

Gary Rubin
-
Posts
633 -
Joined
-
Last visited
-
Days Won
4
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Gary Rubin
-
-
QUOTE (jdunham @ May 13 2009, 07:20 PM)
I think LV suffers from a bit too much of this in a 'don't scare the newbie' philosophy. Maybe it needs to be that way, but it would be great if there were more ways to get past that and end up with advanced palettes with more useful stuff for the advanced users.I would agree with that assessment. I recently spent 2 days banging my head against a DAQmx project. My biggest frustration was the lack of clear documentation for low-level control. If you want to do something "normal", DAQmx and LV make it very easy to be up and running quickly. If you want to do something a little less "normal", you're pretty much on your own...
-
QUOTE (neBulus @ May 12 2009, 10:49 AM)
Next (still cheatting)I log a call with NI support and tell them what I am trying to do and ask them to provide an example.
Ben,
Thanks for the feedback. I did try calling NI support. I was pointed at various Knowledge Base articles which were somewhat related to what I wanted. He also said that what I am trying to do should be possible, but requires very low-level timer control, so it might not be very straightforward.
We ended up going with an external logic chip on a breadboard that took 20 minutes to setup and is working like a charm.
Gary
-
-
:headbang:

-
Hello all,
I'm trying to get a counter-based application set up using a PCI-6601 counter board. I haven't done NI DAQ in years, and this is my first foray into DAQmx. I feel like I'm really fumbling around here. My current approach is to find an example that has part of what I want to do and cobble it together with parts of other examples. It's a lot of trial and error (mostly error). I'm not finding the DAQmx Help particularly helpful either. It explains how to call each function, but that's really only helpful if you know which function to use in the first place. Any advice on where to start?
In case anyone has any insight, here's what I'm trying to do:
1. Counter0 generates a pulse train at a constant rate. This represents the system trigger.
2. Counter1 generates a pulse train which is synchronous with Counter0 and delayed from it.
3. Counter1 uses the Pause Trigger Property so that it is suppressed when one of the DIO lines is high. When the DIO line returns to low, it Counter1 pulses should come back in the same place relative to Counter0.
I can get 1 and 2, but not 3, or 1 and 3, but not 2.
If I make Counter0 and Counter1 part of the same task, then they are synchronous, but the Pause Trigger property seems to only work on tasks, not channels, so I can't apply it to Counter1 without applying it to Counter0.
If I make Counter0 and Counter1 differents tasks, so I can apply the pause to just Counter1, I lose synch between the two counters. I tried using DAQmx Start Trigger (Digital Edge).vi to sync the Counter1 task with Counter0, but get an error that I can't use both Pause and Start triggers in the same task. I then tried using the ArmStart property instead of the VI mentioned above. This worked fine, until I unpaused; Counter1's pulsetrain was then synchronous with the unpause, rather than Counter0.
Can anyone offer any advice, or at least point me toward some useful resources? If I remember right, it was this confusion of how to find the right tools that led me to use traditional DAQ for my last DAQ project, even though DAQmx was available at the time.
Thanks,
Gary
-
-
QUOTE (jdunham @ May 7 2009, 02:04 PM)
I remember changing the constant in front of someone who had used LV for several years, and he exclaimed ,"I never knew you could do that! I always put a NOT function after it." Maybe he wasn't the sharpest tool in the shed, but I'll wager he wasn't alone, so NI put both of them in the palette (in the old days there was only the False constant).So, originally you could only define a FALSE constant? There was no True?

-
Why does the Boolean palette include both a True constant and a False constant?
Why does a numeric constant in the BD default to I32, while a control/indicator on the FP defaults to a double?
Thank you to whomever changed the Compound Arithmetic so that it defaults to a logical operation when selected from the Boolean palette, and an arithmetic operation when selected from the Numeric palette.
-
Eureka!
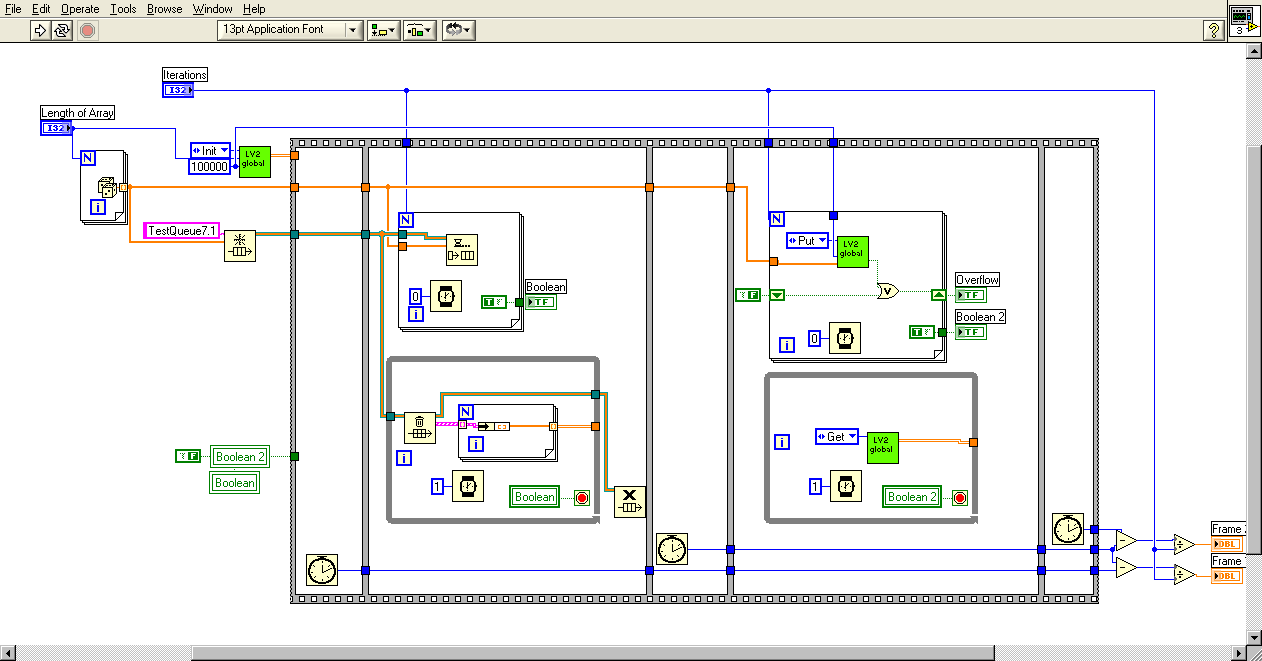
I've added queue preallocation, and am finally getting trends more in line with what I was expecting. I also tried changing the execution system from Same as Caller to Standard, but that didn't seem to have much effect.
Download File:post-4344-1241484811.zip
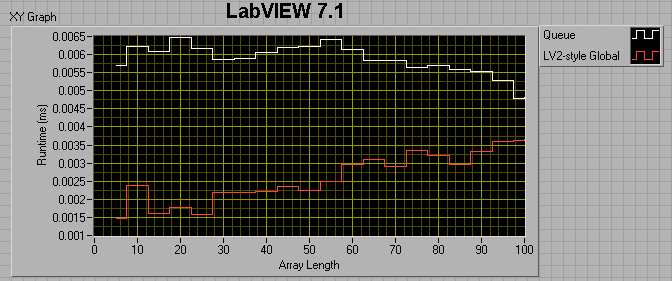
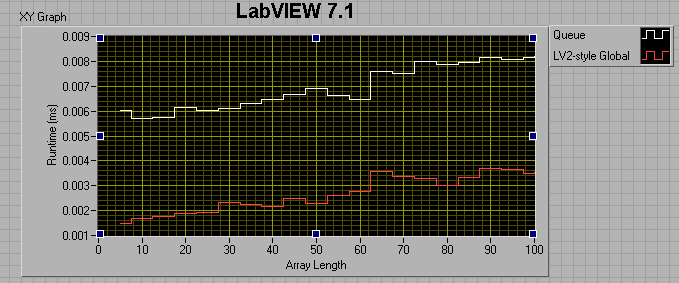
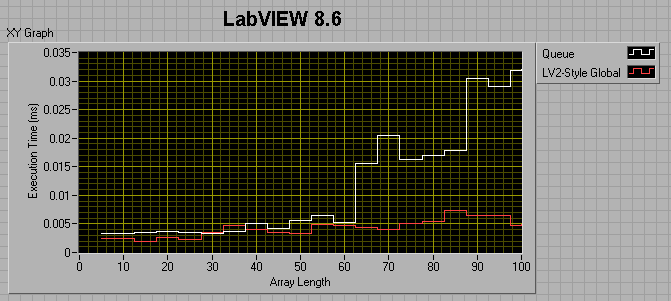
For a 0ms wait in both consumer and producer loops:
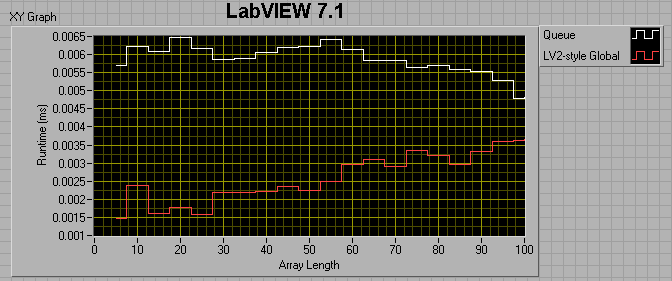
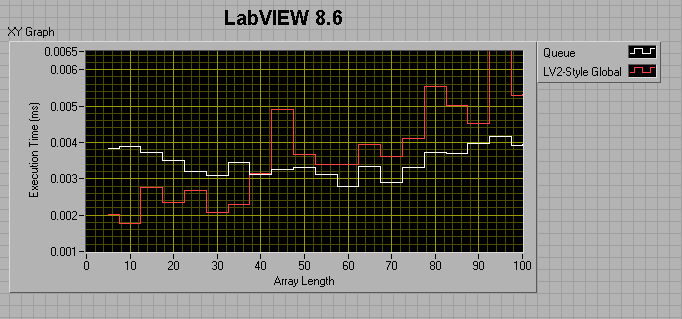
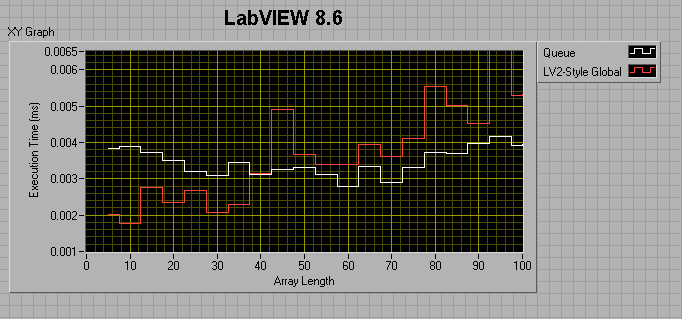
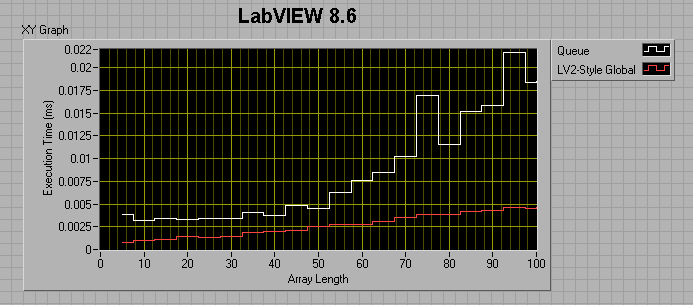
For a 0ms wait in the producer and a 1ms wait in the consumer:
It appears that from 7.1 to 8.6, the queue method (as measured by this benchmark) got about 50% faster, while the LV2 method got considerably slower?!
So, the lesson learned is that you really want to preallocate your queue if you plan to use it for a large amount of data.
Thanks to all who have taken a look at my code.
There's still something I'm wondering about; as Ton suggested, is a queue recommended for this type of use? (AQ?)
QUOTE (shoneill @ May 4 2009, 05:51 PM)
I changed the "preferred Execution System" of your benchmarking VI to "User Interface" and I got much faster results for the Queues..... (Still slower then LV2 global though)Shane, I tried that and got MUCH slower results overall, although the queue and the LV2 were more similar.
QUOTE
There are some little things allready taken care for in the queue solution that isn't available in the LV2 global, like prevention of getting old data.Ton, what do you mean by this? How could you get old (I assume you mean previously read) out of a LV2 global?
Thanks again,
Gary
-
QUOTE (Ton @ May 4 2009, 04:32 PM)
I am suspicious about the array building as well.I haven't looked at the LV2 code, but I don't think that a queue using to store all data and read that as a burst using 'Flush Queue' is standard procedure.
To be totally fair I wouldn't include the 'Destroy Queue' in the timing, one other thing is that preset the size of the LV2 global, something you didn't do for the Queue. You only have an overflow flag to detect the slow 'dequeuing' of data.
There are some little things allready taken care for in the queue solution that isn't available in the LV2 global, like prevention of getting old data.
Ton
Thanks, Ton.
I'll try some of those suggestions tonight, like rerunning with the queue preallocate and removing the Destroy queue. I'll post results later, so long as the kids let me work

Gary
-
QUOTE (Gary Rubin @ May 2 2009, 11:00 PM)
Download File:post-4344-1241463223.zip
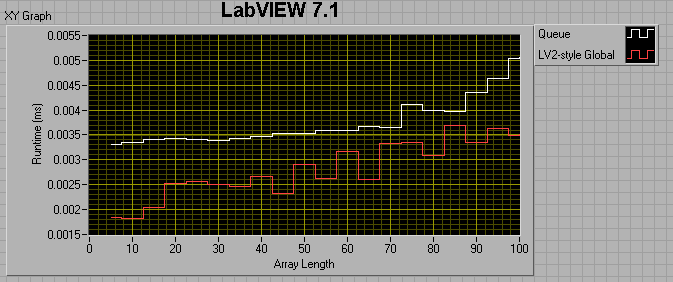
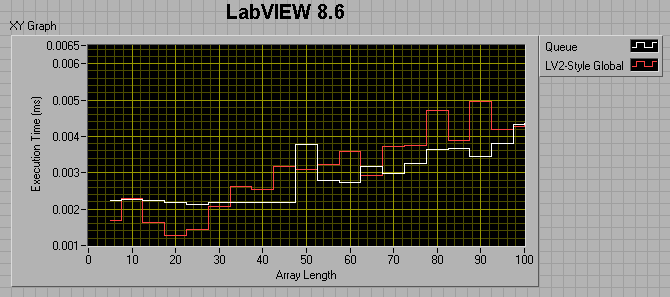
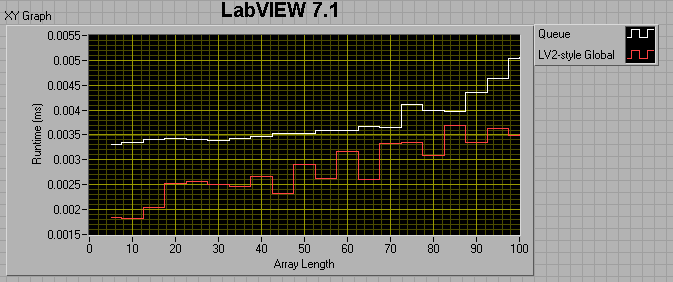
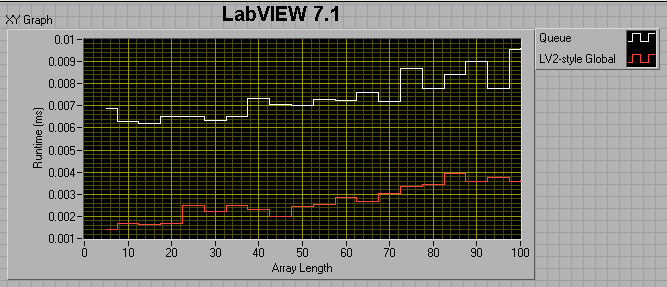
If the producer loop has a 0 ms wait, and the consumer loop has a 1ms wait, I get the following results:
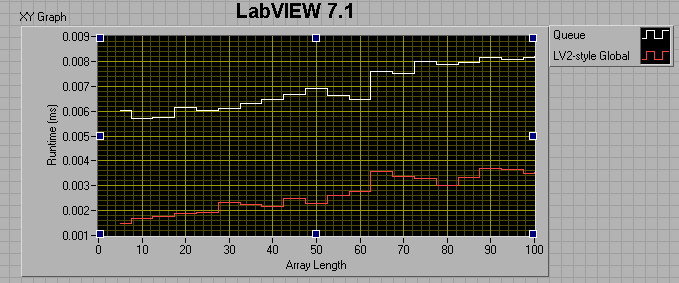
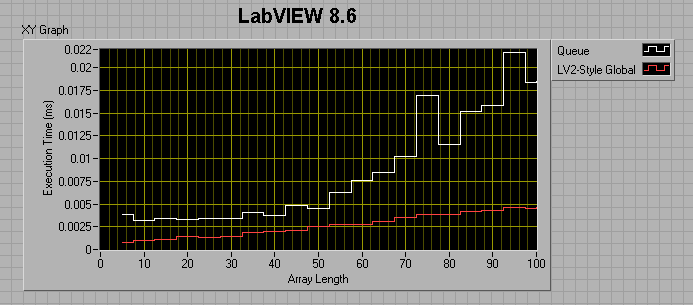
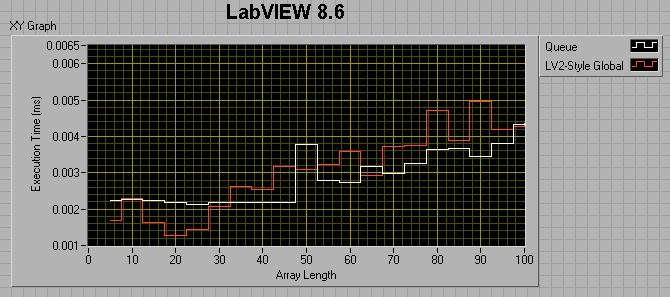
If I change the consumer loop wait to 0ms, I get the following:
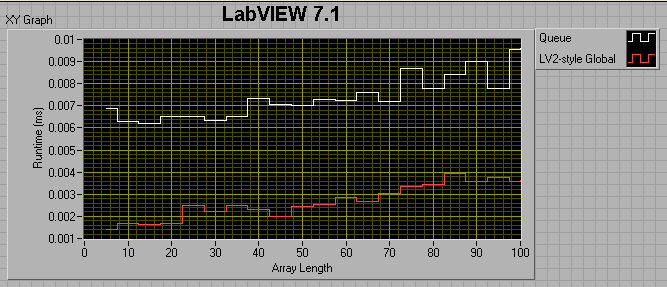
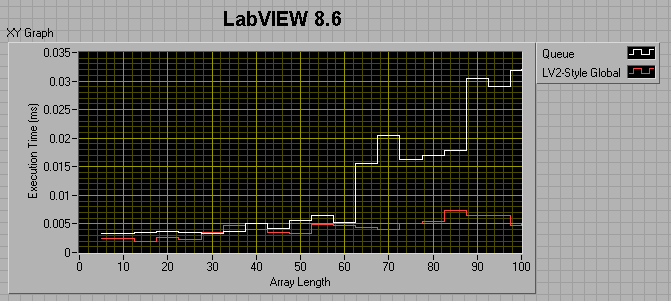
I thought maybe I was comparing apples to oranges, in that the LV2 FIFO uses preallocated memory, while the queue does not, so I tried preallocating the queue by filling it up then flushing it prior to entering my sequence structures. This did help, but not by much. For a 100 element array, preallocating the queue reduced its runtime by about a factor of 4, but it's still twice as slow as the LV2 FIFO.
The take-away message seems to be that 8.6 Queues are faster than 7.1 queues if the number of elements in the enqueued data is less than ~50. After that, 7.1 Queues are faster. Also, LV2-style FIFOs have the potential of being much faster than Queues.
I would love to have someone shoot holes in this, or tell me that I'm not doing my comparisons right. One of my suspicions is that, because I'm timing both the producer and consumer together, it's the build array in the dequeue consumer loop that's killing me, but is there any other way around that? In the meantime, I'm going to be thinking hard about changing over all my queues to LV2-FIFOs. Are queues are just not meant to be used as deep FIFOs for passing data between loops?
Gary
-
QUOTE (Aristos Queue @ May 2 2009, 10:33 AM)
Download File:post-4344-1241319157.zip
Download File:post-4344-1241319209.zip
If someone else can confirm these results, are there any workarounds? A 25% slowdown in my producer loop (based on enqueue performance) is unacceptable for my application.
Also, I just saw my typo in the topic title.

-
QUOTE (PJM_labview @ May 1 2009, 12:43 PM)
I have had a lot of questions about the profiler since LV 8.0. I believe something was changed somewhere so that it does no longer behave quite the same way that in previous LV versionI won't disagree with that, but my second attempt using timers in the code seemed to show the same general behavior that the profiler showed.
-
-
QUOTE (neBulus @ May 1 2009, 09:28 AM)
I think you're onto something there, Ben, but I'm not sure what to make of it.
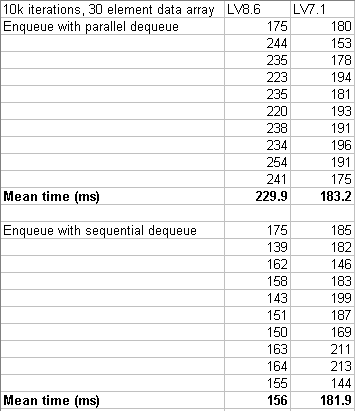
Here are the results:
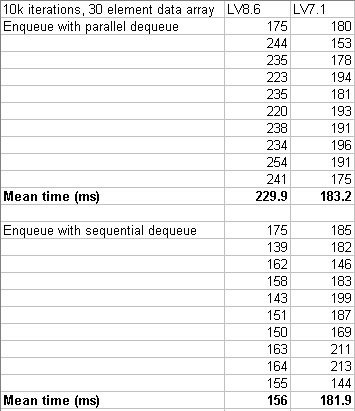
I guess the sequential results are more like what I'd expect; LV8.6 is more efficient at allocating memory for the growing queue.
I am surprised at the parallel results. Am I really to understand that a version of LabVIEW that was written back when everyone was on a single CPU is better at parallel tasks than one that's been developed in the world of multi-processors?
Incidentally, the 25% difference between the two is consistent with what the profiler was saying.
-
QUOTE (neBulus @ May 1 2009, 09:28 AM)
so the dequeue maybe taking loanger since it is waiting for something to show up in the queue.One of the reasons I'm wondering whether it's a red herring coming out of the profiler is that both versions report that the dequeue subVI takes 0.0ms. In fact, changing the display in the profiler to microseconds, LV8.6 claims the dequeue subVI takes 0us. Not sure I believe that.
-
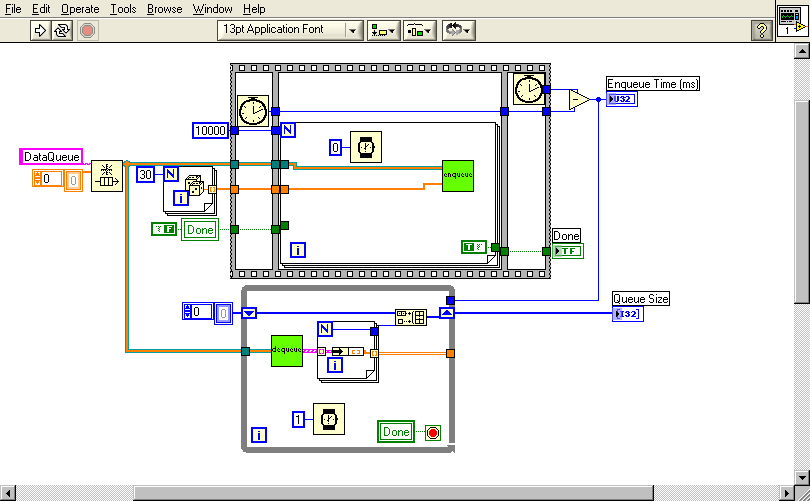
Hello all,
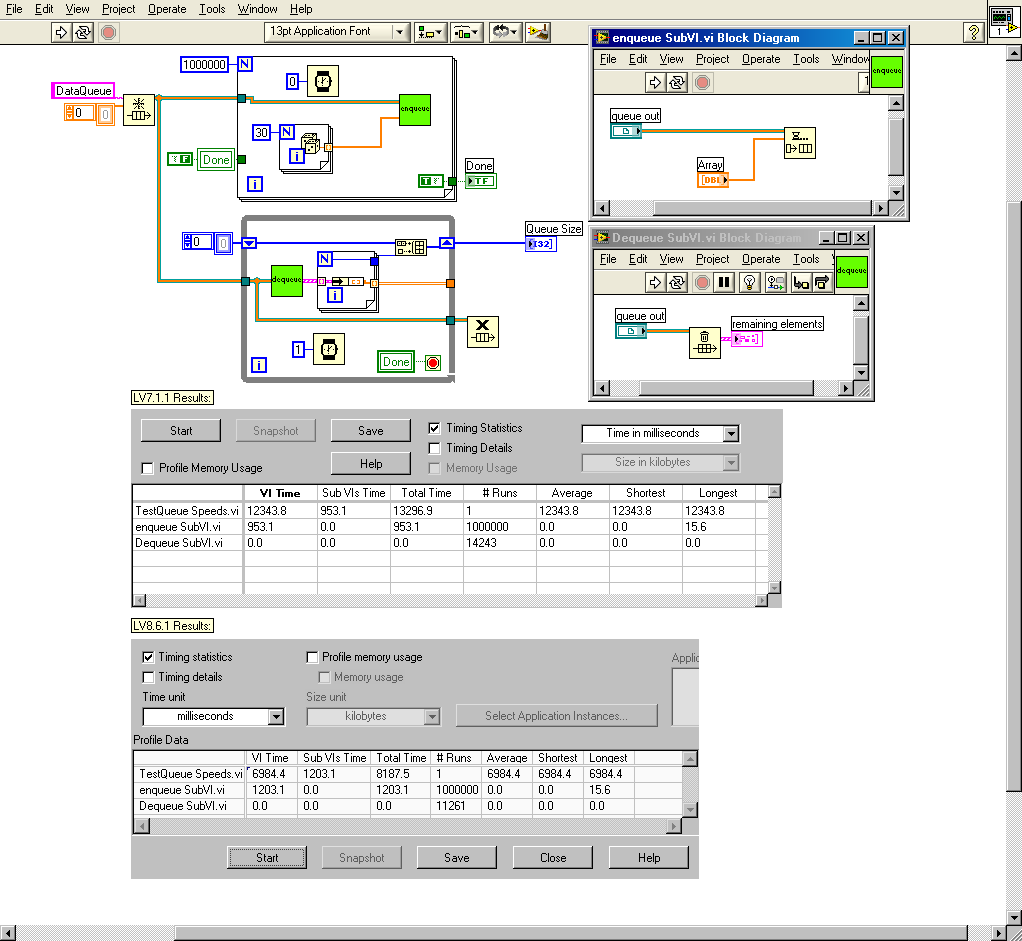
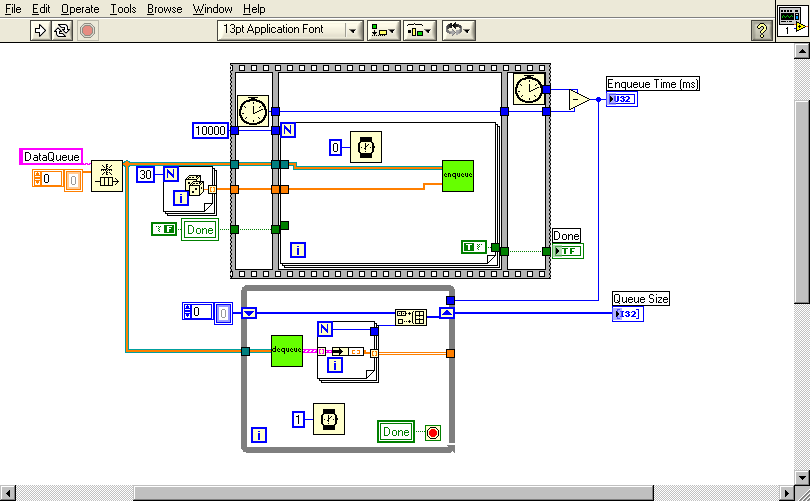
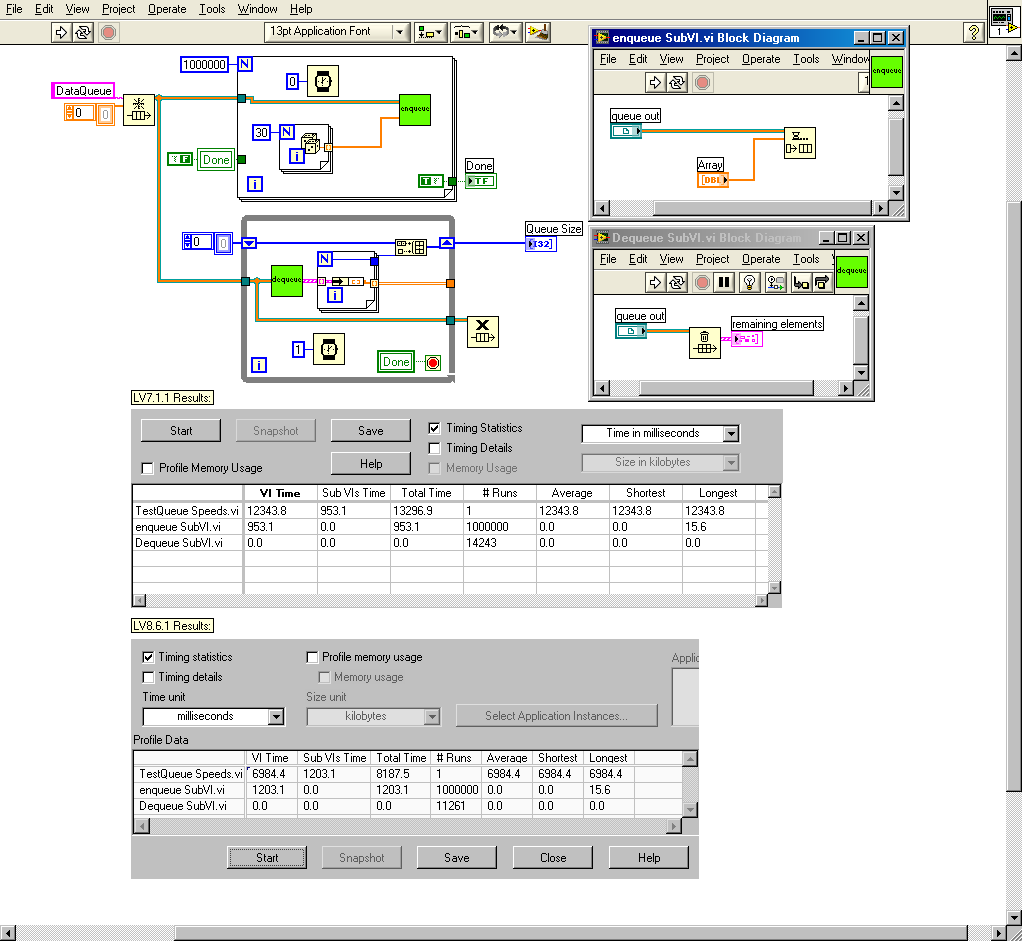
As I indicated an a post last night, I am working on transitioning some code from LabVIEW 7.1.1 to LabVIEW 8.6. Because performance is very important in this application, the first thing I did was benchmark the execution times for the two versions using profile. I found something surprising that I'm hoping someone can corroborate and/or explain. I noticed that a lot (but not all) of my subVIs were faster in LV8.6, but that those involving queues were quite a bit slower. To check this out, I did the test shown in the attached picture.
The reason I wrapped the enqueue and flush queue in subVIs was just so I could use the profiler on them. Both the subVIs are running in Time Critical Priority with debugging and auto error handling turned off. The Top Level VI is normal priority, but also with debugging and error handling turned off.
These results are typical of what I saw for my real code; The top-level VI is MUCH faster in 8.6, but the enqueue is considerably slower.
So, what's going on? Is this speed difference real, or a by-product of using Profile? Are 8.6 queues really slower than 7.1 queues?
Thanks,
I'm sure I'll be posting more as I explore the 8.6.
-
I am trying to transition some code from LabVIEW 7.1.1 to LabVIEW 8.6.1. Quite a few of the subVIs are set to Subroutine Priority, including one that calls Median.vi.
For LV7.1, I made a copy of Median.vi in my library, and was able to change its execution to subroutine priority.
In LabVIEW 8.6.1, LV replaced my libary's version of Median with its own version from the base analysis library. I noticed that I could not change the execution priority on that one, nor could I save a copy of it elsewhere (the Save As option was greyed-out). I am able to replace the LV8.6 native Median with the one from my library, which still gives me control over the execution, but it leads to a question: if I want to change priorities on such low level functions, can I do that from 8.6? or do I need to keep LV7.1 around just to give me that ability?
I also noticed that in LV7.1, I could open the Call Library node in Median, but could not in the 8.6 version.
Thanks,
Gary
-
I like this one:http://xkcd.com/253/
-
QUOTE (crelf @ Apr 23 2009, 11:10 AM)
<trying not be feel offended> Of course that's true when talking about about an array that is indexed by the loop </trying not be feel offended>, but my understanding was that we weren't talking about that - we were talking about an array where the size is not defined by the number of loop executions.Ah, good point.
-
QUOTE (crelf @ Apr 23 2009, 10:13 AM)
There's no way for the For Loop to know how many elements are going to be in the array...If the loop is indexed, there sure is a way for the loop to know. I'm sure I've read an app note for 7.1 that concurs with Ben's statement. Trying to find it now.
EDIT:
Here we go - app note 168:
QUOTE
If you want to add a value to the array with every iteration of the loop, you can see the best performance by usingauto-indexing on the edge of a loop. With For Loops, the VI can predetermine the size of the array (based on the valuewired to N), and resize the buffer only once.I don't know if something under the hood in LV has changed since then that makes the preallocate and replace faster.
-
I've just started using the LabVIEW NXT Toolkit. Is there any explanation of the provided VI's. I'm looking at this, but it doesn't seem to descibe the toolkit VI's. It looks more like what the toolkit developers used than documentation for what they created. There's no help on the toolkit VI's either. I feel like there's must be some documentation out there that I haven't found yet.
I'm looking for information on how to perform a non-continuous motor rotation.
Thanks,
Gary
EDIT:
I still haven't found the documentation that I would like to see, but a least I found the VI's that I was looking for.
I was in the direct command palette, and hadn't even noticed the Toolkit palette.
-
-
Boolean foreground/background colors
in User Interface
Posted
According to the documentation for the Boolean Color property, the order of the color pairs is Foreground, then background. This seems to be the opposite of the way it works (see attached).
Download File:post-4344-1242664470.vi