it's possible to generate HTML reports that can be shipped without depending on a file-layout or web-server.
The included DEMO VI shows you how to use this class (only the initiate function is required), and loads a sample file into your default web-browser.
Click here to download this file
This tool shows absolutely the power of LVOOP programming, in 1 hour I made a inherited class that overrode 3 VIs and thus created new functionality!
I hope you like it, if you have more ideas for improvement please let me know!
This function usese the Base64 code from ChristianL
Here's the full screenshot:
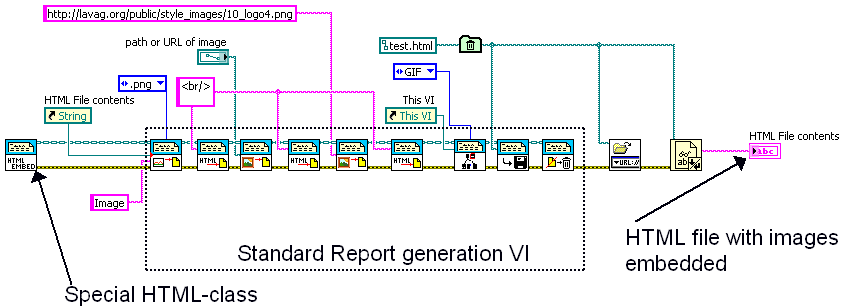
-
1
- Append Control Image to report
-
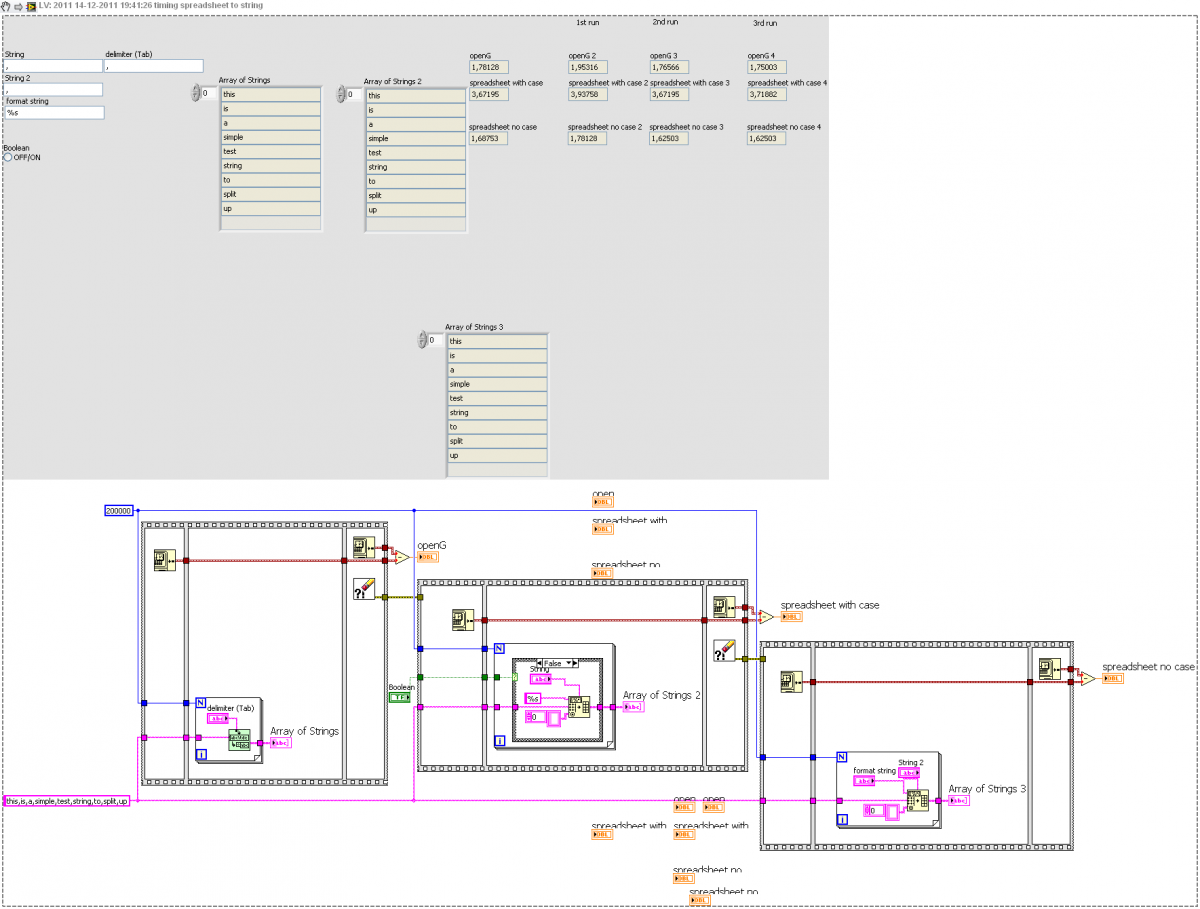
Well today my computer is even slower.
Here's a snippet with the 1st-5th run on the FP stored.
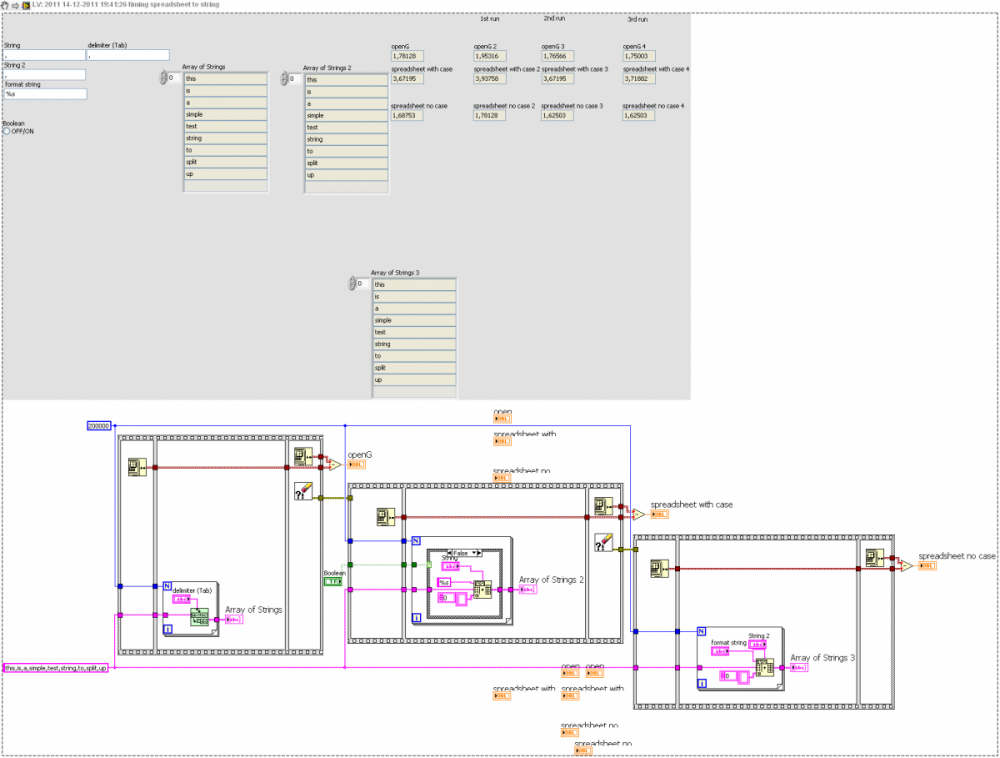
Ton
-
I'm not sure if this is a bug. You unregister the ERF, and then you use the same ERF to register new events.
Here's a quote from the help:
Event structures which use this event registration refnum no longer receive any dynamic events.
So it sounds like it's a dead ERF...
What really buggy is that it locks up the UI whenever I click one of the buttons.
Ton
-
Your method of testing is wrong, for instance the native version only takes 0 ms, this is so because the code is compiled and the result is stored in memory.
By replacing all the inputs to control I got the OpenG twice as fast as the the 2nd (with case structure function):
Ton
-
The files should be installed into:
user.lib\_openg
Have you installed the dynamic palette library?
Ton
-
You should be able to install the libraries with VIPM, just like on Windows.
So you'll need to take the following steps:
-Connect VIPM to LabVIEW with the correct VI-server port
-Select the correct LabVIEW version
-Select the packages you want to install, and select install.
Ton
-
For that amount of timing you need to use something like an RealTime environment.
Ton
-
There is to the client no difference where the repository is hosted (as long as there is a reliable internet connection), there might be a speed issue.
Every hosting provider has there own set of tools for managing repositories.
Ton
Using Subversion for distribution and versioning
in Application Builder, Installers and code distribution
Posted
If you are going for using a version control system (VCS) as a deployment server I would advise Mercurial or Git (distributed VCS or DVCS).
You would setup a deployment server that only the author of the tool has write access.
The author would setup a development server for his hour-to-hour checkins/commits (Save early, save often).
When a release is ready you'd push the changes to the deployment server.*
On the end user's side the toolkit is installed with 'hg clone http://mercurial-deployment-rep'.
Periodically, you can use 'hg incoming', if there are incoming changesets you'd use 'hg pull -u' so that the working copy (visible files) are updated.
If you setup the deployment server as a HTTP-server you can also allow the server to have a zip/tar as a single download of the current state of the project (so the client doesn't need Mercurial installed).
Now for user engagement a DVCS is particular practical, the end user would pick up bugs and improvements and save them. If they want them to be fixed on the deployment server, they would commit them to there local repo, and publish them somehow (via http, file) to the developer. The developer would look at the changes and accept them (or not). That is a superb way to have your users committed. Such services are provided by commercial hosters like Bitbucket of Github)
Ton
*If you don't want your users to know the history between the releases you could setup the rebase extension, that pushes the different changesets as a singel changeset.