
GregSands
-
Posts
264 -
Joined
-
Last visited
-
Days Won
26
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by GregSands
-
-
I haven't used LapDog for communicating with RT targets. For several years I've had it in mind to wrap the network stream functions in a class similar to how the queues are wrapped up, but I haven't actually done it yet. Mostly because I don't get to do many cRIO apps so I haven't had enough time to explore good implementations.
Wrapping the network stream functions sounds interesting, though I imagine it may not be easy. It would help if the network stream functions directly accepted a class as the data type, but I guess there are too many difficulties maintaining identical classes across different machines. I can't see a MessageStream class inheriting from the existing MessageQueue class, so I guess one question is whether you'd approach it by defining another MessageTransfer(?) class which both would be subclasses of? There's also a small issue of separated Reader and Writer streams.
However, I have heard unconfirmed reports from a CLA I know and trust that there is a small memory leak in RT targets when using objects.
Is this related solely to cRIO, or to all RT targets (such as the R-series board I'm using)?
-
Thanks for these responses.
I believe AMC uses UDP, instead of TCP, for network communication. Depending on what you are doing, you might require the lossless nature of TCP.
You should also have a look at ShaunR’s “Transport” and “Dispatcher” packages in the Code Repository; they do TCP.
Yes, AMC uses UDP, and yes, lossless messaging is required, but I hadn't realised UDP could be lossy, so that's very helpful. I'll have a look at those CR packages you mention.
I’ve done some (limited) testing of sending objects over the network (not Lapdog, but very similar), and the only concern I had was the somewhat verbose nature of flattened objects. I used the OpenG Zip tools to compress my larger messages and that worked quite well.
Do you flatten to string or to XML (and does it really matter)? Sorry, I'm rather new to all this - finally stepping away from the JKI State machine architecture

One minor issue I've had with sending lapdog type messages over the network (especially custom message types), is that running the program to test will lock out the classes and prevent editing. As such, I use lapdog on the RT machine, but avoid sending any lapdog messages over the network.
Can you elaborate? Do you create custom message types for each command? I had thought of using the built-in native and array types, with variants used for more complex data (clusters etc), but can see that custom message types could be a lot neater. Also, I can't quite see why the locked classes is an issue - once the message types are defined, I thought they shouldn't need to be edited??
Thanks.
-
Has anyone used LapDog to pass messages across a network? In my case I'm thinking of an RT system controlled from a Windows computer. The only similar feature I've seen is in the Asynchronous Message Communication Reference Library - has anyone already added something like that to LapDog? I just didn't want to spend too much time developing something that's already available. I haven't used either AMC or LapDog extensively before, but my impression is that LapDog gives a little more control and flexibility. (And the Actor framework perhaps a little too much, as a poor reason for not going that route!).
-
- Popular Post
- Popular Post
Rather than getting worked up about useless (or even dangerous) parts of LabVIEW, here's a couple of nodes from the New VI Object list that are actually useful, along with what it appears they do:
Swap Vector Elements

Takes a 1D array, and swaps one element with a new value in a memory-efficient way.
Get Fixed-Point Components
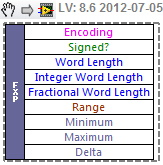
Pulls out information about the nature of a Fixed Point variable.
And here's one that looks like a no-op -- though I'm happy to be corrected

Transpose 1D Array

-
 3
3
-
Read it again. It is a list of synonyms. Each item in the list is a pair.
Definitely not synonyms (words which mean the same thing). Not strictly antonyms either (words which mean opposite things). I guess you could call them pairs, but there is probably a more grammatically correct term.
-
Did you select 50-60 associated files and try to open them all at once? On a related note, I know that Win7 won't let you "multi-open" over a certain limit (which is pretty annoying sometimes).
See here to get around this annoyance.
-
2
-
-
There used to be some standard functions that supported different data types in the HIgh Performance Analysis Library (HPAL). Not sure about extended but I know they went the other way and implemented some in SGL. I went to the NI labs page but it looks like it has been pulled but there is a beta program where the functionality has been moved to. The page is at https://decibel.ni.c.../docs/DOC-12086 with the address for the beta program if you were interested.
HPAL has become a new toolkit: Multicore Analysis and Sparse Matrix toolkit. I think it's based on the Intel Math Kernel Library which only supports single and double precision, so not much hope of it being "extended".
Greg
-
And, why would you steer away from regexes?
I spent a few years doing a lot of Perl programming, so I'm not totally anti them! When they're needed, they're extremely powerful, but if you have a fixed delimiter, as in this case, then they will always be slower than a token search.
-
Nice! That's getting close, but it's missing the very last section - here's a screenshot from RegexPal:
The regex grabs the last section in LabVIEW though. But I'd still steer away from regexes if there's any other way to do it.
-
Can you forget about the regex and use either Spreadsheet String To Array, or Scan String For Tokens?
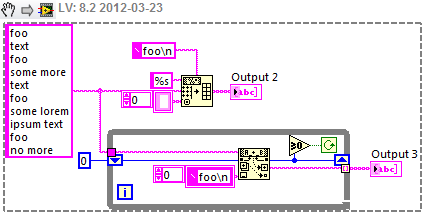
Assuming of course that the foos will be discarded, or can be added back in.
-
Did you notice that both your refs are now the same - i.e. pointing to the first XControl?
-
9 times out of 10...Yes.
But don't go comparing 2011 x64 with 2009 x32. It'll make you cry. 
I've been using 2011x64 a bit lately, and the speed hasn't been an issue at all. Now, the functions don't always work, but that's a separate issue. What have you found?
-
a simple way to throttle the polling loop is to use the "Wait for Front Panel Activity" function with a long timeout (500 msec)How can I have never known about this function? Thank you!
-
I seem to recall making it work with a Stacked Sequence (only time I've used that!) but not a Flat Sequence. But a Diagram Disable is just as good, and you can easily remove the structure again after rewiring the connections.
-
GregR -- I really appreciate your posts on what's beneath the surface of LabVIEW, and especially your comments above on 64-bit LabVIEW.
Just to further the discussion on array sizes, I work a lot with large 3D arrays, and I posted recently on ni.com here about a crash I have with this code:
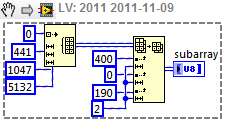
which crashes immediately at Array Subset, without any error reporting. The allocation seems to work ok - in the code I extracted this from, I fill in the array from disk, and can take other subsets until I get to these indices here. This is with LV 2011 64-bit on Windows 7 64-bit, 4GB memory, another 4GB virtual memory, and the array here is just under 2.5GB in size. Using this tool, there are apparently 2 free blocks of at least 3GB, so allocation appears not to be the problem.
Using the 64-bit Vision toolkit to look at memory allocation, I can allocate 2 2GB images, and another of almost that size:
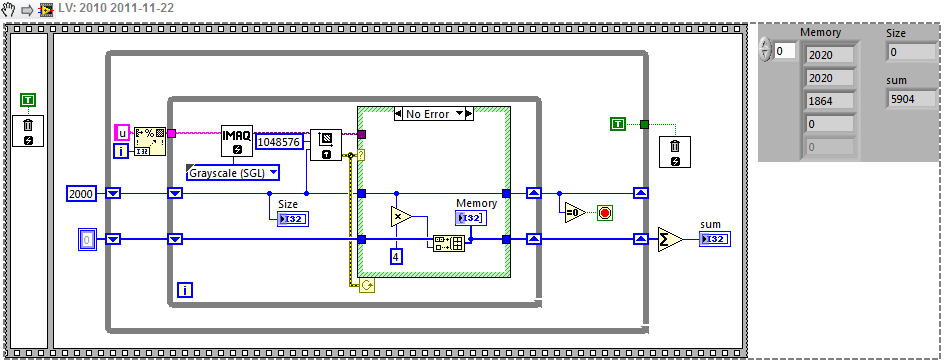
I presume the 2GB limit is a limitation of the Vision toolkit rather than the machine. However even though I can allocate those, if I try to use them, I may sometimes crash LabVIEW (or just now, even crash my browser while typing this post!).
I guess I was hoping that moving to a 64-bit world would be a fairly painless panacea for memory issues, and eliminate (or at least significantly reduce) the need to partition my data in order to work with it. While I can't move completely anyway (until some other toolkits become fully 64-bit compatible) I'd wanted to try it out for a few of the larger problems. Perhaps more physical memory would help - that would suggest it might be a Windows issue with managing virtual memory - however looking at the first problem on another machine with 8GB, the 2.5GB array won't even allocate even though a much larger 1000x1000x5000 array will.
Trying to think what would be helpful in terms of allocating and using memory:
- a way to check what memory can be allocated for a given array (the tool mentioned above gives some numbers, but they don't seem to relate to what can actually be used)
- if memory is allocated, then it should be able to be used without other problems later on
- I'm sure this is impossible, but I'd love the ability for Vision and LabVIEW to "share" memory (see here)
- behind the scenes management of fragmented arrays -- FALib gets closer, but is only easy for 1D arrays
One last thought, on a more philosophical level - where does 64-bit LabVIEW fit in NI's thinking? At the moment, it's very much the poor cousin, barely supported or promoted, with only the Vision toolkit available at release (ASP takes another few months, still not there for LV 2011). Given LabVIEW's predominant use in the scientific and engineering community, and the rapidly increasing availability of 64-bit OS, how long until 64-bit becomes the main LabVIEW release?
- a way to check what memory can be allocated for a given array (the tool mentioned above gives some numbers, but they don't seem to relate to what can actually be used)
-
What if you enclosed the contents with another frame (say a sequence), then moved that. The Scripting Tools have some functions that might help, from which this clip was extracted:
Does that make it easier to do what you want?
-
1
-
-
Emphasizing the inputs and outputs distracts me from what I'm really interested in, which is what the code is doing. Terminal icons are too similar in shape and size to sub vi icons, and to a lesser extent class constants.
You beat me to the comment -- this was exactly my first thought on seeing this image. I also always use terminals - I cannot think of a time I willingly used icons - perhaps only when coding on someone else's machine.
-
Here's the original, with a few options for 2011: http://forums.ni.com/t5/LabVIEW/How-To-Setup-your-LV-Icons-so-you-can-tell-versions-apart/m-p/1665192
-
1
-
-
A little update: I have implented this using lvODE, in the end it was pretty simple
That's probably a much nicer and easier way to go. Glad it was simple.
-
But that goes against the reason for having a small compact VI i the first place
I am leaning towards this one.
Is the gap between the small icon and the wires intentional? It does visually indicate that errors are cleared, but at the same time looks "wrong".
-
Keep a revision of the VI which opens with the dirty dot, save to it a different file name, then do a diff (Tools > Compare) between the two.
I tried this -- both VIs need to be open to compare them, and of course the automatic changes are applied when opening the VIs, so there's no difference. Or am I doing something wrong?
-
Every so often I have a VI which always opens with a dirty dot, and the reason is "Object(s) modified on the block diagram". Is there any way to determine which object(s) that might be? It would be great to be able to double-click the message in the list of unsaved changes and go to that object, or to a list of objects. I've seen this in all recent versions of LabVIEW including 2011.
-
It probably depends on how large your meshes are. If they don't have many vertices, the brute force approach is simplest and perhaps fast enough. Something like checking that all your vertices in one object are on the "outside" of the triangles of your second object. There are a few ways to compute that - I think one easy one is to compute the scalar triple product [a . (b x c) or det(a b c)] of the vectors a = v1-p, b=v2-p, c=v3-p between a point p(x,y,z) and the vertices v1, v2, v3 of a triangle - the sign of this product/determinant is positive if [p1, p2, p3] are clockwise, and negative if anticlockwise. That gives some idea which side of the triangle you're on. I imagine you also want to stop before they intersect, not after, so checking the distance to the plane of each triangle is also fairly easy.
Searching for "collision detection algorithm" gives a few possibilities, but most are game related or overly complex.
-
As I said in the other thread, I liked your implementation better.

Sorry, missed your update on that thread.
Lapdog over the network?
in Application Design & Architecture
Posted
Really interesting to follow this conversation. I can't pretend to understand all of it - yet - but thanks for the discussion and ideas.