Search the Community
Showing results for tags 'sqlite'.
Found 22 results
-
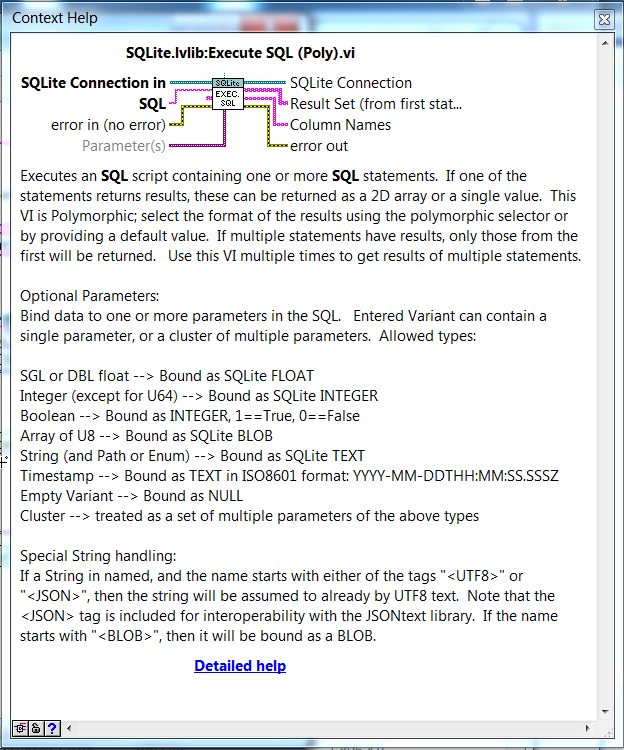
View File SQLite Library Introductory video now available on YouTube: Intro to SQLite in LabVIEW SQLite3 is a very light-weight, server-less, database-in-a-file library. See www.SQLite.org. This package is a wrapper of the SQLite3 C library and follows it closely. There are basically two use modes: (1) calling "Execute SQL" on a Connection to run SQL scripts (and optionally return 2D arrays of strings from an SQL statement that returns results); and (2) "Preparing" a single SQL statement and executing it step-by-step explicitly. The advantage of the later is the ability to "Bind" parameters to the statement, and get the column data back in the desired datatype. The "Bind" and "Get Column" VIs are set as properties of the "SQL Statement" object, for convenience in working with large numbers of them. See the original conversation on this here. Hosted on the NI LabVIEW Tools Network. JDP Science Tools group on NI.com. ***Requires VIPM 2017 or later for install.*** Submitter drjdpowell Submitted 06/19/2012 Category Database & File IO LabVIEW Version 2013 License Type BSD (Most common)
-
For comment, here is a beta version of the next SQLite Library release (1.11). It has a significant new feature of a "Parameter(s)" input to the "Execute SQL" functions. This can be a single parameter or a cluster of multiple parameters. Uses Variant functions and will be not as performance as a more explicit preparing and binding of a Statement object, but should be easier to code. drjdpowell_lib_sqlite_labview-1.11.0.86.vip

-
Version 1.8.6
1,846 downloads
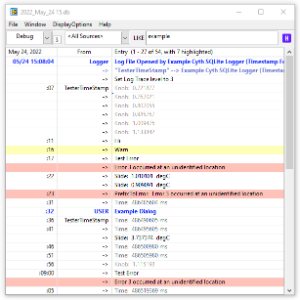
A logger and log viewer using an SQLite database. The logger is a background process that logs at about once per second. A simple API allows log entries to be added from anywhere in a program. A Log Viewer is available under the Tools menu (Tools>>Cyth Log Viewer); this can alternately be built into a stand-alone executable. Requires SQLite Library (Tools Network). Notes: Version 1.4.0 is the last available for LabVIEW 2011. New development in LabVIEW 2013. Latest versions available directly through VIPM.io servers. -
 Currently, my vision software will do a compression (subtract to background image then count zero) and write to a table in SQLite file. Since we want to speed up the process, I write entire image in a temporary table. Then at the end, I read the table, do compression and write to the actual table, then drop the temporary table. This takes a lot of time too even I use the Journal mode = memory. I think the issue is I put the process code in 4 separated modules: Select the temp table -> output array Compress the output array of step 1 Insert the compress data from step 2 to actual table Drop the temp table I am looking for an option to mix these steps together to speed up the speed for example select and delete the row in temp table at the same time then at the end I can drop the table faster. Currently, it takes significant time to drop the table. Our raw data can be up to 3GB. But I don't know how to combine the query. I also read that SQlite does not support this. So I also looking for an advice on how to make this process more efficient. I thought about using the queue too but I need input before I change it. Thank you in advance.
Currently, my vision software will do a compression (subtract to background image then count zero) and write to a table in SQLite file. Since we want to speed up the process, I write entire image in a temporary table. Then at the end, I read the table, do compression and write to the actual table, then drop the temporary table. This takes a lot of time too even I use the Journal mode = memory. I think the issue is I put the process code in 4 separated modules: Select the temp table -> output array Compress the output array of step 1 Insert the compress data from step 2 to actual table Drop the temp table I am looking for an option to mix these steps together to speed up the speed for example select and delete the row in temp table at the same time then at the end I can drop the table faster. Currently, it takes significant time to drop the table. Our raw data can be up to 3GB. But I don't know how to combine the query. I also read that SQlite does not support this. So I also looking for an advice on how to make this process more efficient. I thought about using the queue too but I need input before I change it. Thank you in advance. -
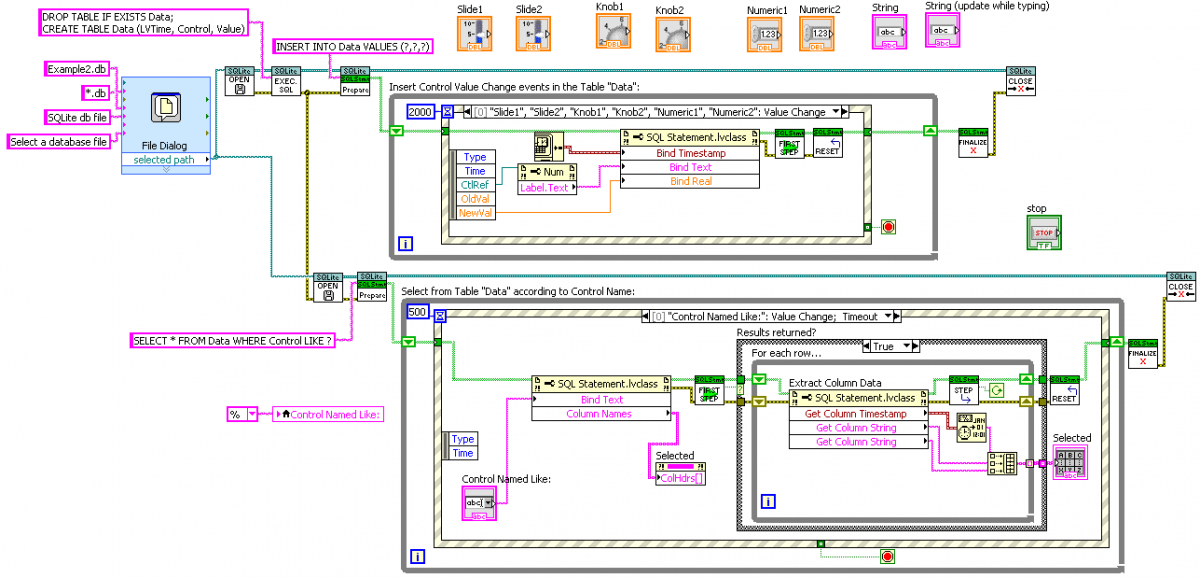
Hello, I’ve been working with SQLite for a logging application and I thought I might offer my SQLite LabVIEW wrapper for possible inclusion in OpenG. There are at least two other implementations out there, both with licensing restrictions, but it would be nice to have this in OpenG as I think SQLite is a major addition to the capabilities of LabVIEW. Below is a zip file; it includes a couple of examples. SQLite LabVIEW.zip LabVIEW 2011. SQLite dll for Windows (32-bit) included. NOTE: more recent version now in the Code Repository. An (incomplete) menu: Here is the block diagram of Example2: There are basically two use modes: (1) calling “Execute SQL” on a Connection to run SQL scripts (and optionally return 2D arrays of strings or variants from an SQL statement that returns results); and (2) “Preparing" a single SQL statement and executing it step-by-step explicitly. The advantage of the later is the ability to “Bind” parameters to the statement, and get the column data back in the desired datatype. The “Bind” and “Get Column” VIs are set as properties of the “SQL Statement” object, for convenience in working with large numbers of them. This package closely follows the SQLite C/C++ interface and is intended to facilitate the execution of SQL scripts, rather than provide VIs that substitute for SQL statements. Thus there are no VIs for creating tables, triggers, etc. The SQLite website provides extensive documentation of SQL and the C/C++ interface. The only differences from the C/C++ interface are: 1) “Reset” and “Finalize” do not return the error code from the previous “Step” (as this would be both unnecessary an confusing in LabVIEW) 2) The default busy timeout for waiting for a database file that is temporarily “busy” due to another connection is set at 5000 ms, rather than 0 ms. 3) I created a “First Step” VI that wraps “Step”, intended to be the first call on Step that actually execute the statement (further calls to Step increment through return result rows). I did this to allow future potential retry logic in “First Step”, and to have a clearer set of VI icons showing the difference between executing a statement and stepping through result rows. As I said, it would be really nice to have an SQLite interface in OpenG. I’ve only just scratched the surface of what can be done with SQLite (see, for example, the “Full Text Search” and “R*tree” extensions). — James
-
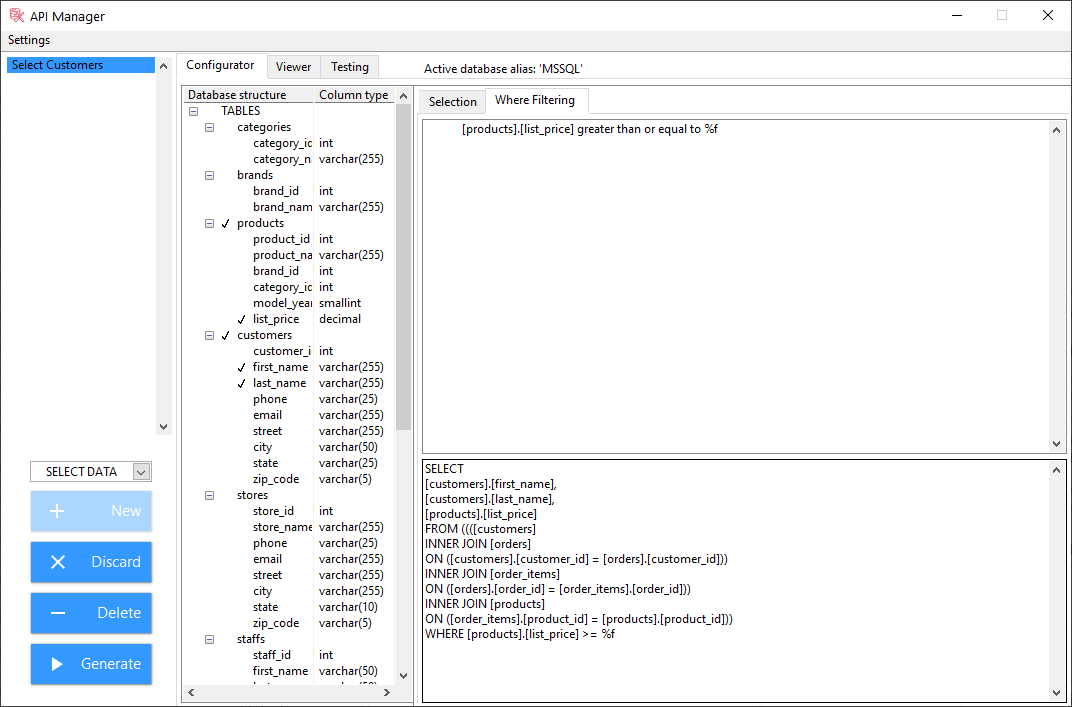
Dear Community, let me present our new ANV Database Toolkit, which has been recently released at vipm.io. Short introduction to the toolkit is posted by this link, and it also describes steps which should be done in order to use this toolkit. ANV Database Toolkit helps developers design LabVIEW API for querying various databases (MS SQL, MySQL, SQLite, Access). It allows to create VIs which can be used as API with the help of graphical user interface. When using these VIs, toolkit handles connection with the database, thus relieving developers of this burden in their applications. It has the following features: Simplifies handling of databases in LabVIEW projects Allows to graphically create API VIs for Databases Supports Read, Write, Update and Delete queries Supports various database types (MS SQL, MySQL, SQLite, Access) Overall idea is that developer could create set of high-level API VIs for queries using graphical user interface, without actual writing of SQL queries. Those API VIs are used in the application, and handle database communication in the background. Moreover, SQL query could be applied to any of the supported database types, it is a matter of database type selection. Change of target database does not require changes in API VI which executes the query. After installation of the toolkit, sample project is available, which shows possibilities of the toolkit in terms of execution different types of queries. Note, that in order to install the toolkit, VI Package Manager must be launched with Administrator privileges. This toolkit is paid, and price is disclosed based on price quotation. But anyway, there are 30 days of trial period during which you could tryout the toolkit, and decide whether it is helpful (and hope that it will be) for your needs. In case of any feedback, ideas or issues please do not hesitate to contact me directly here, or at vipm.io, or at e-mail info@anv-tech.com.
-
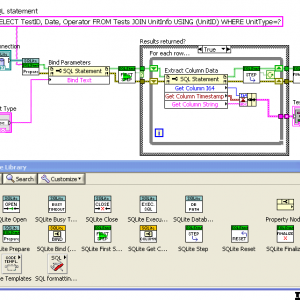
Version 1.11.3
9,070 downloads
Introductory video now available on YouTube: Intro to SQLite in LabVIEW SQLite3 is a very light-weight, server-less, database-in-a-file library. See www.SQLite.org. This package is a wrapper of the SQLite3 C library and follows it closely. There are basically two use modes: (1) calling "Execute SQL" on a Connection to run SQL scripts (and optionally return 2D arrays of strings from an SQL statement that returns results); and (2) "Preparing" a single SQL statement and executing it step-by-step explicitly. The advantage of the later is the ability to "Bind" parameters to the statement, and get the column data back in the desired datatype. The "Bind" and "Get Column" VIs are set as properties of the "SQL Statement" object, for convenience in working with large numbers of them. See the original conversation on this here. Hosted on the NI LabVIEW Tools Network. JDP Science Tools group on NI.com. ***Requires VIPM 2017 or later for install.*** -
Hi, I would like to know if I can write stream data into two different tables with SQLite at the same time or not? Currently my system has one camera. I store the capture images and particle measurement in one table. I have just add one more camera to the system and would like to do the same thing and write to a second table in a parallel process. I wonder if this is possible or not. I use SQLite library. Thanks in advance.
-
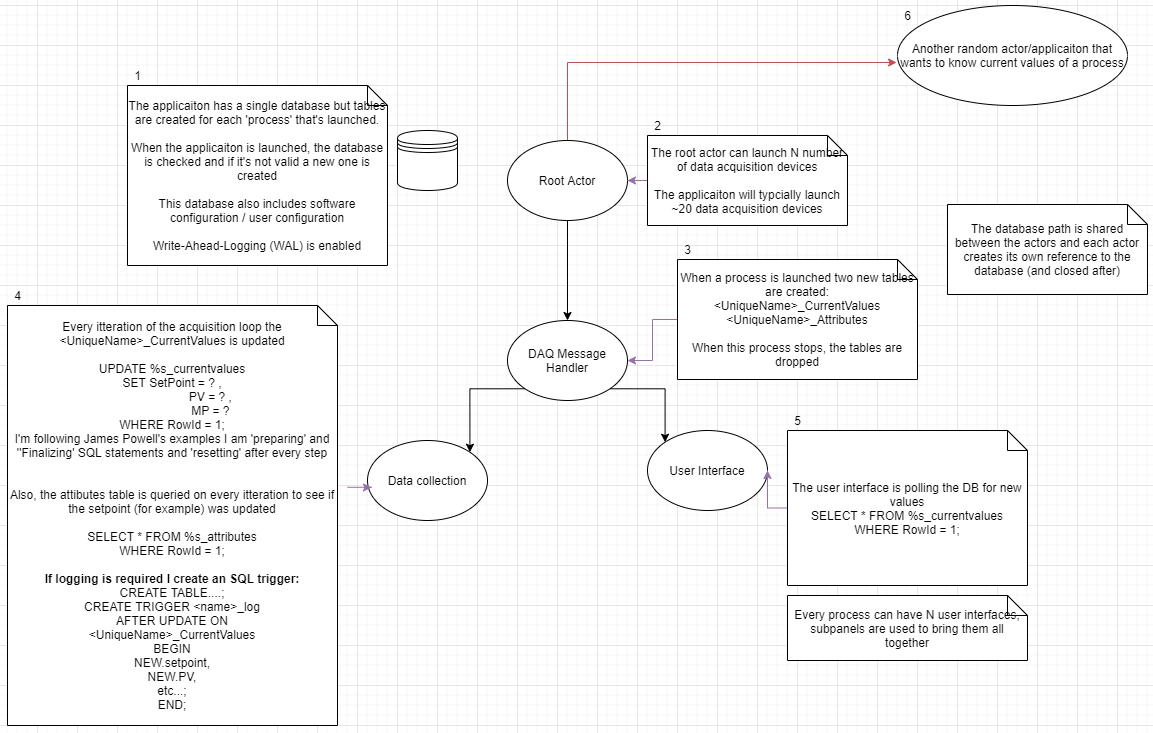
Hi Everyone, I (re)watched James Powell's talk at GDevCon#2 about Application Design Around SQLite. I really like this idea as I have an application with lots of data (from serial devices and software configuration) that's all needed in several areas of the application (and external applications) and his talk was a 'light-bulb' moment where I thought I could have a centralized SQLite database that all the modules could access to select / update data. He said the database could be the 'model' in the model-view-controller design pattern because the database is very fast. So you can collect data in one actor and publish it directly to the DB, and have another actor read the data directly from the DB, with a benefit of having another application being able to view the data. Link to James' talk: https://www.youtube.com/watch?v=i4_l-UuWtPY&t=1241s) I created a basic proof of concept which launches N-processes to generate-data (publish to database) and others to act as a UI (read data from database and update configuration settings in the DB (like set-point)). However after launching a couple of processes I ran into 'Database is locked (error 5) ', and I realized 2 things, SQLite databases aren't magically able to have n-concurrent readers/writers , and I'm not using them right...(I hope). I've created a schematic (attached) to show what I did in the PoC (that was getting 'Database is locked (error 5)' errors). I'm a solo-developer (and SQLite first-timer*) and would really appreciate it if someone could look over the schematic and give me guidance on how it should be done. There's a lot more to the actual application, but I think once I understand the limitations of the DB I'll be able to work with it. *I've done SQL training courses. In the actual application, the UI and business logic are on two completely separate branches (I only connected them to a single actor for the PoC) Some general questions / thoughts I had: Is the SQLite based application design something worth perusing / is it a sensible design choice? Instead of creating lots of tables (when I launch the actors) should I instead make separate databases? - to reduce the number of requests per DB? (I shouldn't think so... but worth asking) When generating data, I'm using UPDATE to change a single row in a table (current value), I'm then reading that single row in other areas of code. (Then if logging is needed, I create a trigger to copy the data to a separate table) Would it be better if I INSERT data and have the other modules read the max RowId for the current value and periodically delete rows? The more clones I had, the slower the UI seemed to update (should have been 10 times/second, but reduced to updating every 3 seconds). I was under the impression that you can do thousands of transactions per second, so I think I'm querying the DB inefficiently. The two main reasons why I like the database approach are: External applications will need to 'tap-into' the data, if they could get to it via an SQL query - that would be ideal. Data-logging is a big part of the application. Any advice you can give would be much appreciated. Cheers, Tom (I'm using quite a few reuse libraries so I can't easily share the code, however, if it would be beneficial, I could re-work the PoC to just use 'Core-LabVIEW' and James Powell's SQLite API)
-
Good Afternoon, I have been having an issue trying to resolve an error all afternoon, and hope that you might be able to help. I am trying to execute the follow SQL " SELECT m.name as tableName, p.name as columnName FROM sqlite_master m left outer join pragma_table_info((m.name)) p on m.name <> p.name where columnName = 'UploadedFlag' order by tableName, columnName " That returns a list of the tables that Contain the 'UploadedFlag' Column. I have testing the SQL on both HeidiSQL and SQLite Expert Personal applications and run and return what I expect, however when I run it through LabVIEW I get a 402860 Error with the description " SQLITE_ERROR(1): near "(": syntax error " If anyone could point me in the direction of the syntax error then I would be very greatful. Regards Mark
-
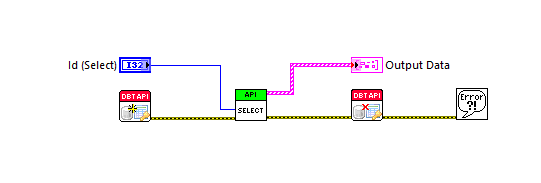
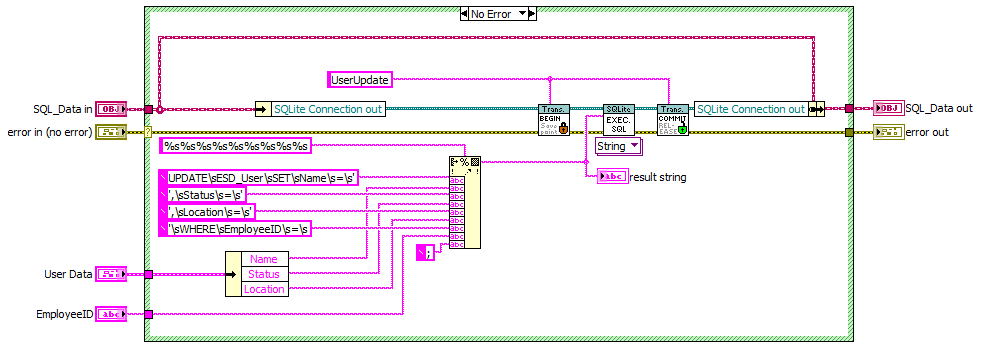
Hi Lava Citizens, I am trying to implement SQLite - update function so i can easily modify values in a selected row. http://www.sqlitetutorial.net/sqlite-update/ I have tried this statement - UPDATE ESD_User SET Name = 'James Bond', Status = 'Employee', Location = 'Canada' WHERE EmployeeID = 5; using the DB Browser for SQLite. The command does update the values as expected. I am trying to do same with the labview + sqlite driver. I have attached the update user code. I am getting an error from EXEC SQL "SQLite.lvlib:Connection.lvclass:Execute SQL (Single String).vi:760001:Step on "UPDATE ESD_User SET Name = 'James Bond', Status = 'Employee', Location = 'Canada' WHERE EmployeeID = 5;" SQLITE_BUSY: database is locked." Can you please explain the cause of this error? Thank you, max
-
 Question: I'm trying to determine the 'best' way to structure my data when storing to disk. My data comes from a variety of different sensor types and with quite different rates - e.g. temperature data (currently) as a 1D array of temperatures and a timestamp [time, t1, t2, ..., tn] at maybe 1 Hz and analog waveform data from load cells at data rates ~O(kHz). I also want to be able to read back data from previous experiments and replot on a similar graph. Reading threads on this forum and at NI I'm uncertain if I'll be better pursuing a set of TDMS files, probably one per sensor type stored at the group/channel level, then at the end of an experiment, collating the TDMS files into one master file and defragmenting, or trying instead to write to a SQLite database. (I have nearly no experience using SQL, but no problem learning - drjdpowell's youtube video was already very informative.) An alternative possibility mentioned in a thread somewhere here was to write TDMS files, then store records on which files hold what data in what I understood to be a catalogue-style SQL database. Could anyone with a clearer idea/head than me comment on which avenues are dark tracks down which time will be easily lost in failed attempts, and which seem likely to be worth trying? Background: I'm currently rewriting some code I wrote last year based on the 'Continuous Measurement and Logging' template/project. The logging in that case was writing to a single, binary file. Keeping my data format in line as I changed sensor arrangement became increasingly annoying and an ever expanding series of block diagrams lead me to start on the 'Actor Framework' architecture. I have some initial progress with setting up actors and generating some simulated data, passing it around and getting it from different formats onto a waveform or XY-graph (can be chosen by choice of child class to insert into a subpanel). I'm now looking to write the logging code such that I have basic implementations of several of the components before I try and write out all of the measurement components and so on - I already have a temperature measurement library for an LTC2983 based PCB and so can use that to test (with hardware) inputting 1D arrays, whilst I'm planning to use just the sine wave VIs to test waveform input. I'm not so far into this set of coding that anything is set in stone yet, and so I want to at least try and start off in the right direction. Whilst it seems likely changes to requirements or plans will require modifications to whatever I write, it would be nice if those weren't of the same magnitude as the entire (e.g. logging) codebase. Apologies for the somewhat verbose post.
Question: I'm trying to determine the 'best' way to structure my data when storing to disk. My data comes from a variety of different sensor types and with quite different rates - e.g. temperature data (currently) as a 1D array of temperatures and a timestamp [time, t1, t2, ..., tn] at maybe 1 Hz and analog waveform data from load cells at data rates ~O(kHz). I also want to be able to read back data from previous experiments and replot on a similar graph. Reading threads on this forum and at NI I'm uncertain if I'll be better pursuing a set of TDMS files, probably one per sensor type stored at the group/channel level, then at the end of an experiment, collating the TDMS files into one master file and defragmenting, or trying instead to write to a SQLite database. (I have nearly no experience using SQL, but no problem learning - drjdpowell's youtube video was already very informative.) An alternative possibility mentioned in a thread somewhere here was to write TDMS files, then store records on which files hold what data in what I understood to be a catalogue-style SQL database. Could anyone with a clearer idea/head than me comment on which avenues are dark tracks down which time will be easily lost in failed attempts, and which seem likely to be worth trying? Background: I'm currently rewriting some code I wrote last year based on the 'Continuous Measurement and Logging' template/project. The logging in that case was writing to a single, binary file. Keeping my data format in line as I changed sensor arrangement became increasingly annoying and an ever expanding series of block diagrams lead me to start on the 'Actor Framework' architecture. I have some initial progress with setting up actors and generating some simulated data, passing it around and getting it from different formats onto a waveform or XY-graph (can be chosen by choice of child class to insert into a subpanel). I'm now looking to write the logging code such that I have basic implementations of several of the components before I try and write out all of the measurement components and so on - I already have a temperature measurement library for an LTC2983 based PCB and so can use that to test (with hardware) inputting 1D arrays, whilst I'm planning to use just the sine wave VIs to test waveform input. I'm not so far into this set of coding that anything is set in stone yet, and so I want to at least try and start off in the right direction. Whilst it seems likely changes to requirements or plans will require modifications to whatever I write, it would be nice if those weren't of the same magnitude as the entire (e.g. logging) codebase. Apologies for the somewhat verbose post. -
A new feature called the "Session Extension" has just been rolled into the trunk of latest release of SQLite (3.13.0). From the authors: In a nutshell you can "diff" a database and produce a patchfile of the changes (and the reverse). Now. Most are probably thinking source code control at this point which isn't very interesting in terms of LabVIEW. However. There is another use case - synchronizing remote acquisition databases. Previously we could have a SQLite database to store acquired data in, say, a cRIO or PXI chassis. Periodically we would want to back up or synchronize another database either for back up, offline exploitation or the file was becoming too large to store.. This meant making a backup copy locally and then sending the entire database file to the recipient. That could take a long time, was fraught with problems of disconnection and there may have not been enough space to create a copy. With this new feature we should be able to overcome or at least alleviate these issues and effectively implement "restore points" and "staged updates" for remote databases as well as bandwidth reduction while synchronising and configuring. For example. We may store configuration information, amongst other things, in the database and only want to update that section. We may only want the last 24 hours of data sent back for exploitation. We may only want error or waveform meta information....and so on. I'm looking forward to playing with this feature over the next few weeks. so if you have suggestions for another use-case, then I would like to hear it.
-
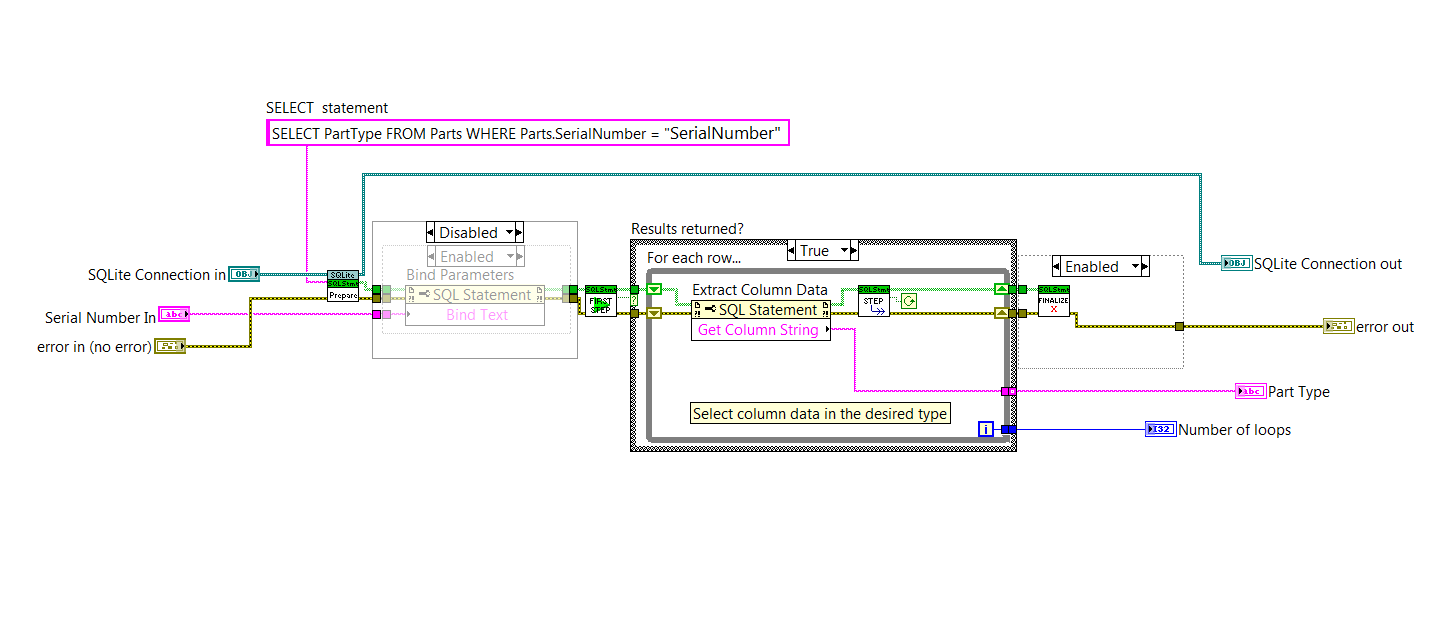
 hey guys, I'm pretty new to Labview and very new to databases. I found SQLite and thought it would be a good fit for a new project, but I'm having a hard time getting the where statements to work so I get the data I'm expecting. Ive created a table in a database editor called parts, it has two fields part type and serial number. I scan a tag to get a serial number and would like my database call to return the appropriate part type. Right now I only have one value in each column ( a single serial number and a single part type). I tried to use the "?" and bind the serial number to it but kept getting zero returned values. I can get the part type value by saying "SELECT PartType FROM Parts". I must be doing something very simple wrong, I tried to look on the SQLite.org but really wasnt sure what I was missing in the syntax section for select. any help would be great, Thanks
hey guys, I'm pretty new to Labview and very new to databases. I found SQLite and thought it would be a good fit for a new project, but I'm having a hard time getting the where statements to work so I get the data I'm expecting. Ive created a table in a database editor called parts, it has two fields part type and serial number. I scan a tag to get a serial number and would like my database call to return the appropriate part type. Right now I only have one value in each column ( a single serial number and a single part type). I tried to use the "?" and bind the serial number to it but kept getting zero returned values. I can get the part type value by saying "SELECT PartType FROM Parts". I must be doing something very simple wrong, I tried to look on the SQLite.org but really wasnt sure what I was missing in the syntax section for select. any help would be great, Thanks
-
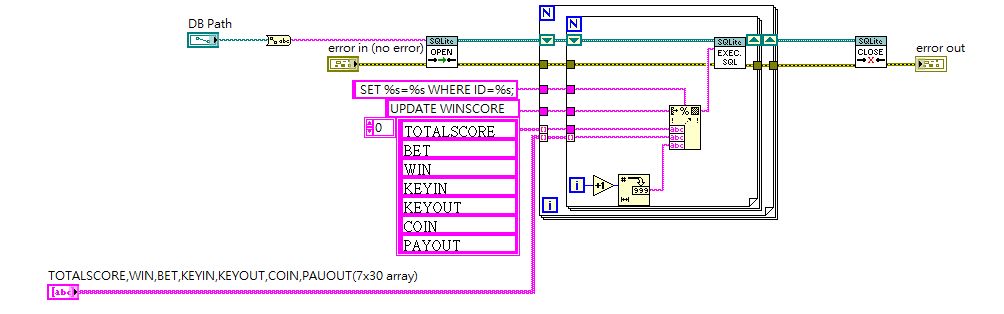
I used sqlite api to update my data, my array is 7x30. It takes 1.5s, is any methods can improve speed? Thank you! B/R Ancle
-
View File Cyth SQLite Logger A logger and log viewer using an SQLite database. The logger is a background process that logs at about once per second. A simple API allows log entries to be added from anywhere in a program. A Log Viewer is available under the Tools menu (Tools>>Cyth Log Viewer); this can alternately be built into a stand-alone executable. Requires SQLite Library (Tools Network). Notes: Version 1.4.0 is the last available for LabVIEW 2011. New development in LabVIEW 2013. Latest versions available directly through VIPM.io servers. Submitter drjdpowell Submitted 03/08/2013 Category Database & File IO License Type BSD (Most common)
-
A new SQLite question: I have, during testing, created several multi-GB files which I can use for read testing. I notice that upon first access (after loading LabVIEW) the query to get data takes sometimes exactly as long as if the file was not indexed at all. Subsequent reads are fast (drops from 30sec to 100 msec). 1) Has anyone else seen this? 2) Is this normal (Loading Index into memory) 3) How do I make the first file access fast? Shane
-

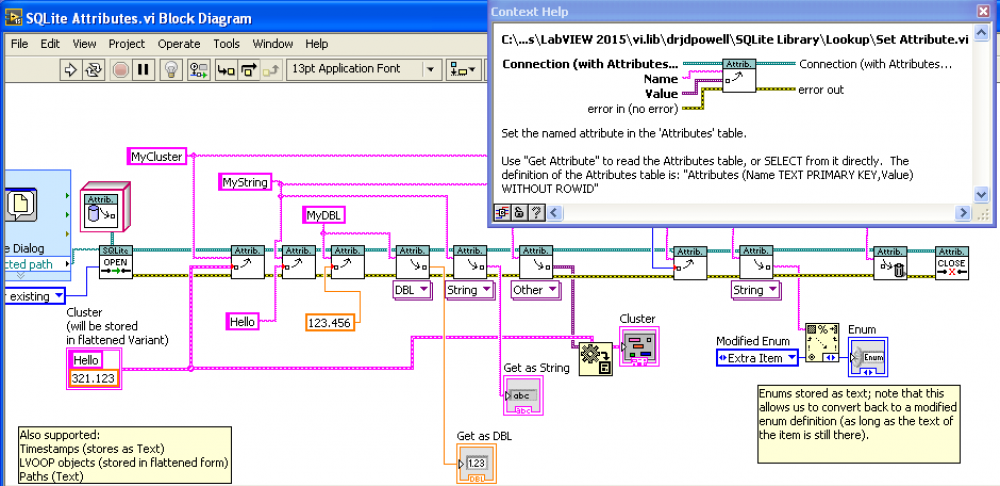
sqlite SQLite Library 1.6 beta: Attributes lookup table
drjdpowell posted a topic in Code In-Development
Attached is a beta version of the latest 1.6 version of SQLite Library, for anyone who like to give feedback. A major addition (not yet well tested) is “Attributesâ€, modeled on Variant Attributes or Waveform Attributes, but stored in any SQLite db file. The idea is to make it easy to store simple named parameters without much effort. See the example “SQLite Attributes.viâ€. A more minor upgrade is making “Execute SQL†polymorphic, so as to return data in a number of forms in addition to a 2D-array of strings. See the upgraded example “SQLite Example 1 — Create Table.vi†which uses the new polymorphic VI, including showing how to return results as a Cluster. For Attributes, I had to make some choices in how to store the various LabVIEW types in SQLite’s limited number of types. The format I decided on is: 1) all simple types that already have a defined mapping (i.e. a “Bind†property node) are stored as defined (so strings and paths are Text, DBLs and Singles are Float, integers (except U64) are Integers. 2) Timestamps are ISO-8601 Text (the most standardized format of the four possibilities) 3) Enums are stored as the item text as Text, rather than the integer value. This seems the most robust against changes in the enum definition. 4) LVOOP objects are stored flattened in a Blob. 5) any other LV type is, contained in a Variant, flattened and stored in a Blob. Using a flattened Variant means we store the type information and LabVIEW version. drjdpowell_lib_sqlite_labview-1.6.0.51.vip LabVIEW 2011-2015 The Attribute stuff grew out of a project where SQLite files held the data, one for each “Runâ€, and the Runs had lots of small bits of information that needed to be stored in addition to the bulk of the data. When and where the measurement was taken, what the equipment setup was, who the Operator was, etc. I purpose-made a name-value look-up table for this, but realized that such a table could be made into reusable “attributesâ€.
-
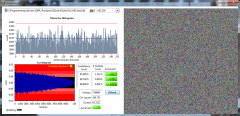
From the album: ShaunR
SQLite database statistical analysis with AES 256 CBC encryption. N.B. 1. Multiple encoding runs produce new database byte-map. - differential analysis resistant. 2. Statistically indistinguishable from random data. - statistical analysis resistant. -
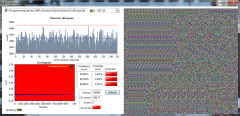
From the album: ShaunR
SQLite database statistical analysis with AES 128 ECB encryption. N.B. 1. Multiple encoding runs produce identical database byte-map - susceptible to differential analysis. 2. Information leakage and correlation especially for zero values - susceptible to statistical analysis.. -
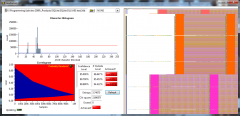
From the album: ShaunR
SQLite database statistical analysis without encryption -
I briefly mentioned a logging API that I've been using for logging errors, warnings etc to a SQLite database in the NLog thread. Since it seemed to be of interest, I thought I'd knock together a demo so that peeps could see how I use it and demonstrate some of the features using database enables above and beyond boring old text file logs (it requires the SQLite API for Labview installed) So here she is..... If people approve and think it's useful, I will add it to the SQLite API for Labview as an example.