ragglefrock
-
Posts
105 -
Joined
-
Last visited
ragglefrock's Achievements
")
Newbie (1/14)
0
Reputation
-
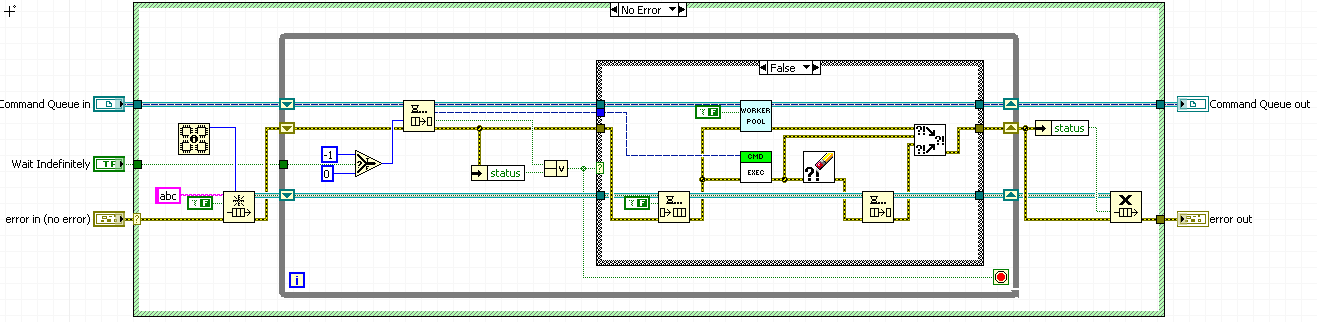
I believe I was correct. I'm attaching the prototype code I've been working on. If you put a single-element mutex around the Command Queue and have each clone exit if they can't acquire the mutex, then you end up with exactly one clone waiting at any given time. The only exception is the time between a clone receiving a command and spawning the new clone to start listening, but this time is constant and bounded. Adding this new mutex means you now must force the Command Queue to have an infinite timeout, but that seems very acceptable. The root caller can always simply kill the queue after it registers all commands have been processed if they wish. The code I'm attaching tests this by having each Command Execute method pop up a front panel with a Stop button. This allows you to test the execution ordering. The most recent Worker Pool to look at is Worker Pool with Limit and Queue Lock.vi. Hmmm... Another flaw here. I never actually successfully seem to reclaim or reuse any clone instances in this case either. The problem seems to be that you can't wait for the queue again unless you're the last clone in the Worker Pool chain. This also implies that the last clone in the Worker Pool chain is always free to start listening to the Command Queue, because by definition no one else can. This leads to the fact that we always create new Worker Pool clones, because we never can reach the case where a clone tries to listen to the queue and fails, which is what shuts a clone down in my scenario. Back to the drawing board... Worker Pool.zip
-
Yes, that is true. Is there any way to reclaim or reuse reentrant clones then in this design pattern? If you continue with the idea of having a loop in the Worker Pool clones, then I believe the idea comes down to the fact that you only ever need one clone waiting on the queue at a time. More than that is wasteful, because any clone is capable of starting a new listener as soon as something is enqueued. But on the other hand you have to always have one listener or you encounter the situation you described. I think protecting the Command Queue with a single-element lock could solve this. If you try to access the Command Queue while the resource is locked by another clone, then there's no reason for you to continue executing and you can shut down.
-
And one last refinement option. You can insert an extra queue (or some such resource) to artificially limit the number of worker threads that can be activated at any given time, regardless of the size of the actual Command Queue. For instance, in the example below I limit the number of workers to the number of CPUs in the system. Here I used a named queue as the shared resource, but there are many other ways to abstract this out.

-
One thing that came to mind as an interesting use case for this was in the context of a Queued State Machine. I had started prototyping a QSM architecture built on LVOOP, where each state was defined as a class overriding a base State class that had an Execute State dynamic method. This would allow you to dynamically add states, even at run-time, as well as populate a queued state with specific data and properties to control how it executes. It seemed like a nice idea, but quickly got a little washed out when I thought about how it might be awkward to actually use the darn thing. But... it's starting to sound interesting again because of this. Imagine now that the engine that executes the queued states is some form of the Worker Pool. We could then have a QSM that can asynchronously handle certain cases if they don't require a strict ordering. Sometimes you would want to assume that state A finishes before state B starts, so there would have to be a way to either dispatch the state to a synchronous or asynchronous execution system, where the asynchronous system is much like your Worker Pool design pattern.
-
Ah, indeed. That doesn't make very much sense, does it? I think what I needed was a while loop inside the worker pool VI to accomplish what I was describing. One question: what does this give us over just using a parallel for loop? I vaguely feel there's some differences, but I'm not 100% sure what they are.
-
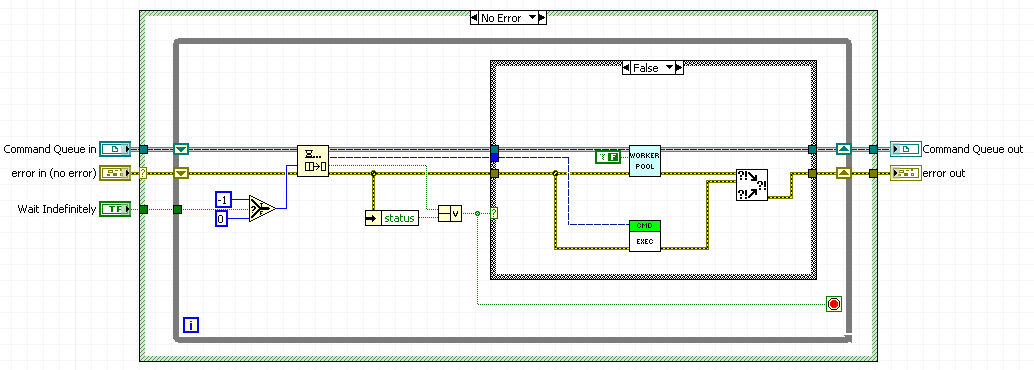
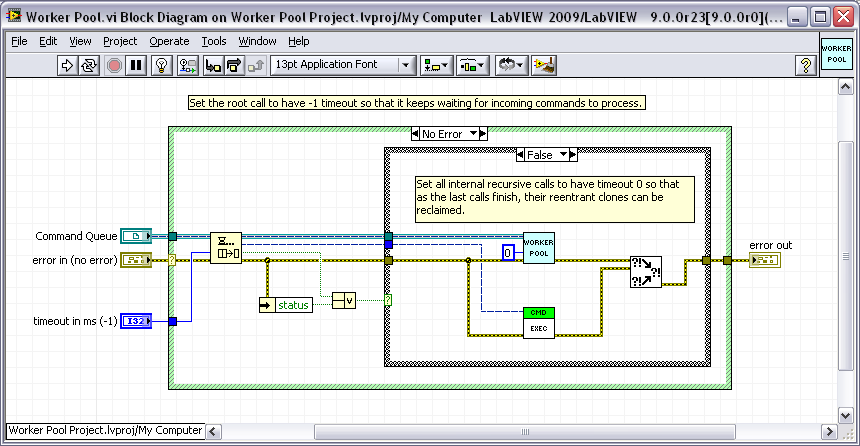
I might add one thing to your Queue-based pattern. Currently, you have the queue wait indefinitely for a new command to process. This works well if you enqueue all your commands at the same time. But it's possible you might want a pattern where you can keep enqueuing commands asynchronously. In the current design, you would never get to reuse any of your shared reentrant clones, because the last recursive call to the Worker Pool VI is still waiting on the queue, so the entire stack is blocked. I would add a variable timeout to the queue function. The idea is that the root call has timeout -1 if you want it to run indefinitely, but all inner recursive calls have timeout 0, so that as the last clones finish, their reentrant instances can be reclaimed by the pool and reused. You can also set the root timeout to 0 if you want it to stop as soon as the queue is ever empty.
-
Really cool! I would never have thought to use recursion this way.
-
Calling a .NET function on another machine (LV and T-stand)
ragglefrock replied to jed's topic in Calling External Code
Check out WCF (Windows Communication Foundation). It's designed to allow easy and abstracted network communication using .NET classes and interfaces. It's pretty extraordinary technology if you have some C# or VB.NET skills. -
More fields in Project Explorer?
ragglefrock replied to Gary Rubin's topic in Development Environment (IDE)
These fields could be bad for load performance if they require the project to load the VI to query them. Currently the project doesn't have to load all VIs that it references, though there are exceptions. If load times get any worse, projects won't be usable at all. -
Execution System Oddness
ragglefrock replied to Gary Rubin's topic in Application Design & Architecture
I would generally only select differenct execution systems for subVIs that will run continuously in parallel with other operations, not subVIs that simply process data and return immediately. If you, for instance, create a subVI out of a consumer loop in a producer/consumer architecture, that might be a good candidate for a separate execution system. But that's probably really only necessary once you start developing a very parallel system. -
Get a ghost writer! Everyone does it! I'd recommend this person, who appears to be the most intelligent writer of our time. And he writes sci-fi, which is kind of like programming. More info on the author and the book.
-
QUOTE (Sonny @ Jun 4 2009, 08:32 AM) Again, for higher transfer throughputs you will have to transfer larger sets of data. Instead of having a network queue of scalar doubles, have a network queue of an array of doubles. Transfer 100 or 1000 points at a time. This will drastically increase performance. It's not really the data transfer that is slowing things down, it's the overhead of communicating with the target, waiting for a response, etc.
-
QUOTE (dcarroll @ May 28 2009, 12:02 PM) You can also look into using http://en.wikipedia.org/wiki/Windows_Communication_Foundation' rel='nofollow' target="_blank">Windows Communication Foundation utilities for inter-process communication. TCP/IP might be simpler unless you require some advanced functionality. It's really neat technology, sufficed to say...
-
Load Only FP into memory
ragglefrock replied to LAVA 1.0 Content's topic in Object-Oriented Programming
Or require that the plugins belong to lvlibs. You could then just load the associated lvlib and check for a User Tag or something. -
QUOTE (Sonny @ May 12 2009, 04:57 AM) I think due to the nature of the VI Server implementation, there's simply a high overhead of making the queue function calls. You can likely transfer data faster by building larger packets of data and reading the queue less often. For instance, if you are sending arrays of doubles, try sending 10k at a time instead of 1k. Sending the data itself is not as likely to be the slowdown as the remote function calls. If you are not sending arrays but rather clusters over the queue, consider making the queue send arrays of those clusters at a time. Or try flushing the queue periodically instead of just reading one packet at a time. I didn't do any official benchmarks, but the size of the data packet transferred was very much related to the total bandwidth possible.