

Aristos Queue
-
Posts
3,183 -
Joined
-
Last visited
-
Days Won
204
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Aristos Queue
-
-
The equals operation is a *value* comparison, not a reference comparision. All of the fields of the object must match exactly for equals to return true. We do not have any concept of a reference of the object.
-
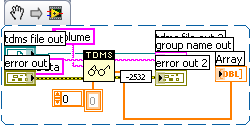
I converted a VI from LV8.6 to LV2009. There is a ClearError VI inserted in the error wire (see attached). Why did it do that?
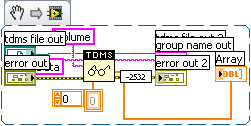
No my code isn't this ugly. I used the new create snippet to create the png file and it uglied it up a bit.
George
- Ourcode conventions say that when we insert something like that on yourdiagram, you should see a load warning when you load the VI explainingthe change. Did you get such a warning? If not, please file a CAR.
- Generallythis would be done for any node that used to silently fail some caseand in the new version it returns an error code for that case. Existingcode may have been written to assume the silent failure. To preserveprevious version functionality, we insert a function to conditionallyclear the new error code.
- Inserting a full "Clear Errors.vi"that wipes out all error information would be strange... The only caseI can imagine that applying to is if in the previous version the nodeutterly failed to propagate error in to error out and we have fixedthat, but, again, to preserve previous functionality, we clear allerrors downstream. But that's just a guess. [LATER] Looking closer atyour posted picture, that is just a conditional clearing of the errorcode, so I'll bet #2 applies.
-
My work machine is a PC. My home machines & laptop are all Mac. My C++ development is always done under Windows where I have access to that wonderful tool MS Visual Studio. I haven't ever found anything for text programming that comes close to the usability of MSVS. On the other hand, most of my G development these days is done on my laptop where I can use my touchpad, which I find much nicer than a mouse for LV programming (easier to move back and forth from keyboard to mouse as needed).Just out of interest to you program for NI on a Mac?-
 1
1
-
-
Why choose? You could decide to study scripting LVOOP!

-
2
-
-
I seriously doubt it. The percent of LV in LV has gone up substantially with every release since 8.0. The problem is not how much of LV is written in LV, nor even how many VIs can you look at to see how something is done. The question is how many of those VIs can you use in your own code AND expect support for those VIs in the next version of LV. If every VI that ships with LV is one that we have to maintain indefinitely, we'll rapidly stagnate.It used to be a great boon that most of labview was written in labview. There were lots of sub vi's installed that found uses outside the original premise. Pretty soon we'll have one vi (call library function) and everything will be a dll call.
We're not talking about password protecting the diagrams or anything. We're talking about making it so that you have to create your own copy of the VIs in order to use them.
-
To the best of my knowledge, ShaunR is correct. The shared variables do not provide synchronization behaviors. On a local machine they are equivalent to global VIs. Over the network, they are a broadcast mechanism, which, by polling, you can use as a trigger, but I don't think you have any way to sleep until message received.I don't believe they intrinsically suspend execution until an update is received. They also have huge caveates (e.g cannot be dynamically created at run-time). Its a bit of a sledgehammer to crack a nut IMHO.
-
I've started a thread in the Developer Feedback forum on ni.com. If you have feedback on this particular aspect of design for items in vi.lib, please post your comments there.
http://forums.ni.com/ni/board/message?board.id=features&thread.id=429
-
It's a question of reallocation on every call vs leaving the allocation in place to maximize performance. If the data can occassionally ramp up to "large number X", and you have enough ram, then it's a good idea to just leave large block always allocated for that large data event, no matter how rare it is. The larger the desired block, the longer it takes to allocate -- memory may have to be compacted to get a block big enough. Also, keep in mind that we're talking about the space for the top-level data, not the data itself. So if you enqueue three 1 megabyte arrays, and then you flush the queue, the queue is just keeping allocated the 12 bytes needed to store the array handles, not the arrays themselves.Yes, you're right, memory leak isn't the right term for it. If had had problems, I wouldn't have known it. But sometimes it has to acquire a lot of data, sometimes less. So the amount of memory that's been allocated is governed by the largest data set acquired. Not really a big deal, just doesn't sit well with me. -
Glad to hear it worked out.
-
1
-
-
- Popular Post
- Popular Post
So the background compiler generates machine code on the fly in a single step and stores it in memory? Or does it compile down to function calls for the runtime engine to translate into os specific commands?When you write a C++ program, you write it in some editor (MSVC++, XCode, emacs, Notepad, Textedit, etc). Then you compile it. If you're tools are really disjoint, you use gcc to compile directly on the command line. If you have an Integrated Development Environment (XCode, MSVC++), you hit a key to explicitly compile. Now, in MSVC++, you can hit F7 to compile and then hit F5 to run. OR you can hit F5 to run, in which case MSVC++ will compile first and then, if the compile is successful, it will run. All of this is apparent to the programmer because the compilation takes a lot of time.
There's a bit of hand-waving in the following, but I've tried to be accurate... The compilation process can be broken down as
- Parsing (analyzing the text of each .cpp file to create a tree of commands from the flat string)
- Compiling (translation of each parse tree into assembly instructions and saving that as a .o file)
- Linking (taking the assembly instructions from several individual .o files and combining them into a single .exe file, with jump instructions patched with addresses for the various subroutine calls)
- Optimizing (looking over the entire .exe file and removing parts that were duplicate among the various .o files, among many many many more optimizations)
LabVIEW is a compiled language, but our programmers never sit and wait 30 minutes between fixing their last wire and seeing their code run. Why do you not see this time sink in LabVIEW?
- Parsing time = 0. LabVIEW has no text to parse. The tree of graphics is our initial command tree. We keep this tree up to date whenever you modify any aspect of the block diagram. We have to... otherwise you wouldn't have an error list window that was continuously updated... like C++, you'd only get error feedback when you actually tried to run. C# and MSVC# does much the same "always parsed" work that LV does. But they still pay a big parse penalty at load time.
- Compile time = same as C++, but this is a really fast step in any language, believe it or not. LabVIEW translates the initial command tree into a more optimized tree, iteratively, applying different transforms, until we arrive at assembly instructions.
- Linking time = not sure how ours compares to C++.
- Optimizing time = 0 in the development environment. We compile each VI to stand on its own, to be called by any caller VI. We don't optimize across the entire VI Hierarchy in the dev environment. Big optimizations are only done when you build an EXE, because that's when we know the finite set of conditions under which your VIs will be called.
-
3
-
Unfortunately, you can't time an animated gif well enough. The animations have too loose a time slice to be reliable, and anytime the UI thread gets tied up, they can hang. Further you have no ability to reset it in LabVIEW -- whenever you launched the VI, that would be the time displayed.Animated "Gif" image. -
Option 1: Create a queue, a notifier and a rendezvous. Sender Loop enqueues into the queue. All the receiver loops wait at the rendezvous. Receiver Loop Alpha is special. It dequeues from the queue and sends to the notifier. All the rest of the Receiver Loops wait on the notifier. Every receiver loop does its thing and then goes back around to waiting on the rendezvous.
Option 2: Create N + 1 queues, where N is the number of receivers you want. Sender enqueues into Queue Alpha. Receiver Loop Alpha dequeues from Queue Alpha and then enqueues into ALL of the other queues. The other receiver loops dequeue from their respective queues.
Option 1 gives you synchronous processing of the messages (all receivers finish with the first message before any receiver starts on the second message). Option 2 gives you asynchronous processing (every loop gets through its messages as fast as it can without regard to how far the other loops have gotten in their list of messages).
-
2
-
-
That's just plain old compiling. And that's what we call it. :-) The fact that you as user don't have to explicitly invoke it is a service on our part, but the compilation happens before you run, which is exactly when it happens in every other compiled programming language.I was using 'JIT' to refer to the background compiling that happens in the Labview dev environment. What do you call that process? Precompiling? A level 1 compiler? On large projects I've seen a several second delay between hitting the run button and having the application actually start, so I don't think it compiles directly to machine code. -
- Popular Post
- Popular Post
Daklu, the style of my writing below is fairly terse and occassionally EMPHATIC. I've done this to emphasize key points that I think you've missed in How Things Work. Some customers in the past have felt I'm insulting them writing this way, but it is the only way I know through the limited text medium to highlight the key points. My only other option is to post just the key bits and leave out a lot of the exposition, but that doesn't seem to be as helpful when communicating. So, please, don't think I'm calling you dumb or being disdainful. I'm trying to teach. The problem is that you're almost right. Customers who are completely off-base are easier to teach because they need the whole lesson. Here, I'm just trying to call out key points, but presenting them in their full context to make sure it's clear what fits where. Throughout the post, refer to the graphic at the end of the post as it may clarify what I'm talking about.
Dalku wrote:
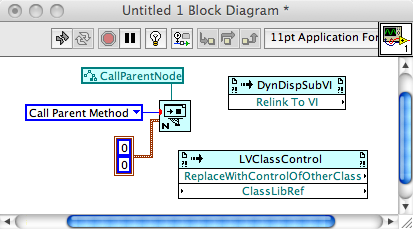
Is there a "right way" (or any way for that matter) to call child class methods on a parent object that was stuffed into a DVR?No. If there is, that's a bug that needs to be reported to NI ASAP.
Think about what you just asked for... ignore the DVR part for a moment. You just asked for a PARENT object to invoke a CHILD class method. That cannot ever happen. You cannot pass a parent object directly to a function that takes a child object. The parent object in question IS NOT a child -- the parent object does not have the child's private data, nor does it have all the methods that may have been defined on the child class. For this reason, LV will break the wire if you try to wire a parent wire to a child terminal -- the wire is broken because there are zero situations in which this can successfully execute.
You CAN pass a child object to a parent terminal. That is because a child IS an instance of the parent -- it has all the necessary data and methods defined to act as a parent object.
What you can do is take a child wire, up cast it to a parent wire and make a Parent DVR out of that. Alternatively, you could take a child wire, make a Child DVR wire, and then upcast that to a Parent DVR wire... these two processes produce the idenitical result: a parent DVR that contains child data.
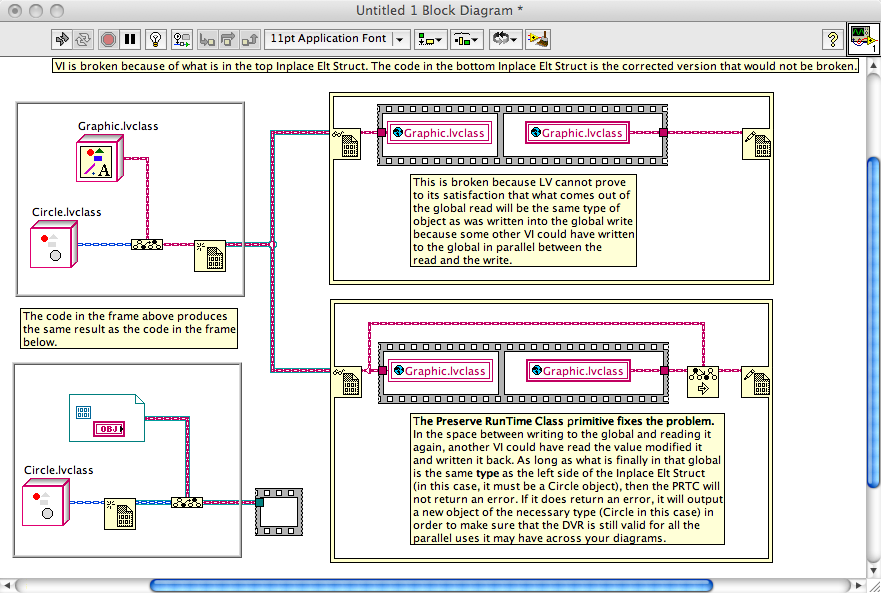
Upcast and downcast DO NOT create new objects EXCEPT when they return an error. The point of a cast is to say, "I have an existing object. Please check that it is this type and approve it to go downstream if it passes this test." You use this only when you need to do something for a specific type of object and you do not have the ability to edit the parent and child classes in order to add the appropriate dynamic dispatch VIs to both.If you create an object reference to a parent object, afterdereferencing the parent object there does not appear to be any way todowncast it to a child object or use dynamic dispatching to call childclass methods. I built a simple example project with a parent class anda child class to illustrate this.Preserve Run-time Class (PRTC) is the same thing. "Allow this object to pass downstream if it passes this test, otherwise create a new object that does pass the test." The test in this case is "Does the object in have the same TYPE AT RUN TIME as the OBJECT (not the wire) on the target object input?" If the left object is the same or a child class of the center object then there is no error. You will ALMOST NEVER WIRE PRTC WITH A CONSTANT FOR THE CENTER TERMINAL. I would say "never" because I can't think of any useful cases, but maybe someone has something out there. If you are wiring the center terminal of PRTC with a constant, something is wrong in your code. You use the PRTC to assert that the left object, which comes from some mystical source, is the right type to fulfill run-time type requirements of dynamic dispatch VIs, automatic downcast static VIs, and the Lock/Unlock of Data Value References. In all three of these cases, there is some input (either the input FPTerm or the left side of the Inplace Elt Struct) that must be passed across to the output (either the output FPTerm or the right side of the Inplace Elt Struct) WITHOUT PASSING THROUGH ANY FUNCTION THAT CHANGES THE OBJECT'S TYPE. You're free to change the object's value, but not its type. Sometimes you pass the object to functions where LV cannot prove that the type is maintained. Easy example -- pass the object into a Global VI and then read the Global VI. You'd never do this, of course, but it demonstrates the problem. LV cannot know that the object you read from the global is the same object you wrote in -- some other VI elsewhere might have written to the global in parallel. But you, as the programmer, know that there are no other writes to the global VI, so you use the PRTC to assert "this is going to be the right object type." You wire the original input (as described above) to the center terminal, and the output of the global to the left terminal, and pass the result to the original output terminal (as described above).
Does that make sense?
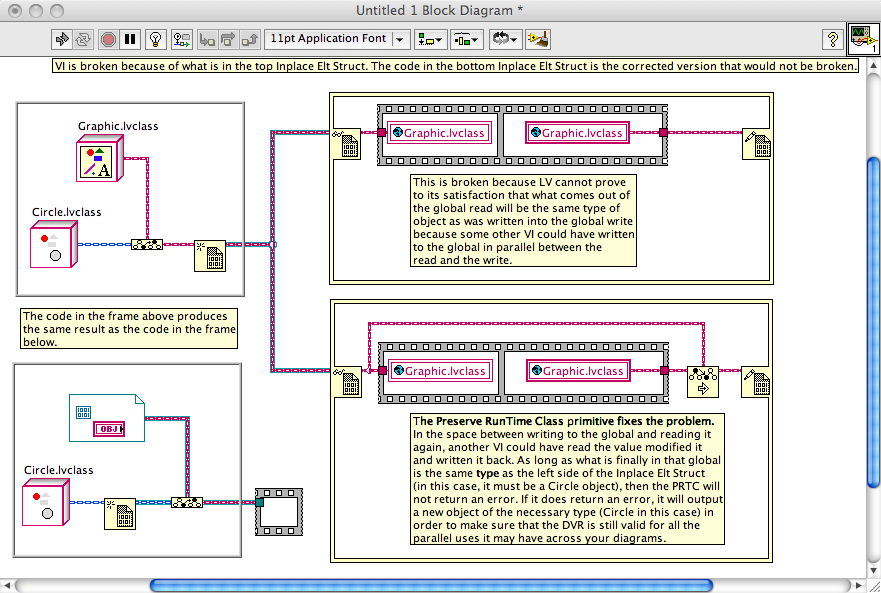
-
9
-
Good news! LV 2009 fixes the issue. LVClasses can now build all their files into the executable.Exactly! What a nightmare! :headbang: I just spent three hours on this trying to stuf everything into one executable.
-
The Source Distribution is the most reliable option, definitely the one that NI designed to solve this problem.Another option is to use the Source Distribution under the Build Specification in the project. This requires the Application Builder.
-
Can you post an image of a couple of these sequences you're proposing? It would help to see in order to suggest data passing mechanisms.
-
Talk to Mikael... putting the DVR inside the class sounds an awful lot like the GOOP Toolkit implementation where they wrap a raw reference to data in a class to give it dispatching behaviors. Mikael may have some info about the deadlock potential of this situation.Hey Jim
That's a good point that I haven't explored deeply. My first thought is that class Bike has its own DVR to it's datamembers and the child Racer has its own so they are separate and shouldn't interfere with each other. I'll do some tests and see what is involved in breaking it or causing it to lock.
-
> Dropping a Variant Collection object on a VI creates a Variant
> Collection with a CollectionImp object instead of one of the
> childclass objects.
Go to Variant Collection.lvclass:Variant Collection.ctl. Change the default value (not the type, just the value) of the CollectionImp control to be an instance of one of the concrete types -- HashTable, for example. Now whenever you drop VariantCollection.lvclass, you get one that has a hashtable unless/until you change it to something else.
-
1
-
-
There are no plans to add this in a future version. It was explicitly rejected as a possible feature during brainstorming... I posted about this in the beta forums, and I *think* I updated the Decisions Behind The Design to talk about this. (If I didn't, remind me to update it soon.)One issue to resolve with this method is dynamic dispatching. It seems that you can't do dynamic dispatching using Data Value reference terminals. Hopefully this will be added in a future LabVIEW release. In the meantime you will probably have to do dynamic dispatching inside the In Place Element Structure. -
Replies to this topic should be made in the Idea Exchange where this was cross-posted. That way the evaluation of the idea can all be in one location.
-
The following was written on my whiteboard at my desk for most of the time we were developing LVOOP:
El Voop == Spanish for strength!
Le Voop == French for style!
Al Voop == Arabic for quality!
LVOOP == LabVIEW for class!
And for the record, we didn't have any way of pronouncing "LVOOP-DVR" during development because DVRs are not specific to objects.
-
Please post all further comments on the forum for the idea itself... that way this conversation stays all in one place.
-
Here's another suggestion:
Create a new state called "Update Indicators". Put all the indicator FPTerms in that state. Now instead of displaying the values in the state that generates the value, you wait to get to the Update Indicators state to update the indicators. Of course, this would require one of two things. Either:
A) a queued state machine so that you could queue up the Update Indicators state followed by the next state that you really wanted to go to, o
B) you make the next state to transition to another value in a shift register that the Update Indicators state can use.
Can't downcast a dereferenced object?
in Object-Oriented Programming
Posted