Samapico
-
Posts
35 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Samapico
-
From what I understand: Yes, but the typedef will be considered as 1 field, so if you load a previous version, the data in that typedef'd cluster will be entirely replaced by the new typedef with default values. That is, "unless the data can be directly converted", which I assume means that it will work if you just change the numeric representation of some of the values in the typedef. The same thing would happen if you had a numeric field, and you changed its type. If you change its type to another numeric, it will be able to properly convert, but if you change it to a string, your previous versions will be loaded with the default string value. Edit: Oh yeah, I'm now "Active".
-
I didn't know there was a place to post these on LAVA... I posted an idea that you OOP guys should like: A simple "New -> Child Class" menu item in the context menu when you right-click an existing class... Idea link
-
That would definitely be interesting... if the only reason why typedefs don't carry a mutation history is because the class isn't always loaded as you change it, then it would be good to implement it for typedefs that are part of a class, indeed.
-
I've read the term quite often on here, but never really wondered what it was about. I just did a quick test to confirm what I thought... If I get it right, it means I can save an object to a file (Write to Binary File), and even if the private members (and the class methods, I presume) change, I'll still be able to load that object back with a simple 'Read from Binary File'. I'm guessing clusters (and other typedefs) don't have that feature, since we have a lot of trouble with super-clusters of parameters that keep on being updated as the project goes... We need some very complex auto-update of that data, which is painful to maintain, quite unreliable and annoying. So if I get this right, I could simply use a class, and even if I load an old object from the disk, all the members that disappeared since then would be simply be ignored, and the members that were created would simply be set to their default value? That's... like... black magic, man I'm also guessing saving/loading an array of these doesn't matter either? Also, if typedef'd clusters don't have that ability (I say 'if' cause I'm not sure), what would happen if a class has several clusters as members? What happens when these typedefs are modified? Edit: Just read this http://zone.ni.com/d...a/tut/p/id/6316: "LabVIEW, as a graphical programming environment, has an advantage over other programming languages. When you edit the class, LabVIEW records the edits that you make. LabVIEW is context aware as you change inheritance, rename classes, and modify private data clusters. This allows LabVIEW to create the mutation routine for you. LabVIEW records the version number of the data as part of the flattened data, so that when LabVIEW unflattens the data, LabVIEW knows how to mutate it into the current version of the class." Pretty much confirms what I thought... still unsure about typedef'd clusters within a class, though. Edit2: After reading the entire thing, I don't think I have any questions left I guess I'll just reiterate how cool this is, and how I'm a little pissed that I didn't know about this before... would have saved me a lot of trouble...
-
Well, I'd have to do some more tests, cause what you see up there was actually called twice from a VI (in parallel), and the result of both calls was thrown into another similar nested for loop. So I'm not sure which loop was creating the problem. Note that the array in there was about 2500x2000 (from ImageToArray), so I guess it takes quite a lot of data before it gets confused. SuperS, that's a good point you have there... but I'm wondering, does it really take the number of processors, or does it take the value you give it in the 'Configure iteration parallelism...' dialog? These 2 information seem contradictory :/ But either way, I guess it makes sense that it doesn't add any efficiency anyway.
-
I have a parallelized For Loop within another parallelized For Loop to quickly process a 2D array. This is in a reentrant VI that is called twice "at the same time" (nothing guarantees that they run at the same time, but they can execute in parallel with the way they are wired in the caller VI) It seems to be causing random issues... some of the output is set to 0 randomly... these zeros seem to appear by chunks, so it seems related to the loops not working correctly. I was always feeding it the same data and the output was changing. Did anyone ever noticed these issues as well? I'm having trouble reproducing it reliably though. I disabled the parallelism of the inner loop, and my output was fine, then I re-enabled them and it's still fine, so I don' t know if it has to do with the modifications being in memory or whatever, but yeah...

-
Well... you can build an exe that does whatever you want. If that "whatever" is a compiler that generates something that happens to be executable by your hardware, I don't see how that could be a problem.
-
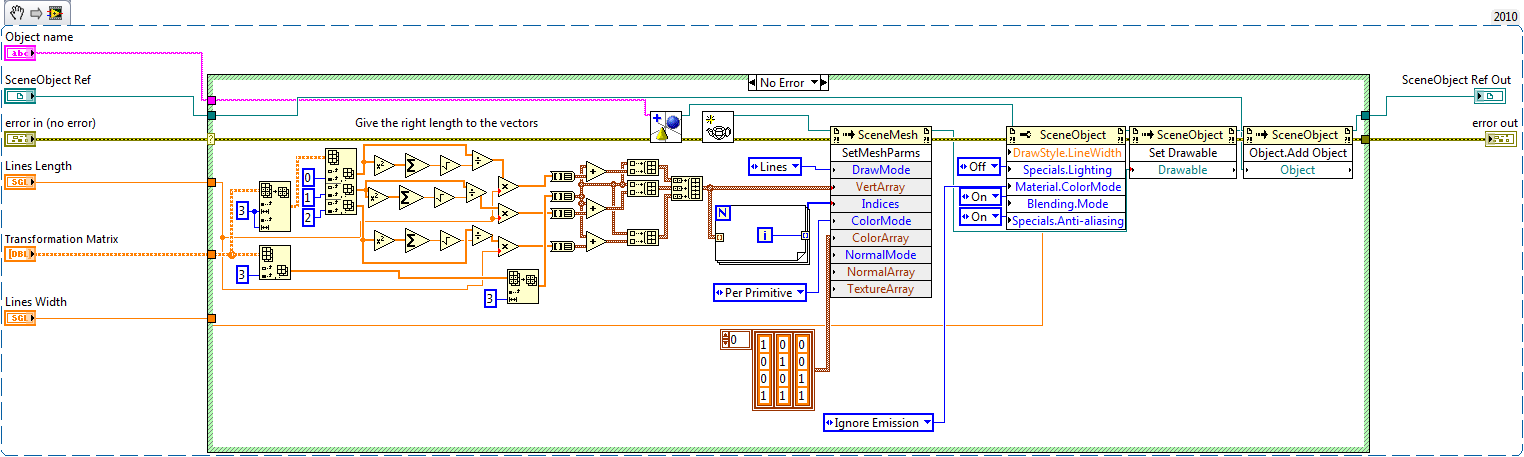
I have a VI that does exactly that. Feed it with your global scene object, and it will add 3 axis in it. By default it puts them at (0,0,0), but you can specify a 4x4 homogeneous transformation matrix to where you want it. If you never used these VI snippets: Drag that image on your desktop to save it as a .png file, and drag the file in an empty block diagram. It will automagically create all the code for you.
-
Thanks for the links... I'll look into that......... and probably ask more questions then
-
This might be a first of many topics / posts I'll make in the future, since we're starting to prepare a complete rebuild of our software platform... The current one is in LabVIEW, but it's pretty ugly... Nested .lvlib's, hundreds of global variables without any control, a lot of duplicated code... Now that we acquired more skills and experience with LabVIEW, and that our requirements are clearer, we can/want to build something that is upgradeable, modular, flexible, etc. The beast is pretty huge. It's an inspection system that uses an industrial robot. So we have cameras, IO modules that communicate with the robot and other stuff, inspection algorithms and filters, threads that control the overall sequence with the robot and inspection threads, etc. I read a bunch of topics in these forums about OOP and architecture in general, and from what I understand, LVOOP byRef should be avoided, unless necessary, since it's kind of opposed to the nature of LabVIEW. However, I can't imagine our platform without a lot of parallelism, and parallelism doesn't make sense to me with byVal objects... I'll try to save the architecture-related questions for later, but how would you build a large application without (or with as little as possible) parallelism, or in such a way that byRef objects don't end up being used everywhere? Ideally, we want (mostly) everything to be as modular as possible (possibly dynamically loading stuff as plugins, but that's beside the point) so that a module responds to events, and generates events that the other modules "catch". However, modules will often require data from other modules, and if many modules require data from one module, how can you get that data by value? My guts tell me that byRef classes would work wonderfully, but at the same time, it's probably going to lead to some bad programming habits, or bad design. This is probably pretty vague, and some parts might not make sense, but I don't really know where to start myself. I'm hoping that your guidance will at least make me ask the right questions Anyway, thanks in advance