Hi Everyone,
I (re)watched James Powell's talk at GDevCon#2 about Application Design Around SQLite. I really like this idea as I have an application with lots of data (from serial devices and software configuration) that's all needed in several areas of the application (and external applications) and his talk was a 'light-bulb' moment where I thought I could have a centralized SQLite database that all the modules could access to select / update data.
He said the database could be the 'model' in the model-view-controller design pattern because the database is very fast. So you can collect data in one actor and publish it directly to the DB, and have another actor read the data directly from the DB, with a benefit of having another application being able to view the data.
Link to James' talk: https://www.youtube.com/watch?v=i4_l-UuWtPY&t=1241s)
I created a basic proof of concept which launches N-processes to generate-data (publish to database) and others to act as a UI (read data from database and update configuration settings in the DB (like set-point)). However after launching a couple of processes I ran into 'Database is locked (error 5) ', and I realized 2 things, SQLite databases aren't magically able to have n-concurrent readers/writers , and I'm not using them right...(I hope).
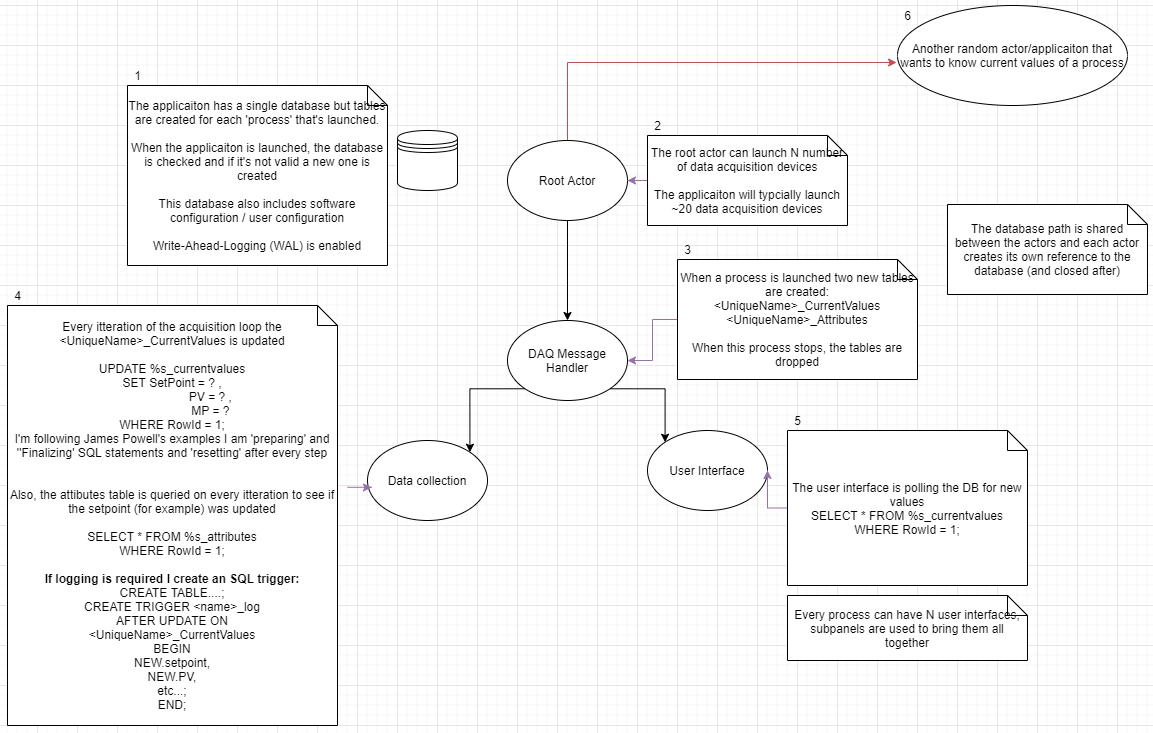
I've created a schematic (attached) to show what I did in the PoC (that was getting 'Database is locked (error 5)' errors).
I'm a solo-developer (and SQLite first-timer*) and would really appreciate it if someone could look over the schematic and give me guidance on how it should be done. There's a lot more to the actual application, but I think once I understand the limitations of the DB I'll be able to work with it.
*I've done SQL training courses.
In the actual application, the UI and business logic are on two completely separate branches (I only connected them to a single actor for the PoC)
Some general questions / thoughts I had:
Is the SQLite based application design something worth perusing / is it a sensible design choice?
Instead of creating lots of tables (when I launch the actors) should I instead make separate databases? - to reduce the number of requests per DB? (I shouldn't think so... but worth asking)
When generating data, I'm using UPDATE to change a single row in a table (current value), I'm then reading that single row in other areas of code. (Then if logging is needed, I create a trigger to copy the data to a separate table)
Would it be better if I INSERT data and have the other modules read the max RowId for the current value and periodically delete rows?
The more clones I had, the slower the UI seemed to update (should have been 10 times/second, but reduced to updating every 3 seconds). I was under the impression that you can do thousands of transactions per second, so I think I'm querying the DB inefficiently.
The two main reasons why I like the database approach are:
External applications will need to 'tap-into' the data, if they could get to it via an SQL query - that would be ideal.
Data-logging is a big part of the application.
Any advice you can give would be much appreciated.
Cheers,
Tom
(I'm using quite a few reuse libraries so I can't easily share the code, however, if it would be beneficial, I could re-work the PoC to just use 'Core-LabVIEW' and James Powell's SQLite API)


")