

Gary Rubin
-
Posts
633 -
Joined
-
Last visited
-
Days Won
4
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Gary Rubin
-
-
It keeps the admins from having to deal with complaints...

Edit: I was just able to report Yair's original post. Maybe it's a special feature that's only available to us non-premium members.
-
Given that LabVIEW code can be difficult to understand for a non-LabVIEW programmer, I'm not sure I see the utility of this. My thinking is that if you have the know-how to make sense of the code, then you probably already have access to LabVIEW.
That said, I can see a benefit of such a tool for looking at code from other versions of LabVIEW. Before I upgraded from 7.1 to 8.6, I felt like I couldn't really participate in some of the discussions here because I couldn't open the VIs that people were posting.
-
An array is an array - don't they all have dimSize at the front?
Right, so I think that what he's saying is that when the decimation turns an N-element array into 4 N/4-element arrays, there should be 3 extra dimSizes as compared to the original array. That should mean that more memory is needed.
-
This is getting so confusing I was the one confusing coercion with allocation.

Maybe the subtitle of this topic should have been "down the rabbit hole".
Then again, most of my topics seem to end up that way

-
I'm scratching my head as well. Are you possibly confusing array copies with coercion?
Nope, my coercion dots are red.
-
OK - now I'm really confused - why would there be a allocation dot on the output of the decimate? The output is still a 1D array of SGLs - it's just got fewer elements.
I didn't realize that it would be able to reuse the same space for the new array, especially given the fact that one is a decimation of the other (i.e. the output elements are not contiguous in input array).
-
I can understand why the inplace structure doesn't have it yet, but I'd expect the normal manual conversion to have it

Here's what I'm seeing.
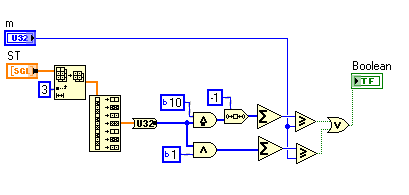
I'm surprised there's no allocation dot on the output of the decimate.
-
Sorry for the brusqueness. I thought you knew something about LabVIEW's internal memory and were being cute...
I was trying this inplace trick because when I tried doing the conversion normally, it was not done inplace. I was hoping that the inplace structure would get rid of a buffer allocation on the output of a Single->U32 conversion
-
Both types aren't 32-bit, at least not yet...
Are you going to explain that comment, or just leave it hanging out there for a while?

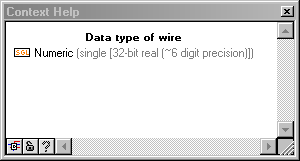
-
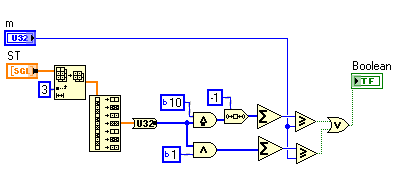
Why can't I do this?
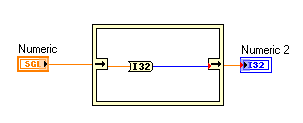
Both data type are 32-bit, so is there any reason why I shouldn't be able to do that conversion inplace?
-
They're under the "classic" section's Boolean palette.
-
The behavior I'm seeing at moments is that I will only be able to select one radio button at a time. I would like to have the ability to select multiple buttons if I need to.
As far as I know, the behavior that you're seeing is what defines a radio button.
-
In fact, I think this is a really important discussion
I agree, and I really appreciate the link to the Adam Kemp message. You (crelf) might have more access to the ins-and-outs of LabVIEW, but for the rest of us average Joes, all we can do is make observations about what works best in our own little code sets, and hope that those observations about the best way to do things can be generalized and applied to other cases. Some insight from NI can help us better understand why something works well, and therefore, when to use it.
-
Are you sure about that? I'm sure I've read that putting input controls inside a case statement prevents LV from making certain compiler optimizations. I can't find the reference at the moment though.
This might be what you're thinking of?
Thanks for all the answers.
For a second there, I thought we were going to have a flame war between Chris and Michael

Yes, Crelf, I probably was mistaken in referring to it as a simple state machine. It is more like a functional global in it's own architecture, although I don't usually think of it that way. The shift registers are used as persistent memory for its own internal use, rather than trying to provide global-like behavior for the callers.
-
I realize that the answer to this question is probably more complicated than just a yes/no, and it may to lead to more questions, but I'll ask anyway.
I do a lot of simple state-machine architectures for data processing routines that need to retain information from one iteration to the next. I typically will use an Init state, which initializes uninitialized shift registers (USRs), then a run state to pull data from the USR, and do the number crunching.
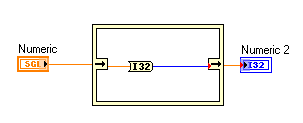
What is the best way to get data in and out? I'm showing 3 options below.
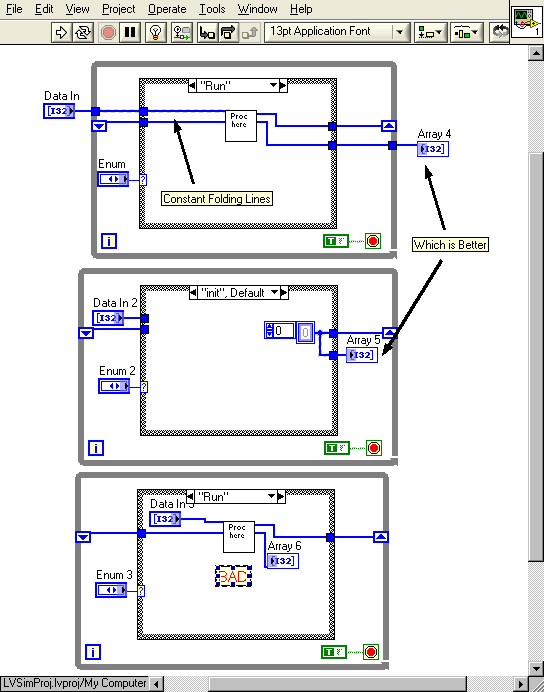
I know that the third option is a No-No. That's been discussed here before.
What about the first two? Is the presence of the constant folding wires in the 1st option LabVIEW's way of telling me that the Control terminal should go outside the while loop?
What about on the output side? Does it matter if the Indicator terminal is inside the loop vs. outside?
I'm just full of questions this week.
Thanks,
Gary
-
That depends on what you mean by "database"
The lvproj file is an XML text file - change the extension to ".xml" (or even ".txt"), open it, and you'll see all the XML tags and thier values.Oh, is that all it is? I had assumed it was something more complicated than that.
-
Only if that information didn't already exist in the project explorer (say, what the status was at last save).
I was thinking the same thing on my drive home. I assume a Project is some type of database-like thing. If fields in that database containing additional information for each member VI are updated as each VI is saved, it would probably not slow things down too much.
-
These fields could be bad for load performance if they require the project to load the VI to query them. Currently the project doesn't have to load all VIs that it references, though there are exceptions. If load times get any worse, projects won't be usable at all.
Ah, good point...
-
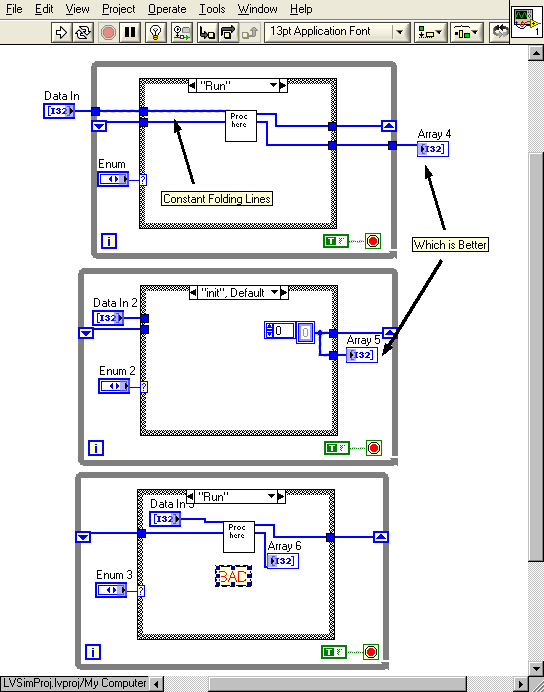
I would generally only select differenct execution systems for subVIs that will run continuously in parallel with other operations, not subVIs that simply process data and return immediately.
Of course, but unless that Subvi is called dynamically, someone's got to call it, and if they're calling two different subVI's one of them is going to be in a different executions system.
See figure 7. This is what I'm envisioning.
-
Try Portal > Today's Active Topics.
Of course, that only works if you check LAVA daily.
-
Is there any way to add fields (other than just Path) to the Project Explorer? In addition to the obvious additions (e.g. time/date), I would love to see a listing of other parameters, including:
- Debug on?
- Preferred Execution System?
- Priority?
Maybe this should go in a Wish List forum?
Gary
-
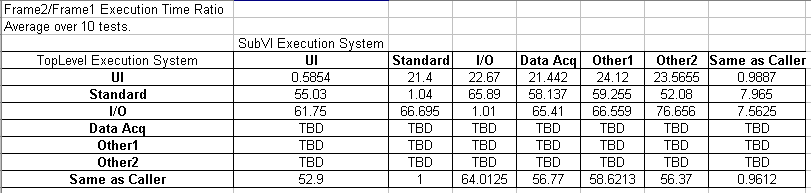
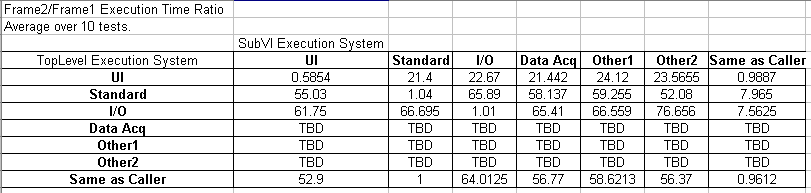
Here's some more information.
Top Level Execution System: Instrument I/O
Panel1 SubVI: Same as Caller
Panel2 SubVI: Other 2
Profiler Off: Frame2/Frame1 Execution Time = 66.7
Profiler On: Frame2/Frame1 Execution Time = 8.3
Observation: Profiler slows down Frame1 more than it slows down Frame2?
Profiler Results (multiple tests)
Panel1 SubVI Total Time (ms): 406 515 547 640 422 453
Panel2 SubVI Total Time (ms): 781 765 875 844 765 937
Observation: According to Profiler (so take numbers with a grain of salt), the subvi running in the different execution system takes longer. AQ, is this consistent with your assumption that the added time is associated with thread swapping? Does the thread swapping time get attributed to the subvi by Profiler?
Question: What does this all mean (aside from the fact that we should be very careful with execution system settings for some cases)???
-
I don't think it has anything to do with data copies. I'll bet it is just the time needed to do the thread swapping. If you are "same as caller", then the same execution thread can run the subVI and you can just keep working. If you force a change of execution systems, the VI has to stop, put itself back on the run queue, and wait for a thread from the chosen execution system to come along to execute the subVI. Then it has to go back on to the execution queue to switch back when returning.
So, is the takeaway that a really fast, tight loop should only contain subvi's in the same execution system? What about the fact that "same as callers" seemed to be a little bit slower than explicitly setting the subvi to the same execution system as the caller?
-
I was once told here on LAVA (by rolfk?) that data transfer overhead is not dependent on Labview Preferred Execution Systems. In other words, if a caller is running in one execution system, it should not matter whether a subvi is running in a different execution system. At least, that's how I understood it. Given that,
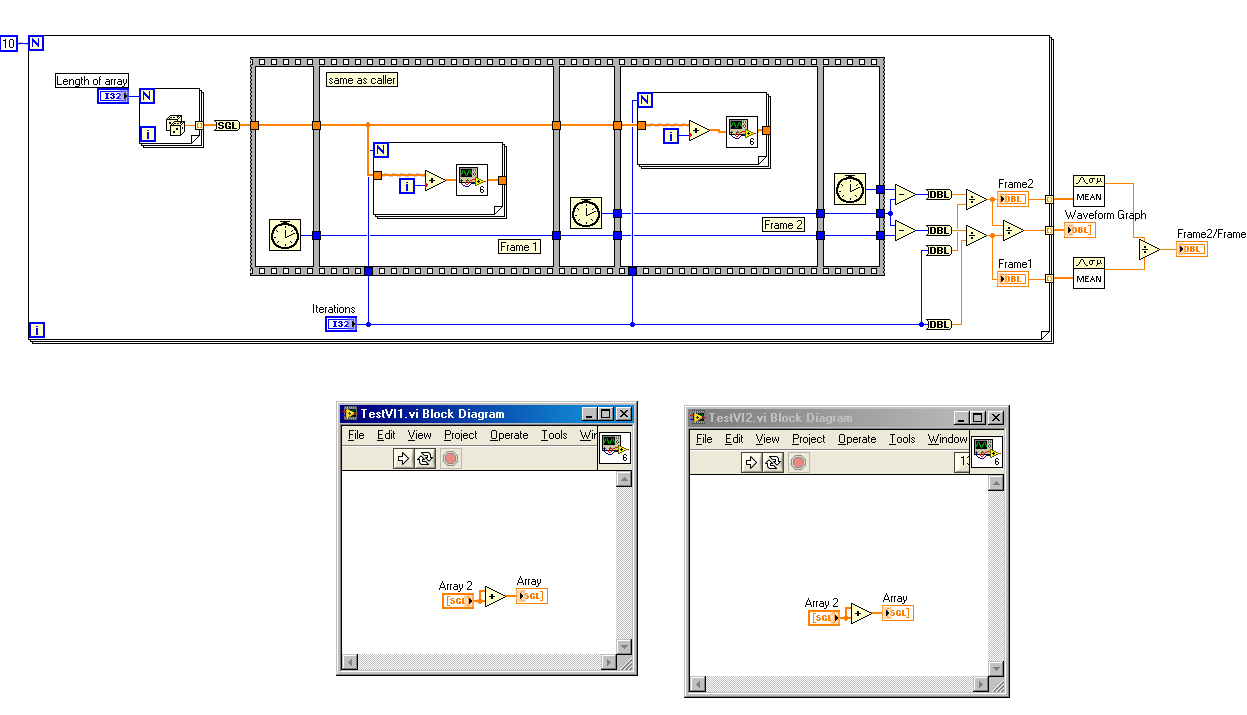
I'm a little puzzled (and alarmed) but what I've just discovered. I was doing some experimentation to figure out whether any performance can be gained by tweaking the manner in which subVIs are called/configured. The subvi's are very simple, just summing an array with itself.
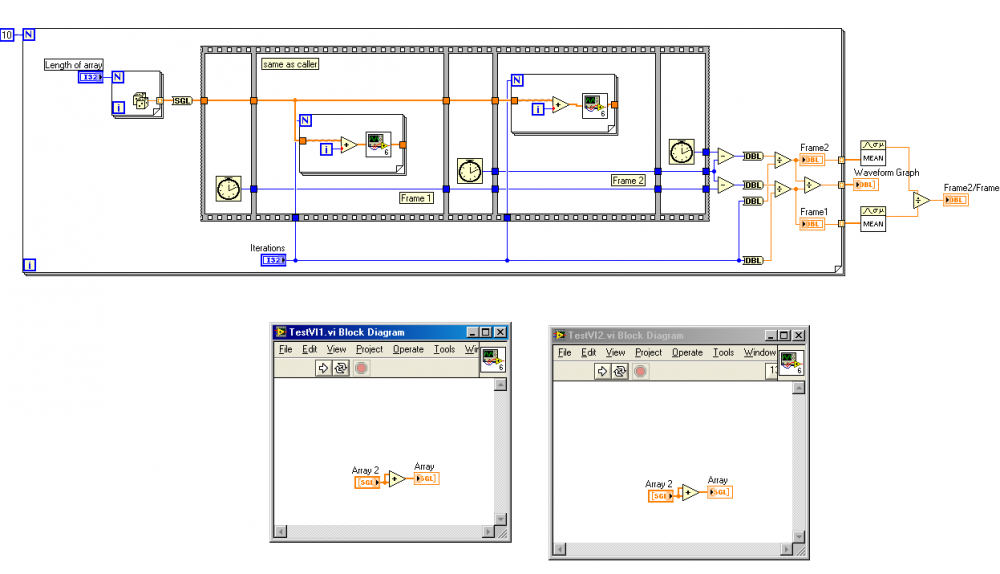
The toplevel vi is Time Critical Priority with debugging off.
The subvi in the 1st panel is always Normal Priority, Same a caller, with debug turned off.
I've varied the Preferred Execution system of the toplevel and the subvi in the second panel, and noted the ratio of the execution times for each of the test loops.
Here's what I've seen so far.
I also did a single test in which I set the toplevel priority to Normal (like the 2nd subvi), but still got the large disparity when crossing Execution Systems.
Can anyone duplicate?
What gives?
Gary
EDIT: Fixed embedding of attachments.
Extending Virtual Memory
in Development Environment (IDE)
Posted · Edited by Gary Rubin
One of our guys tried doing the 3GB thing and it really screwed up his computer.
This might explain things: http://blogs.technet.com/askperf/archive/2007/03/23/memory-management-demystifying-3gb.aspx