

Aristos Queue
-
Posts
3,183 -
Joined
-
Last visited
-
Days Won
204
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Aristos Queue
-
-
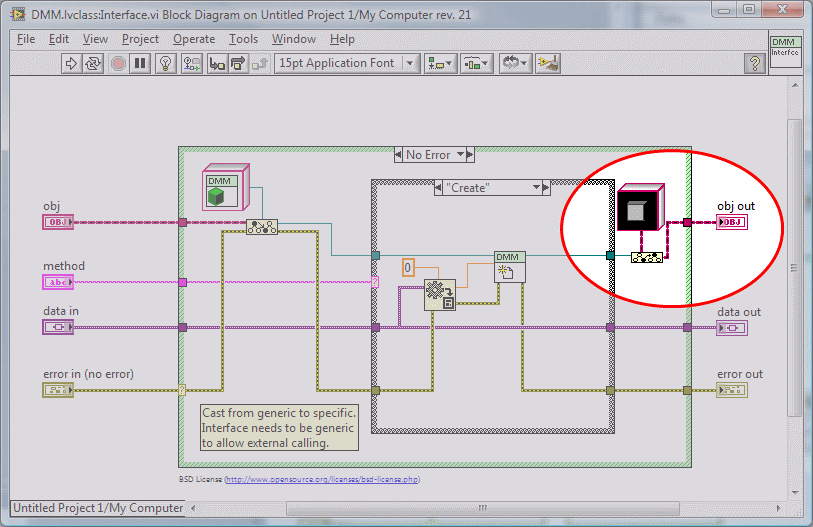
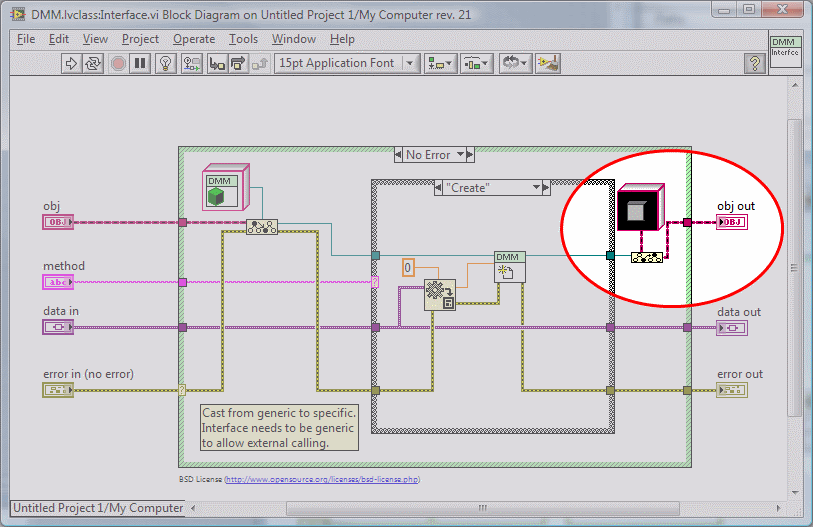
None of the patterns documented in the document change a lick with the introduction of DVRs. Some of the other patterns from the Gang Of Four book might be more directly implementable, but they (generally) remain undesirable as any use of references in a dataflow program is subject to severe negatives, especially since most of the needs that the patterns serve can be done without references. I would hesitate -- strongly -- to call any pattern that uses DVRs "cannonical" unless/until it can be demonstrated that no dataflow solution exists.The recent arrival of the ability to manipulate objects by reference should allow to simplify these design patterns, isn't it? -
You don't. The only mechanism is to run the VI.How does the class user determine what the current value of the constant on the BD is without running the VI? (I mean when more than 5 minutes have passed since copy-paste. And No, a free label comment on the BD doesn't count!)
-
Private methods on interfaces can implement parts of the interface and are quite useful.Maybe in the long run there will be a valid reason for having private or community methods in Interfaces. -
What is a tabbed menu?
-
You are correct. It is not your job to keep track of our bugs. Once you file a bug report with us, it's our job to get it fixed. Unfortunately, not every bug that gets filed gets fixed. There's a constant balance between the CAR backlog, fixing CARs for new features, and development of new features. Time available in the development cycle, risk level of the bug's fix, and mutation issues can all keep a bug from getting fixed, sometimes for quite a while. And there are some bugs that eventually reach the point of "it's just not ever getting fixed" simply because the issue is so corner case and requires so much code movement that it's probability of getting fixed falls to zero.I may have have the case number but to be honest, I don't think its the customers job to keep track of the supplier. It does make for a good excuse. We didn't do anything with it because you didn't check in once a week on the status.....
Corrupting bugs have highest priority (those that cause you to lose all your work because the VI is saved wrong).
Crashing/hanging bugs have next priority.
After that is incorrect behavior (doesn't work as documented) and then cosmetic (stray pixels left on the screen, for example). CARs without a known workaround take precedence over those with a workaround. And bugs that occur in the runtime engine take precedence over bugs that occur only in the editor.
What the LV Champions have done is create a system for users to prioritize bug fixes. They have the ability to tag bugs as "this is a high priority to us, even though it may not look like a big deal." That helps make sure a bug gets attention that it might otherwise not get because of other seemingly higher priority bugs. The Champions thus have the ability to speak for the community and say, "This needs to be fixed ASAP." Again, even with the ASAP, it can take a time to get a fix right for some bugs, so "ASAP" may not be the next release.
There are CARs from many versions ago that are still not fixed. Every release we have a percentage of the CAR backlog that we commit to fixing, and every release we chew through a few more of them. I know it is poor consolation that your particular bug didn't get fixed. All I can say is that we fix many, and we try, through the Known Issues list, to keep you apprised of those we don't.
-
-
It's definitely NOT going to make 2010. As I said at NI Week... you should expect very few LVOOP features in the next one, possibly two, releases. What we're working on now will take significant time and attention, with little bandwidth to spare in the interim.So now.. Will it come back in 2010 or should I just keep on coding?

-
He probably just copied the constant from somewhere... the effect won't be any different than if he used a regular LV Object constant -- the center input only cares about the type of the wire, not the value on the wire. Of course, depending upon the value of that constant, you might be creating a dependency on a class that is otherwise unused in the diagram. It'd be better to use a default-value constant.Kurt, I noticed an unusual upcast to a non-default Labview Object. Why do you do that?
-
 1
1
-
-
You'd think so, wouldn't you? The response there has been very different.Doesn't it apply to project window as well? -
Read the documentation on the Event Structure. It was brand new in LV 6.1, and that gives you the tools to do what you're asking.
-
- Popular Post
- Popular Post
Your tool makes me both happy and sad, both motivated and depressed.I posted a new version of the Class Tool with some improvements to the menu and it now also shows methods of ancestor classes.
It is nice to see people using classes and using them so much that they write tools to extend them and make them more useful. It's just this particular tool... you see, this used to be in LabVIEW, but it never shipped. First I was told -- by multiple sources -- that using a text display was bad, that it needed to be the icon display or whatever the user had configured in their Tools>>Options for palette displays. Ok, so I made LV build an on-the-fly graphical palette. But then it was shot down because the layout was inconsistent: things in the palette shouldn't move when a new VI is added to the class, but adding new VIs at the end means nothing is ever findable. Can't you make it alphabetical but read my mind and not be alphabetical when I don't want them to be? Shouldn't virtual folders have something to do with it? Why aren't the parent methods folded in? Why are they in sub folders? Shouldn't they be in superfolders? What the heck is a superfolder? Perhaps the palettes should be named in iambic pentameter. Can you make all the icons rhyme?
Eventually I went crazy, had a nervous breakdown, and killed the feature. Clearly, anything we did automatically was undesirable. Another member of my team made it so that a .mnu file could be associated with a class so that users could define their own layout for the VIs. I've never felt like revisiting the issue.
I commend your work on this feature. I am surprised this thread is not full of people complaining about how useless it is.
-
3
-
URL isn't quite right in the link. Here's the fixed link:
-
No. Individual branches you might be able to guarantee order of, such as where the output of node A forks to nodes B and C -- the compiler will always add those to the execution queue in a particular order. But if output of Node A forks to C and D, and B also forks to C and D, the order of C and D may vary depending upon whether A finishes first or B finishes first, and which finishes first can vary greatly depending upon the operating system thread scheduling.Question for you: If I have a VI with independent parallel operations the execution order is indeterminate. Assuming compiled Labview programs use some sort of list scanning described above, does it follow that although I cannot predict which order each operation is executed the order will be the same each time the program is executed?
A "dataspace entry" is a single piece of LV data capable of going down a wire as a coherent LV data type. There are several dataspace entries that are not represented directly on the diagram, but, in general, any of the items you can interact with on the diagram are going to have a terminal representation at some point. Some things -- like a queue -- which aren't associated with any particular VI, have storage that is not directly a terminal.[Edit: Is "terminal" the correct term to use when referring to something that can hold data? I've generally though of terminals only as controls or indicators that are on the conpane. Although constants and controls that are not on the vi conpane could be viewed as sub vis with their own conpanes...] -
Excellently done!So did Evil AQ do a decent job of explaining things to me?I think I can add that the inplaceness algorithm -- where we decide a downstream wire can reuse an upstream wire's mem address and modify that value -- is logically equivalent to each wire having a reference count on that data, and when the ref count is one, the nodes can modify the address represented because no one is sharing it. If you created a DVR directly to a by-value wire's address, the refcount would not be one -- it would be two, one for the DVR and one for the parallel by-value wire. So until that other branch was done, you couldn't modify the data. A data copy is created so that the DVR is the one and only refcount for the data. There are various improvements we can sometimes do using top-swapping instead of deep copy, but in general, the DVR needs exclusive rights to that memory address.
-
A bug? Only sort of. Yes, it's abug, yes it makes LV unstable, but, um... no, it is unlikely to befixed.Your thoughts please? :blink:Am I looking at a bug here?This is documented somewhere but I can't find it at the moment. If Iload A.lvclass in AppInstance 1, that same piece of data cannot be usedin AppInstance 2 because
- if we close AppInstance 1, the class leaves memory, which wouldleave the data in AppInstance 2 without a class definition which wouldcause LV to crash the next time you copy, delete or access that data.(in fact, this crash is what's bringing down your VI, but we'll get tothat in a moment)
- and because the A.lvclass loaded in AppInstance 1 might not bethe same as the A.lvclass loaded in AppInstance 2. One might bec:\A.lvclass and the other might be d:\A.lvclass, and they might nothave anywhere close to the same definition. Applying the assemblyinstructions to copy one an object of the first class might createcompletely corrupt objects if applied to objects of the other class.
The only correct way to shuffle object data from AppInstance 1 toAppInstance 2 is to flatten it to string and unflatten it from string.This happens automatically when the two AppInstances are on differentmachines -- the objects are flattened to go across the network. Thishappens automatically if the wire type is LVClass and not variant, evenwhen the two AppInstances are on the same computer. And it happensautomatically for variants when the two AppInstances are on the samecomputer if you wire a port number to the Open Application Instanceprimitive.
However, it does not happen automatically when you're using varianttype to transfer the class data and the contexts are on the samemachine and you didn't specify a port number for the Open App Reference. Why doesn't it happen automatically? Because LV would have to flatten and then unflatten every variant as it crossed the context boundaries on the off chance that there's a class buried somewhere inside -- in the data, in an attribute, in a cluster of array of cluster of variant's attribute, etc. When I put that code into LV, performance of many many apps went way way way down. It seems that many scripting functions, editor extensions, etc, grab data across the boundaries. That's a real problem for LV classes, but I've got no way to detect it (even just testing for the data type at runtime was too much of a performance hit).
As I said, this is documented in the shipping docs somewhere, and I know I've typed this up before.
-
1
-
- Popular Post
- Popular Post
[speaking purely as a developer myself, not speaking in any way for NI for this post.]
Oh, yeah, I've made this mistake before. Not with LV... another tool. In my case it was choosing to use Oracle (licensed to my employer) instead of MySQL (freeware tool). I left that employer and my tools were dead -- I had copies of all my databases, but no way to use them. In a case where I made the right decision, my copy of CorelDraw is mine, paid for out of my pocket, even though Iuse it frequently at work. NI probably would've bought Corel for me once I showed a need for it in my work, but all of my personal graphics projects are in Corel and I don't want to lose access to them if I everleave NI.
Essentially, bsvingen faces a rather classic problem. He used a license registered to entity A to produce software for entity B, and now without access to person A's license, he's stuck without the ability to continue working on the project for entity B.
The solution is not, IMHO, to say, "Never use the licensed tool, always use the free tool." The actual answer is, "Never start a project using tools that have licenses that differ from the owner of the project." In other words, if the project is for entity B, don't use entity A's licenses to develop it. So if this is my personal project, I need a personal license, rather than relying upon my office license, otherwise I end up one day not having access to that license.
Is a personal copy of LV cheap? Heck no. But neither is a personal copy of a lot of cool software. I'd like to say, "use LV for everything it is appropriate for." But I'd also like to get a paycheck every couple weeks, which means LV costs money, which means "use LV if you can afford to use it in all the times where it is appropriate". It'd be nice if it were down around $250, like Visual Studio, but we don't have anywhere near the volume that MS does to be able to make back our expenses at that low a price.
I don't think the licensing takes away from the *language* being a general purpose programming language -- by which I mean, if you have access to LV, you can use LV for any programming project, effectively and efficiently, to the same degree as any other programming language. Every language has its strengths and weaknesses, and LV's particular set of trade-offs are no worse than a lot of other languages. But I do agree with bsvingen that the licensing takes away from the development tool being a general purpose development tool -- by which I mean not all developers will have access to it. That's really what's at the heart of the open source/free software arguments, but while I definitely use open source stuff, and I've contributed back to a few open source projects, and I wrote a lot of shareware back in history, I don't think anyone has figured out how to pay a staff of programmers while charging nothing for the software.
-
3
-
One option: Use an edge of green and a core of something else, similar to the queue wires.I like this idea much better than using green wires. Color is one of the main ways I distinguish between groups of related classes.
-
What you are asking for is not possible, at all, in a dataflow language. A raw pointer to data on a parallel by-value wire cannot be constructed meaningfully. Ever. That would completely destabilize LabVIEW's parallel architecture. The whole point of a data flow wire is that *nothing* other than the upstream primitive that created the value can modify that value. Nothing. If you have raw pointer access to the data on a parallel branch, you will almost always create wholly unpredictable behavior or a crash, with the crash being highly likely.
We fully support references. We do not support pointers at all. But you don't refer to a piece of the block diagram. You refer to an address in memory. That other, parallel wire, does not refer to that piece of memory. It refers to its own piece of memory.Labview is kind of in a middle ground where it doesn't quite follow the pure "everything is data" idea but also doesn't fully support references, leaving it difficult to work with either.-
2
-
-
It's definitely not something I would force ever. It's just a recommendation that a couple folks think should be followed. I've had multiple situations where the mixture was useful, and haven't seen any negatives yet, myself.I really like to be able to have both byRef and byValue within the same class.That way I can have a number of high speed access members, and still beable to use ByRef on data that need it. So please don't force peopleinto selecting one type or the other.
-
Jim Kring wrote:
1) You can't tell just by looking an an object that it's by reference(as you can when you see a DVR with an LVOOP object inside)Strong recommendation we've developed over the last few years: If your object contains even a single refnum, make the wire color be refnum green. I even updated the color picker in LabVIEW 2009 so that refnum green is one of the default colors displayed so it is easy to grab it for your wire designs (it's the last non-gray square in the row of pre-selected colors).
Also, I've had a few people suggest that if one member of your private data control is a refnum then all of them should be refnums, so that everything in the object behaves like a reference. I'm not sure what I think of that, but I'll throw it out there for consideration.
Unfortunately, the bookkeeping on this is significantly problematic. Essentially, you'd need the inside of the IPE to output an array of refnums that are "the refnums I currently have deref'd" and then pass that by dataflow to any nested (including inside subVIs) IPEs. But the subVIs don't have magic secret inputs/outputs that would allow this information to pass along, and trying to do it in a "global store that each IPE checks to see if refnum was used upstream" requires the IPE to know aspects of dataflow that are simply unknowable, such as what nodes are upstream of it. We did kick around embedding the information in the refnum wire itself, but with a reference, there's no guarantee that the reference is used in only one place.With this in mind, one feature that I'd love to see in LabVIEW is for IPE structures to be smart at run-time and output an error (rather than deadlock) if an IPE is called inside another IPE and tries to dereference data that has already been dereferenced by the outer IPE.In the end, we couldn't find a way for the IPE to tell the difference between a refnum that was dereferenced upstream (and should error) and dereferenced in parallel (that will eventually be released), except in the most trivial of cases. If you're writing circular reference code, you'll need to carry along with the refnum a parallel array of refnums already opened, and at every IPE, manually check whether the chosen refnum is already referenced.
-
1
-
-
I honestly believe there is no good solution. You have to choose the option that is least bad for your particular development team. For me, branches are the worst option, but I can easily understand someone believing single-trunk development being the worst.Unfortunately the other patterns have issues of their own.Perhaps all software teams should just have an uber secretary who keeps track of everything and let that person tell you what you can develop today.
-
The Equals primitive compares values and returns true if the values are equal. All of the comparison primitives (=, !=, <, >, >=, <=, and Sort 1D Array) compare based on the value of the private data cluster. Online help includes details on how comparison works when the underlying clusters aren't the same.NI - Isn't there a way to compare the data types as equal "values"?If you're wanting to say "is this object of this particular type", then you use the Two More Specific primitive. If you're wanting to say "are these two objects the same type", use the Preserve Run-Time Class primitive (new in LV 2009).
"Get LV Class Path.vi" can also give you the exact class info.
Very few of these should ever be needed in your code. "Using the full power of OO" means never* doing type testing -- that road leads straight back into the world of enums and case structures.
* 'never' of course is relatively never, since we wouldn't have the prims if it was truly never.
-
When you're working in the same branch as your fellow developers, VIs and .lvclass files should be locked when you check them out. Ideally, you should get a warning when you try to check out a file that says "this file is already checked out. Any changes you make may not be able to check in. Are you sure you want to check the file out?"
When you're working on different branches, I don't have any answers for you other than coordinate with your fellow developers. It's a largely unsolvable problem.
Multiple branches can quickly break down in pure text languages too. True, changes can *often* be integrated together, but often they can't. LabVIEW has every function as a separate file, which is nice -- its surprisingly rare for multiple developers to need the same function simultaneously.this pattern works fine with 100+ developers with text languages...ah well not point in wishing it will go away.The private data control of LV classes are a nasty bottleneck. As rare as it is to need to change the same function, two developers needing to add data to a class is more common. I don't really have a solution for this. The closest you can come is to check out the class, add a placeholder typedef and quickly check the class back in. Then in your own code, update the typedef to the data you actually need. This assumes you're not flattening the class to disk and trying to store data of this class type.
-
1
-
-
It is a philosophy question, and I doubt there is a right answer.
"Favor composition over inheritance" is a battle cry I have heard a lot over the last few years. Composition means I can "plug in" functionality from lots of sources. The trouble, as I see it, is that you end up writing a lot of wrapper functions in order than the outer object can expose the inner objects' APIs as its own. Now, the theory is that the inner object's API can change completely and as long as the new API can still support the old functionality, the outer API doesn't have to change -- you change the implementation of those wrappers, not the outer API. But what I observe is that it is rare to want to change the inner API and not change the outer one. Perhaps you're adding a new option, or you're breaking one atomic function into several individual parts. There's usually a reason you're doing that, and it is rare -- in my experience -- that the reason you're doing it is just so you can have a better internal API. Changes to deeper layer APIs are almost always driven by top-level demands for features. Or, to put it another way, it is rare that the core decides, "I'm going to change how I do things because it will be better." It is much more common for the outermost layer to say, "I need to serve the user differently... but I can't do that unless the core exposes some new functionality."
Given that the desire for a new API is almost always driven by the layer closest to the user, when the core changes, the outer layer will want to change anyway, so if there's a tight binding (inheritance) between core and outer layer, so what? Not having that binding doesn't generally seem to save you. Sure you *could* avoid rewriting the outer layer when the core changes, but if the whole point of changing the core is so you *can* rewrite the outer, then you're going to rewrite the outer.
Yes, I spend a lot of time changing inheritance trees around -- introducing new middle layer classes, wiping them out again a couple revisions later. I've got one tree of classes I'm working on at the moment where each layer of inheritance is adding one function, and one "concrete" class forking off of the trunk at each level. As I revise each of the concrete classes, they're sliding down the tree, gaining functionality, and I'll probably collapse a lot of the middle layers eventually. I find that the chain of inheritance is useful for navigating my code and I don't see a major drawback to refactoring the tree. Very few classes are persisted to disk, so that's rarely an issue, and in LV, the mutation logic built into the language generally handles everything I need it to.
-
1
-
Interfaces
in Object-Oriented Programming
Posted
Which brings me to another thought I've been having about interfaces... the possibility that an interface could declare a private method and expose a public method that uses that private method as part of an algorithm. There are cases where I, as the person implementing the interface, need to write some function that the class must expose in order to plug into some algorithm, but the function itself is one that should never be called except by the algorithm.
I know... I'm questioning all sorts of basic assumptions about "what constitutes an interface." But that's my job as a language designer. Just because it works like XYZ in C# or Java doesn't mean that it is how it should be implemented, either in languages in general or in LV specifically.
This is a topic on which I'll be playing for a long while yet.