

John Lokanis
-
Posts
798 -
Joined
-
Last visited
-
Days Won
15
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by John Lokanis
-
-
Are the NI Week 2012 vids gone? I was looking back (after showing some of the new ones to co-workers) at my collection and wanted to grab a few more but they appear to be gone.
-
thanks for the explanation. I suspected something like that but now it is more clear to me. Always good to understand what is going on behind the scenes.
I read somewhere that the compiler will try to parallelize the for loop even if you don't turn on loop parallelization. If that is true, the main reason I can see to turn it on is to have the IDE detect if the loop is not parallelizable based on its design (like iteration-to-iteration dependencies).
One place this can bite most people is passing something through a loop using a shift register. In the past, I am sure we have all made the mistake of passing something through a for loop without using a shift register (simply using tunnels) and having the data on the wire get lost because in one situation the for loop executed zero iterations. Once you get bit by this, you learn to always use a shift register to prevent that data (perhaps a reference or something that does not get modified in the loop) from being lost. But this then makes the loop un-parallelizable (is that even a word?) because the shift register implies that there can be an interation-to-iteration dependency. The better design is to branch the wire before the for loop and send the new branch on to later functions, letting the other branch that enters the for loop die there. This of course causes a data copy and we have been taught to avoid those when possible. But, in this case I think it is the best solution if you wish to take full advantage of loop parallelization.
Did that all make sense? Or am I off in the weeds on this?
-
I was not really trying to benchmark anything. I actually came across this when trying to determine if turning on loop parallelization was worth while in a separate project. I have a broadcast method that sends a message to multiple listeners. It does this in a for loop (looping through the various transports and putting the message on each one).
I added some code to time when the message was received at each destination. I then compared the times. After that, I turned on parallelization in the for loop and ran it again. From what I could see in this limited test, there was no noticeable difference.
That is what led me to the VI posted here and the observation I made. I know that the OS gets in the way and messes things up. This is quite clear if you run my VI multiple times and see the varying results. I was mostly just curious to understand what was going on behind the scenes that could explain the patterns that emerged. The randomness can be explained by the OS but the patterns seem to indicate some underlying behavior. I read a bit about 'chunking' in the LV help but am not sure if that is what I am seeing in the patterns.
Anyways, just some curiosity, that is all. At least I have learned from this thread that posting VI snippets is a bad idea...
-
I don't think asking for code is bad, or wrong. Code samples are good at showing how to do things. Theory explains why you do things. My presentation focused on the theory, so code samples kind of distract from the message. (FWIW, I'm far less concerned about showing the how than I am about explaining the why.)
How about creating examples of how to use Actors to solve common programming challenges or implement different architectures without using LV code? Instead use pseudo-code or maybe simple block diagrams to illustrate what actors and messages would be created to implement the solution. You should also include some diagrams that shows both how the parts interact and how they are (or are not) coupled together.
No need for LabVIEW code since your discussion is about theory and not G programming tips and tricks. If you can give your presentation to a Java or C++ programmer and they understand it, you have done your job.
-
If you have multiple processors, as most machines do these days, they really are parallel.
Yes, with multiple CPUs, you get some parallelism. The interesting thing is how you sometimes get a jagged line as some elements that come after others were created earlier in time.
I expected more of a staircase effect where the first 4 elements (I have 4 CPUs) would have the same time-stamp and the next 4 would have a later time stamp, and so on. It appears that instead the compiler is breaking the loop up into sections of some predetermined length and then giving those sections to different CPUs. The length of the sections also appears to decrease with each iteration of processing as the jagged line become less pronounced as you approach the end. It also appears that the processing on each CPU does not start at the same time but is rather staggered, as if the sections were determined and the first CPU started working on its section while the second section for the second CPU was still being handed off for processing.
Adding the 0ms delay did allow the CPU's processing to line up, or so it appears.
This is, of course, all conjecture from just observing the output. I just found this very curious.
Bjarne: I've heard -- but have not confirmed -- that some of the browsers have stopped moving the meta information for some reason -- security, I think, with people doing things like, oh, embedding runnable code in the meta data... like LV is doing. ;-) Try saving the PNG to disk and then add it to your diagram.I have tried dragging the original PNG to a LV diagram and it generated code just fine. But saving to disk from LAVA and doing the same did not work. So, the stripping might have happened on my end (using Chrome browser).
Here are the VIs, FWIW.
-
Just playing around with loop parallelization (sp?) and the hi-rez tick counter. I got some interesting results. Looks like loop iterations can execute out of order (parallel loops are not really parallel (of course) since the CPU must serialize them at some level)
Not sure if this is all that meaningful but I found it interesting. Here are some code snippets to play with.
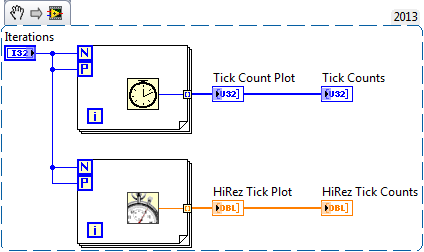
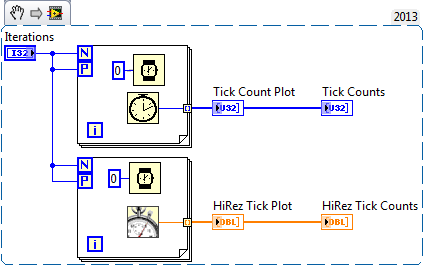
-
I agree with James that there is no universal "better" answer. However, I prefer the first solution and believe it is more robust. To expand a bit on what James said, solution 2 presents some difficulty exposing read-modify-write operations through the public api. In addition to the normal data access methods, the class has to expose some sort of mutex (lock/unlock) functionality to prevent other threads from overwriting the data between the read and write operations. The IPE structure is the safest way of mutexing data access; why make it more difficult for users by taking that option away from them?
By default all my classes are as by-value as I can reasonably make them. If I start with a by-val class I can easily create by-ref or singleton behavior by dropping it in a DVR, or global, or whatever. But, if my class starts out as a by-ref class I can't go backwards and use it someplace where I need a by-val class. And if it starts out as a singleton, I can't use it as either a by-ref class or a by-val class. Keeping my core functionality in by-val classes maximizes the ways I can use the functionality the class exposes.
I don't disagree with this but my point was the use of property nodes to access data in a DVR wrapped class (via their accessors) opens you up to the same race conditions that FGVs (with only get and set operations) have. So, whenever someone says how cool it is that you can do this, I think 'yeah, but what about read-modify-write issues?'.
Of course you can use the IPE structure to unwrap the class and safely use its methods to modify class data, but that is not using the property nodes.
I do use DVR wrapped classes to implement singleton objects, but I am careful to only use the property node feature to read current value and not read-modify-write.
I suppose you could pull some tricks to overload the read accessor to modify the data (ex: increment a counter) but I generally would consider that a bad practice.
But, if your goal is a "GLOBAL" then that implies 'by-ref' to me and therefore the better choice for replacing a FGV with a class that uses a DVR is to put the DVR in the class private data and protect it with methods for access and modification. I just don't see the point in making something you intend to be a "GLOBAL" have the ability to be a by-val class.
That said, I complete agree that if you are making a class that might be used by-val or by-ref in the future, then wrapping it in the DVR for those by-ref cases is preferable, as long as you keep the property node race issue in mind.
Now, if only we could wire a DVR wrapped class into an invoke node to access the class methods, we could do some cool stuff!
-
Nancy also mentioned the use of DVRs as a replacement for FGVs and AEs. There are two ways to make an LVOOP DVR FGV. One is to create a class with methods that operate on the data and then wrap that class in a DVR. The other is to create a class that has a DVR in its private data and then create methods that create the DVR, access the data in the DVR and destroy the DVR.
My question:
Which one is better? Which one do you use?
One 'feature' she pointed out was if you wrap a class in the DVR, you can wire the DVR to a property node to use the accessors, This seems cool at first but don't you just introduce the same race conditions that the old get-set FGV had in the first place? After all, wiring a DVR wrapped class to a 'read' property node is simply a 'get' and wiring it to a 'write' property node is a 'set'. The operations you do in between are unprotected.
Given this, I would argue the the second LVOOP DVR FGV implementation is the better choice. If you still want to wrap the class in a DVR, simply do not make any 'write' accessors and force the writes to happen in methods that use an inplace structure to protect the data.
-
Dev Suite DVDs arrived in the mail today! Now to go install all the add-ons...
-
I have been immortalized in the LV2013 release notes!

I am so glad they added this. Although I think it is more because I kept calling support and asking them what each installer did what and when it was needed. I was amazed that the top-tier test support guys didn't have any more clue than I did. I'm betting this feature alone reduces the number of calls they get in the future.
-
 1
1
-
-
Did the download include a new features list?
If so, could you share it here?
Try this:
-
Oh well. I guess I missed it the first time. Guess my search terms were lacking before I posted this.
-
Oh, I would not be switching to LV2013 yet either if my project was near completion. But in this case, I do not expect to be ready to release until well after SP1 comes out.
For me, there are many compelling features in 2013 that I want for this project. Including the new web service features and the improvements to .net calls.
Getting this tree control speedup is just a bonus.
In the past I have always waited for SP1 before updating my projects. It is actually kinda fun to be able to jump in the pool early this time.
As for upgrading my tool chains, that took all of 20 minutes to install packages from VIPM, copy reuse code, recompile and save everything. The only 'bug' I ran into is the new rule that a shared clone cannot statically link to an Application level event. Not sure why this is but the workaround was fairly painless to implement.
-
I too have jumped through many similar hoops over the years. But you need to embrace change!
Think of it this way: the code that drew the colors when scrolling will just run 10x fast now!
-
1
-
-
This is cool both visually and auditorily.
enjoy!
-John
-
Just ported my project to LV2013 (livin on the bleeding edge!)
I am sure to find many cool new features and improvements but I thought I would share one with you the jumped right out at me:
The Tree Control is 10x faster!

(At least, when I am setting cell colors on multiple rows while updates are deferred.)
In my example, it was taking 4-5 seconds to do the update for a few 100 rows in LV2012. In LV2013 it takes less than a second.
This will be a big improvement for my GUIs. So, thanks to the engineer(s) who worked on this!

I wonder if this is specific to the tree control or if other UI processing is also improved?
I will report back with more finds but please add your own to the thread.
-John
-
1
-
-
Activation appears to be online now. I just got mine to go through. Try it!
-
1
-
-
Even the original application (now over 10 years old) uses a plug-in architecture. (LLBs created with OpenG Builder). But it is time to move on and try new and (hopefully) better things. So, I will give PPLs a whirl. But I can always fall back to LLBs if it fails. But that is a whole different can of worms I will solve later.
Maybe I should call this a dynamically distributed plugin architecture!

-
At this point I am thinking of using a PPL to store the prompt and it's support files. That way, I should be able to just send the PPL across.
On a side note, I am playing around with reading a VI file into LabVIEW and then writing it back to disk in a new location. (I will need to do this because I need to send the file over the network, regardless if it is a VI, PPL or ZIP.)
For some reason, LabVIEW does not want to open my new copy of the VI, even though it is an exact byte by byte duplicate of the original (verified by comparing the file data in LV and with WinDiff). So that is not good.
<edit: nevermind. forgot to turn of convert EOL. works fine now>
-
Now we are getting off topic, but the reason to split the current system is because having the UI tied to the engine that executes the plugins means that for each instance, only one user at a time can access and control the machine. By splitting them, the client application can view sessions from multiple servers at the same time. And multiple clients can view sessions from the same server. I can have one server for everything or I can have N servers as demand increases. And I can have N clients using that same server pool. I can also have clients view sessions based on criteria besides what server they are executing one. With the current system, you can only see the sessions on the server you are viewing since the UI is hosted by the same application that executes the plugins.
The best analogy I can think of is a web server and browser. The current system would be equivalent to having the web server and browser be a single EXE. To view the web page, you would have to log onto the machine running this exe and while you were using it, no one else could. So, to view a web page, you would need to give each user their own server/browser application. Also imagine that while the page is being viewed by one exe, it cannot be viewed by another at the same time. The new architecture separates these functions but the server still needs to serve up some UI information at run-time that the client cannot have prior knowledge of. Ideally I would prefer to have the flexibility of having the UI information be a fully functional VI. That way I am not limited in the future to what my prompts can look like or do. But, if that is impossible I might have to make a generic prompt and simply push configuration info from the server to the client.
I have tried to keep the problem description generic because the point of the thread was to find a way to dynamically push a VI to another machine and run it. That seems like something that would have more applications than just my current design.
So, not concerning yourself with my motivation, does anyone know a good way to send a VI (actually a hierarchy of VIs) from one LabVIEW EXE to another and execute it at run-time?
-
Unfortunately that is not an option for me. The client needs a lot of custom code. It needs to manage multiple servers at multiple sites, shared views and access control for multiple clients viewing the same server session, database recall of historical output, etc... The client is actually more complex than the server and has just as much parallelism if not more than the server. So, LabVIEW is a natural fit. I would need a whole team of Javascript devs to attempt to reproduce it.
But thanks for the idea anyways.
-
I am trying to think this through and see if it is even possible. I can think of a few possible paths to go down but am not sure if either will work or if there is a better way.
The goal:
I have two application instances running on two different machines on the same network.
I want a VI that is part of application instance A to be displayed and executed in a sub-panel of a running VI in application instance B
Why?
Well, I am splitting an existing application into two parts. A server and a client. The UI is hosted in the client running on app instance B. The Server is running on app instance A. The server executes a set of plugin modules. Some plugins require a custom prompt to be displayed to the user. In the old system (all on one app instance) I could pass the plugin a handle to the sub panel in the UI and it could insert it's prompt VI for the user to see and take an action. But now that they are split, I cannot do that anymore. The plugins are created outside of both the server and the client applications so they do not know what the prompt will be until run-time.
Option 1.
When I update the plugin libraries, I need to push a copy to both the server machines and all client machines (already this seems like a bad idea). Then, the server can simply tell the client what prompt to load, display and run. I would need a mechanism for the prompt to send its data back to the server plugin. And there would be a lot of unused files on the client side since it only needed the plugin prompt VIs and their sub vis.
Option 2.
When I need the client to display a prompt, the plugin would determine the local path to the prompt VI and to all of it's sub-vis (this is not too hard) and then it would load the binary data from disk for each of those VIs, send it over the network and on the client side, save it to a temp folder. The tricky part would be to re-name (using some temp pre/suffix) the destination files and re-link them together (no idea how to do this but I think it is possible). Then the plugin would tell the client where to find the prompt VI locally to load, display and run. I would again need the prompt to message the server with it's output once the user responds to it.
This option, while complex, seems like the best way to go. Since it is similar to building a source distribution, I am hopeful there is a way to do this. I just don't know how.
Option 3
I can't think of another option. Any ideas?
Thanks for reading. This one has me a bit stumped.
Oh, and all this needs to work under the run-time engine so no scripting allowed!
-John
-
Certainly only top men have this problem. Top. Men. (Those who do not get the original reference should at least get the Family Guy homage)
Good catch. Never type while mad. I should have done a better job proofreading..


(we really need a :facepalm: emoticon on LAVA)
-
From what I could tell, we were *supposed* to see the focus row be correctly set while editing in 2013, but from my preliminary tests, it appears to still be a problem in 2013, and will thus still require the programmatic workaround.
I'm ok with that but will the Focus Row property be public?
Feedback Requested: Daklu's NI Week presentation on AOD
in LabVIEW General
Posted