

Omar Mussa
-
Posts
291 -
Joined
-
Last visited
-
Days Won
10
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Omar Mussa
-
-
In case you missed the Aussies getting a clinic over the weekend (I'm talking to you Crelf!), here is the recap:
http://www.youtube.com/watch?v=yRu0ePLlqgY&feature=player_embedded"'>http://www.legofussb...mbedded
-
 1
1
-
-
I have seen LabVIEW slowdown, 2009 SP1 does not seem to fix any of the bottlenecks for me. I have seen the >3 sec edit times as well.
Here are some things that I think contribute to slow development edits (note: these have major impacts on my ability to develop code quickly using LabVIEW -- also note, I typically have the lvproj file open and I know opening the code without lvproj file open helps this somewhat but it disrupts other parts of my development flow a lot as well)
1) Dynamic dispatched methods -- when I first started using classes in LV 8.2 I thought the ideal default behavior for classes would be to enable dyn. dispatching. I've since changed my mind and now try to minimize dyn. dispatching due to edit time performance hits.
2) Tab controls -- I've noticed that if I have a tab control with 'a lot' (not quantified) of controls and indicators, that LabVIEW edits get really slow. I think having a lot of controls/indicators in general may be an issue, but I have seen real issues when editing tab controls (this has happened on multiple projects in LV 8.5, 8.6 and 2009 for me).
3) Large number of VIs in project. I'd say that once you are over 2000 VIs you probably experience some pain and over 3000 VIs definitely puts my development virtual machine into slow motion (strangely, it really affects some VIs more than others and I'm not sure what causes that except for possibly items 1 & 2 above). Also, despite the really awesome potential power of having multiple project files open, I find that I generally can only have 1 project open or I get major edit time performance impacts due to context synchronization -- especially when the projects point to the same code (for example reuse libraries).
4) One of the things that has actually crashed LabVIEW for me and is really annoying is editing/applying type definition changes. I think LabVIEW has a workflow issue in that every edit to a type-def causes LabVIEW to try to figure out what VIs are now in an unsaved state even before you've hit 'apply typedef changes' or saved the type-def. This makes edits on typedefs pretty painful and can make applying type defs a finger crossing experience for me. I've noticed that there are a few cases that seem to be really problematic -- 1: editing a typedef that is used by a class but is not a member of the lvclass (happens when I create a new type-def from a control that is used by a lvclass method) 2: trying to add a type-def to a lvclass when the lvclass already uses the typedef. Somehow, these operations do not seem very stable in LV2009 SP1 for me (or in previous versions).
I haven't filed any of these as bug reports with NI due to lack of time, lack of reproducibility and lack of my ability to create a 3000 VI project that I can share with NI.
-
That is a lot of work!!
Maybe the developer used 'Add Case For Every Value' - which would still be a lot of work, but not as much as manually adding them

-
No answers, just that I feel your pain. I too had code with a memory leak and talked my boss into letting me buy Desktop Execution Trace Toolkit.
Ya, I don't have to worry about the try/buy decision. I tried doing more analysis and basically it looks like the app should have lost 2k of memory (which is counter to TaskManager which reported > 4k increase). I've attached my analysis. Either I need to change my trace parameters or the toolkit is not a great approach to fixing this issue -- have not figured out which is the case yet.
-
Has anyone tried using the Desktop Execution Trace Toolkit for debugging memory leaks? I tried to do it and I think it points me in a direction I can look into, but I'm having a really tough time getting useful information from the trace. Also, the export of data is in a format that is not very Excel friendly which also makes analyzing the data hard. If anyone uses this tool a lot and has suggestions, I'd appreciate it!
In my current trace, I'm only looking for memory events and looking for data >=400 bytes. I get events that show up, but I cant tell if they are a leak.
I've attached my 'trace' export but I haven't done any work on my own to try to parse it -- if anyone has already got tools for analyzing this data, great otherwise I'm not looking for someone to create one. I just attached it to show how non-trivial this process is.
-
I was wondering if anyone does issue tracing/Bug Tracking using Microsoft Access?
If you want to do issue tracking, use real issue tracking software. I highly recommend FogBugz (we use it at JKI), although it is a paid product. I've also used Bugzilla, it is free, it was not as easy as FogBugz (for me) but it still worked ok.
-
Real reform stands a much better chance of happening when the feds keep their evil little paws off of something.
I don't understand what you mean -- do you think the insurance industry or health care industry can reform itself?
-
This is interesting. However, it would really help if you documented your Example better. Especially the fact that you need to right-click on the 'Get' node to select the named attribute that you want to get the data from, and to double-click the 'Set' node to add new 'named' attributes.
Also, it would be nice if by default the 'attribute name' property defaulted to the name label of the object wired to it. I would like to not have to set the attribute name at all most of the time. For the 'Get' operation, if only one data-type is 'registered' with the xnode it would be nice if the GetData automatically used that data type. Also, it would be great if your zipped folder structure was better -- I would only put the xnode in the root level (+ a readme.txt with documentation) and would try to move everything else into subfolders because the folder looks really messy right now which makes it harder to figure out what I should 'care' about as a user.
-
Congratulations! Good luck! Welcome to the sleep deprived LabVIEW warrior dad club!
-
The project window should have a bright yellow triangle next to the missing file name. Sorry about that. If you can reproduce it, please CAR it.
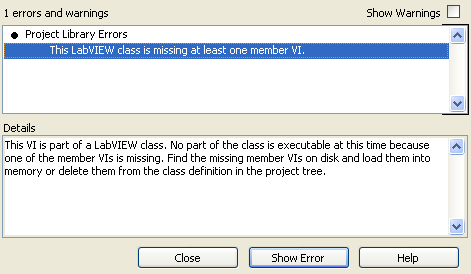
The project item did have a bright yellow triangle. But unfortunately, that triangle is not visible if the VI is inside of a virtual folder until you manually expand the folder. My class had several virtual layers so it took a few minutes for me to find the culprit VIs. I think it would have been easier for me to find the VI if I had known the name/expected path.
I can easily reproduce this, just create a class, put the VI in a virtual folder, and delete a VI on disk but not from the class and then load the class.
Edit: I can't easily reproduce the crash.
-
If you open a class that can't find a member of the class, you get this message in the error dialog:
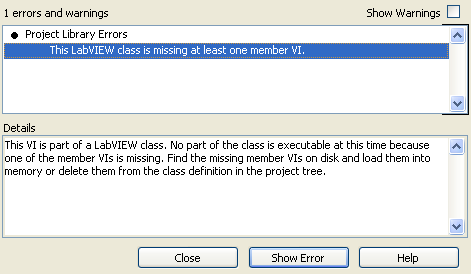
Note that it doesn't tell you what file(s) are missing. This makes it a real pain to figure out what is 'wrong'. Note: the reason I got this dialog is because LabVIEW crashed while I was editing my class so some changes to the class library (including members that were renamed) were lost.
-
I use the suspend when called feature a lot. Its a really great feature for debugging. However in LabVIEW 2009, the feature no longer works the same way.
In LabVIEW <=8.6, you could update the inputs to a suspended VI and rerun your code and it would use those inputs to determine code execution.
In LabVIEW 2009, if you change the inputs of the suspended VI, the VI still runs with whatever the caller VI passed into the VI.
Here's a video to demonstrate this issue.
http://content.scree...f8/00000135.swf
-
1
-
-
It looks like the preferred breakdown is to use Test Suites to set an object's initial conditions and have a unique Test Case for each sub vi? Previously I had thought of Test Suites as simply a way to enable 'single click' execution of a subset of Test Cases.
I generally use the TestSuite.SetUp method to setup the 'environment' of my test -- for example, if I'm testing a class that depends on some other class, I'll create the dependent class in the TestSuite.SetUp. Single click execution (i.e. test grouping) is only one of the benefits of the TestSuite, the real power lies in its ability to help create very flexible test harnesses. Also, TestSuites can contain other TestSuites (not just TestCases), so you can really do a lot of stuff to keep your test environment modular.
In the VI Tester Example project (VI Tester Help -> Open Example Project...) the Queue TestCase has a diagram disable structure in the setUp so we can see what the response would be if the queue were not created. Suppose I wanted to test both conditions: valid queue and invalid queue. What would be the best way to set that up in the context of the Example Project?
I think the way that I would do this would be to create a method that sets the queue ref and modify the TestCase as described in my first post for setting the error propagation testing. Ultimately, you'd have a 'Valid' and 'Invalid' TestSuite...
Another thing I have done in the past is enclose the vi under test in a for loop and create an array of different inputs I want to test. I'm pretty sure this violates the idea of 'each unit test should test one thing,' but it is easier than creating a unique test VI for each string input I want to test. I'm wondering how well that technique would carry over in this paradigm. Maybe it would be completely unnecessary...?
Running unit tests in a for loop means you have a bad test design (for VI Tester). Creating a bunch of TestCases in a for loop and adding them to a TestSuite however, is perfectly OK. I would prefer to do the latter method, unfortunately I found a bug in VI Tester's UI that currently makes this really difficult (unless you just want to run your tests through the programmatic API). I have no ETA on when the bug will get fixed, but its definitely a high priority for VI Tester.
-
Thanks for the real world example, I was hoping you would provide one from JKI's products.
No problem, I'm hoping to write some blog articles in the future related to unit testing with VI Tester but I've been really busy.
I think its time for me to make those decisions on the project I'm working on.
Well, technically, its always the right time create unit tests

Here are some more criteria that we generally use at JKI:
1) Always test code that is critical for security of apps -- security may just mean that it functions correctly, or in JKI's case, we have tests to validate that we have security for our VIs (like password protection, etc. --> yes, you can create unit tests to validate properties of VIs, see this blog article).
2) Always create unit tests for bugs identified by end users -- usually, if an end user finds a bug, it means its a bug in a shipped product (even if the customer is internal) and you don't want the bug to come back, so create a unit test for the issue.
3) Try to create unit tests for public APIs. If you have a public API (for example, if you are using LVOOP, your public API is the set of Public scoped methods, for JKI's Easy XML toolkit, your public API is the four VIs our users call), create unit tests that exercise your API. I don't find it critical to test every possible input to each VI in your API. However, after some time you come to realize that there are certain things you want to test -- like what happens if you input a 'NaN' into a numeric input of some VI -- those things should definitely be tested. We try to create a unit test for each public method, that way its easy to create additional tests (by duplication) as other issues arise. In some cases, we have been able to create tests before the code we needed to write was complete -- unit testing your API is a great way to artificially create a customer for an API, and this tends to result in a better API. You start to realize that if you can't unit test your code via your public API, you probably have an issue with your API that you need to correct.
I hope this helps!
-
One thing going for this method is that it is simple, and from my reading on unit testing, simple is good. I think I'm reading that unit tests should test one thing, and one thing only. If you need to test 5 different ways your subroutine could fail, you should write 5 different unit tests.
I guess I'm just wondering if I'm missing a shortcut, or if the long road (writing more unit test subVIs) is the better (or only) road to take in this case.
Ya, one problem with writing unit tests is that you basically write a lot of tests. I'm pretty sure that whether you use VI Tester or NI's UTF - if you want to test that 30 VI's have error propagation, you'll need to write 30 tests.
It comes down to how many test paths you want to test to ensure the quality level you need. As an example, JKI's EasyXML product consists of just 4 public API VIs. We have > 60 unit tests for these VIs. One great thing about writing unit tests as it relates to TDD is that you can write unit tests for bugs the have been identified before the fix is in place. We do this for every bug reported to JKISoft forums for our products. Some unit tests currently fail because we haven't implemented a solution for those issues yet. But the great thing about a unit test is that once it passes, you know from that point forward that if the test fails, something is probably wrong with your code. This means that your unit tests add value and stability to your code over time.
Ultimately, you have to decide what things add value by testing them, and test the hell out of those things. Although, with scripting, it may be possible for us to create more unit tests quickly and not have to make the value decision as often.
-
I think you are saying I would write a specific VI to test error prorogation for each of the VI's I want to test, which was what Chris suggested, and similar to what I've pictured below. I'm guessing that I might be able to create VI's like this for every subVI I want to test, via scripting, if I put my mind to it.
This is one way to do the error propagation test. It works, there is absolutely nothing wrong with doing it this way.
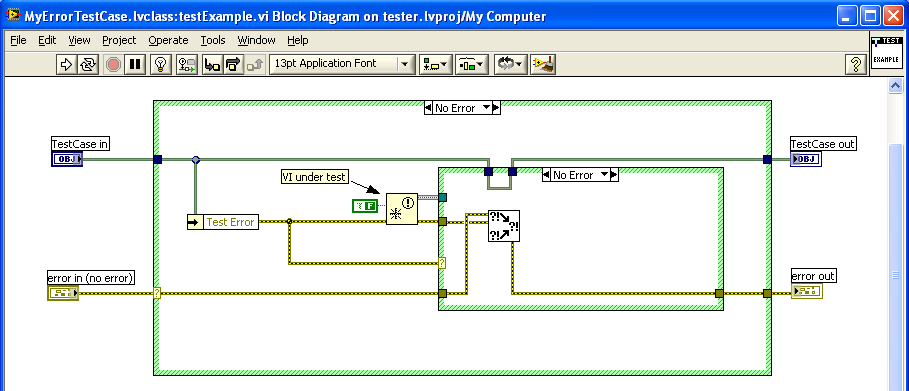
Then if I use your method of carrying the error in the object, I can use a method to change that error in the setup VI, or in individual unit test VIs. If I want to check how a VI reacts to a specific error, then I can use that "Set Test Error" method to provide the specific error to the VI under test. This would allow me to test how a VI reacts to a specific error, or specific set of errors by running the unit test with those errors set.
Actually, the benefits of using my method are this:
1) You can use Set Test Error to test specific errors (as you point out)
2) You can add unit tests for your other VIs under test easily and you will be able to test their ability to test the exact same error conditions based on the TestCase (rather than hard-coding the error-in for N-tests).
I've also attached a picture of a unit test that I'm working with now, just to make sure I'm on the right track.
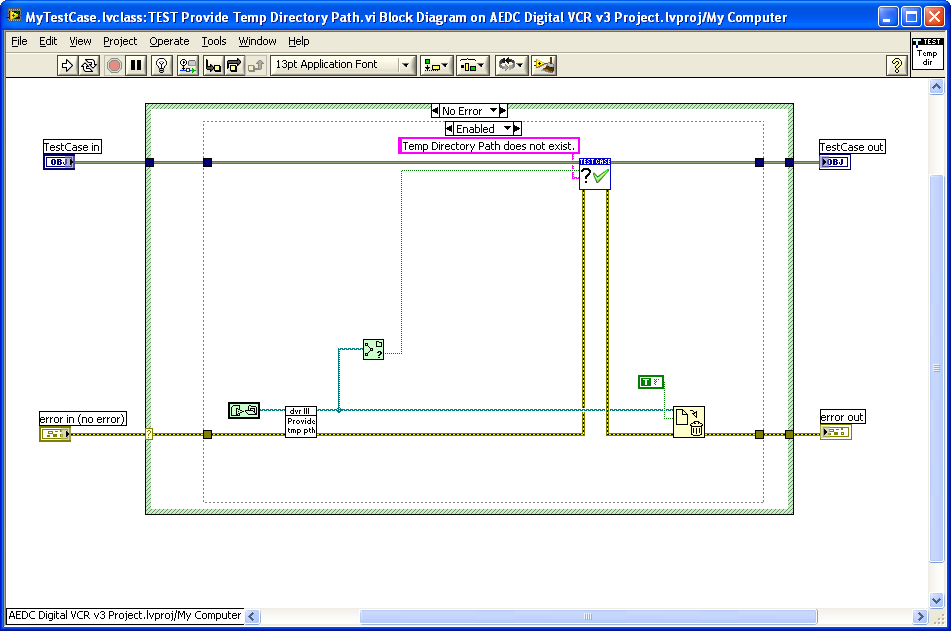
This test looks fine to me
It looks like you are on the right track. You are right that scripting can help automate these tasks, however I don't have any scripting code for generating tests to share. I don't think I understand where you're having difficulty understanding the previous post, so if you have any new questions, that would help. -
If I want to test that my VI "under test" passes an error through on its error In connector; should I do that as a separate unit test?
What you're really asking is 'how do I do error propagation testing using VI Tester? One way would be to just create unit tests that hard code an error into your VI under test. However, that is actually a difficult way to scale as you add various error conditions, etc.
Another way would be to create a TestCase with a property called 'TestError'. See my screenshots below.
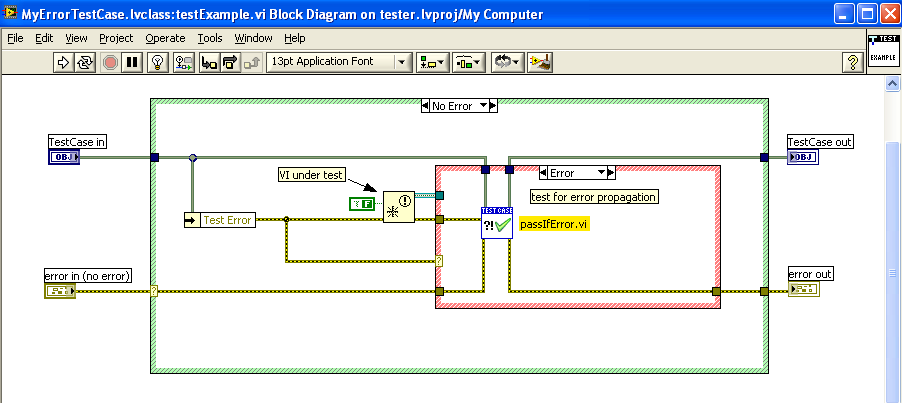
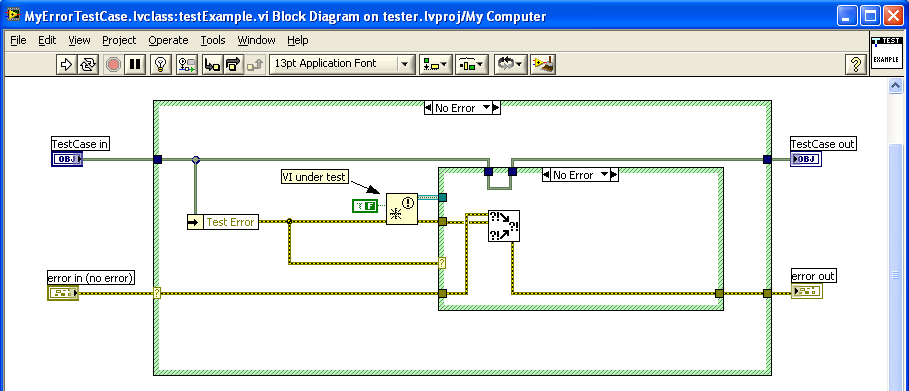
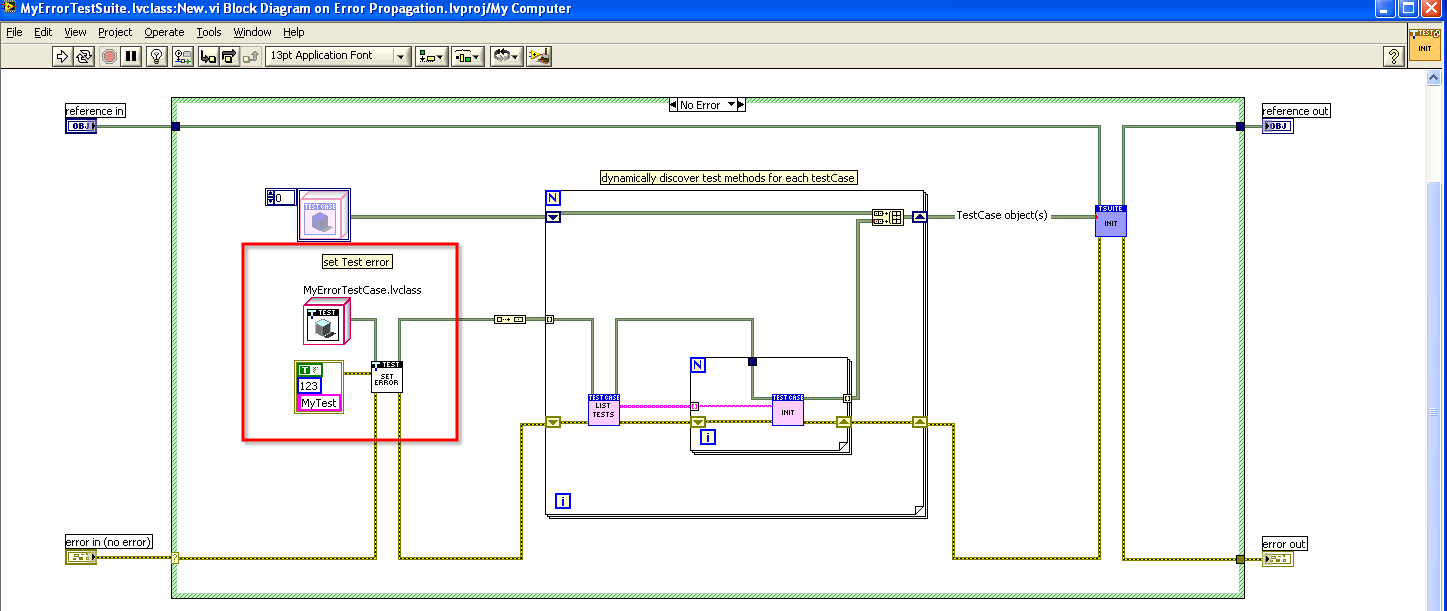
Now, your only issue is "how do I set the TestError" property. One way would be to set the TestError property using the TestCase.SetUp method. The problem with this method is that it becomes essentially a code change to your TestCase if you want to test different error conditions. Another way would be to create a method called 'SetTestError' and then to add your TestCase to a TestSuite (pictured below).
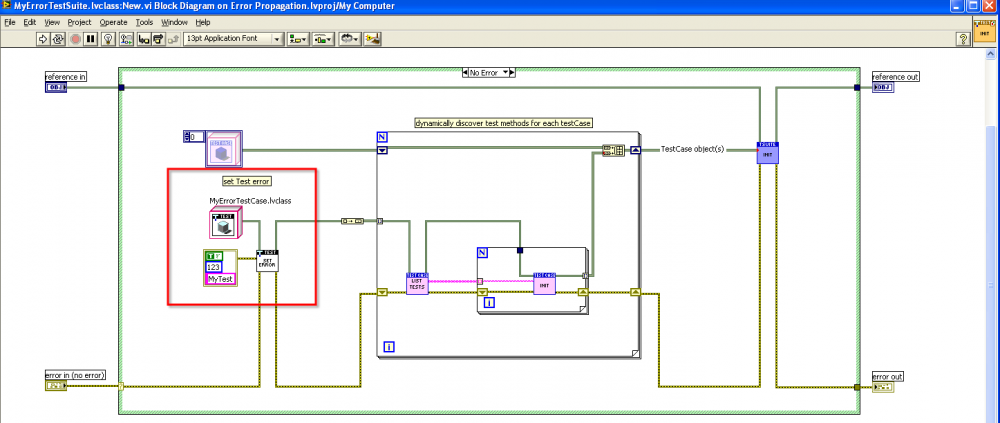
Now, you have a lot of power because you can easily create multiple tests in your TestCase that will get tested with the same error conditions you've set up in your TestSuite - and you can validate that all of your VIs propagate the error as expected.
The only problem I found with this method is that there is currently a bug in VI Tester GUI that prevents having multiple TestCases of the same type within the same TestSuite. So, this means you will probably need to create another TestSuite for the NoError (or other ErrorConditions) case(s). I've created a sample project and attached it here (in LV 2009 - although there are no LV 2009 specific VIs used).
-
Yes, but can you create VIPCs that link to packages at an arbitrary network location or when using that feature do they have to link to a 'real' package repository, which implies a repository client license is needed.
If you link to the package in the VIPC instead of embedding it, the package needs to be on a VI Package Repository and you must have a VIPM Client license to access that repository (unless the package is distributed through the VI Package Network like the OpenG/JKI packages are -- we plan on eventually opening up the VI Package Network to others but we're still working on several issues that prevent this from happening at this time).
-
Granted I suspect it's all easier to manage from VIPM.
In VIPM Enterprise (3.0) to deprecate a package in your repository, you just right click on the package and select 'Deprecate'. All clients connected to the repository will no longer actively convey any information about that package (however, if a VIPC file uses the package, it will still be able to download it from the repository --> deprecated is not the same as deleted).
Questions about snapshots: How are snapshots represented and stored in VIPM? Are they treated the same as other packages? You need VIPM Pro to create snapshots, is VIPM needed to use snapshots? Do you save the snapshot with your package source code in scc?
Snapshots in VIPM are called VI Package Configuration (VIPC) files. You create them by either dragging packages into the editor, or using the editor to have it scan your project and automatically detect what packages your project depends on (Requires VIPM Pro). Once you have created a VIPC file, you have created a snapshot of the packages and versions that your project depends on (and it is saved for a specific LabVIEW version based on the project you are working on). Any VIPM activation level (including Community) can apply VIPC file (double-click VIPC from within Windows or go to File-->Apply Package Configuration) --> at that point VIPM will install/upgrade/downgrade your packages to get that LabVIEW version into the specified configuration. Using VIPC files (snapshots) makes it very convenient to switch between LabVIEW projects without having to worry about what versions of reuse libraries you were using when you were last working on a given project. We are working on improving the VIPC documentation to make it easier for users to realize the full value of the VIPC files.
Since we just released VIPM 3.0 - I'll just do one shameless plug that you can find out more at jkisoft.com/vipm
-
Maybe a little off topic. Does anybody just use TestStand for there unit testing? If so, do you have any recommendation or caveats.
Ben Hysell has written some awesome articles related to unit testing and LabVIEW. One of the articles talks about using TestStand for unit testing:
http://www.viewpointusa.com/newsletter/2009_january/newsletter_2009_jan2.php
He also wrote some great articles about using JKI VI Tester in the same article series here:
http://www.viewpointusa.com/newsletter/2009_february/newsletter_2009_febtdd.php
http://www.viewpointusa.com/newsletter/2009%20March/newsletter_2009_Mar.php
I highly recommend these articles!
-
Ya, the Dinovo Mini looks really nice and compact. If only it had xbox360 support it would be perfect but not a big deal. I think that's the way to go. Cnet video review here: http://reviews.cnet....7-32784878.html
I have the Dinovo Edge for Mac -- it is really awesome for my Mac mini which I'm using as my MMC for my home. I'm really impressed by the keyboard and it is really nice to have a trackpad built in rather than to have a mouse. Honestly, for a MMC, the biggest problem I have with a separate mouse is that you never have a usable surface when you need one -- so you end up with another accessory - a freakn mouse pad -- so I'm really happy with the Edge's built in trackpad.
-
I guess many of you have encountered this issue with the tab control.
Is this a bug or something everybody knows about and always just manage to live with it.
The problem is that the Tab Control don’t always changes Tab when you programmatically changes is using a local variable, if you at the same time updates a control or indicator using the property node which is located on any of the tabs.
Why??
(LV 8.6)
//Mikael
I think this is a bug that maybe nobody's been reporting? I've seen it for a while so I'm in that group (and it still exists in LV2009 as far as I have seen). My workaround -- you can use the Value.Signaling property and it seems to always update correctly. Just be sure that the Tab Value Changed event is not going to impact you negatively if you use this property.
-
There are known problems with multiple non-vi/ctl files with the same name in LabVIEW libraries and classes that can result in unexpected cross-linkages between lvlibs or worse, corrupt files. See this thread on NI's forums for details.
Essentially it appears that the loader uses the standard LabVIEW linker rules about how to find a file when loading the members of a library. Whilst this is perfectly sensible for LabVIEW VIs, custom controls etc which should have a unique name, it is less than helpful when the library files contain other types of file that may legitimately have the same name - such as dir.mnu files. This isn't a problem in project files as in that case the members aren't all loaded into memory when the project is.
The solution is to move the dir.mnu files out of the lvlibs, or to rename/recreate them with unique names. Your current solution will go very badly wrong if you ever have multiple dir.mnu files in the same lvlib !
Thanks, I will try your suggestion.
FWIW - I don't have multiple dir.mnu files in the same lvlib, these are in different lvlibs as shown here
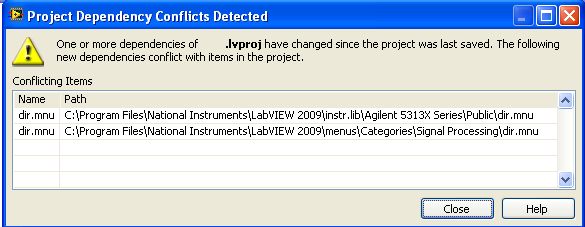
-
One thing that I thought lvlibs was supposed to do was to help prevent conflicts within LabVIEW. I'm not sure if this was a problem in LV 8.6 but I'm using LV2009 now and getting a strange problem.
In my project file, I have two different lvlibs that have a 'dir.mnu' file. These lvlibs are from 1) an Agilent driver, 2) Some NI lvlib (NI_AALPro.lvlib).
Anybody else seen issues like this? What's the solution (my current solution is to ignore the warnings)?
Thanks in advance!


Save and restore clusters. Restore won't know which values are being restored.
in Application Design & Architecture
Posted
Shameless plug - you could also just use the JKI EasyXML toolkit for this.