Search the Community
Showing results for tags 'architecture'.
Found 9 results
-
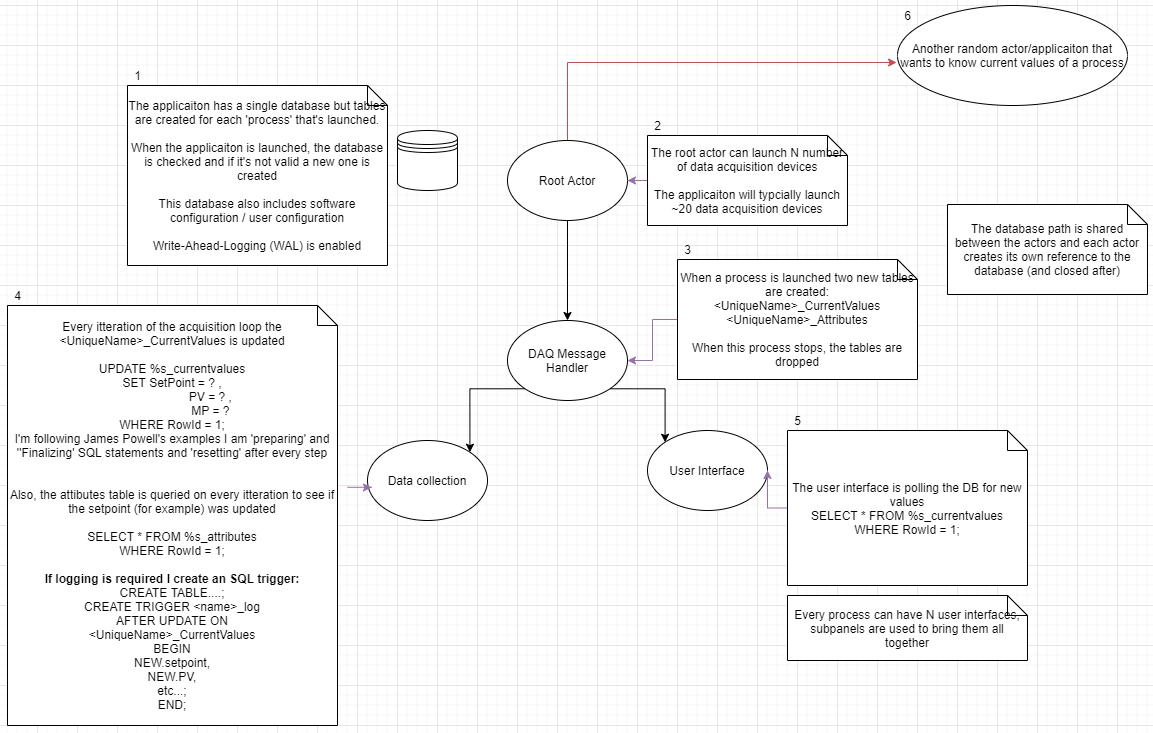
Hi Everyone, I (re)watched James Powell's talk at GDevCon#2 about Application Design Around SQLite. I really like this idea as I have an application with lots of data (from serial devices and software configuration) that's all needed in several areas of the application (and external applications) and his talk was a 'light-bulb' moment where I thought I could have a centralized SQLite database that all the modules could access to select / update data. He said the database could be the 'model' in the model-view-controller design pattern because the database is very fast. So you can collect data in one actor and publish it directly to the DB, and have another actor read the data directly from the DB, with a benefit of having another application being able to view the data. Link to James' talk: https://www.youtube.com/watch?v=i4_l-UuWtPY&t=1241s) I created a basic proof of concept which launches N-processes to generate-data (publish to database) and others to act as a UI (read data from database and update configuration settings in the DB (like set-point)). However after launching a couple of processes I ran into 'Database is locked (error 5) ', and I realized 2 things, SQLite databases aren't magically able to have n-concurrent readers/writers , and I'm not using them right...(I hope). I've created a schematic (attached) to show what I did in the PoC (that was getting 'Database is locked (error 5)' errors). I'm a solo-developer (and SQLite first-timer*) and would really appreciate it if someone could look over the schematic and give me guidance on how it should be done. There's a lot more to the actual application, but I think once I understand the limitations of the DB I'll be able to work with it. *I've done SQL training courses. In the actual application, the UI and business logic are on two completely separate branches (I only connected them to a single actor for the PoC) Some general questions / thoughts I had: Is the SQLite based application design something worth perusing / is it a sensible design choice? Instead of creating lots of tables (when I launch the actors) should I instead make separate databases? - to reduce the number of requests per DB? (I shouldn't think so... but worth asking) When generating data, I'm using UPDATE to change a single row in a table (current value), I'm then reading that single row in other areas of code. (Then if logging is needed, I create a trigger to copy the data to a separate table) Would it be better if I INSERT data and have the other modules read the max RowId for the current value and periodically delete rows? The more clones I had, the slower the UI seemed to update (should have been 10 times/second, but reduced to updating every 3 seconds). I was under the impression that you can do thousands of transactions per second, so I think I'm querying the DB inefficiently. The two main reasons why I like the database approach are: External applications will need to 'tap-into' the data, if they could get to it via an SQL query - that would be ideal. Data-logging is a big part of the application. Any advice you can give would be much appreciated. Cheers, Tom (I'm using quite a few reuse libraries so I can't easily share the code, however, if it would be beneficial, I could re-work the PoC to just use 'Core-LabVIEW' and James Powell's SQLite API)

-
 Hi all, I have a question about high level system design with FPGA-RT-PC. It would be great if I can get some advice about ideal approaches to move data between the 3 components in an efficient manner. There are several steps; DMA FIFO from FPGA to RT, processing the data stream in the RT to derive chunks of useful information, parsing these chunks into complete sets on the RT and sending these sets up to the Host. In my system, I have the FPGA monitoring a channel of a digitiser and deriving several data streams from events that occur (wave, filtered data, parameters etc). When an event occurs the data streams are sent to the RT through a DMA FIFO in U64 chunks. Importantly, events can be variable length. To overcome this, I reunite the data by inserting unique identifiers and special characters (sets of 0's) into the data streams which I later search for on the RT. Because the FPGA is so fast, I might fill the DMA FIFO buffer rapidly, so I want to poll the FIFO frequently and deterministically. I use a timed loop on the RT to poll the FIFO and dump the data as U64's straight into a FIFO on the RT. The RT FIFO is much larger than the DMA FIFO, so I don't need to poll it as regularly before it fills. The RT FIFO is polled and parsed by parallel loop on the RT that empties the RT FIFO and dumps into a variable sized array. The parsing of the array then happens by looking for special characters element wise. A list of special character indices is then passed to a loop which chops out the relevant chunk and, using the UID therein, writes them to a TDMS file. Another parallel loop then looks at the TDMS group names and when an event has an item relating to each of the data streams (i.e. all the data for the event has been received), a cluster is made for the event and it is sent to the host over a network stream. This UID is then marked as completed. The aim of the system is to be fast enough that I do not fill any data buffers. This means I need to carefully avoid bottle necks. But I worry that the parsing step, with a dynamically assigned memory operation on a potentially large memory object, an element wise search and delete operation (another dynamic memory operation) may become slow. But I can't think of a better way to arrange my system or handle the data. Does anyone have any ideas? PS I would really like to send the data streams to the RT in a unified manner straight from the RT, by creating a custom data typed DMA FIFO. But this is not possible for DMA FIFOs, even though it is for target-scoped FIFOs! Many thanks, Max
Hi all, I have a question about high level system design with FPGA-RT-PC. It would be great if I can get some advice about ideal approaches to move data between the 3 components in an efficient manner. There are several steps; DMA FIFO from FPGA to RT, processing the data stream in the RT to derive chunks of useful information, parsing these chunks into complete sets on the RT and sending these sets up to the Host. In my system, I have the FPGA monitoring a channel of a digitiser and deriving several data streams from events that occur (wave, filtered data, parameters etc). When an event occurs the data streams are sent to the RT through a DMA FIFO in U64 chunks. Importantly, events can be variable length. To overcome this, I reunite the data by inserting unique identifiers and special characters (sets of 0's) into the data streams which I later search for on the RT. Because the FPGA is so fast, I might fill the DMA FIFO buffer rapidly, so I want to poll the FIFO frequently and deterministically. I use a timed loop on the RT to poll the FIFO and dump the data as U64's straight into a FIFO on the RT. The RT FIFO is much larger than the DMA FIFO, so I don't need to poll it as regularly before it fills. The RT FIFO is polled and parsed by parallel loop on the RT that empties the RT FIFO and dumps into a variable sized array. The parsing of the array then happens by looking for special characters element wise. A list of special character indices is then passed to a loop which chops out the relevant chunk and, using the UID therein, writes them to a TDMS file. Another parallel loop then looks at the TDMS group names and when an event has an item relating to each of the data streams (i.e. all the data for the event has been received), a cluster is made for the event and it is sent to the host over a network stream. This UID is then marked as completed. The aim of the system is to be fast enough that I do not fill any data buffers. This means I need to carefully avoid bottle necks. But I worry that the parsing step, with a dynamically assigned memory operation on a potentially large memory object, an element wise search and delete operation (another dynamic memory operation) may become slow. But I can't think of a better way to arrange my system or handle the data. Does anyone have any ideas? PS I would really like to send the data streams to the RT in a unified manner straight from the RT, by creating a custom data typed DMA FIFO. But this is not possible for DMA FIFOs, even though it is for target-scoped FIFOs! Many thanks, Max -
Hi everybody, Currently working on VeriStand custom devices, I'm facing a 'huge' problem when debugging the code I make for the Linux RT Target. The console is not availbale on such targets, and I do not want to fall back to the serial port and Hyperterminal-like programs (damn we are in the 21st century !! )... Several years ago (2014 if I remember well) I posted an request on the Idea Exchange forum on NI's website to get back the console on Linux targets. NI agreed with the idea and it is 'in development' since then. Seems to be so hard to do that it takes years to have this simple feature back to life. On my side I developped a web-based console : HTML page displaying strings received through a WebSocket link. Pretty easy and fast, but the integration effort (start server, close server, handle push requests, ...)must be done for each single code I create for such targets. Do you have any good tricks to debug your code running on a Linux target ?
-
 Hello again LAVAG, I'm currently feeling the pain of propagating changes to multiple, slightly different configuration files, and am searching for a way to make things a bit more palatable. To give some background, my application is configuration driven in that it exists to control a machine which has many subsystems, each of which can be configured in different ways to produce different results. Some of these subsystems include: DAQ, Actuator Control, Safety Limit Monitoring, CAN communication, and Calculation/Calibration. The current configuration scheme is that I have one main configuration file, and several sub-system configuration files. The main file is essentially an array of classes flattened to binary, while the sub-system files are human readable (INI) files that can be loaded/saved from the main file editor UI. It is important to note that this scheme is not dynamic; or to put it another way, the main file does not update automatically from the sub-files, so any changes to sub-files must be manually reloaded in the main file editor UI. The problem in this comes from the fact that we periodically update calibration values in one sub-config file, and we maintain safety limits for each DUT (device under test) in another sub-file. This means that we have many configurations, all of which must me updated when a calibration changes. I am currently brainstorming ways to ease this burden, while making sure that the latest calibration values get propagated to each configuration, and was hoping that someone on LAVAG had experience with this type of calibration management. My current idea has several steps: Rework the main configuration file to be human readable. Store file paths to sub-files in the main file instead of storing the sub-file data. Load the sub-file data when the main file is loaded. Develop a set of default sub-files which contain basic configurations and calibration data. Set up the main file loading routine to pull from the default sub-files unless a unique sub-file is not specified. Store only the parameters that differ from the default values in the unique subfile. Load the default values first, then overwrite only the unique values. This would work similarly to the way that LabVIEW.ini works. If you do not specify a key, LabVIEW uses its internal default. This has two advantages: Allows calibration and other base configuration changes to easily propagate through to other configs. Allows the user to quickly identify configuration differences. Steps 4 and 5 are really the crux of making life easier, since they allow global changes to all configurations. One thing to note here is that these configurations are stored in an SVN repository to allow versioning and recovery if something breaks. So my questions to LAVAG are: Has anyone ever encountered a need to propagate configuration changes like this? How did you handle it? Does the proposal above seem feasible? What gotchas have I missed that will make my life miserable in the future? Thanks in advance everyone! Drew
Hello again LAVAG, I'm currently feeling the pain of propagating changes to multiple, slightly different configuration files, and am searching for a way to make things a bit more palatable. To give some background, my application is configuration driven in that it exists to control a machine which has many subsystems, each of which can be configured in different ways to produce different results. Some of these subsystems include: DAQ, Actuator Control, Safety Limit Monitoring, CAN communication, and Calculation/Calibration. The current configuration scheme is that I have one main configuration file, and several sub-system configuration files. The main file is essentially an array of classes flattened to binary, while the sub-system files are human readable (INI) files that can be loaded/saved from the main file editor UI. It is important to note that this scheme is not dynamic; or to put it another way, the main file does not update automatically from the sub-files, so any changes to sub-files must be manually reloaded in the main file editor UI. The problem in this comes from the fact that we periodically update calibration values in one sub-config file, and we maintain safety limits for each DUT (device under test) in another sub-file. This means that we have many configurations, all of which must me updated when a calibration changes. I am currently brainstorming ways to ease this burden, while making sure that the latest calibration values get propagated to each configuration, and was hoping that someone on LAVAG had experience with this type of calibration management. My current idea has several steps: Rework the main configuration file to be human readable. Store file paths to sub-files in the main file instead of storing the sub-file data. Load the sub-file data when the main file is loaded. Develop a set of default sub-files which contain basic configurations and calibration data. Set up the main file loading routine to pull from the default sub-files unless a unique sub-file is not specified. Store only the parameters that differ from the default values in the unique subfile. Load the default values first, then overwrite only the unique values. This would work similarly to the way that LabVIEW.ini works. If you do not specify a key, LabVIEW uses its internal default. This has two advantages: Allows calibration and other base configuration changes to easily propagate through to other configs. Allows the user to quickly identify configuration differences. Steps 4 and 5 are really the crux of making life easier, since they allow global changes to all configurations. One thing to note here is that these configurations are stored in an SVN repository to allow versioning and recovery if something breaks. So my questions to LAVAG are: Has anyone ever encountered a need to propagate configuration changes like this? How did you handle it? Does the proposal above seem feasible? What gotchas have I missed that will make my life miserable in the future? Thanks in advance everyone! Drew -
Hello Everyone, I need litter suggestion about object oriented with Producer Consumer design pattern. I have One MAIN program and Other 7 module that controlled (mean sending message or command by queue to module) by MAIN program and it has producer consumer design pattern.Now i want to convert this application into OOP but my doubt is if I will convert in OOP then each case in consumer loop is become a class(Command pattern).In such case I have more than 100-200 class in entire application. is it good idea to have such big amount of class in application? or i misunderstand something? looking forward to your suggestion.thanks
-
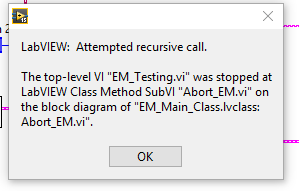
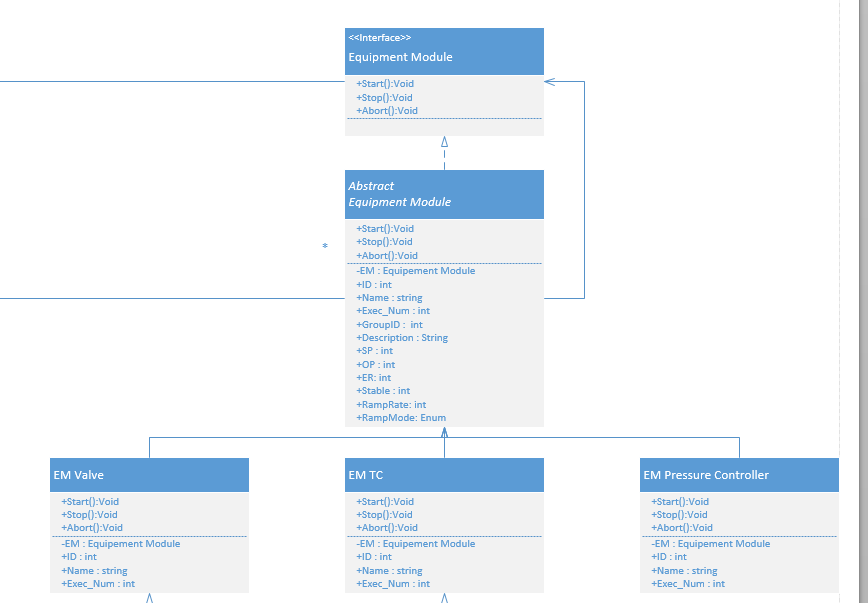
 So this will seem fairly long winded but I believe some people here will find this to be an interesting question and hopefully people can point me in the right direction. To give you guys some background I am a process control integrator working with PLC's and CRIO's to create automated solutions for out clients. I have a background in Software engineering and have worked a great amount in the past in Object Oriented languages such as Java or C#. I have only been using LabVIEW for the past 2 years and this is the first time I have utilized the OO features of LabVIEW. One of the first things I looked into was if interfaces and abstract classes existed in the OO concepts for LabVIEW. I learned quickly they do not and after looking through the white paper I had a grasp as to why. Which is fine but it lead to the rest of what I am going to explain. The end goal is to create some Equipment control modules based on the S88 standard that is used in process control. Typically an EM would have a Start(),Stop(), and Abort() function. We would like to create a library of these EM’s and keep with an overall good structure using inheritance in a OO style. I can inherit information from a parent class, and I can override the functions from a parent class as well. What is giving me problems however is that I am encapsulating a parent class object in the child object data area and I am attempting to utilize an override function on this encapsulated object. Our reasoning for an encapsulated object is to allow for dynamic creation of new EM’s that can be utilized by a previously created EM. I would like to be able to abort a parent EM and have that abort any cascaded EM’s that are children of it. With my current setup that I would use in C# I am running into a recursion error. Picture should be attached. I believe I understand the reason for this error, which is that technically we are recursively creating these EM’s and therefore can have essentially an infinite amount in memory to interact with. This wraps into why I was wondering in the first place about interfaces and abstract classes. If my top Object was actually a interface instead of an actual class you would be able to declare it but it would not be instantiated until a constructor created the more lower down classes. This would get rid of this recursive error as I could check if the child EM is instantiated before I decided whether a function could be utilized on it. So my question to everyone is, is there a work around that would give me the same result or is there a more LabVIEW acceptable way to do this? Attached is my UML diagram, the error I am receiving, and the LabVIEW Project that I created to attempt to demonstrate the architecture I wanted. Thanks for any help! ClassOOTest.zip
So this will seem fairly long winded but I believe some people here will find this to be an interesting question and hopefully people can point me in the right direction. To give you guys some background I am a process control integrator working with PLC's and CRIO's to create automated solutions for out clients. I have a background in Software engineering and have worked a great amount in the past in Object Oriented languages such as Java or C#. I have only been using LabVIEW for the past 2 years and this is the first time I have utilized the OO features of LabVIEW. One of the first things I looked into was if interfaces and abstract classes existed in the OO concepts for LabVIEW. I learned quickly they do not and after looking through the white paper I had a grasp as to why. Which is fine but it lead to the rest of what I am going to explain. The end goal is to create some Equipment control modules based on the S88 standard that is used in process control. Typically an EM would have a Start(),Stop(), and Abort() function. We would like to create a library of these EM’s and keep with an overall good structure using inheritance in a OO style. I can inherit information from a parent class, and I can override the functions from a parent class as well. What is giving me problems however is that I am encapsulating a parent class object in the child object data area and I am attempting to utilize an override function on this encapsulated object. Our reasoning for an encapsulated object is to allow for dynamic creation of new EM’s that can be utilized by a previously created EM. I would like to be able to abort a parent EM and have that abort any cascaded EM’s that are children of it. With my current setup that I would use in C# I am running into a recursion error. Picture should be attached. I believe I understand the reason for this error, which is that technically we are recursively creating these EM’s and therefore can have essentially an infinite amount in memory to interact with. This wraps into why I was wondering in the first place about interfaces and abstract classes. If my top Object was actually a interface instead of an actual class you would be able to declare it but it would not be instantiated until a constructor created the more lower down classes. This would get rid of this recursive error as I could check if the child EM is instantiated before I decided whether a function could be utilized on it. So my question to everyone is, is there a work around that would give me the same result or is there a more LabVIEW acceptable way to do this? Attached is my UML diagram, the error I am receiving, and the LabVIEW Project that I created to attempt to demonstrate the architecture I wanted. Thanks for any help! ClassOOTest.zip
-
Hi, I'm writing a LabVIEW application using the Actor Framework. This is the first time that I have used the framework and I need some advice regarding application architecture. My apologies if this is a basic question! How is a settings dialog box best implemented? In the past in non-Actor Framework applications I have loaded the configuration from a functional global variable, displayed the settings dialog, then written the updated settings back to the functional global. I'm not sure this would work correctly (or optimally) within the context of the Actor Framework, though. My application uses the template generated by Create Project -> Actor Framework. The top-level Actor manages the user interface. Two child Actors control separate pieces of hardware. The top-level actor must read a saved configuration from an INI file when the application starts, and save the final configuration back to the INI file on exit. Instinctively I think it would be best for each child actor to maintain its own settings, as a cluster in its class private data. Ideally I don't want to have to keep a separate instance of the two clusters of settings in the top-level Actor's private data in order to populate a settings dialog; this duplication seems unnecessary. The only way I can think of to make this work is as follows. At application start 1. Top-level Actor reads settings from INI file. 2. Send messages to both child actors with the new settings, and tell them to apply those settings to their private data. 3. Each child Actor should respond to acknowledge that the private data has been updated. To update the settings using a dialog box 1. Send a message from the top-level Actor to each child Actor to ask them to send their settings to the top-level Actor. 2. Wait for both child Actors to reply. 3. Display the dialog box. 4. If the user clicked 'Ok' and not 'Cancel', send messages to both actors with the new settings, and tell them to apply those settings to their private data. 5. Each child Actor should respond to acknowledge that the private data has been updated. On exit 1. Send a message from the top-level Actor to each child Actor to ask them to send their settings to the top-level Actor. 2. Wait for both child Actors to reply. 3. The top-level Actor writes the settings to the INI file. This doesn't seem like a sensible approach, though. Waiting for message replies sounds like the wrong thing to do. I wouldn't know where in the block diagram to implement this scheme, either. Can anyone offer me any advice? There must be a fairly standard way of doing this that I'm missing! Thanks in advance, Chris --- Dr. Chris Empson Robot Screening and Instrumentation Specialist School of Chemistry University of Leeds UK CLD
-
 Hey guys, So I was just wondering if forums like LAVA had any code review of an entire application and such. I typically have code review done at work but I was wondering if there was a thread where people just shared their code. I understand that sharing an entire code is typically not possible due to company policy and IP related matters but I thought it might be nice if I can take a look at a code of somebody outside of my typical circle and see how they do things.
Hey guys, So I was just wondering if forums like LAVA had any code review of an entire application and such. I typically have code review done at work but I was wondering if there was a thread where people just shared their code. I understand that sharing an entire code is typically not possible due to company policy and IP related matters but I thought it might be nice if I can take a look at a code of somebody outside of my typical circle and see how they do things. -
 Hi everyone, I'm wanting to open up the floor for your opinions and past experiences with designing a network communications architecture. - There will be one server, written in LabVIEW on a Windows based PC. - There will be multiple remote clients programmed in LabVIEW on cRIOs. - All devices will be connected via a wireless network, and all cRIO clients should have good throughput to the server. - It should be designed for bidirectional data flow, however the clients will do most of the talking. - Data sent will be, status packets, images, PDF documents, and other information. - Clients will not be continuously sending data, such as a typical DAQ system, but more reporting on events. I'm leaning towards the TCP socket option, but would like to consider higher-level forms of NI-propriety designs, such as Network Shared Variables or Network Streams, which I haven't had huge amounts of exposure to. Thanks for your opinions. Brenton
Hi everyone, I'm wanting to open up the floor for your opinions and past experiences with designing a network communications architecture. - There will be one server, written in LabVIEW on a Windows based PC. - There will be multiple remote clients programmed in LabVIEW on cRIOs. - All devices will be connected via a wireless network, and all cRIO clients should have good throughput to the server. - It should be designed for bidirectional data flow, however the clients will do most of the talking. - Data sent will be, status packets, images, PDF documents, and other information. - Clients will not be continuously sending data, such as a typical DAQ system, but more reporting on events. I'm leaning towards the TCP socket option, but would like to consider higher-level forms of NI-propriety designs, such as Network Shared Variables or Network Streams, which I haven't had huge amounts of exposure to. Thanks for your opinions. Brenton