
GregSands
-
Posts
264 -
Joined
-
Last visited
-
Days Won
26
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by GregSands
-
-
Check out the LabVIEW Multicore Analysis and Sparse Matrix Toolkit which has multicore replacements for FFT and many other matrix functions.
-
 1
1
-
-
I'm guessing there must be more to your question, but based on your specs, I'd be asking whether it was worth spending time and effort deleting a relatively tiny part of a file. 100k out of tens of GB? I'd just leave it there and work around it!
-
Aside from what is in the Help, I don't know how the Threads option works. From what I can tell, it does not seem to have much (any?) effect inside a parallel loop. I tend to use it for large 3D arrays, so it makes a substantial difference.
-
 1
1
-
1
-
-
I would recommend trying the NI Multicore Analysis and Sparse Matrix Toolkit. The FFT included there seems robust and much faster than the native LabVIEW FFT. It also supports single precision (which is faster again, and usually sufficient) and 3D FFTs as well. All of the MASM VIs are useful replacements for the single-threaded defaults, and I think it is based on the Intel Math Kernel Library. I think I tried FFTW at one stage - in fact I just found a post I made in 2013 which has links to a FFTW wrapper - I'd forgotten about that! Also at the end of the page is a link to a 32/64 bit version. But I'd still try the MASM toolkit.
-
1
-
-
Ernest Hemingway provides a one-line answer to the question in the title:
Gradually, then suddenly.
-
Two suggestions if you haven't tried them already:
-
- Popular Post
- Popular Post
Does it help to re-ask the question as "where should LabVIEW have a future?" It is not difficult to name a number of capabilities (some already stated here) that are extremely useful to anyone collecting or analyzing data that are either unique, or much simpler, using LabVIEW. They're often taken for granted and we forget how significant they are and how much power they unlock. For example (and others can add more):
- FPGA - much easier than any text-based FPGA programming, and so powerful to have deterministic computational access to the raw data stream
- Machine vision - especially combined with a card like the 1473R, though it's falling behind without CoaXPress
-
Units - yes no-one uses them
") , but they can extend strict programming to validation of correct algorithm implementation
, but they can extend strict programming to validation of correct algorithm implementation
- Parallel and multi-threaded programming - is there any language as simple for constructing parallel code? Not to mention natural array computations
- Real-time programming
- Data-flow - a coherent way of treating data as the main object of interest, fundamental, yet a near-unique programming paradigm with many advantages
- and all integrated into a single programming environment where all the compilation and optimization is handled under the hood (with almost enough ability to tweak that)
Unfortunately NI appear to be backing away from many of these strengths, and other features have been vastly overtaken (image processing has hardly been developed in the last 10 years, GUI design got sidetracked into NXG unfortunately). But the combination of low-level control in a very high-level language seems far too powerful and useful to have no future at all.
-
6
-
Are there any updates to this package? The last I see in the thread is a beta version of 4.2.0, but the official package through VIPM seems to max out at 4.0.1-1.
-
It appears that the shared libraries are fully threadsafe, given the calls are all set to run in any thread, and I don't think the zlib library is multithreaded. Would there be any issues with setting the VIs to "Shared clone reentrant" to allow multiple simultaneous calls?
-
Thanks - I hadn't even thought of using multiple queues in this way, but that makes a lot of sense. I should be able to structure it like this fairly easily.
-
The Parallel For Loop is perfect for parallel processing of an input array, and reassembling the results in the correct order, however this only works if the array is available before the loop starts. There is no equivalent "Parallel While Loop" which might process a data stream - so what is the best architecture for doing this?
In my case, I'm streaming image data from a camera via FPGA, acquiring 1MB every ~5ms - call this a "chunk" of data - and I know I will acquire N chunks (N could be 1000 or more). I then want to process (compress) this data before writing to disk. The compression time varies, but is longer than the acquisition time. So I'd like to have a group of tasks which will each take chunks and return the results - however it's no longer guaranteed that the results are in the same order, so there's a bit of housekeeping to handle that.
I have a workable architecture using channels, but I'd be interested in any better options. Easiest to explain with a simplified code which mimics the real program:
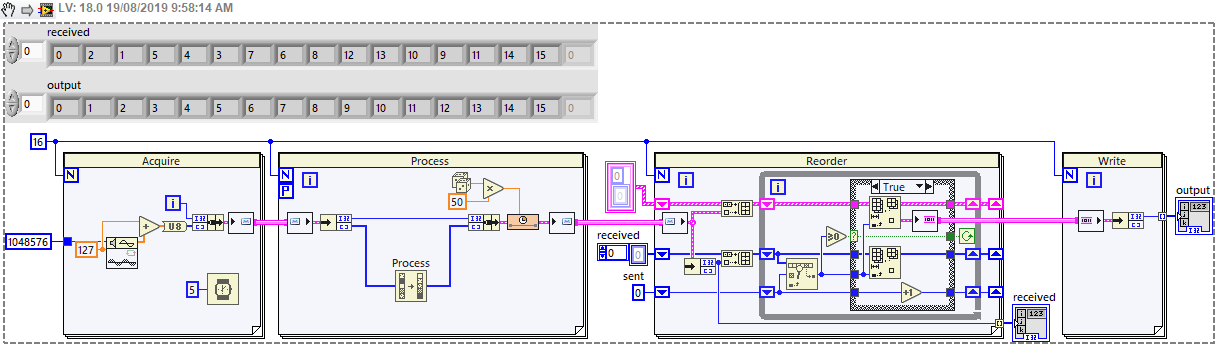
It requires the processing to use a Messenger channel (i.e. Queue) because a Stream channel cannot work in a Parallel For Loop, but this doesn't maintain order. And the reordering is a little messy - perhaps could be tidied using Maps but I don't have 2019 at the moment. The full image is too large to keep in memory (I'm restricted to 32-bit because the acquisition is from an FPGA card), so I need to process and write the data as it becomes available. I've considered writing a separate file for each chunk, but writing millions of small files a day is not particularly efficient or sustainable.
Is there a better approach? Have I missed something? I feel like this must be a solved problem, but I haven't come across an equivalent example. Could there be a Parallel Stream Channel which maintains ordering, or a Parallel While Loop which handles a defined number of tasks?
Thanks.
Greg -
Just to say that I have also had the same issue for quite some time. Several months ago I sent a message using the Contact Us link at the bottom of the website, but have not had a response.
-
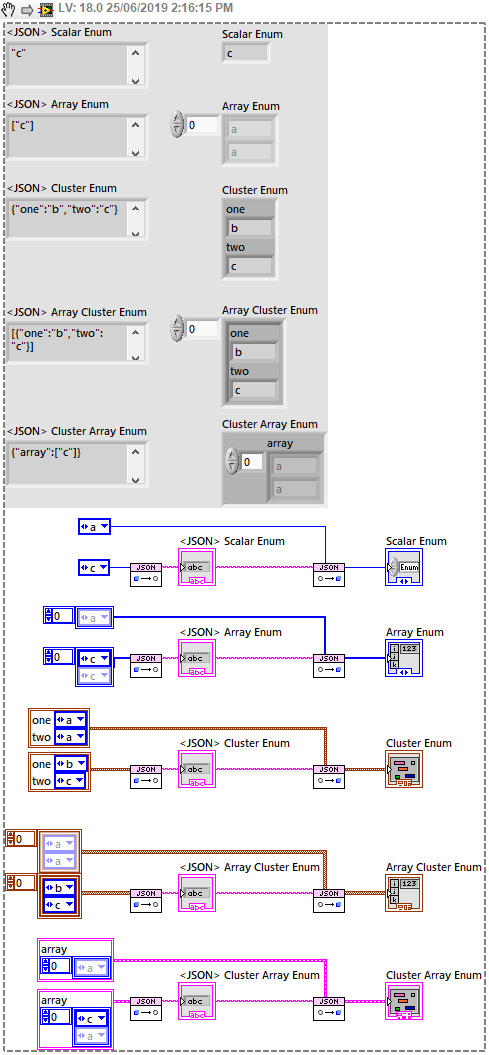
It appears that Arrays of Enums are not handled properly, or at least not in the way I expect or would like! See the attached image for details - using JSONtext 1.3.1.84 on LV 2018.
-
1
-
-
I've not used the PCIe-1477, but have been using the earlier PCIe-1473 - different FPGA chip but I presume the coding is similar. If you want to code the FPGA directly, rather than using the IMAQ routines, have a look at examples such as this one, which also show how to write to/from the CameraLink serial lines. However, as @Antoine Chalons says, you do need to know the specific commands for your camera.
-
Just to add to that, the bolded titles remain even though there were no unread posts showing in "Unread Content". However I just clicked "Mark site read", and the bold has disappeared.
-
Using Firefox/Windows I also have several forums left bolded after reading all posts.
-
You might also try right-clicking the cluster, and looking at Advanced/Show Hidden Element to see whether there might be controls in the cluster that are hidden. But ensegre's suggestion of copying across to a new cluster is probably easiest.
-
1
-
1
-
-
-
Great, thank you AQ.
-
So this gets a little more interesting with the output type of the DDS:
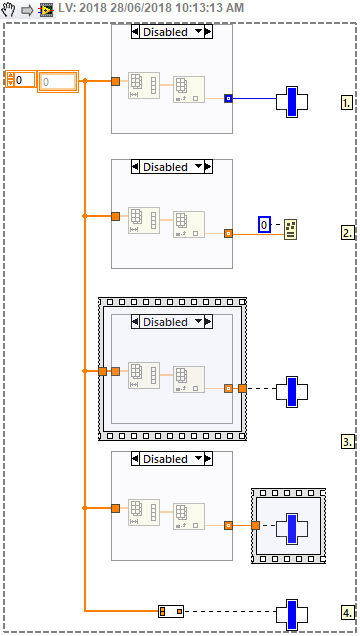
1.Following directly with a VIM causes the output to back-propagate from the VIM's default input type.
2.This does not happen if the Types Must Match is used directly, even though this is essentially the contents of the VIM.
3. Wrapping a sequence around either the DDS or the VIM causes the type to be defined correctly.
4. Putting the DDS inside its own VIM also solves the problem, but only if there is also a sequence wrapping the DDS inside - if not, then the output type from the DDS VIM is always its own default output type.
In any case, here's the Default Element VIM (saved for 2012) for any who might use it.
-
Oh, very nice! I'd not wanted to use Reshape Array because of the memory re-allocation, but I didn't think of using it in a Diagram Disable Structure.
 if I ever meet you in person...
if I ever meet you in person...
-
1
-
-
Does anyone know of a way to create a single (default) element of an arbitrary-dimension array? I'm trying to create some Malleable VIs which have the same code for 1D-3D arrays, but have different code for floating-point vs integer arrays. A second possible use in Malleable VIs would be to Initialize a new array based on an input array.
Any thoughts from anyone?
-
- Popular Post
- Popular Post
Firstly, you are using a Formula Node, not a MathScript Node. But that will do what you need just fine.
Secondly, look at the built-in help to explain the operators. Right click on the Formula Node, then Help, and then look for the allowed operators. You'll see the ones you need, including >> (right shift), << (left shift), & (and), ^ (exclusive or), and | (or). Note that ^ is not "to the power of". That should make completing this fairly straight-forward.
-
3
-
This probably won't help you, but you should be using HDF5 files - it can do exactly this. H stands for Hierarchical, and it is quite straightforward to write data to multiple files, and create a "master" file which transparently links them. That works for writing as well as reading, so you can create the master file at the start, and write data to that which will be stored in separate files, or create it after writing individual files. The HDF5 library handles all of the connection, and can be as simple as I said or far more complex if needed.
Which Math Library does LabVIEW use?
in LabVIEW General
Posted · Edited by GregSands
Added snippet
Reds, did you miss my earlier comment - while lvanlys.dll does not use multicore functions, the LabVIEW Multicore Analysis and Sparse Matrix Toolkit does. Despite X's comments on the lack of documentation, which are quite fair and accurate, I'm seeing huge speedups on my i7-12700F with 8P+4E cores (20 logical processors according to CPU Information).
For a 1499x1499 CDB 2D array, the inbuilt NI FFT takes ~270ms, the MASM FFT takes ~20ms, and the MASM FFT on the same array as CSG takes ~11ms (the built-in FFTs don't support single-precision, but MASM does, and it's often all that is needed).