

Aristos Queue
-
Posts
3,183 -
Joined
-
Last visited
-
Days Won
204
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Aristos Queue
-
-
Although I am fixing MANY icon issues with classes in the next revision, that's not one I'm touching ... adding the number is a long-standing LV feature to provide uniqueness of icons for lax users who don't generally edit their icons. If you want a workaround, go create 9 new VIs. The numbers only run 1 through 9. All VIs that you create thereafter will not have a number added in the corner. But otherwise just assume that the lower right is going to get hit. ... I think you might find this less of a pain in the next version. As I say, I'm adjusting several aspects of icons for LVClasses to try to eliminate the pain.
In all these years, I think this is the first time I've ever explicitly promised a feature to be in a future version. Must be getting weak.
-
 Can we please get a definative answer from NI on this one?
Can we please get a definative answer from NI on this one?It should help if you have multiple coercion dots on the same wire.
This answer is not definative... I know that the above is one situation where explicit coercion helps. There may be others. -
:thumbup: This one has been on my "wanted" list too for years!
Everyone that had to interface with a dll and manually enter all the datatype knows what a pain in the b...ehind it is :thumbdown: !
I am really looking forward to see your implementation.
Why NI did not do such an utility, I really wonder...

Didn't we just announce that at NI Week 2006???
http://www.ni.com/niweek/keynote_videos.htm
Take a look at Noel Adorno's presentation. She introduced the DLL Wrapper in the keynote. You can download it from ni.com somewhere... (I don't have that link).
-
Is there much of a difference between hiding the application by setting the FP.State property to Hidden and closing the front panel by setting the FP.Open property to False?
Yes. I strongly recommend never using the FP.Open property. It is "old style" and the FP.State was added to supplant it. Passing "false" to FP.Open is an ambiguous situation. If the window is already hidden and you pass false, did you intend for us to close the window entirely? This is just one of many ambiguous situations. The behavior in all these cases is well defined, but in all of these cases you have to figure out what decision LV R&D made. The old style still exists because of the huge number of toolkits that use it.
-
I would say that this is a usability issue. NI should handle this with a message or a description\note on the dialog explaining that you must run the VI or save it first. We're suppose to know this magically somehow?

If you're advanced enough to figure out what the Show Buffer Allocations tool does in the first place, then your name is probably CRelf or equivalent and appear to have no problem magically figuring stuff out.

-
This SubVI takes an assumed-to-be-positive I32 integer n as input
....
this SubVI does not perform any input validation or error checking.
Instead of "assumed to be positive I32", why not use an unsigned 32-bit? Then you don't have to worry about someone passing a negative.
-
I'm working on automaticaly creating a project from a folder hierarchy. I had to think a little bit on what data would i need to do the recursion or stack and then it was as easy as putting a "do what i want while array not empty loop". At each iteration i just use the delete array that automatically gives me the last element by default (wich is feature that i like a lot) and add elements to the stack. I believe that the majority of recursive problems can be solved by that method.
I do the same thing frequently, but I tend to use the Queue primtives... enqueue the first element, loop while the queue is not empty. On each iteration, dequeue one, then Enqueue the next level. If I need it to be depth-first (stack) then I use the "Enqueue at Other End" prim. I don't know which solution offers better performance.
-
Sorry to hijack the thread for a moment, but was this work related to LV Embedded, or some other project?
Boredom. To prove to myself that it could be done. And to give me a way to code LV programs while on plane flights without a laptop. Nothing that I've ever turned into functional code. Just a math proof of concept.
-
Jacedom:
Using function recursion in LV feels to me like someone using a hammer gun like an hammer and slamming the hammer gun on the nails...i also feel this way about OO in LV...old methods used in a new way of solving problems...Were any of the other situations that I posted "interesting cases" for you?
I want to keep pushing this discussion because your position is somewhat unique. 99% of the time, the question asked of LV R&D is not "Should LV have recursion?" The question usually asked is "why doesn't LV have recursion?" It gets asked with high frequency, and attempted by some developer on the team about once every two to three years as far as I can tell. This keeps the research focus on the question of how to do it. The LV R&D team has been pounding on the recursion problem for *years* (bordering on *decades*) and we've recently started making some headway for dataflow-safe recursion. This is definitely the time to be asking the "should" question. Statistical outlier opinions are always worth at least a glance -- the definition of genius is the guy who saw something obvious that everyone else missed.
Your basic position, as I understand it, is two-fold:
1) The overhead of recursion outweighs the ease of its coding.
2) The iterative solutions are possible (that's provable) and they're sufficiently easy to implement in LV as compared to other languages that they should be preferred.
Is that somewhat correct?
On the topic of overhead, the current "recursive" solution is VI Server with reentrant VIs. That's not recursion IMHO and of course its performance sucks. Recursion works, and works well, when it has what LabVIEW doesn't have: a call stack. The $64000 question is "can you build a dataflow safe call stack" or something that performs as well. If we (R&D) can do so, should we?
That brings us to the preference for iterative solutions. I want to debunk one comment about other languages not having shift registers... in this loop:
int i = 1;
while (true) {
++i;
}
'i' has the same functionality as a shift register. I've done a bit of work on a text-based version of LV using C syntax, and a shift register is nothing more than a variable you declare outside the loop and promise to only assign once at some point during the loop.
Is there some aspect of LV that you think dramatically improves a programmer's chances of correctly coding the iterative solution to most recursion functions as compared to the recursive solution? I don't know of anything myself, but I'm open to argument.
> I never heard of the Fibonnacci numbers before this
> topic...i am more interested at the recursion and
> stacked iterative implementation concepts regarding
> specifically LV.
I think the point is made that you tried to convert the formulas as written into an iterative solution and got it wrong. I'm not trying to rub this in, just pointing out that I myself find converting a recursive problem into an iterative solution VERY HARD. I think that most software engineers would botch conversion of all but the most trivial problems. As far as the comment about an iterative solution making you think about other use cases, I don't get that point at all. When I conceive the use cases for any function -- XML parser or whatever -- I do it independent of the implementation of the code. I don't see how looking for an iterative solution changes the functionality you're trying to provide.
I know that none of my arguments speak to the efficiency of code --- code performance frequently is better with an iterative solution than with a recursive solution. I've seen that. But in my 16 years of programming, I've learned the hard way that code correctness has to be the first priority and optimizing the code comes second, if it turns out to be needed at all.
LV doesn't have recursion today. But it continues to suck up R&D time because the demand for it is high. It turns out to be a hard problem to solve, but I assume that some decade it will be solved. I don't think you've convinced me yet that I ought to encourage my co-workers to turn their attention to something else.
-
any suggestions to solve that problem?
I know why you're having the problem, and you're not going to solve it easily.
1) A class stays in memory as long as there are any instances of the class in memory. Get rid of all instances of the data and the class will be able to leave memory. This means any control or indicator whose current operating value is the class value would need to be reset, and all the little copies hiding on terminals across the block diagram. About the only ways to clean it out are a) run the VI again with a different class that overwrites the previous execution (tricky since you have to hit all the same code paths) or b) unload the VI from memory. Why does it stay in memory? Because all those instances of the data need the class definition to be able to be copied, modified and even deallocated correctly.
2) A class stays in memory if there is a dynamic dispatch call to its parent class if those VIs are running. Remove from memory any VI that is calling the parent class methods. Why does it stay in memory in this case? Because we don't know what sort of flattened strings might represent your class data that you might be about to unflatten.
The only solution is to make your system really dynamic so that you dynamically load the parts relevant to classes and when you want to unload you unload all those VIs, then load again with the new set of classes.
-
Dynamic VIs can be declared of Subroutine priority and these even seem to work properly. However if one has dynamic VI of subroutine priority, file browser context menu New -> Override VI doesn't work. If Override VI menu item is selected from child class, nothing happens. Override VI can still be created manually, but automatic creation doesn't work. The attatchments has a simple sample project.
This was reported to R&D (#42IHGKJ1) for further investigation.
-
Another question: is there any possible solution how to run two or more same subvi at the same time (for example in 2 subpanels) ?
Any time two subVIs are in parellel with each other (meaning no wires output from one are needed as inputs to the other) then they will run in parallel. If you put those two subVIs into two subpanels, they'll run independently without any intervention from you.
-
 Whew!
Whew!Heh... didn't mean to conflate those two sentences. I didn't intend to cast doubt on your diagnostic prowess.
-
With W4N node it is possible to connect incompatible wire to the node as the developer gets no warning when he connects different notifiers to the same node.
I don't understand what you mean here... the notifiers have a well defined subtype. You can't attach two different type of notifiers to the same node simultaneously, since there's only one input. When I hook up a notifier of int32s to the W4N prim, then the terminals are int32 type. If I delete that wire and hook up a notifier of strings, the terminals are string type. If I create a subVI that takes a notifier of int32 as input, I cannot wire any other type of notifier to that terminal. Only a notifier of int32 will connect. I can't bundle different types of notifiers together in an array.

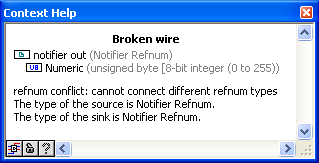
(putting mouse cursor on other side of the Red X on broken wire shows details of the other type -- a notifier of int32)
You've got a lot of good ideas, Jimi, but I can't even begin to imagine what you're referring to on this one. Safe mode???
Oh, and as for the "new prim vs added terminal" -- I thought about it some more. Adding a terminal wouldn't work -- this is behavior you'd have to pick at compile time and not have changing at run time. If you put one of these nodes in a loop and on the first few calls said "don't remember every refnum's history" and then changed it for later iterations to "remember every refnum history", there'd be no way to reconstruct the data of previous calls except by having stored it even though it wasn't being used (big performance hit). It would get messy. So I think that adding a new prim entirely would be the way to go (not that I'm planning on getting to this any time soon, let me remind you). We'd just have to make sure the new icon was distinctive. Other options would be a popup configuration (not something I like) or the terminal that requires that it be wired with a constant (which would be odd). There could be an on-diagram configuration [such as the polyVI selector ring] but that sort of thing cuts of access to the node's bottom terminals and takes more space on diagram.
-
Believe it or not, I really don't want to argue implementations... you asked for examples of recursion, I tried to provide one. I gave a simple case as an exemplifier of an entire class of problems.
For an equal comparison, your code must be compared to the top example, that does not involve a division, and not the bottom one that permits higher orders of recursions.So it is this one :
That i find even simpler due to the fact that it does not hide code in a case structure.
Your version, although I conceed it is simpler, does not match the function defintion... if I'm trying to confirm that your code matches the specification of the function, my first question is "Where are the two 'minus one' calls?" The fact that you found a way to provide the value without ever having the -1 calculation means that you had to think about how to encode the function in a VI and get the same mathematical result, as opposed to simply encoding the function as specified. My general case remains. Instead of Fibbonacci, let's try Ackerman:
http://en.wikipedia.org/wiki/Ackermann_function
<img src="http://upload.wikimedia.org/math/0/a/e/0ae4053de098cc9554752b190a38bc56.png">
If you want to write a program to print out the table of values for the Ackerman function, you can do it without recursion (all recursive functions can be expressed iteratively) but you'll be hard pressed to show (other than by empirical printing of the table) that you'd gotten it right.
I went through a bunch of LV's C++ code and LV examples to find other recursion examples...
In LV C++ code, we use recursion for assigning depth indicies to a cluster in LV (here's pseudocode):
AssignToClust(cluster, int32 *curdepth) { for (i = 0; i < number_of_elts_in_cluster; ++i) { cluster[i] = *curdepth; *curdepth += 1; if (cluster[i] is a subcluster) AssignToClust(cluster[i], curdepth); }You know the int16 arrays that come out of the Flatten Variant primitive? Those are type descriptors. In the C++ code, we use a lot of recursion for traversing those (for actions such as "typedef changed names, find all embedded type descriptors and change the name").
Related to the previous example: Generation of XML for LabVIEW data is a series of recursive calls between multiple functions, not just a single function. ClusterToXML might call ArrayToXML might call ClusterToXML might call ArrayToXML might call I32ToXML. Each adds a header before calling the nested recursion function and then adds a tail after the nested function returns. Doing this with a stack implementation would be very non-trivial.
The routine to search LV palettes for a particular function is recursive: check this palette, if not found, check subpalettes sequentially. Believe it or not, we do this every time you right click on a node so that we can show you the source palette for the node. It continues to amaze me just how many calculations can be squeezed into the time between right-click and the appearance of the popup menu.
Here's an example that ships with LV that uses a stack implementation but would be simpler if we had recursion:
c:\program files\national instruments\LabVIEW 6.1\examples\general\queue.llb\Queue Stack - Solve Maze.vi
Downloading VIs to RT targets -- download top-level VI. The download each subVI (repeat recursively). This one is easy to have implemented with a queue of VIs -- enqueue the top level VI, then repeat "dequeue one VI, enqueue all its subVIs, download that VI to target" until the queue is empty. The hard ones are the ones where you need results from multiple recursions to take the next step. Like this next one...
Math string parsing: Given arbitrary string of numbers and the four basic math operations, evaluate the value of the expression. For example (1+3)*3-4/4)
Generally the Evaluate function is "search left to right to find the first * or /. Split the string and Evaluate each half and either * or / the results. If no * or / is found, do same for + or -. If not found, return the value of the string." Adding parentheses makes this a bit trickier, but you get the idea.
Game theory: pruning a game tree involves recursive evaluation of future states of the game "On turn n you can take possible moves 1 through m. G(n,m) is a good position if you have won the game or if the majority of possible G(n+1, [1..m]) moves are good positions..." Evaluate G(1, [1..m]) to decide the best first move."
-
Have you ever had to use this in a concrete (deployed solution working and used by someone else) solution? If yes, could you explain the problem so that i can put it in perspective?
Used by someone else? Except for LV, none of my code gets used by someone else generally. But I have used it in graphics applications (specifically screen saver apps) that others could've written. The Fibonacci sequence underlies the golden ratio that is so useful for layout and design.
Whether or not I have used that particular math expression is beside the point... I've actually had many math expressions of the form "F(x) = F(g(x)) with some recursive base case" over the years that have been in deployed code. Newtonian approximation of functions comes to mind.
As for the code, what does function recursion add? Readability. Your VI works... I think. It took me 20 minutes of staring to figure out what the heck a divide operation had to do with calculating this value. Compare with this:
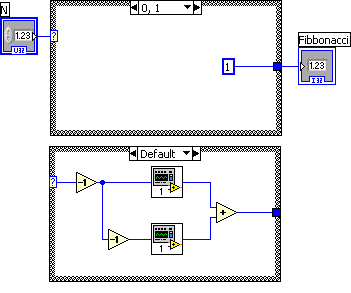
-
I think that the reason you haven't seen that many complaints is that it is hard to find out what happend.
Jimi's first post used a W4N node in a loop (should have been a single W4MN node instead, I know...), but it brought the issue to the surface. As for the explanation, you (and you are the "Perfect Queue"
 ) had to dig deep down, to really understand what was happening, no other Power user could come up with an explanation.
) had to dig deep down, to really understand what was happening, no other Power user could come up with an explanation.Maybe we could do a poll, and ask LabVIEW developers how they think a W4N node placed in a non-reentrant VI works, when called in two different places? I think the answer is obvious, since we specify a notifier by a reference, we also expect the two W4N calls to be separated. Changing the behaviour to a situation where references are being separated, shuldn't have any impact on older projects. At the most, programs would be using the correct timeout values, and get the expected behaviour, right?
Oh, no need for a poll. We can all guess how they'd reply -- the same way we all replied. Yeah, I had to go drilling into this because I forgot the rules of a single node with different refnums. The current behavior is actually documented in the online help (not in detail, but it is there). It's just been a while since I looked into it (refactoring the notifiers was the very first project I had when starting at NI years ago).
This isn't so much a reentrant/non-reentrant issue. It's how does a single node that gets different refnums at different times behave. Jimi's original demo was a problem of a Wait for Notification inside a For Loop. Nothing about reentrancy there.
The current node always looks to the future -- this can actually be used to ensure that processes fire in a forward looking order. What looks like a bug in Jimi's two demos (either because each notifier only fires once or because two notifiers have dependencies upon each other) becomes a feature when notifiers are firing independently multiple times. I've had theories before that "If I change XYZ no older code will notice." I no longer maintain such fantasies, and changing the runtime behavior of the notifiers sets off big flashing alarm bells in my head. I'd rather try to add a new node or a terminal for specifying behavior on the current node.
Regarding the performance, I feel that the notifiers are behind the queue operations, e.g. using preview queue element instead of a W4N node (timeout = 0) is much faster. So maybe a speed bump is needed anyway?Considering that they are exactly the same code, I'd be surprised that there's any speed differences. The notifiers are implemented as a single-element queue that simply overwrites its first element instead of locking on enqueue. It isn't like the code is cloned or anything -- they are litterally running the same code.
-
can you please comment the post from Jimi. The post where two parallell pieces of code hang, due to this notifer behaviour.
Do you really argue that this is not a bug?
If you do, wouldn't that be like saying that W4N nodes should not be put in non-reentrant VIs?
Sorry... took me a while to get back to this post.
I really do say this is not a bug. The notifiers were not designed to work in this case, in fact, they were explicitly designed against this case for performance reasons -- the bookkeeping of which message was seen last for each individual refnum is a hit that the vast majority of apps don't worry about. In the 5 versions of LV released so far with the notifier prims (not to mention several prior versions with the VIs-around-CIN-node), this is the first time that anyone has complained (to my knowledge) about the lack of support for this case. As for the question of whether or not the Wait for Notification behavior should change, I'd have to say "no" if for no other reason than we'd be breaking behavior going back multiple versions of LV.
As for the question of whether new prims could be added (a "Wait for Notification with Fine-Grain Memory"), it probably could be done, but I'd worry about the confusion of having two Waits in the palette... it'll require delicacy. I doubt that this will become a priority anytime soon, especially since other synchronization tools exist which I thnk can be hacked to do the work. I'll put it on the back burner of suggestions (which is actually a good place to be... there are good suggestions that have actually fallen off the back of the stove, rolled across the kitchen floor, out the cat door and are sitting in the garden -- LV gets a lot of good suggestions each day!)
-
Recursion case 1 :
Listing the content of a folder. And all subfolders...and all subfolders and... i see no need or advantages to push the recursion on the methods(VIs) also.
The classic would be calculating Fibbonacci numbers:
F(0) = 1
F(1) = 1
F(n) = F(n-1) + F(n-2)
Coming up with a data structure to do this recursion is annoying, especially when the the function definition is already known.
-
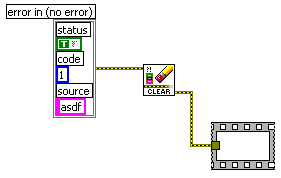
If I'm understnading you correctly, you've disabled automatic error handling in the VI you attached - what you need to do is disable it in the VI that calls that VI - that's where the errors are handled since it realises an error is coming out of your subVI and isn't connect to anything - it's only once it gets out of the subVI and is properated up to the calling VI does it realise it's not being handled and pops up the dialog.
I opened up the VI and took a look. Christopher is correct. The subVI's configuration doesn't matter. It's the caller VI that has to be configured to not do automatic error handling. You have a subVI that is returning an error, and that error is not handled. You can either turn off auto error handling in the caller or handle the error -- wiring the output terminal to anything is sufficient, as shown:
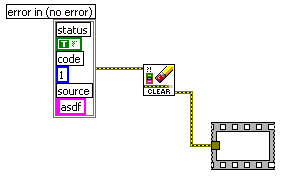
-
Argh ! :headbang: Please just make the object control and indicator typed ! This sounds terrible.
They are typed. Strongly typed. We're not talking about the type of the VI. We're talking about the type of the call to the VI.
-
Certainly the way to go if trying it is quick... On the other hand if trying something might take a lot of effort, always good to ask if someone else has already invented the wheel.
It depends on your goal. If the goal is getting a project done for work, then, yes, ask if there's already a wheel. But if the goal is pushing yourself, you've got to pretend you're in a high school physics course. Every experiment you try is something done hundreds of times before, but you haven't done it yourself, and until you do you don't really understand the implications for the next higher-level experiment. Anyone using LV can use the Sort 1D Array primitive. But can you write the code that does the sort? These are the sorts of challenges that prove you know a language.
You might try these...
High School Level
http://www.acsl.org/acsl/96-97/pdf/allstar/progs.pdf
(In the PDF above, the problems start on page 7.)
College Level
http://www.mcs.vuw.ac.nz/~david/acm/
None of these is going to stress LV's parallel processing capacities -- in any language other than LV, spawning and collecting threads is a graduate-degree level concept.
-
Welcome to the LV matrix...
"I look at all these wires and nodes and structures... I don
-
I think an externalNode (XNode) will be better for that
Quick safety tip for all you who seek to peek under the skirts of LV: external nodes and XNodes are not the same thing, though they both serve the same goal. External nodes were LV R&D's first attempt at nodes that script themselves. They have issues and have been supplanted by XNodes, our second attempt. XNodes are better, in theory*.
*"In theory", from the Latin "en theos" meaning "with God" or, more specifically, "assuming He Who Built The System doesn't change His mind."


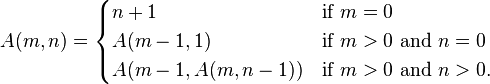{kind=link}
[CR] Convert between ASCII and Unicode
in Code Repository (Uncertified)
Posted
It seems unlikely that your UNICODE-->ASCII works given all the possible UNICODE encodings. I say this, not because I'm an expert in Unicode, but because I know how much I don't know. For example,
http://billposer.org/Software/uni2ascii.html
This is an open source ASCII-->UNICODE-->ASCII tool. Notice the revision history? This simple tool has a change log that goes for pages and talks about support for multiple encodings, etc. Further, the standards document for unicode has *chapters*. Compare that with your standard listing of the ASCII standard, which is just a table of 256 characters.
Here's the motherload of information about unicode:
http://www.unicode.org/unicode/faq/