Autodefenestrator
-
Posts
13 -
Joined
-
Last visited
-
Days Won
1
Recent Profile Visitors
3,021 profile views



Autodefenestrator's Achievements
")



-
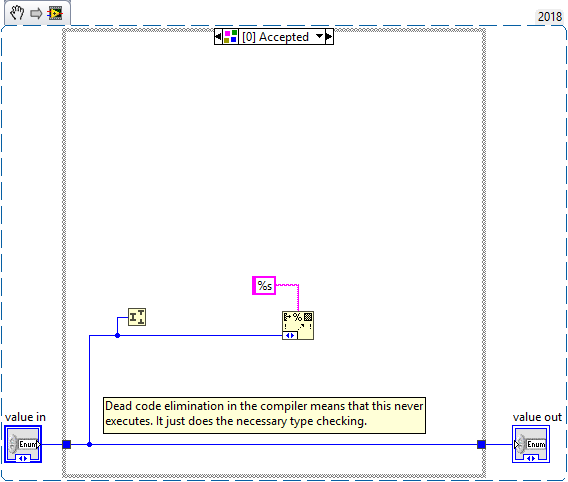
So I wanted to make a VIM that was essentially "Convert input into 1D string array". If you passed it a 1D array of anything it would convert each element to strings (similar to the debug VIM that ships), but passing in any scalar would do assorted things depending on the scalar (single item array for things like numerics, but a Path would split into each component, and different methods for other types). I thought it would be a good idea to have an option that if an enum is passed it, the array passed out would be the list of all of the options converted to strings. They way to get this is "Get Numeric Information" on the Data Type Parsing palette, but it uses a Variant input and therefore allows any input. And there was no "Assert enum" on the "Assert Type" palette. So, I've made one: It seems to work with every data type I can think of, because I don't know what besides an enum is a valid input both for a %s input to a "format string" node, and can also be an input for the "split number" node. I was wondering if anyone else can think of anything that is a valid "%s" conversion (like string, path, VISA reference, assorted DAQmx references) that is also valid for "split number". I am hoping to avoid discovering a data type later on that I didn't think of that also accepts this case and breaks "Get Numeric Information". Assert Any Enum Type.vim

-
- 5
-

-
I'm currently doing some driver creation in advance of getting actual hardware hooked up. One of the things I have to do is use a TEC temperature controller. This will be used on multiple stations with identical functionality, but we sort of "scrounged" for instruments, so we couldn't get the same model of TEC controller everywhere. We have 3 different ones (Newport 3700, Keithley 2510, ILX LDT-5980 if it matters). What I'm trying to figure out is if the PID constants that can be set on these devices are universal or not. They'll all be using the same sensor (10K thermistor) and the same TEC (with adapters for the different plugs), and theoretically they'll all be using voltage set points to drive the TECs. Basically, I would like to tune the PID for one setup, and then just be able to copy those values over to setups using the other two TEC controller models. But right now I can't tell if those PID constants are equivalent across all of the devices or not.
-
For reasons of which I am not 100% aware, the decision was made before I was brought on that direct data write access to the local database would be disallowed, and instead it would only allow stored procedures to be run that targets the local file. I think it's done because of a combination of reasons (encapsulation of the table structure, a security level flag we have to attach to each piece of data in the DB for reasons I won't go into, etc). I admit it would simplify things to have direct DB writing as the data storage. I am at this very moment only attempting to design a universal data storage method and not worrying about the sequencing aspect. We do have TestStand on some of our stations and are trying to roll it out to more of them, but I know that we'll never be able to switch 100% to TestStand for some of our processes, so when designing a universal solution it needs to be able to work both from a full LabVIEW application and from VIs called by TestStand as it runs. However I do see that instantiating a worker for each DUT (or one worker per class that handles an array of DUTs of that same class) addressable by serial number and sending it a message whenever a piece of data is available may be a better solution. I think I was fixated on converting the global clusters that the old versions of the applications use (where they constantly unpack a cluster from a global VI, read/modify it, then put it back in the same global VI) to a by-reference method that I didn't think that maybe sending messages to a data aggregator of sorts might be a better idea. I think I'll pursue that idea further and see what I come up with.
-
I work in an environment where we really don't ever want to lose test data once we've taken it. Many of the tests we do are either destructive (i.e. one time only, then the DUT is dead) or require very long test times that we don't have the production bandwidth to spare on a retest if we can avoid it. We already have a 3-step system to ensure test data isn't dropped due to network or database problems. Instead of just issuing a command to write to the database when the test completes, we first write the data to a local file on the hard disk. Then have a compact database running on the local machine import the data from the local file. Then the local database syncs its successful imports with the main database once every few minutes. We're in the process of trying to standardize our company's code instead of having a bunch of use rewriting the same procedures multiple times and in different ways, with too much duplication of effort and chances to add new bugs. So one of my tasks at the moment is to come up with a common method for everyone to use that does the best job possible of ensuring test data is never dropped. The LVOOP white paper says that "less than 5%" of cases have a need for by-reference objects. I think this is one of them. We want to use classes for data saving so we can add functionality to child classes without having to redo all other tests that use the parent class. The (extremely simplified) process is something like this: 1. Create one set of test data for each unit about to be processed, indexed by serial number, available globally. 2. Do any manner of tests, possibly with many tests running in parallel. Abort on error or operator cancel. The instant test data is acquired it is added to the test data corresponding to its serial number. In some cases test data is dependent on previous test data. 3. Handle then clear any errors. Then save all test data, including partial data sets caused by cancellation or errors. As I see it, my options are: Standard VI globals: Bad for many reasons well known everywhere. FGV: The amount of different types of data and operations performed on it make this unattractive due to the complexity that we'd have to fit in one VI More "standard" methods of LV by-reference (i.e. 1-length queues or other blocking methods): Require extremely diligent coding to ensure the reference isn't left "checked out" and might not be "put back" in its holding area, making it unavailable for the final data saving LVOOP class data converted to a DVR and stored in a FGV that has only 4 functions (clear/new/get/delete) using serial numbers as indexes, returning a DVR of the top-level test data class when called. One wrapper VI for each child class downconverts it to a DVR of that child class. Operations are performed on the data using Dynamic Dispatch VIs inside of In-place structures. Since the in-place structures both block other in-place structures using the same reference while they are running, and absolutely require a matching object to be put back in the DVR during code creation that can't be skipped during runtime. Obviously I am leaning towards the last option but before I start a big project I'd like to make sure I'm not using an architecture that is going to cause problems in the future that I don't see right now, or if there's an easier solution that I don't see that has the same amount of data integrity. I'd like to hear input if anyone has done anything similar and it worked well or if I'm missing something. Thanks!
-
I work with a small-ish (5-6) team of developers at my company. We're trying to update and improve a lot of our old test station software and we've decided to try using TestStand for sequencing instead of writing a custom sequence for each test station and product, or trying to write a generic but highly complicated sequencer ourselves that could work for every test station we have. In order to keep things as modular as possible we'd like to come up with a set of rules/guidelines that we all agree to follow in some manner, so we can assign one person to develop for tests using one type of hardware, one for a different type of hardware, one to do all of the database interactions, and so on, but with the requirements and interactions for those clearly defined enough such that there's no unexpected interactions between VIs. We'd also probably need to put in place a few new coding guidelines, such as perhaps a ban on global variables, trying to cut down/eliminate passing clusters/objects between VIs and passing primitives instead, and so on. I'm just curious if there's anyone out there who has done something like this before and maybe has any advice for things to establish before getting started. It's much easier to do things as right as possible from the beginning instead of waiting until we have hundreds of VIs written in an inconvenient way and we have to make the decision whether to rewrite them all to be "right" or to work around them even though they are "wrong", etc. Thanks!
-
I actually didn't see that table before, I was looking at a different page. I think that the reason "mainstream support is ending" would probably be a good enough reason to push through getting some new versions in. They may see that it's August 2015 that it ends officially and try to push it out a quarter or two but that could work. The non-IT guys can understand that a lot better than developers wanting the newest version of something because it's "shiny".
-
Ah, I didn't know that. That's actually an argument that has the advantage of being both true and being understandable by someone who isn't a developer but has to approve our purchase reqs... Given that preinstalled Windows 7 installs for all of the Home versions already have a set stop date by Microsoft, I think that could be a good argument to make. The strategy of building executables is one we'd like to move to everywhere, but currently it only seems feasible with software revisions that haven't been changed in a year or so, as many of our processes need slight tweaks month-to-month as we have a lot of new products that keep adjusting their specs slightly. We do have plenty of stations that we have executables for... just not enough to only need exactly 4 or 5 licenses.
-
Hmm... I wonder if the NI rep can tell me how many licenses my company owns and at what revisions. I've been having trouble tracking down exactly what versions and how many we own and what exact versions/privileges we have.
-
Hi, I work for a medium sized company with a small dev group (I'm one of 4 LV people at the moment, with maybe one new hire soon). We're currently using LabVIEW 2011 for all of our development and deployment on new stations, mostly because we bought a bunch of licenses in 2011 and didn't upgrade them after that. We have a few 2009 or older full licenses on older stations, 2 LV2012 licenses that I could find (one full, one developer), and one 2013 developer, and then for 2011 we have something like 3 developer licenses and probably 10 or more full licenses. In the future we're going to try to stick more to compiling EXE files and deploying those instead of putting the full license on the station and running it like that for extended time frames. So if we upgraded versions just for the developers and maybe a couple of other ones for testing before replacing with a compiled EXE, we could probably still be fine. From time to time I will look around to see how to accomplish a task in LabVIEW, and find that it's either not easy or not possible in LV2011 but is in a future version of some kind. I've also seen examples of code that seem to have improved block diagram commenting and some helpful programming methods added, but it's hard to quantify how much of that stuff would help and how much time/money it might save in the future. I've yet to come across a task that is flat-out impossible in LV2011 though. Can anyone share if they've dealt with something like this before, or have a better notion of what time savings might come (either to the developer or in reduced bugs on the end station) from moving to LV2013 or 2014? Specific examples would be great if possible, though I will understand if some of it is company confidential code.
-
Right now I'm thinking that we have a big directory tree that we put all of the instrument classes in, and put that in the instr.lib directory. Devs would update it regularly; working stations would only upgrade it if something is changed and the version they had no longer works. The root class plus each of the child classes would each have a .mnu file in their directories, so all of the VIs would be accessible using either deep-browsing the default palette, adding only the relevant .mnu files to a customized palette, or using whichever form of quick drop they prefer. We already kind of do this for the VIs we use for interacting with the database that we use, but in the user.lib directory instead, and no major issues with that so far. Individual projects would be in their own project directory and repository, somewhere outside of the National Instruments directory structure.
-
I don't think we want to overlay this on top of the Actor framework. I've looked into that in the past and there are a number of reasons why it probably isn't something we would benefit from, both because of the initial overhead in setting everything up plus the fact that my co-developers are just wrapping their heads around OOP to begin with. Queued message handlers may be used on a case-by-case basis. I've used some hardware before that the only way to interact with it was with a .NET object dropped onto a front panel somewhere with a long series of setup commands before it is ready to run instructions, and that sort of device would definitely use one. Something simple like a 1-channel power supply would never need to do that, which is a lot of what we use. For those instruments that wouldn't use a QMH but might be called from 2 different threads at the same time (I'm thinking of multi-channel devices of some kind) the classes by reference concept is an interesting one. I'm not sure I like the 1-length-queue method the example uses, but some method of being able to not get query/response pairs in parallel threads mixed up seems like it could be handy to have as an option. Something else I was wondering... we use Subversion with TortoiseSVN as a repository. Has anyone found a "best" method to share home-grown instrument libraries across dev machines and deployment environments? Perhaps one where each separate basic instrument type has it's own menu on the tool palette?
-
We do in fact use many different models of Tektronix scopes. I know of at least 5 models in use at the moment. The programming manuals for each are very similar and in many cases they share the same manual with the occasional caveat on some of the functions such as "(Model XXX only)". Our code is also probably not going to go public either, I understand. However, are there any generic things you can share that you discovered in your case? Pitfalls, things you didn't think of at first but found that you needed later?
-
I work for a medium-sized company with 4 full-time plus a few occasional developers who use LabVIEW, me being one of the full-time developers. The company isn't that old, and apart from me none of the developers have formal Computer Science training (i.e. they are engineers who transitioned to it gradually). Right now we're getting to the point where we need to start being a lot more efficient in our re-use of code, as currently we pretty much assign one developer to one station, and then most of what they write isn't applicable to any other station. So what I have proposed to them (but nothing officially done yet) is that we switch to a hierarchy of classes that would allow for re-use of effort, so instead of writing 10 different VIs for "Read voltage" for 10 different test stations using 3 different instrument vendors and then re-writing a bunch of code when we discontinue using one of the vendors, we'll use inherited classes to abstract it all out. The hierarchy I am thinking of is basically: Base Instrument (everything) -> Instrument type (i.e., multimeter, oscilloscope) -> Specific instrument (i.e. Tektronix DPO3054 oscilloscope) OR Base Instrument (everything) -> Instrument type (i.e., multimeter, oscilloscope) -> Manufacturer (i.e. Tektronix) -> Specific instrument (i.e. DPO3054 oscilloscope) The idea is that we will have one "set up" VI that creates a reference to one specific instrument and model, creating a reference to the child class farthest down the line at the very start, cast it to the "Instrument Type" class, and then write a set of possible commands to the instrument type that are then overridden by the specific instrument class lower in the hierarchy. The "manufacturer" class would be there for vendors like Tektronix that have many shared commands that work across many of their scopes in the exact same way, but some of the more expensive ones have additional features. I've written a few sort of "proof of concept" VIs to show that it seems to work with simulated instruments but nothing beyond that. We'd like to get started as soon as possible but I'd like to make sure I don't make any initial mistakes that are going to kind of hobble us from the beginning if I do them wrong... so I was wondering if anyone else had done things like this before and could offer advice, or if anyone in general has ideas based on what I'm trying to do as I haven't used OOP in LabVIEW much before. Thanks!