

Aristos Queue
-
Posts
3,183 -
Joined
-
Last visited
-
Days Won
204
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Aristos Queue
-
-
@Mads Inelastic... I like the economic implications. "High maintenance" is right vector, but still implies a particular threshold... and "higher maintenance" sounds weird.
@shoneill I've used "viscous" in the past to describe practices "that resist [data]flow". I'm tempted by it.
"Inelegant" has a good balance of subjective/objective judgement.
"Brittle" does seem like the idea many people keep coming back to. I like its factual aspect (sure, you can use it, you can make it work, but it is still brittle) and the fact that it is not a negation of some other term, which keeps us out of the "which way do you mean for that negation to work?" problem (which is the heart of "unmaintainable").
-
23 minutes ago, ShaunR said:
You have answered your own question then
Your VI is an example of unscalable but it may well be maintainable for small or even medium sized projects. You just need to quantify the "size" where it becomes a significant factor.
I'm afraid that "unscalable" runs into the same problem, doesn't it? "Well, I'm at scale X and I keep ours working fine." :-(
I think I need a term that means "harder than it needs to be." That's kind of why I like "paintainable." It implies, "Yes, you can do it this way. It works. You may not even realize how much energy you're exerting keeping it working compared to what you could be spending."
In terms of real words, I'm leaning toward "inefficient". Usually that word is reserved for actual run-time performance of the code, and I hate to muddy it, but it is the term that describes the developer's effort as well.
-
6 hours ago, ShaunR said:
If you are saying that there will be no difference between SP1 versions and release proper, then you should just drop the pretence that SP1 is a "service pack" and rename it to a "feature pack".
I kind of expect NI marketing to do that in a few years. Maybe it won't ever happen for the current LabVIEW platform, but LabVIEW NXG is being designed for this brave new software world. It's not my call to make, and it is really hard to push back against the idea when the whole software industry, including our own vendors and many downstream dependents, are moving in that direction. Like ShaunR, I have reservations about the whole idea, but I am observing it as a successful pattern in many other companies, both vendors and users, so I'm keeping an open (if doubtful) mind.
-
ShaunR: I agree. But within context, the term "unmaintainable" is used (by many presenters and book authors and professors) to describe any pattern of action that contributes to the overall unmaintainability of the system as a whole because that pattern is known to break down at scale. The problem is with the term itself -- it implies an impossibility that is clearly rejectable with a single counterexample. Therefore, I'm looking for a different term of art.
-
5 minutes ago, jcarmody said:
Paintainable?
SO TEMPTING. Last I checked, I was a member in good standing with the Illuminati Unseen Templar Knights Of The Oxford English Dictionary, licensed to coin new English terms.
-
I'm writing a shipping example for next LV. I have a series of VIs: one shows an incorrect solution, one shows an inefficient solution, one shows an unmaintainable solution, and one shows a good solution.
I'm naming the VIs accordingly. The problem is with "unmaintainable." At several NIWeek presentations, I have described some X as "unmaintainable" and gotten arguments from audience that, "Hey, that's my architecture and I maintain it just fine." And they're right -- it is their architecture, and they are successful with it. When I (or most of the "Room G" presenters) use the term "unmaintainable" we mean "when part A of the code changes, the process to update part B is error prone, either because it is hard work or it is easy work that is easily forgotten."
Is there a better shorthand term that I should/could be using other than "unmaintainable"? In many cases, I can explain what I mean by the term, but in slide titles or -- as today -- in VI names, it would help a lot to have a singular term, without triggering the kickback reaction. Something like "Uneasilymaintainable"? :-)
-
6 hours ago, ShaunR said:
I see you have you marketing hat on

It's a factual statement: the trend of the last several years is the main release having fewer new bugs and the SP1 release having more new features. I expect these trends to continue, with the probability of a new bug arising eventually being equal between the two releases. NI is being pushed by industry to shorten the overall release cycle considerably. Most software is moving in that direction. Even systems as complex as MS Windows have moved to continuous delivery.
I am not arguing that you should do any particular thing. I am saying that your stated argument for waiting for the SP1 is becoming less and less valid each year. You might have other reasons for waiting, but the bug level isn't as solid a delimiter as it used to be. I am personally somewhat uncomfortable with software having a permanent "level of instability", but that does appear to be the trend across the industry.
-
On 10/14/2017 at 0:07 PM, ShaunR said:
I expect you will find that most people that you say buy the new version are on a SSP so they get it anyway even if they are using an older version.
CEIP data shows for a wide swath, it isn't just "buy"... it's also "use."
-
7 hours ago, Antoine Chalons said:
people do that??

Frequently, and with increasing frequency. There really is little difference between a full release and an SP1 release at this point -- the cadence is about 6 months apart, and each has bug fixes you might need/want. With the binary-backward-compatibility of 2017 and later, more barriers to upgrading disappear. It is more likely that the main release will have new features, but the various drivers/modules might add support in the SP1, which, from customer perspective, is new features. So, while I understand the hesitancy to upgrade until the SP1, the reasons for that hesitancy have decreased dramatically over the last five years, dropping to zero hesitancy for some segments of the LV user base.
-
51 minutes ago, ShaunR said:
Because the release time-frame for bug fixes and LabVIEW itself doesn't help with the project at hand and it may quite possibly be rolled up into a new LabVIEW release requiring a new purchase. So people ask some questions on the forums, find a work around and move on. We are working on weekly timescales and NI is 6 monthly. We need to resolve bugs within days, not months. A bug fix in 6 months time might as well be never, especially if we have to buy a new LabVIEW version to get it.
I'd buy that argument except that
a) a lot of you do buy the next version
b) I take the time to report bugs against Visual Studio and MS Windows and lots of other software so that eventually those issues get out of my way
If nothing else, filing a sufficiently outraged bug report, complete with a rub-your-face-in-it reproduction case (so the bastards at Microsoft can't claim I'm making it up) is really cathartic. Substitute "NI" for "Microsoft"... I bet it can help your morale. :-)
-
On 10/12/2017 at 2:53 PM, infinitenothing said:
Is there a way to check if we're in the customer experience feedback program?
Details of the CEIP program are here: https://www.ni.com/pdf/legal/us/CEIP.pdf
The answer to your question is here: “…navigate from the Windows Start Menu to All Programs » National Instruments » Customer Experience Improvement Program.”
You should also be prompted the first time you run a fresh install of LabVIEW (assuming you don't copy in an existing config file).
-
planet581g: Have you contacted NI tech support? That's exactly the kind of thing that we'd like to hear about. I'm not sure why so few people escalate those sorts of issues to us, but I've noticed over the years that if users can restart and keep working, they never report the issue. Please, for your own sanity, take a moment to report those things. It's the only way we'll know about them and possibly fix them. I know it is a pain to pack up your code and get it into a service request, but posting about it on LAVA doesn't help! :-) (Ok, I admit... it does help sometimes when you happen to catch attention from someone at NI and it is something concrete to report, but a hang caused by "something" in a large hierarchy isn't one of those!)
Are you using malleable VIs? There's one infinite compile in 2017 that we found recently that I've fixed in the upcoming 2017 SP1 release, but that's the only one I know of like what you're describing.
-
1 minute ago, hooovahh said:
Wish I would have known that earlier, could have filed a couple hundred CARs by now.
Please start now. Only squeaky wheels get grease.
QuoteI also think variant to data could help invoke crashes too by converting things to things it shouldn't and then acting on those things.
Not Variant To Data... that has full checking on it for coercion legality. It isn't a raw Type Cast. I suppose you could get a backdoor Type Cast using the Unflatten From ____ nodes... on refnums. Casting refnums is the heart of the problem. I should have phrased it more broadly -- the two things you can do to crash LV that aren't R&D's fault are moving refnums onto wires that don't match their real types and calling outside of LabVIEW (to DLLs, Sys Exec, etc) in ways that inject back into LabVIEW.
6 minutes ago, hooovahh said:It's not a bug its a feature. One I'll admit I wouldn't use, but still.
If a user writes a piece of LabVIEW and gets behavior that contradicts intended design, including failing to get an error when they should, that's a bug. Some are small enough compared to the effort to fix such that we let them go without being fixed, but they're still a bug. And changing the one line of code from "FileName()" to "QualifiedName()" is a pretty low-hanging fix.
-
 2
2
-
-
On 10/5/2017 at 7:23 AM, hooovahh said:
I was asking for an explanation, full well knowing it might lead to me asking for other things. But I do agree that the result of an XNode stating "I'm inline safe" and then not being, might lead to a crash or other unexpected behavior. Still I sorta feel like that is the result of a poorly made XNode, and while NI could protect for it, there are plenty of places I can force LabVIEW to crash doing something stupid and NI can just respond with "Don't do that." because I'm at fault for not abiding by the documentation.
There should be exactly two of those things in released features: the Type Cast primitive and the Call Library node. And maybe System Exec.vi. But otherwise, no, we treat anything that can crash LabVIEW as something we messed up on.
On 10/5/2017 at 10:57 AM, DTaylor said:I think you can! It looks like the compiler exception doesn't check the fully qualified name. You can put your inline-safe XNodes inside libraries to namespace them, and name them all Error Ring.xnode.
Thank you for reporting that bug. Found and fixed in LV 2018.
-
23 hours ago, planet581g said:
Oh, and if 2017 seems to be eating up processor usage, but you have NO processes running and everything is just sitting there idle, try closing the breakpoint manager window if you have it open. That worked for me.
Surely that isn't unique to 2017... the breakpoint manager hasn't changed (to the best of my knowledge) at all in several versions.
Are you sure that is a new issue? (Not that I'm saying that the Breakpoint Manager *should* be eating CPU at all, but if it is the cause, I would expect it to go back at least to 2015 and probably to 2013.)
-
On 10/11/2017 at 9:57 AM, MarkCG said:
I've been experiencing a lot of crashes with 2017, way more than with 2014 which is what I was using before. Why or how they are caused I can't say.
This, by the way, is why NI does not generally advertise version X as being more stable than version Y. I can tell from bug reports coming in that 2017 is way more stable than 2015, especially when I filter for CARs filed specifically against new features, but all it takes is one bug that happens to be in a user's personal common code path for them to see it as massively unstable.
-
2 hours ago, crossrulz said:
AristosQueue swears that they are useful. He mentions it in almost every event I have seen him at.
As a matter of fact, I fixed a crash yesterday as a result of accumulated NIER reports. If we get enough stack crawls, sometimes we can triangulate these impossible-to-reproduce crashes. Sometimes even a single stack crawl is enough, as it lets us desk-check that code and imagine, "what if X happened? what if Y happened?" It's tedious, but, yes, it does help. If nothing else, it let's us flag a given code path and we can add more debugging logic along the route so that the *next* time someone crashes, it includes more information in the crash log. Eventually, we can trap these things.
@MarkCG Please do send in the NIER reports. And -- I know this is more controversial -- please enable the Customer Experience feedback. If you're in a high-security industry, I understand, but for everyone else, the usage data about what features you're using really does guide priorities, both for new features and for fixing CARs. It does help.
-
20 hours ago, mje said:
I see, yes that makes sense. I get how that's a problem in LabVIEW since there is no lower level representation presented beyond the block diagram. For example when I debug my optimized gcc code I can always peer at the resulting assembly to get an idea of what's going on when code seemingly jumps from line to line or look at registers when a variable seemingly vanishes and never makes it's way into RAM. Without a lower level presentation, you're pretty much hosed with respect to debugging if any optimizations are enabled.
I withdraw my objection, especially since there's some reference to optimizations in the dialog if I recall.
Seriously though, thanks for taking the time to set me straight. Cheers, AQ.
No problem. It helps me to know how customers see the world... sometimes we can restate things in more intuitive ways. :-)
-
7 hours ago, mje said:
Not "Enable debugging, and constant folding, and loop invariant analysis, and target specific optimizations, and a bunch of other stuff."
You have it backwards. In order to enable debugging, we have to turn OFF all that stuff. That's what allows debugging is doing away with all the optimizations of the code. The optimized code looks nothing like the block diagram and isn't amenable to exec highlighting, probing, etc. These aren't orthogonal things... enabling debugging MEANS turning off all the stuff that prevents debugging.
The documented reduction in memory and performance improvement? Turning off debugging allows all those things to kick in. The only error in the documentation to my eyes is the word "slightly".
-
23 hours ago, hooovahh said:
Other things I check I can see changing at run time like if the actor is in a subpanel I may behave differently, or if the VI has its window showing.
Right, but I'm asking for things that you could change at *compile* time. Anything that toggles at run-time is irrelevant to my question in this thread.
-
2 hours ago, hooovahh said:
Would you see implementing all properties of a VI in this conditional structure?
That's explicitly the question... "is there any use case for anything other than Enable Debugging?" My hope -- which this conversation is convincing me is true -- is that the answer is "no." There are people questioning whether "Enable Debugging" is itself a use case, but so far nothing beyond that.
2 hours ago, hooovahh said:honestly I would just read this as a property node on first call into the VI the keep it in a shift feedback node all other times the VI is called.
You're leaving to run time a compile time decision? And you're compiling in a first-call dependency on a requires-UI-thread property node?
Ewww. Gross! That's exactly the kind of code smell the Cond Dis struct is there to prevent!
Exactly what code would you be guarding with that property node check? That's the use case I'm asking about.
-
9 minutes ago, shoneill said:
AQ, what if I want (or need) my debugging code to run with optimisations enabled i.e. without the current "enable debugging"? Think of unbundle-modify-bundle and possible memory allocation issues on RT without compiler optimisations......
This would require a seperate switch for "enable debugging" and my own debug code, no?
I don't think I understand the question. "with i.e. without" is confusing me.
If you for some reason wanted to compile in your own code based on your own criteria, you would do exactly what you do today: define your own symbol. There would be no change to that. This is only for code changes that you want to enable/disable with the master debugging switch.
-
1 minute ago, hooovahh said:
I really am editing the VI. It is fixing whatever bug or issue I found with the reentrant VI, that couldn't easily be troubleshot with debugging turned off (or no probing ability like on reentrant RT VIs).
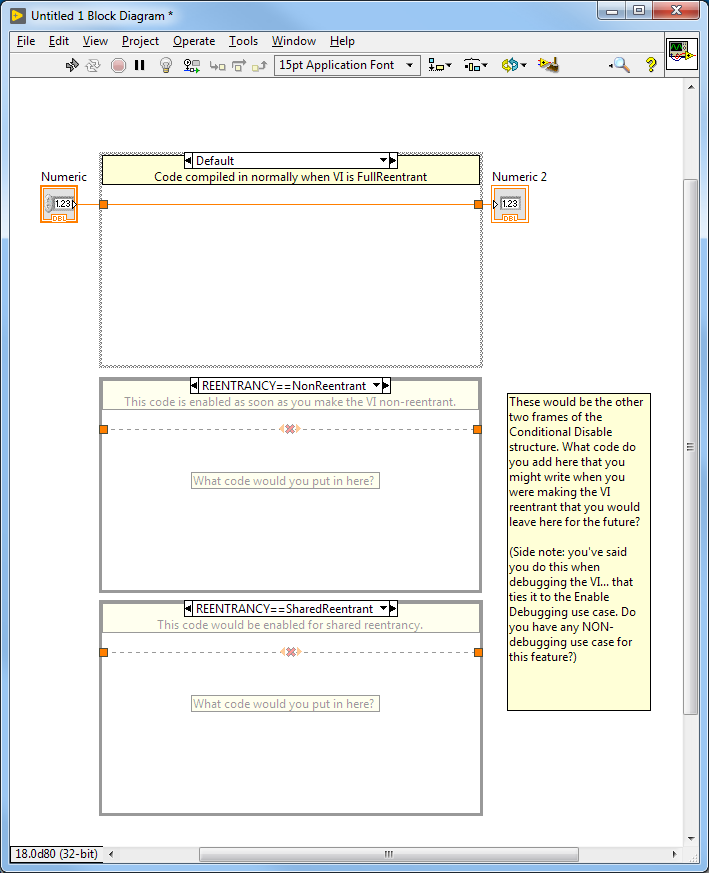
A bug fix is something you change to the VI AFTER you've debugged it. I'm talking about code that you would include in the shipping VI that says, "Whenver reentrancy is turned off, compile this code in". Something like...
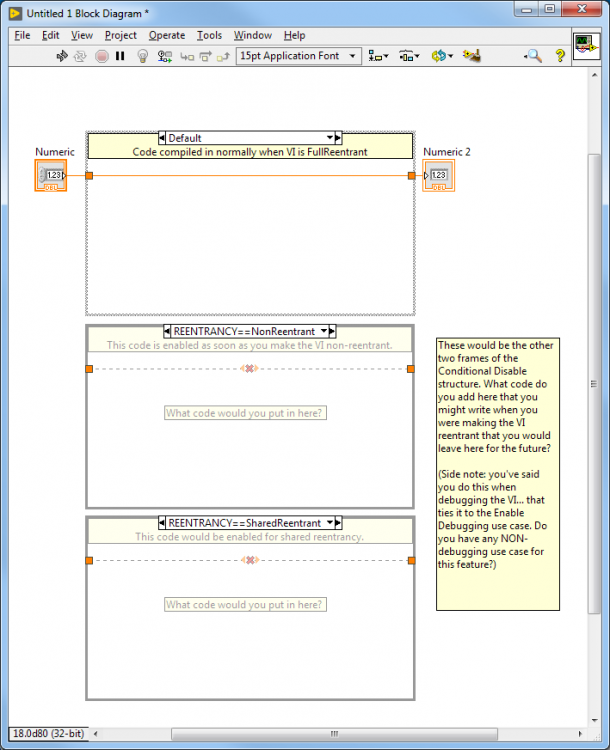
-
On 10/6/2017 at 7:22 PM, mje said:
I'd still argue the debugging flag is the wrong place to go about it, just because that flag has been hacked before doesn't mean it's the right thing to do again.
This comment is really bugging me.
To me, toggling debugging is the same as moving from Desktop to FPGA. The entire code base is compiled differently for the new target. I cannot see anything about the existing Enable Debugging option that is an existing hack. That checkbox is the toggle used to change between two entirely different execution environments. The fact that that target is a bit amorphous (it doesn't have dedicated hardware/any platform might become a debugging target) doesn't change the fact that it is an entirely different environment. Your objection hits my ears like saying, "Dragging a VI from Desktop to FPGA is too easy. Users should have a whole list of checkboxes to enable VHDL compilation on a function-by-function basis."
Can you expand your thoughts for me here?
Types Must Match
in LabVIEW General
Posted
You'll find more delights regarding that primitive and the structure if you join the LV 2018 beta program...
http://ni.com/beta
along with some other major advances in malleable VI technology.