

Aristos Queue
-
Posts
3,183 -
Joined
-
Last visited
-
Days Won
205
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Aristos Queue
-
-
One minus...i have to cross the internet to get in my Perforce depot, this causes LV to hang(1-3 seconds) frequently due to all the queries made to verify if the file is in the depot, checked out, etc...
So after a while i disabled it...

There's some P4 settings you can put in for remote depots that creates a local mirror of the depot and only syncs back occassionally. I've only heard about these settings from our international R&D folks (the ones in Shanghai who have to access the P4 servers here in Austin, TX) so I can't give you any more info than that, but it might be worth skimming the P4 help documents.
-
If the by_value need is 99.9% (within the LabVIEW community), why haven't anyone already created this? It should not be more difficult than creating the by_ref systems that exists today.Here is my real question though: Do you really mean 99.9%? Right now, I think we need by-reference classes, with locking.
Jaegen and JFM both ask effectively the same question.
Why hasn't anyone built by-value classes before? It wasn't possible. Only fundamental changes to the LV compiler make this possible. There just wasn't any way for any user to create classes that would fork on the wire and enforce class boundaries for data access. Doing inheritance by value was right out.
As for the "99.9%" estimate -- All the fever about the need for by-ref classes with locking is about doing things that you cannot do effectively with LabVIEW today. The by-value classes are all about improving all the code you can already write with LV today. It's about creating better error code clusters, numerics that enforce range checks, strings that maintain certain formatting rules, and arrays that guarantee uniqueness. Suppose you have a blue wire running around on your diagram and suppose that this 32-bit integer is supposed to represent a RGB color. How do you guarantee that the value on that wire is always between 0x000000OO and 0x00FFFFFF? A value of 0x01000000 can certainly travel on that wire, and someone could certainly wire that int32 to a math function that outputs a larger-than-desired number. In fact, most of the math operations probably shouldn't be legal on an int32 that is supposed to be a color -- if I have a gray 0x00999999 and I multiply by 2, I'm not going to end with a gray that is twice as light or any other meaningful color (0x013333332). Every VI that takes one of these as an input is going to have to error check the input because there's no way to enforce the limitation -- until LV classes.
My entire drive has been to highlight that Software Engineers in other languages have found that organizing the functions in your language around the objects of the system instead of the tasks of the system creates better software. When we apply this design style to a language IT SHOULD NOT CHANGE THE LANGUAGE NATURE. In fact, OO design can be done in LabVIEW WITHOUT LabVOOP in LV7.1. At NI Week presentations for 2002 through 2005, I and others gave presentations that talked about the importance of using typedef'd clusters and disciplining yourself to only unbundle those clusters on specific VIs. I talked about creating promises to yourself not to use certain VIs outside of certain other VIs. With LV8.2, we have OO programming. LabVOOP is a set of features that let the language and programming environment enforce these "data walls", to let you formally define the boundaries of data.
Everyone keeps looking at LabVOOP as the silver bullet to solve the problems they've been having with LabVIEW -- references. The greatest value of LabVOOP is not in solving any new problems. Its in changing the fundamental design of all the previous VIs you've ever written. As time goes forward, as the UI experience of LabVOOP improves, I think this will become more obvious. My opinion, not shared by most of National Instruments, is that eventually -- in about 5-10 years -- we will have LV users who learn "New>>Class" before they learn "New>>VI" because the VI is not the primary component of the language that a user should be thinking about if they are going to use LV for building applications. If they are going to use LV as a measurement tool -- dropping a bunch of Express VIs, creating one-off utilities for charting values from a DAQ channel -- then they will be more interested in VIs and may never create a class.
Jaegen, you asked if I can refute the need for references. No, I can't. As I said, improving references would help LV. But it is an issue for all LabVIEW data, not just LabVIEW class data. Locking references for arrays, for numerics, for refnums themselves (ha!), AND for classes. Classes certainly have some special needs when we do references (primarily the automatic deref in order to do a dynamic dispatch method call), but "by reference" is a conversation for LabVIEW as a whole, not for LabVOOP by itself.
I saw a beautiful thing yesterday -- an internal developer with a several hundred VI project he's built since August in which all the VIs are in classes. He's used the classes to create a very flexible string token parser and code generator. He tells me that the code is much easier to edit than his previous version that didn't use classes. In fact, he scrapped the old code entirely to do this rewrite. ... And not a reference in sight.

-
since the native implementation would take care of this.
No, a native implementation would not take care of this. Let me lay that myth to rest right now.
If we had a native by-reference implementation, the locking would have been left completely as a burden to the programmer. Would you suggest we put an "acquire lock" and "release lock" around every "unbundle - modify - bundle" sequence? When you do an unbundle, how do we know that you'll ever do a bundle -- there are lots of calls to unbundle that never reach a bundle node, or, if they do, its buried in a subVI somewhere (possibly dynamically specified which subVI!). There are bundle calls that never start at an unbundle. We could've implemented a by-reference model and then had the same "Acquire Semaphore" and "Release Semaphore" nodes that we have today, only specialized for locking data. Great -- now the burden on the programmers is everytime they want to work with an object, they have to obtain the correct semaphore and remember to release it -- and given how often Close Reference is forgotten, I suspect that the release would be forgotten as well. Should you have to do an Aquire around every Multiply operation? A Matrix class would have to if the implementation was by reference. Oh, LV could put it implicitly around the block diagram of Multiply, but that would mean you'd be Aquiring and Releasing between every operation -- very inefficient if you're trying to multiply many matricies together. So, no, LV wouldn't do that sort of locking for you. There is no pattern for acquire/release we could choose that would be anywhere near optimal for many classes
The by-reference systems used in the GOOP Toolkit and other implementations do not solve the locking problems. They handle a few cases, but by no means do they cover the spectrum.
The by-value system is what you want for 99.9% of classes. I know a lot of you don't believe me when I've said that before. :headbang: It's still true. :ninja:
-
This is a reply to the original post, not to any of the subsequent comments. I want to focus on "when would this be a problem in a real situation."
Simplest case: Unique ID. I have a database that can be accessed simultaneously by many people, such as a banking system. At many branches around the contry, people may simultaenously open new accounts. Each account should have a unique account number. The counter that stores the "next available account number" needs to have the "get modify set" lock -- get the current value, increment it, save it back for the next request. Otherwise you may have two accounts that both get the same value, both increment and then both set the new value back.
Wikipedia is a site where anyone can edit an encyclopedia entry which does *not* support a locking mechanism. If I view a page, I might see something wrong, so I edit the page to fix it. Meanwhile, someone else notices a different part of the same article and realizes they can add some additional information. They start editing. They submit their new information, then I submit my fact correction. Their new information is lost because mine is the final version of the article checked in and I didn't have their changes in my edited version.
These are cases of data editing. You can have more interesting locking requirements... take this forum for example.
Suppose I post a message which asks a question: "Can I open a VI in LabVIEW?" You see the message and start composing your reply to answer the question. Before you get a chance to post your message, I edit my original post so it asks the negative of my original question: "Is it impossible to open a VI in LabVIEW?" I hit re-submit, and then you hit submit on your post. You submitted "Yes" because you were answering the original question. But the "last edited" timestamp on my post is before the timestamp on your reply, so it looks like your answering my second question. Which then leads to a ton of posts from other people telling you you're wrong. This is a case where you and I are not modifying exactly the same entry (we both have separate posts) but we're both editing the same conversation thread.
Any time two systems may be updating the same resource -- DAQ channel settings, OS configuration, database tables, etc -- you have a danger of these "race conditions" occuring. It's a race because if the same events had occurred in a different order -- an order that a lock would've enforced -- the results would be very different. These are the hardest bugs in all of computer science to debug because they don't necessarily reproduce... the next time you do the test, the events might occur in a different interleaved order and so the results come out correct. Further, if you do start applying locks, you have to have "mutex ranking" that says you can never try to acquire a "lower rank" lock if you've already acquired a higher rank lock other wise you'll end up deadlocked. The rankings of the locks is entirely the programmer's rule of thumb to implement -- no implementation of threads/semaphores/mutexes or other locking mechanism that I've ever heard of will track this for you since the run time checking of locks acquisition order would be a significant performance overhead to the system.
-
How programmatically fire the "panel close?" event ?
With the exception of "Application Exit" (in Lv8.2) and user defined events, no events of the Event Structure can be triggered programmatically. If a panel is closed programmatically, that does not fire a Panel Close event. This is important for VIs that filter the panel close event, then do some clean up work and then close their own panels (or do the same on behalf of another VI). Similar applies to Value Changed (where the value gets changed, and in the event code the value is somehow modified [perhaps pinned to be within a certain range] ). The system breaks down if the programmatic work triggers events.
App Exit was added as an exception predominantly because it *can't* trigger itself (once LV is exiting, its exiting!) and it provides a way for VIs to guarantee a time to do their clean up work (such as resetting hardware) for built applications.
-
This was reported to R&D (# 41QIL3J1) for further investigation. I've reported the fact that the password stored in the .lvproj file should be encrypted and that the dialog should display whether a password is set or not but not what that password actually is.
-
Which presumably means that they were all copied from an existing VI and someone forgot to change their documentation (what, no checklist at NI?).
If it isn't in the palettes, it doesn't always get checked. Only real zealots go digging into all the subVIs in vi.lib. Not that I'm referring to anyone on this forum or anything.

-
Uh, umm, he he ... I've made similar comments myself.

Don't be too critical ... some of us are STILL cleaning up code written by FORMER employees who knew just enough LV to be dangerous. A sense of humor goes a long way in these situations.

Now there's a signature... "I know enough LabVIEW to be dangerous." Maybe Michael could use that for the new LAVA users. Instead of "2 more posts to go" it could be "Enough LAVA to be dangerous."
-
I assume this feature is implemented because it may be technically impossible to keep track if all decendent class dynamic VIs also really pass the wire trough the method. If the wire doesn't go from input terminal to output terminal directly or indirectly, one cannot of course preserve type.
Bingo.
What I suggest is an addition of a new terminal type similar to dynamic dispatch terminal. This terminal also would require that the wire really continues from input terminal to output terminal so that the type can be passed trough the method VI. However unlike dynamic dispatch terminal, this terminal would not be used for dynamic selection of which method instance to call.Your thoughts accord with mine, sir. In fact, all of the type propagation information needed to support this function is available today in the compiler.
The problem is the user interface. We wouldn't be able to just popup on a terminal and say "This terminal is...>> XYZ" because what we would need is a way to specify which terminal, possibly a fairly complex mapping. And if we implement the simple form, you'd probably next want us to support the case of the MinMax.vi -- given two class inputs that produce two class outputs, the top one being the greater and the bottom one being the lesser, you'd want the outputs to become the nearest common parent to two input types. So to really handle this you need a fairly complex map.
And then there's the enforcement on the block diagram, with some very arcane error reports, such as, "Although data from X and Y both propagate to Z, the runtime data type of Y is not preserved at the Event Structure tunnel." The ones we have for dynamic output terminals are confusing enough. With the dynamic in/out, I was able to implement the background color of the wire to indicate whether or not the data was successfully propagating to the output FPTerm. With multiple sets of propagations on the diagram, I'd have to have some annotation on the wire probably involving a numeric code of which FPTerms were involved in setting the data on the wire.
I tried pulling this together a couple years ago during LabVOOP development. It's a continuing problem. At this point I'm actually considering something more akin to an "Advanced Conpane Configuration" dialog which would allow you to fully define the mapping of input terms to output terms, specify 5 different behaviors for unwired input terminals and about 3 other really useful behaviors that a simple "click on conpane click on control" cannot specify.
I'm starting to think there exists a rather elegant solution to the type propagation problem with the addition of a single new primitive to the language. I've been drawing sketches of a "Preserve Runtime Type" prim, which has a look/feel identical to the "To More Specific" node, but instead of casting to the wire data type, it casts to the type of the data on the wire at runtime. It's a little weird to explain why such a node is necessary, but the short description is that with it you could wrap a dynamic dispatch in a static VI and then do the runtime type cast on the output of the dynamic subVI call to preserve the type... then make the static VI be your public interface. (Sorry, I don't have the sketches in a .png form to post right now.)
-
I had the same issue with dynamic VIs in Lv 7.1 and I used the following workaround:
create a new VI, put all dynamic VIs into it, drag a disable structure around it, put that VI into your main vi - and voila - all dynamic VIs are in the hierarchy.
The second advantage is: if you use typedefs, etc in your main VIs hierarchy, wich are also used in the dynamic VIs, the typedefs in the dynamic VIs are automatically updated, if you change your typedef. The same happens, if you save a SubVI with "save as ..." because all VIs are in memory and are changed automatically ....
cheers,
CB
Um... dynamic subVIs didn't exist prior to LV8.2. You're talking about a subVI that is called dynamically. The post was (I think) about dynamic subVIs (as in in LV8.2, right click on the conpane terminal of an LVClass type and select "This terminal is>>Dynamic Input (Required)"
-
It sounds like you can't use a .net component in an XControl in LV8.
You can't use a .Net refnum as the data type of the XControl, nor pass such refnums to/from the host VI through Properties of the XControl. Using .Net functionality purely internal to the implementation of the XControl should work fine. If you can't get that to work, I suggest posting to ni.com to get feedback from some of the .Net folks -- neither XControls nor .Net are my typical domain.
-
Ok, so in a single VI, this all is working fine (VI_works.vi - as an example with a simple progressbar) but if I want to implement the functionality into a XControl I will get an error "Cannot pass a GCHandle across a AppDomain" (VI_doesntworks.vi). Any other .NET Component (also non-Microsoft Components) doesn
-
I start three instances of this receiver, as well as three instances of my logger and three of my UI (receives the Notifier data)
 YEEE HAW! I think I found it!
YEEE HAW! I think I found it!The key word in the above sentence is "three".
In the "enqueue dequeue enqueue" version -- the VI tries to enqueue and if there's room it immediately enqueues without releasing the lock on the queue.
In the "Get status, dequeue enqueue" version -- the VI checks Get Status and if it finds that there is enough room in the queue, it enqueus... BUT if there are three receivers operating on the same queue, one of the others may have made the same Get Status check and decided it had enough room -- thus taking the very last spot in the queue!
For example:
The queue has max size of 5. There are currently 4 elements already in the queue.
At time index t, these events happen:
t = 0, VI A does Get Status and the value 4 returns
t = 1, VI B does Get Status and the value 4 returns
t = 2, VI B does Enqueue
t = 3, VI A does Enqueue -- and hangs because there's no space left
If you're going to use the Get Queue Status, you have to make your test "If (current elements in queue >= (max queue size - number of enqueue VIs)) then { dequeue }"
Subtle!!!!
-
Even though your idea is also a good one, I was thinking something else. Actually, I always makes sure all my VI's are in memory. Is there any other way to code? Before the project view, I had a VI Tree vi that I used to place all my important vi's on the block diagram. I then open this single VI to make sure I have everything accounted for.Perhaps there's another way to address the above uses-cases in LV8.x but right now, I don't see it.
The ideal would be to get to the point where we don't have to have everything in memory, even for the reasons Michael cited. The project is designed to scale from the simple "couple VIs utility" to the VERY LARGE APP. As such, it does not load into memory all the VIs listed in the project (though subcomponents, such as LVClasses and XControls do at this time).
What could be done when you open the project is for the project to do a quick glance at each of the VI files to get specific information about them and cache that information -- such as which VI calls which other VIs as subVIs. Then editor actions could load VIs as needed. If I renamed A.vi to B.vi, the project would know all the callers of A.vi and could load them into memory right before doing the rename so that the project stays up-to-date.
The project today has a dual existence as both an application definition and a deployment/file tracking tool. If dependency tracking were added, this would push the project more toward being an applciation definition and less of a deployment tool. There's quite a bit of pressure back and forth between app development LV features and target deployment LV features over what the project's job actually is. There was a sign on someone's desk a while back that said, "If you build something truly useful, people will use it for things you never intended then criticize you for shortsightedness." This has sort of happened within our team with the project. The couple original designers had an idea for the project, but now that its there, a lof of other developers are suggesting, "Hey, I could use that to help with feature XYZ if I just tweak the project like this..." The future should be interesting.
-
Can you btw clarify why the first cluster consumes less memory than the second cluster and why enqueueing & dequeueing a buffer makes one extra copy?
Nope. If I understood that I might have attempted to modify the inplaceness algorithm.
There is an enlightened being whom we call Chief Architect, at whose feet we sit to better learn the secrets of inplaceness. :worship: Perhaps I will have an answer in a few years.
-
And for all that attended, thank you very much. I was overwhelmed by the turnout; people standing in the back and even sitting in the aisles.
Norm: Did you ever investigate Reentrant Panels (LV8.0 and later) and whether they were a better solution for you than VI Templates?
-
I was thinking about whether replacing this approach with queues would be beneficial, and here's what I'm still not sure about:
From what I can tell, you can only dequeue the same datatype that you enqueue. I would have assumed that if I enqueue a scalar in the form of an array of length = 1, then dequeue the array, it would have given me the whole contents of the queue, but this wasn't the case. I also don't see any sort of way of saying "dequeue the last N queued elements".
Therefore, ff I wanted to use queues for this type of data transfer, I would have to put the Dequeue, along with Get Queue status, in a while loop and run it until the queue is empty. Is that correct? If so, can that really be more efficient than what I'm doing now?
You can use Flush Queue to dequeue all of the elements. If you want N elements and account for the possibility that there aren't that many elements in the array, then do this:
There's a slightly easier way... Put the Dequeue in a While loop with the Timeout terminal wired with zero. It will dequeue one element. If no element is available, it will immediately timeout. Wire the output Timeout terminal to the Stop terminal of the While loop. You can Or in a test to see if the "i" terminal of the While loop has reached your desired count. This way you don't have to get the Get Queue Status prim involved, and you'll save yourself some thread synchronization overhead.
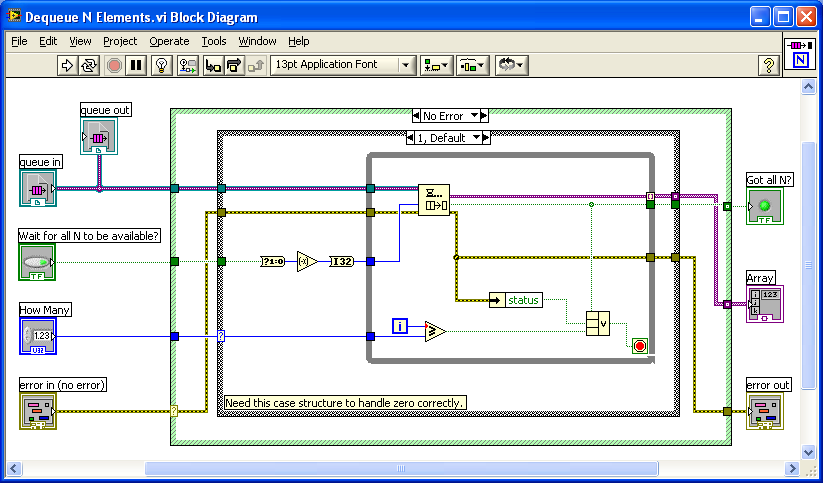
The attached VI is written in LV8.2.
-
nevermind
-
\No, I don't remember, LV 7.1. is the first version I've ever used. And I really started my LV career with LV 8.0. But good to hear that we may expect better optimization later on. Until then, I'll use queues to store my large arrays.
:laugh: Ah! That's why you're so picky! You started with the most stable version of LV ever. We've got to get you some perspective!
All joking aside: The beta period gave LV classes a pretty hard pounding and hammered out a lot of bugs. The version that finally shipped has shown itself to be fairly stable so far, but as we expected, there are problems. This was a pretty wide ranging "feature" of LabVIEW (if you can call all of the features of OO a single feature of the language!). Even as much exposure as our beta program gives to LV, there are a lot of aspects of LV, and there's no way to test all the possible system interactions. I'm actually pretty pleased with the general system stability, but the instability of any first release is what leads to "dot-zero" aversion for many customers. It's nice to have customers who find enough utility in the new stuff to put it through its paces despite the occassional hiccup.
-
I have not be able to create a (simple) VI to generate the error, but sometimes I have an error 91 or -1967362020 when I try to read a shared variable from inside a LVOOP class method. There is nothing that I know of that would make a VI that is a member of a LV class interact with shared variables in any way different from any other VI. To the best of my knowledge there is no special functionality anywhere in the shared variables relating to LV classes. If you manage to create a VI that replicates the problem, you should report it as a bug to NI.
I have absolutely no knowledge as to what those error codes mean if they're coming from a shared variable. Nothing LV class related, I'm pretty sure.
If you move the VI outside of the LV class, does the shared variable have the same behavior?
:!: As for the VI that always needs saving... this is a known issue. I'd list a bug report number here but I don't have the database in front of me at this time. My suggestion is that if a VI is a member of an LV class and thinks it needs to save, go ahead and let it save. I know that's not desirable behavior, but not saving it has been shown to lead to corruption over time (the info saved in the VI drifts out of sync with the info in the .lvclass file). This bug will be fixed, I assure you.
-
Bundle/Unbundle have several special inplaceness optimizations that classes did not attempt to take advantage of in this first release. Do you remember LV6.0.1 followed quickly (weeks) by 6.0.2? That was caused by a mistake in someone changing the inplaceness algorithm. It is a hard algorithm to get exactly right, and if you get it wrong, you can end up with values that change randomly as a VI executes. I decided that having a functionally correct implementation of objects in this first release was better than trying to get involved in the optimizations --- the optimizations will be added in future LV versions. Lesson one of Computer Science 101: Make it work first, then optimize later (or never). In this case, we're going to do "later."
-
There are several aspects of the editor that will need work over time. The find/replace system is one. At this time, there are many places in the editor, like the Hierarchy Window, that do not know to take dynamic calls into account.
Regarding crelf's comment that such finding would have to be based on name: we can do the find better than that. The classes do know their inheritance relationships, so when you search for X.lvlib:Y.vi, we can differentiate which Y.vi calls might possibly invoke X.lvlib:Y.vi specificaly.
It's just going to take time to find all of these places that want special treatment for dynamics. Some of them are going to need UI tweaks, since it is equally possible in some cases that you want to treat dynamic nodes as possible calls to a set of VIs, and other cases where you're going to want to talk about just the specific VI.
-
Either way, a lot of overhead is added when using names, since that name needs to be "dechiphered" in some way no matter how you look at it.
It's not that expensive if you use a dual system the way queues do of lookup normally using the number and only occassionally using the string. Only the Obtain Queue uses string. The others all do numeric lookup using the refnum. Add a function that translates string to "pointer" to your system and you're good to go.
-
Would it be faster than the following simple array trick?
...but my real life LUTs are massive and performance is everything. Note that I already separate the independent variable X into a separate 1D array and forget about interpolating.
You're probably faster for lookup times than the variant, but you'll pay pay a bigger penalty at insert time. If you use the Search 1D Array prim to find what position to do the insert, that's an O(n) penalty (though you might have written your own binary search on sorted data to get this down to O(log n) ). When you add a value to the array, possibly in the middle of the array, you're going to reallocate the array to make room for the new element. That's a lot of data movement. Compare that with the O(log n) time needed to add a variant attribute to the tree with zero data movement. Same comparison applies for removing an element from the lookup table.
So if your lookup table is pretty stable from the time it is built until you're done with it, your method probably has advantages. If you're adding entries and deleting entries a lot, then I wager the variant attrib is going to beat you hands down, even including the expense of converting your doubles to strings to do the key lookup.
The need for lock in get-modify-set pass
in Object-Oriented Programming
Posted
This depends on what you think of as "an object." I contend you're very used to doing this -- you just don't recognize it.
Waveform, timestamp, matrix -- these are object types. They are complex data types with well defined operations for manipulating the data. They may aggregate many pieces of data together, but they are exposed to the world as a single coherent data type. NI isn't going to be replacing these types with LVClasses any time soon -- we want LabVOOP to be seasoned before such core components become dependent upon it. But if we were developing these new today, they would be classes. Every cluster you create is an object definition -- with all of its data public and hanging out for any VI to modify. These are the places you should be looking to use LVClasses. And you don't want references for these.
I tend to think of integers as objects because I've been working that way for 10+ years. You don't add two numbers together. One integer object uses another integer object to "add" itself. Forking a wire is an object copying itself. An array is an object. Consider this C++ code:
typedef std::vector<int> IVec;IVec DoStuff(const IVec &x, const IVec &y) { IVec z(x); c.push_back(y.begin(), y.end()); return c;}void main() { IVec a, b; a.push_back(10); b = a; IVec c = DoStuff(a, b); }Consider the line "b = a;" This line duplicates the contents of a into b. This is by-value syntax. The syntax is there and valuable in C++. JAVA on the other hand doesn't have this ability. That language is exclusively by reference. If you use "b = a;" in JAVA, you've just said "b and a are the same vector." From that point on "b.push_back(20);" would have the same effect as "a.push_back(20);"
The by-value syntax is just as meaningful for objects. In fact, in many cases, it is more meaningful. But you have to get to the point where you're not just looking at system resources as objects but data itself as an object. Making single specific instances of that data that reflects specific system resources is a separate issue, but is not the fundamental aspect of dataflow encapsulation.