

Porter
-
Posts
231 -
Joined
-
Last visited
-
Days Won
27
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Porter
-
-
I'd be happy to take a look. Please share the code with me.
It would be important to prepare a comprehensive list of test cases to validate the each new operation and make sure that existing operation are not changed.
The test cases that I have been using are here: LV-muParser/Testing/eqTestCases_mupExpr.csv at master · rfporter/LV-muParser · GitHub
-
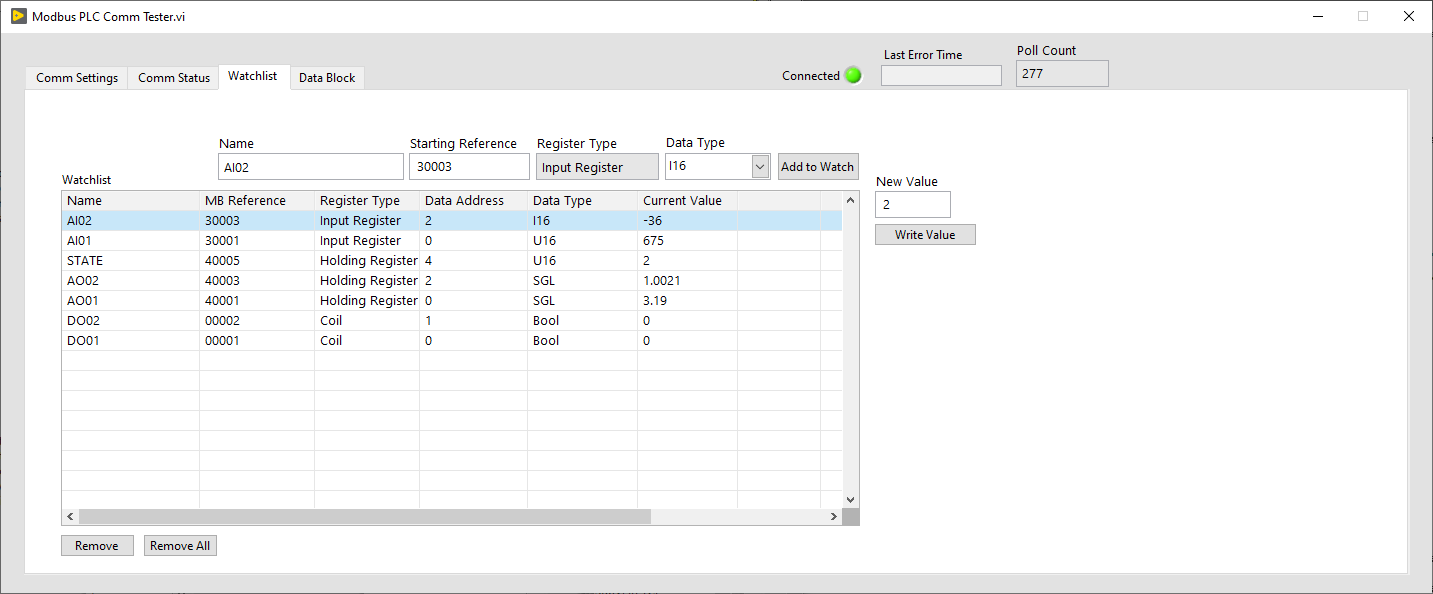
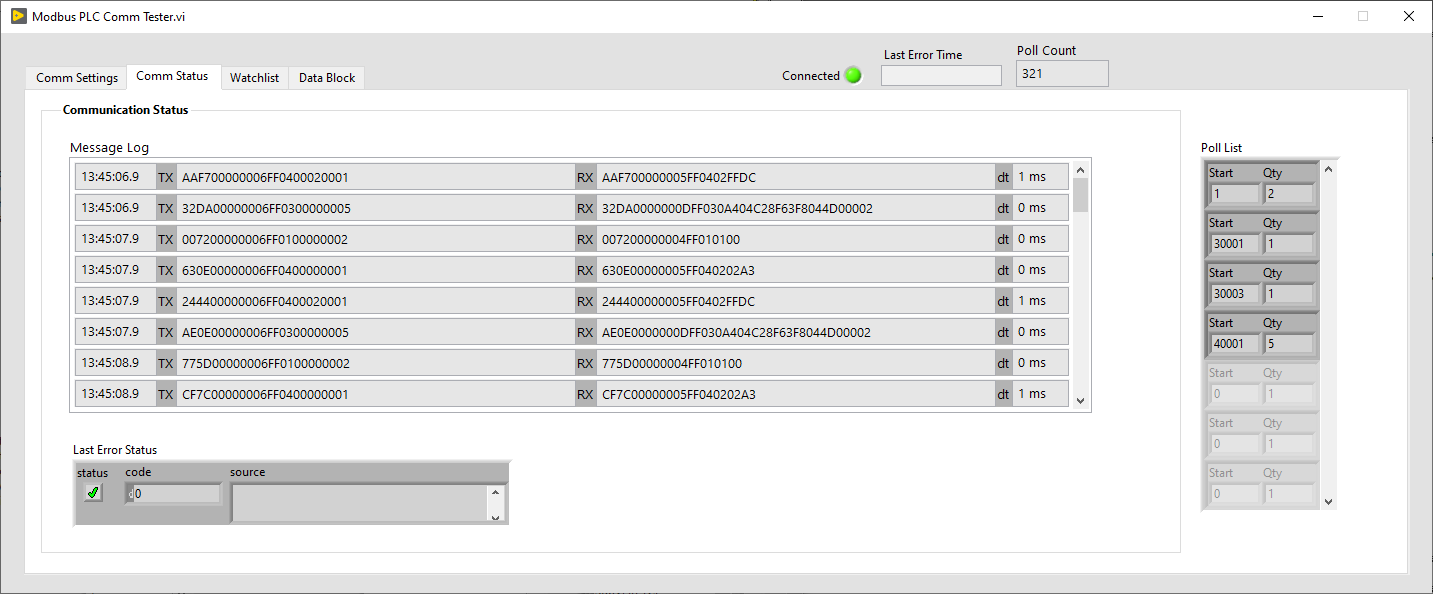
Example code now includes a new comm tester too.

-
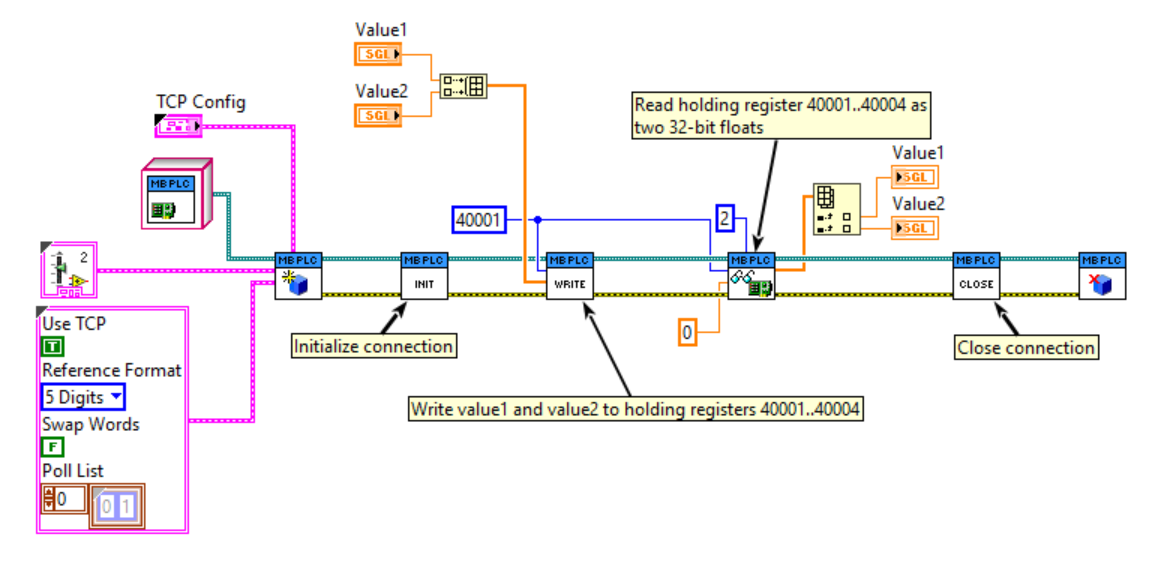
I've put together a wrapper to the Plasmionique Modbus Master library that makes communication with PLCs a bit easier. It could be used for just about any Modbus device, but I had PLCs in mind when I was developing it.
What is easier?
- Modicon-style addressing instead of data address and function code.
- Data-type conversion built-in(eg. 32-bit float mapped to two U16 registers). Word swapping option.
- Poll list and cached data block. Allows you to poll a range of registers then lookup and convert the values elsewhere.
The code is up on GitHub: https://github.com/rfporter/Modbus-PLC-Client
Its a rough draft at the moment. Comments are welcome and appreciated.
-
 1
1
-
-
18 hours ago, ShaunR said:
I won't check those links out as I don't want to be accused of plagiarism if I design from scratch.
FYI the first link is licensed under BSD 0-Clause: LV-MQTT-Broker/LICENSE at master · LabVIEW-Open-Source/LV-MQTT-Broker · GitHub
I've used the MQTT client in a project already. Its well written and actively maintained. Definitely worth checking out.
-
Does anyone want to take a whack at MacOS support?
-
The release is now updated on github. I will send it off to vipm after a bit more testing.
If you are curious about how I compiled libmuParser for windows and ubuntu, and the modification that I made, here are my notes: muParser Build Notes.pdf
On an unrelated topic; is it worth uploading the latest versions of projects on the LAVA CR? Each project now has a copy on github, vipm, and LAVA
- vipm is the most convenient for distribution
- github is most convenient for source version control and issue tracking
- LAVA is most convenient for discussion-
1
-
-
This works for me on ubuntu 20.04, gcc9.4.0, LV2022: lv_muparser-2.1.0.3.vip
-
 1
1
-
-
I will setup a Ubuntu 20.04 VM tonight and recompile against gcc 9.4
-
1
-
-
This vip will put the .so files in the resource directory: lv_muparser-2.1.0.2.vip
-
Shockingly it works just fine for me. Note that installing LV2022 on ubuntu 22.04 is not straight forward. Its best to stick with ubuntu 20.04. I also couldn't get VI package manager to install so I extracted the vip manually.
I did notice that the muparser .so files were not put in the right place. They should reside in /usr/local/natinst/LabVIEW-202X-64/resource/ and not in the vi.lib. Otherwise they won't be found.
-
Thanks for giving it a try.
The library was compiled using gcc version 11.3.0 on Ubuntu 22.04. It uses openMP, but I don't think that is an external dependency.
I will try to get LV2020 community edition installed on my VM so that I can investigate further.
-
I have updated to muParser version 2.3.4.
Is anyone willing to give it a test on LV Linux 32-bit and 64-bit?
Here is the latest code: https://github.com/rfporter/LV-muParser/releases/tag/V2.1.0
-
-
On 8/3/2022 at 7:05 AM, Rolf Kalbermatter said:
You may want to try with this library. No guarantees about its proper operation. It's a quickly hacked together version from this library that I posted earlier. It's not really tested for the extra bitwise operators and there is no provision for correct left and right association of these operators, so it might require explicit bracketing to work as expected unlike in other languages and formula parsers that tend to follow the mathematical and/or C style conventions.
Do you have any plans to put this up on Github and/or vipm.io?
-
It seems that everything is passed as float. Bitwise should be performed on integers. So maybe muparser isn't the best solution.
They do mention that shift left/right can be added though: https://beltoforion.de/en/muparser/customizing_muparser.php
But maybe GPower Expression Parser has exactly what you need: https://www.vipm.io/package/gpower_lib_exprparser/
-
The muparser library should definitely be updated. I had modified the muparser library to add the : character as a valid variable name character because my variable names often include colons.
To add bitwise operations like "2&3 = 2", either you would need to create a wrapper that adds these functions to muparser, or just modify the original source code like I did for the : character. I'm not sure how much work this would be. The labview code wouldn't change at all, except for specifying a new version of the muparser dll.
-
On 5/23/2022 at 11:27 AM, hooovahh said:
By standing farther away.
Same as LabVIEW's zoom feature
-
 1
1
-
-
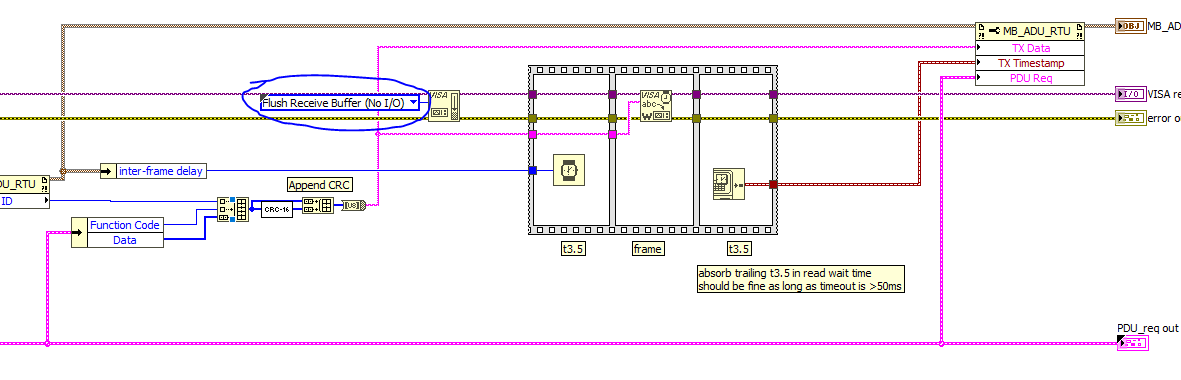
In "TX ADU.vi" of the "MB_ADU_RTU.lvclass" try setting the mask of the VISA Flush to "Flush Receive Buffer (No I/O)"
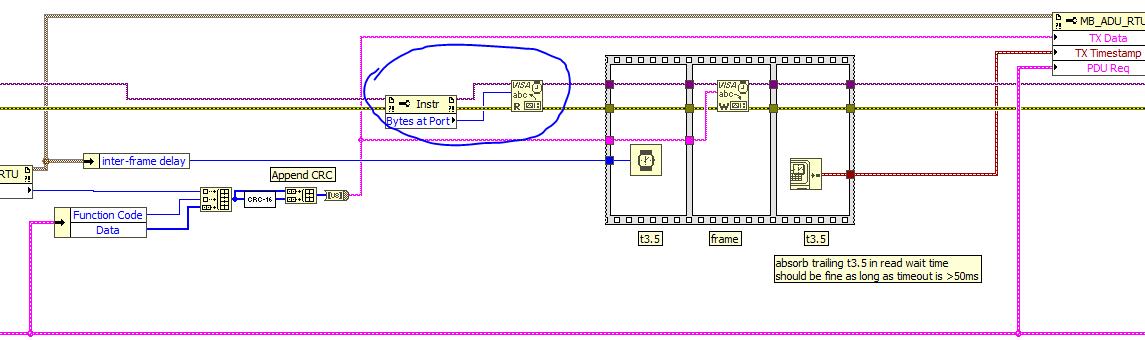
If that doesn't change anything, then try replacing the VISA Flush with this:
Please let me know if that changes anything.
-
What model of USB to RS232 cable are you using?
Maybe this could work?
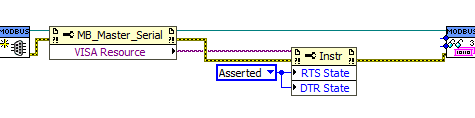
Maybe the RTS and DTR are cleared during the Flush IO buffer that is called just before serial transmission. This is the first time I would have seen this behavior though.
-
300 baud. That is slow!
This error is generated by the slave ID check that happens after the first 2 response bytes have been received.
Byte 0: SlaveID
Byte 1: Function CodeIf the slave ID doesn't match the slave ID of the request, then you have a slave ID mismatch. Likely the data is somehow corrupt.
Are you sure that your stop bit and parity bit are set correctly?
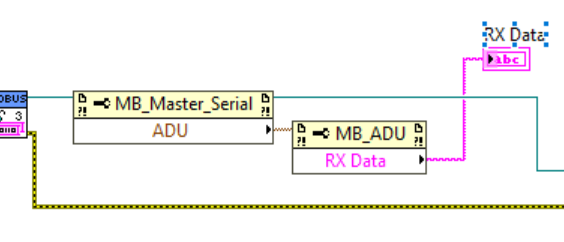
You can also check the two received bytes using a property node like this:
Be sure to set the string indicator to hex display.
-
Windows 10 now has a built-in tar command.
You could extract just that one binary file using a filter in the extract command:
tar -xzvf filename.tar.gz <patterns>
So for you binary file, it could just be:
tar -xzvf filename.tar.gz foldername/binfilename
This will extract your binary file next to the tar.gz file.
-
1
-
-
47 minutes ago, bjustice said:
I fully intend to modify BlueTOMLSerializer to drop all the TOML code and directly consume Antoine's library as a dependency.
That's what I was thinking. Thanks for the clarification.
-
It seems that there are now two forks of the erdosmiller TOML library:
https://github.com/AntoineChalons/lv-toml
https://github.com/justiceb/BlueTOMLSerializer
@bjustice is the BlueTOML a fork of the original erdosmiller library or of Antoine's library?
-
Anything else that should be VIMed?
Median, mode, standard deviation?
Everything NI_GMath and NI_AALbase please. They greatly impact application build time.
[CR] LV muParser
in Code Repository (Certified)
Posted
Got it. Thanks. Do you mind if I post it here?