

Omar Mussa
-
Posts
291 -
Joined
-
Last visited
-
Days Won
10
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Omar Mussa
-
-
We have a large LabVIEW project that is structured in multiple Git repos using Git submodules.
Within each Project we have our source organized into folders like this:
Project Folder Configuration Data Folder Source Code Folder
We typically do development on our development machines where the Configuration Data Folder contains configuration files that are in simulation mode and using atypical configurations.
We also deploy our development system onto tools during development and testing by cloning the repo onto the hardware supported platforms. On these machines, the configuration data is modified to remove the simulation flag and is further configured for the specific project being developed.
When we do a pull onto the deployed systems, we definitely want all the Source Code Folder changes but we generally do not want the Configuration Data. However, we want the Configuration Data to be tracked, so we do want it to be in the/a repo. Does anyone know what the best method to do this is?
What we don't want to happen is for the deployed system configuration data (which might include some machine specific constants, etc) to get over-written by some developer setting that was used for testing, but we still want to pull/merge changes onto the tool. Note that we have the tool on a separate branch from the development branch but when whenever we merge we can potentially get into trouble if we pull configuration data as part of the sync. Since the configuration data is text based, Git typically auto-merges these changes and so it can be difficult to tell that the merge affected the configuration data. I am curious if anyone has had this issue already and come up with a good solution/strategy.
-
I personally think of TestSuites as a way to group a bunch of tests into a common test environment rather than as a way to reuse a TestCase for testing multiple parameters. But I can definitely see the value of being able to set the displayed name of the test case on the VI Tester GUI and how it would help handle the situation you raise of re-running the same TestCase with multiple parameters.
The simplest way that I see to solve this problem is to just have 3 TestCases that share some common test code so that you can have easy to debug and use the three test cases to define the tests for each logger.
In this scenario, I think you'd have a test folder hierarchy like this:
Tests
Tests\Logger\DiskLogger1
Tests\Logger\DiskLogger2
Tests\Logger\InMemory
Tests\Logger\Common
The simplicity of this is that you can specify the specific tests for each logger, you don't have to worry about it being too complicated and you can add all three TestCases to a TestSuite if desired so that they can share some resources or be grouped for logical organizational reasons (or you can skip the TestSuite if you like). Most likely, this is the way that I would approach that problem.
The other way that is possible to approach the problem is to use test case inheritance. VI Tester does support TestCase child classes but you will have to make some tweaks to your code to make this work.
On disk you'll have something like this:
Tests\Logger\DiskLogger
Tests\Logger\DiskLogger.1
Tests\Logger\DiskLogger.2
Tests\Logger\DiskLogger.InMemory
where DiskLogger.1, DiskLogger.2 and DiskLogger.InMemory are classes that inherit from DiskLogger (which is the TestCase with all of your test methods). You can create the child classes just by creating classes from your project - you don't need to create them using VI Tester. You'll need to modify the test methods to use dynamic dispatch inputs and outputs (which will also require that the re-entrancy type changes to 'shared' - LabVIEW will warn you about this and its pretty easy to update). You'll also need to create over-ride VIs for any tests in your child classes that you want to execute (currently by default, VI Tester is conservative and assumes that if you don't specify a test VI to over-ride then you don't want to execute it from your child class). When you create a "New VI for Override" and specify your test method, by default the implementation is to call parent method so this can be done pretty quickly or via scripting.
After all that work, you can use your original TestSuite (the first image) and wire in a bunch of your child TestCases and each child will show its class name on the VI Tester Tree.
-
 1
1
-
-
12 hours ago, ShaunR said:
Hardly. It's like pitching your tent inside your house because you don't have a hammer for tent pegs. Sure, the tent is up. But now you have to move your entire house when you want to go camping! I get really annoyed with the Linux community who's only answer for any Windows issues is to install Linux (or Cygwin)..
I think another way to do Linux on Windows now is via Docker Linux containers... Also, Windows 10 now supports running Linux as a subsystem:
https://msdn.microsoft.com/en-us/commandline/wsl/install_guide
-
I would do the following:
Setup my Parallels VM to use Wi-FI from MAC in bridged mode
Make sure my Windows VM network adapter config is correct to reach the myRIO
Ping the myRIO - if no response then you have a network config issue
If still not working I would shut down the VM, restart the Mac and then start the VM.
Ping the myRIO - you should definitely get a response
Connect
(One other thought, you MAY also have a Windows Firewall issue, can retry with Firewall off if all of these steps fail but I don't think you should need to do that)
-
That's interesting and I definitely have never thought of that. Do you know what the differences are between the Matrix data type and Array data type? I tried a couple of OpenG 2D array operations out and they all seem to work ok on the matrix.
-
Also - since you're using python for the data processing you can use python's web server and avoid the legacy nightmare that is ActiveX.
-
1
-
-
I'm using plotly right now in an offline project (via the JS API) for displaying data parsed from csv data files on a Windows (10) machine. I embed a .NET browser on a VI and load a very basic html file that runs some javascript. From there, the way I see it there are two pathways:
1 - Run a local http server where the data folder is so that you can get the files through AJAX calls to get the file data.
2 - And I know this sucks but - utilize ActiveX so that you can use the file scripting object to read data files. I have my code setup to poll a specific file for date changed and if changed then to parse it and load it onto the plotly graph.
The benefit of option 2 is that you don't need to manage a web server. In order to make it work I have set the local machine as a trusted site and set the trusted site security to allow ActiveX. I went that route because I didn't want to manage an http server on my machine but YMMV.
The end result is that I'm using the 3D plot to generate really great looking graphs as data is acquired and the graphing code can be reused in future data vis. applications. No web connection needed.
-
1 hour ago, ShaunR said:
The OS condition is project only. When you deploy your package, the end user needs to have that in his project too (it also won't work if the VI is opened outside of a project). It is better to use the TARGET_TYPE (Windows, Unix and Mac) which doesn't require the user to do anything and works without a project file.
I think that in this case, the OS flag is OK even if its project only since you (typically?) need to be in a project to work on a target's code anyway (as far as I understand how working with targets works).
1 hour ago, hooovahh said:Will the steps mentioned also force LabVIEW to recognize the SO file as a dependency, and include it any builds? That's one issue I thought I remember having with Windows built EXE, when specifying the DLL path by the CLN input.
I'm not sure - actually think I may have messed that up and it may have just worked for the case where the dependency already existed where expected. I think VIPM builld process may grab it if its in the source folder of the package, not sure - would be definitely worth testing by deploying package to a new machine.
-
That's great! One other thing you might try - I think the build process should also work if the Conditional structure default case was "empty path" and that the "Linux" path was as you coded it - in that case it avoids the unnecessary hardcoded path to the .SO file in the unsupported cases (non-Linux). I think the code will still open as 'non-broken' if open on a Linux target context (as it should be) and it will open broken on a Windows context (as it should be). Its probably best that the code is broken when opened in an unsupported context - because its better to break at development time than at run-time in this scenario.
-
2
-
-
I would check the "specify path on diagram" and try passing the path into the CLFN node and use a conditional disable structure to pass in the extension (or hard code it to only support Linux targets). Best practice would be to create a subVI with the constant so that you use the same path for all instances.
-
2
-
-
FYI - I created a blog post on test driven development in LabVIEW using Caraya here:
http://www.labviewcraftsmen.com/blog/tdd-in-labview-a-caraya-approach
-
I've been using a mix of EtherCAT slaves (all third party, none are NI) for several years now connected to various NI cRIO controllers (9067, 9068, 9035) and I haven't had any major issues. So far, whenever I've had an issue its been because the vendor had an error in their XML file and contacting the vendor I've been able to get fixes in each case without too much hassle.
I would warn that if you are using a 9068 you should be aware of this issue: http://digital.ni.com/public.nsf/allkb/9038F4D0429DD7C686257BBB0062D3F3
In my case this issue was a showstopper so we switched to a 9035 which I would recommend looking at.
-
This is really good info, thanks for sharing your experience. For #2, are you dynamically loading your FPGA Bitfile from disk (I'm guessing you are not)? I have a feeling that if you did this, the RAD image would work (your bitfile would just be another file transferred via the image and the RT app would load the FPGA on startup from a known location on disk - I haven't tried this but I'm guessing this is how it would work).
Dynamically loading the FPGA might not be the best option for all deployment scenarios of FPGAs but it would probably insulate you from this issue.
-
If you use a custom FPGA, you need to recompile it for any change (unfortunately, even cosmetic UI changes
 - unless you are running the FPGA emulated target which you can do to validate simple logic, etc before you compile for hardware).
- unless you are running the FPGA emulated target which you can do to validate simple logic, etc before you compile for hardware).The RT code can run from source though without recompile (it gets deployed to RT target and then it runs and is debuggable more or less like desktop LabVIEW). I've personally had minor inconveniences where I had to reboot the target because the deployment for debugging failed but usually a target reboot is all that it takes to fix deployment issues during development. Once you are happy with your RT code, you can compile an rtexe that you can deploy.
-
As far as I understand it, the reason OpenG moved to a BSD licensing model was to simplify the licensing requirements so that the code could be easily used in commercial projects including LabVIEW based software products. Previously they were LGPL and it was actually difficult to use them because LGPL was more restrictive. It sucks that lawyers can make sharing so difficult.
-
I finally had some time to get back to this issue. In my view it seems that the PSP/Shared Var Engine seems to work best when you are sure that the target and variable will exist for the lifetime of your application. Reconnecting is definitely 'expensive' as is having non-existent variables (which force engine to try to reconnect).
I tried a few of these methods out today to see what would happen and I'm not sure what exactly to make of it but I figured I'd share for those interested. All of the tests I tried were running a Windows 7 machine connected to a cRIO 9067 that was on my desk - so network traffic/infrastructure were not a factor.
First, there is a major difference in performance (execution time) between an invalid variable on a valid PSP engine (target exists, variable does not) vs a variable on an invalid PSP engine (target does not exist so all variables also do not exist) - meaning that if the target does not exist at all then ALL of the connect methods will take significantly longer than usual (for example, "Open Variable Connection in Background" still takes 5000 ms if the PSP var engine is not found, compared with <50 ms if the target is found but the variable does not exist).
Here are the cases I tested:
"Read Variable.vi" - the default way I had tested initially. If target does not exist, times out after ~5000 ms with error -1950679035 - subsequent calls timeout at ~0 ms for a few seconds and then var attempts to reconnect automatically and takes ~5000 ms per call - does this about 5x per variable. If the target exists but variable is not deployed then the read call errors immediately, unfortunately with same error code/message (-1950679035).
Here's the graph of timing for this case:
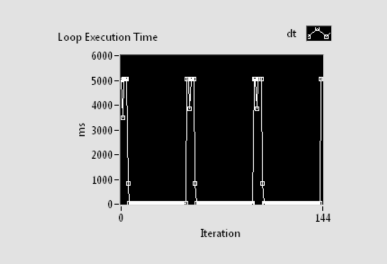
"Read Variable with Timeout.vi" - Has exactly the same behavior as "Read Variable.vi" in terms of this test (same errors, same timing).
"Open Connection in Background" - The first time I tried this I thought - great I'll just call this once and then wait for the connection to get to a connected state. Seems like the best option but unfortunately, if the initial call throws the error -1950679035 then the var connect does not continue in background so you will never get a connected status. In this case the error description is more helpful - the error description is "LabVIEW: (Hex 0x8BBB0005) Unable to locate the shared variable in the Shared Variable Engine (SVE). Deployment of this shared variable may have failed, the SVE has not started, or the SVE is too busy to respond to this request.". So if you get this error, you need to retry the open connection in background, and you end up with the exact same timing profile as the "Read Variable.vi".
So basically it seems to me that my PSP application needs to either - always have the variables available - especially at connect time OR be able to cull out bad targets and not try to connect while the target is down OR be performance insensitive so that it doesn't really matter if the target you're connected goes down or not.
I've attached the VI I used for timing tests. Basically I would swap between invalid targets and invalid variable names to do the tests.
-
Generally I'd be sure to open all connections first and never use a read directly on an unconnected string. To me what you described is expected and desired behavior -- if the implicit connect failed it should retry, and your code should have sufficient error handling to deal with that situation.
Fair enough - in our case all variables 'should' always exist and this issue was the result of some bad configuration data that got merged from a dev branch. I think it makes sense that the variable should try to open a connection, I was *surprised* that this meant every other parallel shared variable operation was blocked waiting for the open to timeout.
-
Great point - I'm not sure whether 'read var with timeout' would help or not - in principle it should be better but I'm not sure if the timeout is respected if the variable does not exist (as in you pass in an invalid PSP variable that is not known to the scan engine). I'll test it once I have time to do that.
-
Recently experienced a performance bug that I traced to a bug in my code related to shared variables that I just want to share to hopefully help others avoid this error. (This was running in LV2014 SP1 on Windows)
I am using a dynamic shared variable "Read Variable Function.vi" but not opening the connection prior to reading the data. I accidentally had passed in an invalid PSP variable path to the "shared variable refnum in" input. This VI happened to be in a loop that was updating fairly frequently (every 50 ms). Well ... it turns out that because I wasn't opening the connection first and passing in an actual refnum, every time it hit this node, it retried opening a connection to a variable that didn't exist which eventually timed out - this was a very shared variable/(scan engine?) intense operation and effectively brought all of my other shared variable operations to a halt - performance went from awesome to a total drag and my application was almost unusable.
Short term fix - I changed my configuration to point to an existing and valid PSP variable and all of my performance went back to normal. Hope this helps someone else avoid my "mistake" although I'd also call this a LV bug in a sense that it shouldn't drag an application's performance down in such a severe way if a variable goes from existing to non-existent.
-
1
-
-
I saw Stephen Barrett present on the topic at the CLA Summit based on the document you linked to. Buried in that doc he created a GIT repo with the source code to his demo:
https://github.com/BarrettStephen/FPGA-Middleware-Demo
This was a very awesome approach to FPGA reuse and I have been aiming to replicate this on my projects but have not had the time to fully invest in reorganizing my existing code, however if I were to start a new project I would definitely consider this approach.
-
I'm able to programmatically connect to shared variables without issues on my cRIO. Here's what I have installed on my cRIO (note, I redacted the items I'm sure have no affect).
-
I totally agree!
-
Are you compiling locally or using Cloud Compile? I've had an issue where Cloud Compile threw an error and only (easiest?) way to fix was to compile locally - everything worked - after that point compiling in cloud was fine again.
-
Its not a trivial task. NI doesn't currently support using RT to create EtherCAT slaves. NI likely has the knowledge of how to do this if it possible (ex: 9144 is an EtherCAT slave) but there is no public info on how to create a custom EtherCAT slave. You probably need to contact NI to get help and you probably also need to start looking hard at the EtherCAT slave requirements - http://www.beckhoff.com/english.asp?ethercat/et9000_et9200_et9300.htm - which I think you'll find will also require joining the EtherCAT working group, etc.
Using Git for Configuration Data revision control
in Source Code Control
Posted
I agree about keeping the sim related config separate - I have taken this approach and found it useful but it can also be tricky to ensure that configuration data that is added during development to the simulation files is merged into the deployment folder. I've personally found BeyondCompare to help solve this problem but it is a manual step that has been hard to enforce with process. The article you suggests looks really promising - I think it was exactly what I was looking for but failed to find by my own searching. I think this is going to help me avoid going down a fairly messy rabbit hole!
We're definitely not running source directly in our final deployment. We run from built exe's and leave no source code on the deployment machines. But the other points are definitely valid. I agree this is a suboptimal way to manage the configuration data. Ultimately what I think I want is for the auto-merging of the text to fail so that the developers can make intelligent decisions about what to merge - basically the way that binary files are treated (probably the only time I will ever think this way) - I think the article @smithd linked to will do that for me.
Very appreciative of the help and advice!