Taylorh140
-
Posts
97 -
Joined
-
Last visited
-
Days Won
7
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Taylorh140
-

Has anyone experimented with operator overloading at all?
Taylorh140 replied to Sparkette's topic in LabVIEW General
So now i can just add my string instead of concatenating them! but joking aside, I feel like this should be an inherited property of LVobject. It's interesting if that is the way it works. usually for multiplies you would take the operation depending on the binary operator inputs types. e.g. if you add u8 and a single float something would have to make a decision that upcasting to a single float is the right decision. -
Yeah well the thread is labeled debouncing. But this can be used any time you want to be absolutely sure there is a transition in a boolean input. Say in a noisy environment you need to be sure that a transition is actually was that initial input really an edge? How can we be really sure? I did find this reference useful: https://my.eng.utah.edu/~cs5780/debouncing.pdf It shows how different the debounce on switches can be as well.
-
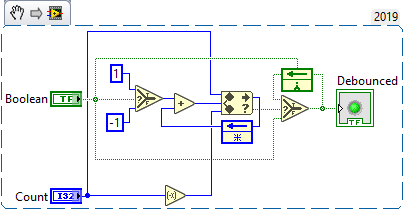
I do like the count. I was thinking about majority vote but it has the issue of being noisy around the 0 point. I think that this may correct at least periodic noise issue that the last method had: This method counts True +1 and False -1 and sums them until they surpass the count by one, only then does the input pass through. What i like about this: Simple enough Small periodic blips do not prevent state changes from ever occurring. Does not use time as a metric (but still need to be considered based on sampling rate) What I don't like about it: Uses two feedback nodes. (seems excessive). Functionally impure. (e.g. has statefulness although seems pretty necessary here) Looks messy compared to last implementation.

-
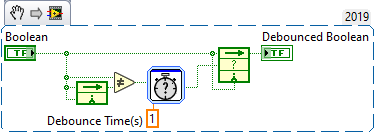
I debounced a boolean. I feel like it could be better. This should take the initial value as output, and requires consistency for one second to change value. I'm curious what's out there or what has been tried? What i like about this: Simple to understand What I don't like about it: Small periodic blips could prevent state changes from ever occurring. Uses time as a metric (I actually prefer non-time metrics, like voting algorithm as they need less consideration) Uses two feedback nodes. (seems excessive). Takes one call after debounce time to propagate output. Functionally impure. (e.g. has statefulness although seems pretty necessary here)
-
VIs, VIs everywhere but not a lot inside.
Taylorh140 replied to Taylorh140's topic in LabVIEW General
If you use a strategy not on the poll would you elaborate? I would appreciate it. -
So I really like the LabVIEW classes, but always end up with alot of vi's that do very little. I was curious what people do about it?
-
You know, now that you mention it. getTypeInfo might be the answer i was looking for the whole time. (i just remembered that i can scan the output and have a list of enumerated type descriptors instead of calling everything all the time.) #duh. So making a call to the get type descriptor each time will not be necessary. I implemented everything using vim's I like the flexibility but now i realize it was a bad idea because of how difficult it is to debug. For some reason I cannot cast a variant to a little endian representation of its data. which was one of the main hurdles here. Thanks @LogMAN
-
When doing flattening by iterating clusters. I make a crazy amount of calls to get type info. I was thinking it might be better to loop through the type string. From Variant to flattened string, But I dont have a good reference for how to decode. (I usually reverse the needed info from the openg library.) If you have any doc's or wiki pages to reference i would appreciate it.
-
I was working with some vims. and looking for a way to check rather the data was pink or brown. if brown i can simply typecast. but if pink i need to pad the strings to a fixed size. I didn't want to iterate the elements of the cluster to check for strings or arrays.
-
Turns out i used the wrong calling convention. C for the Labview.exe
-
@ensegre I can't get the snippet to work. @drjdpowell when i run this method i keep getting an issue with the ui locking up. I tried moving it to any thread. But it still only copies the string one time. Im attempting named shared memory. (attached file) I'm questioning calling the LabVIEW.exe from the LabVIEW.exe (should be ok right). SM_Host.vi
-
So I'm working on windows and i need to write bytes to a pointer location. I can use windows api functions but i would guess that somewhere there is a function that does this? And perhaps is more portable? How is it done typically?
-
LabVIEW portable pointer sized element
Taylorh140 replied to Taylorh140's topic in Calling External Code
Well that's way more useful than i thought it would be then. so no need to distinguish, and better portability. This makes much more sense.
-
LabVIEW portable pointer sized element
Taylorh140 replied to Taylorh140's topic in Calling External Code
So I'm a bit confused right now. perhaps you can set me straight on this. I'm running x64 windows and 32 bit LabVIEW. but when i'm Call Library Function Node and calling a dll from (SysWow64) the "pointer sized integers" are 64 bits? I would expect them to be 32 bit for 32 bit LabVIEW as i don't think it can interact with 64 bit dll's regarless of the pointer size. and yes I'm sure that 64 bits would hold the value. However, since we need to match the c prototype, it makes me think this will cause problems. -
Is there a Labview Type that changes from 32 to 64 bits based on rather your running a different development environment?
-
@FantasticNerd I don't make the rules, as far as this particular situation I can only speculate why. I would guess NDA would be required as well as other complicated approvals. In this case we are requesting a installer/setup procedure. but these things take time, in the meanwhile we are limited in testing. It's great the MAX/NIPM have a list of installed stuff. This is typically where i start too. Now wouldn't it be nice if NI just had a utility that looked at the exe, and made an installer that had all the components :).
-
It just so happens that sometimes I am suppose to reproduce a test system made by a customer. There may have been an installer at one point but no-one knows anymore and they don't want to share the source vis. In the past i have download each NI library installed on that particular PC and installed it on the other until i get it all to play nicely. However it takes some time and is quite tedious. Is this the only way?
-
@Rolf Kalbermatter I appreciate you mentioning this. I myself was weighing this. VI -> Smaller better for sharing examples but can have evil code in them. Slightly harder to make. Image -> Safer to share but lager and much more limited. Easy to make. I was originally leaning toward an image but, I think your right VIs are better. I don't think I've come across malicious VIs here, at least that i know of .
-
Be careful of Pragma pack when your trying to line things up for larger types.
-
I have old labview could you share an image of the vi?
-
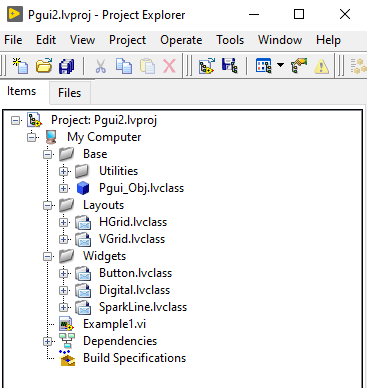
I added what I have to https://github.com/taylorh140/Pgui. It's only right since I copied the enabling technology right from this forum. I don't know if ill have a huge amount of time to work on this but ill defiantly try and improve it when I can. There is still a lot of things that would be nice to develop for this.
-
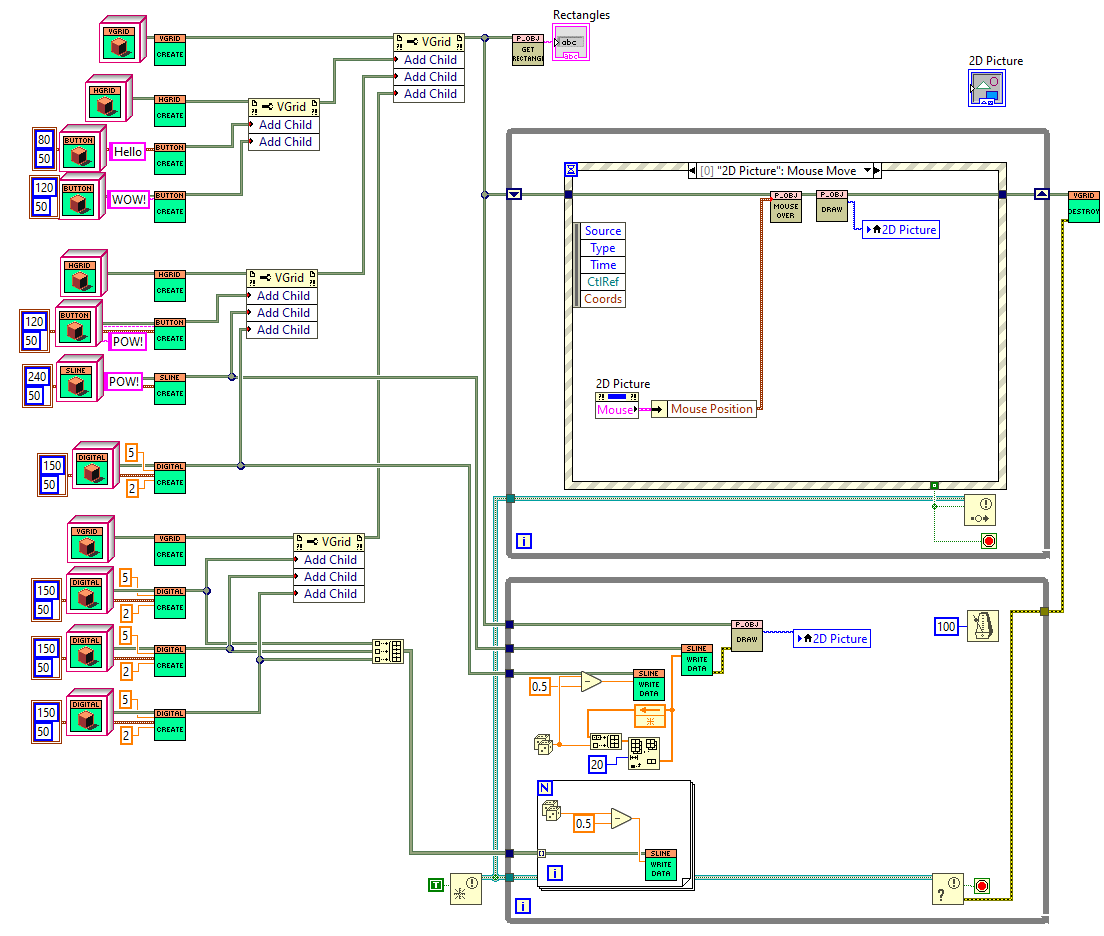
This is true. bad habit I guess. I used openGDS for this w/ EndevoGoop400, so far I like it. But it is still new to me so there are possibly design The enabling technology for this was from @Norm Kirchner so respect where it is due. Being able to translate images allows one to build a UI component and move it into place. Each drawn component can now pretend it is the only UI component on the picture control. I'll try to get a GitHub page published soonish.
-
Two questions about this: 1. Does something like this already exist? 2. Is this something that could be useful? Every once in a while I need dynamic UI components that can be generated at runtime. One nice thing to use for this is a picture control; however it doesn't lend itself as well to keeping other pieces of function such as mouse click events and such. I put together a mini library of UI functions for this that has the ability to be extended. The UI can be generated dynamically at runtime and be any picture thing that you can draw. Using Standard layout techniques that you might find in other GUI libraries. The hierarchy generation can always be simplified by using some type of templating string. Example1.vi Front Panel on Pgui2.lvproj_My Computer _ 2021-07-02 14-03-54.mp4
-
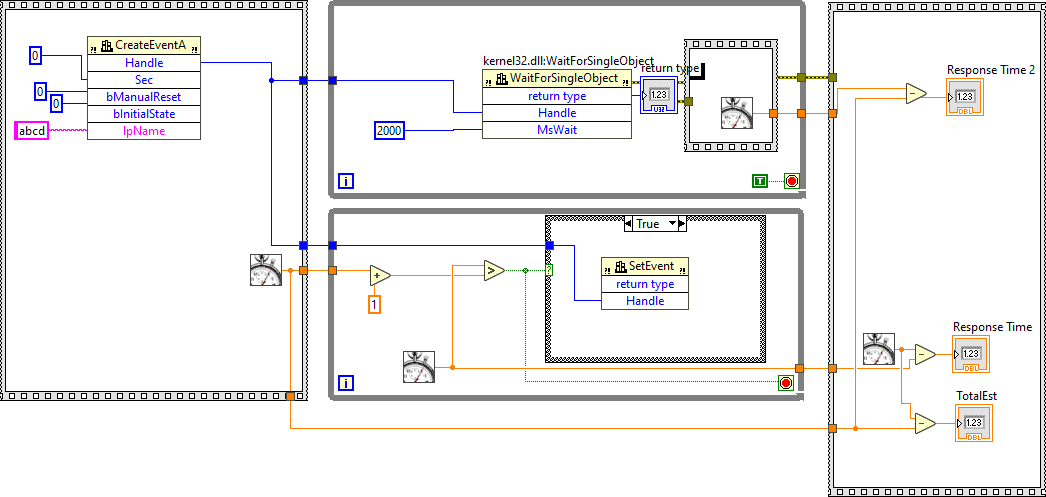
This may bet a better lead; It has a lot of similarity. https://docs.microsoft.com/en-us/windows/win32/api/synchapi/nf-synchapi-waitforsingleobject I have never seen this used. but it does seem to work. With similar performance.
-
Something we can both be glad about. I think I might have a lead. https://stackoverflow.com/a/35389291 But ,I'm still not sure what's going on there, they clearly did a good job.