

PaulL
-
Posts
544 -
Joined
-
Last visited
-
Days Won
17
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by PaulL
-
-
I've read your whitepaper and I like your approach in general. Have you released this code for public use or is it proprietary? You can pm me if it's going to derail this forum thread.
We've learned a lot since I wrote the white paper, and I have since created a system component template that I consider to be immensely successful. It allows us to concentrate on the specific application rather than the details of messaging and the like since those are a given, and creating and debugging an application is orders of magnitude more straightforward, we have found. We have pondered releasing the template in some manner, but we haven't yet. Will you be at NI Week? If so, perhaps the best thing is to attend my session,
Track: Software DevelopmentTechniques
Session ID: TS1665
Title: System ComponentsWith Object-Oriented Design Patterns
Speaker(s): Paul Lotz with LowellObservatory
Date: Tuesday, August 2
Time: 1:00 PM
Room: 14 (located on the 4thfloor of the Austin Convention Center),
and we can talk then about what would be most helpful....
-
 1
1
-
-
Well, an approach we use differs in letter from what you are attempting, but maybe accomplishes the larger goal.
Our Views do handle control events (that's the easiest place to handle them!), but when an event happens they send a message to the Controller, which instructs the Model what to do. In some applications the messages are commands using the Command Pattern, so that we can use one message type (of the top-level Command class) and therefore a single message pipe (user event, shared variable, queue, or other messaging system). (In practice we often send basic shared variables from the View and then translate these to Commands before sending them to the Controller, because the messages may come from various sources, but that is a fine point.)
Paul
-
Has somebody this pdf? It isn't online anymore. Thx!
Our organization just released a new version of its website, and the remappings aren't yet complete.
In the meantime you can find a copy of this paper here:
https://decibel.ni.com/content/docs/DOC-13368
Paul
-
One other question I have is what do you do with a working copy when you are done with it? Do you just delete it from your hard drive like you would any other (non versioned) file/directory or do you have to do something special so the repository knows whats going on?
When you are "done with" the working copy, yes, you can just delete it from your hard drive using, for example, Windows Explorer. You don't need to tell Subversion anything.
Note that you can have multiple working copies on your machine.
In practice, I have a main working copy that I continually update, so I am never "done with" it.... (I do have temporary working copies of some packages occasionally.)
Paul
-
That's not right. You only get a conflict if your working copy has changed and the server copy has also changed independently (you or someone else committed a change from a different working copy). If the OP is the only one using the repository, there is something wrong with his workflow.
Yes, you are correct. My example was not correct.
-
I dont understand why there should be a conflict. I am the only person working on this project so there is only one working copy and I commit my changes pretty regularly. What would cause a conflict?
An example: You modify a file (e.g., save a VI), then ask Subversion to do an update. Subversion will indicate that there is a conflict because your working copy is newer than the checked-in version.
-
When creating an accessor method, there is a choice:
Create dynamic accessorCreate static accessorWhat is the difference between the two and how does that influence our choice?
Is it possible to change the type of accessor after having created the accessor? Or do we need to create a new one?
RayR
Dynamic methods have dynamic dispatch input terminals for the object inputs and outputs of the owning class, meaning one can override those methods in child classes.
One cannot override static accessors, but one can in-line these VIs, for instance, to optimize performance.
It is possible to switch from one to the other by changing the property of the terminals on the connector pane, but I think it is far better to design appropriately in the first place.
In the design approach we use, static accessors are the correct choice in about 98% of the situations we encounter. There are a few rare situations where we need to access data via an interface, so we do define a dynamic accessor method on the interface (but the interface's method never actually executes). My advice is to use a static accessor method unless you are really sure you need a dynamic accessor method. (This answer may depend a bit on one's design approach, though. I think what I have stated is a good rule of thumb, but there may be other sorts of designs that would have different answers.)
-
2
-
-
I'm sure this isn't what you are asking, since that would be too simple, but maybe it will help someone:
In the Tree Properties dialog (I'm looking at the System version) on the Appearance tab there are ring controls to set the number of Rows and Columns, as well as set the properties of the scroll bars.
Presumably the control is no longer in a state where you can do this?
-
You can do that but perhaps it would be better to have a single start button outside the tab control?
-
This obviously isn't a fair question, but what method would you actually be likely to use (use number of seconds in day, create a helper time object, parse a string, have separate inputs for T/M/S, etc.) and why?
Jumping in: I thought about this and I would suggest making an adapter (which one would need any time one redefined an input type, not just if it's a cluster).
Paul
-
Yep, which is one of the reasons why the solution works for you. To reiterate and make absolutely clear to anyone bothering to read this, I'm not claiming your solution is wrong or inferior to any other solution. I'm not claiming there are insurmountable obstacles that can't be resolved with your solution. I'm just pointing out potential consequences of the various designs to the OP, who as a Labview user just starting in LVOOP, probably doesn't have any idea how much these early decisions can affect future changes. (I know I didn't.)
Fair enough! :-)
It significantly limits my ability to meaningfully override the method in a child class, because the custom type defined by the parent class' method often does not match the custom type I need for the child class' method.
I see your point. I guess I see this is as a matter of asking at design time what might change. I can see how it is possible to paint oneself in a corner using a cluster input, and so it would make sense to keep the data out of clusters. On the other hand, if one is just using this data in multiple classes within a single application, I think using strict typedefed clusters is not a bad option. I now see what you mean, though.
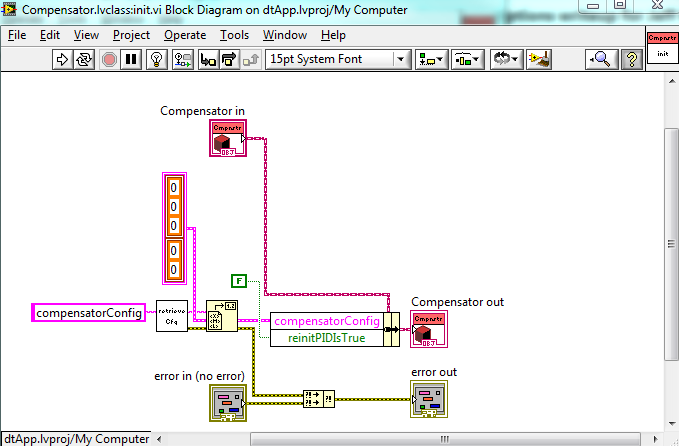
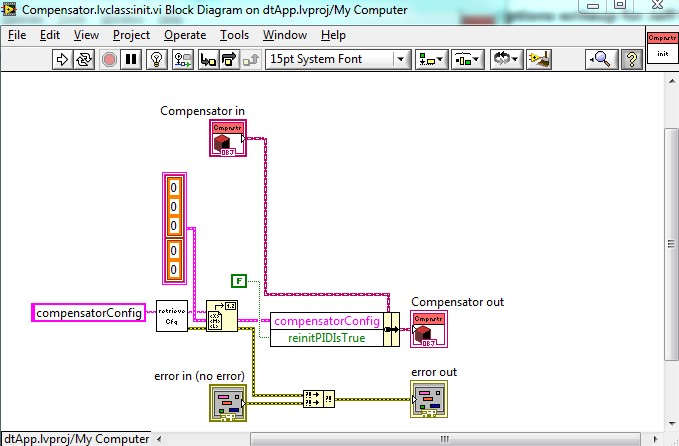
By the way, in your Compensator.init method above you have errors generated within that vi overwriting errors coming in on the input terminal. Is there a specific reason you do that? I usually prioritize all input errors over errors generated within the vi itself (or within its sub vis) simply because the current vi might be failing because of an error that occurred previously, and I want to know about the first error, not the last error. Of course, this vi doesn't have any other inputs so it doesn't really matter that much, but I was just curious...
Short answer: It is a bug on my part. I usually do wire the input to the top terminal of the Merge Errors function, but I haven't been exceptionally careful about it because I dídn't know the Merge Errors function cared (but it makes sense, of course, that it does). Now I know I must wire the terminals in the correct order. Thanks for catching this and pointing it out to me!
-
For example, maybe the configuration parameters need to be adjustable by the end user at runtime through a dialog box or something. Ideally that could be implemented without changing the DataAcquisition class since nothing about the data acquisition instrument or data collection has changed.
Certainly. We accomplish this with a configuration editor that is completely independent of the model (e.g., DataAcquisition class). It does need a reference to the configuration typedef. (We collect the configuration typedefs in a library.) We can add any functionality we want to the configuration editor without ever touching the DataAcquisition class.
The revision update issue is one reason. Using a cluster on the conpane also significantly limits my ability to meaningfully override the method in a child class.
I was actually thinking about this thread during a long drive down to Phoenix yesterday, and anticipated the need to generalize the data as a possible objection. It is certainly true that I can't override a cluster, but since the use case is to handle a definition (really a collection) of a very specific set of flat-by-definition configuration data, in practice I have no need to do this. (We have other types of essentially data classes--e.g.,commands, where inheritance is necessary, so classes are necessary--well, command classes have methods, too, so clusters won't do. To date I have not had a reason to inherit a configuration definition, though of course it may make sense to do this given another paradigm.)
Why does using a cluster significantly limit the ability to override the method in a child class? I don't see why that is. Maybe this is another aspect of version control considerations? I honestly can't think of a serious problem here....
-
Sorry to hear about the horrible experience Tomas and you had! Sounds awful!

I have to say, though, that I use the diagram clean-up tool all the time (it works well for the type of VIs I write--but it would not be good for other types of VIs, to be sure) and I have never seen it cause a drawmgr.cpp error.
I totally agree it should be possible to turn off the feature, since not all users like it and it is not well-suited to some design approaches. For some design approaches, though, it works quite well!
Good luck with the FRC in the future!
-
Hey, Paul
I've been working with high school students and while they are complete novices at programming, they take to LabVIEW very easily. We don't do OOP but we have been programming cRIOs to make robots. Let me know if you want me to invite you (and others at Lowell) to any of their events. Keep an eye out for the CocoNuts (Coconino High School's Robotics group) and FIRST. I've been mentoring them for 2 years now and absolutely love it!
We'd love to come and cheer on the team. Keep us posted! And congrats to the team on what they have accomplished!
-
Paul's suggestion works too. Advantages - simple to understand and fast to implement. Disadvantages - it couples the config file (and schema) to the daq object, which may make it harder to add flexibility later on.
I think of configuration data as attributes for the class that uses them, with the added constraint that we read them from a file.
Hence I need a reference to the type (but I already need that since it is in the class control definition) and I need to call two common methods (retrieveCfg, that I developed), and Unflatten from XML (core LabVIEW) in the class init method:
Since the configuration is just (usually complex) data (no methods), i.e., a custom data type, I don't mind not making it a class [and it is practically simpler to access the data and in some cases necessary to satisfy loop speed requirements if it is a cluster), although a strict type-defed cluster doesn't have the version-safe behavior that a LabVIEW class does, as you have elsewhere noted]. (By the way, what historically drove me to use typedefed clusters instead of classes was that I needed to display the information on a configuration editor's View, and currently classes don't have a control I can put on a View (OK, and I think that using "XControls" as "Friends" is not a practical solution). I think it is certainly fine to define configuration classes, but for the reasons indicated I think it is simpler to use essentially custom data types.)
Personally, I try to make sure none of my class method parameters are clusters. Using clusters that way usually results in bad code smells for me.
OK, I'm curious. Why not? (Is it because of the version to version update issue or something else?) I haven't (yet) found a compelling reason to avoid using strict typedefs of data (used strictly as data) within an application. (In practice, I don't do it often, but I don't have a rule against it.) By the way, where I do use typedefs a fair amount apart from configuration definitions is not for clusters, but for Enums. While I do recognize that classes will update correctly from version to version, my design approach means that this has never been an issue for me with strict typedefs either.
By the way, I'm obviously not arguing against the use of LabVIEW classes. I haven't written a non-test or top-level VI that isn't in a class (well, maybe a couple for very special purposes) for quite some time now! :-)
And, OK, in fairness, I'm using my own custom XML-based configuration editor, not "ini" files requiring a lot of customization for each data type. Of course, I think the simpler XML approach is the way it should be! :-) Lol
-
Hi,
I tried launching the RT execution trace toolkit and been ask to add the NI service locator to the exclusion list of my computer's firewall.
It appears that for LV 2010, the NI service locator is included within the SystemWebserver.exe located here:C:\Program Files\National Instruments\Shared\NI WebServer.
I added the SystemWebserver.exe in the exclusion list of the firewall but i still get the message asking to add the NI service locator to the exclusion list of my computer's firewall when lauching the execution trace tool.
Any hint?
I'm Using Labview 2010 under Win7.
Regards,
Guillaume
I remember getting this message (and reported it to NI in January, and they created CAR# 283235 on it), but the RTETT worked in any case.
I have learned since that:
1) The Windows (7) Firewall won't let things through even if it is turned off (or maybe the default is not to allow data through).
2) When using a wireless connection, I have run into problems (different problems, I think) when I didn't set the type of the network (Public, Work) to the correct value.
Paul
-
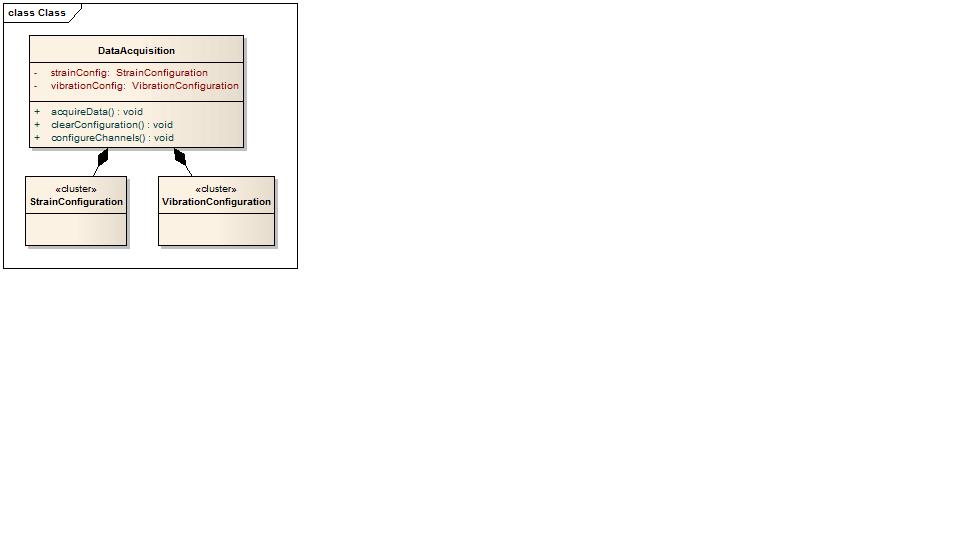
The way I do this is to use composition. That is, make the configuration elements attributes in the class that needs them. (You can use the same configuration in multiple classes.)
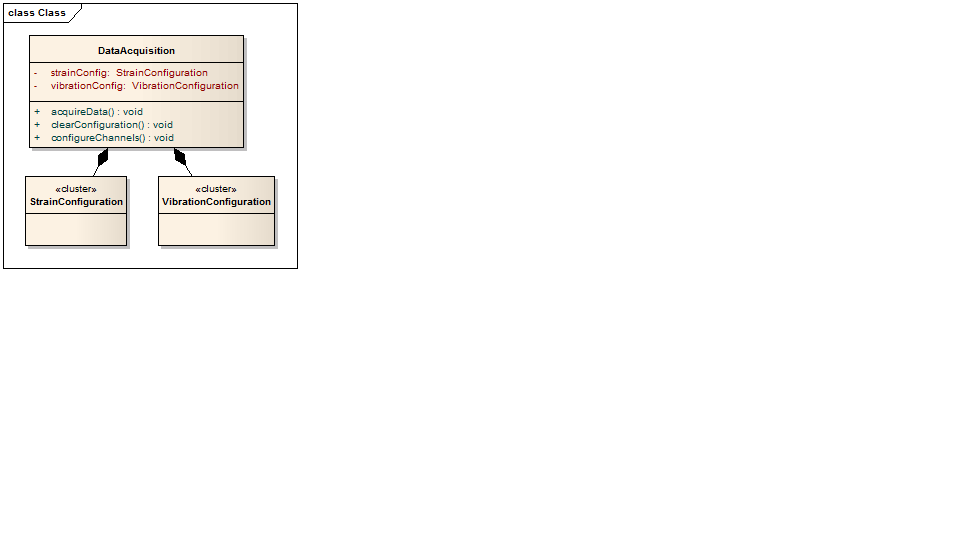
In the image, then, I have added the configuration clusters as attributes in the DataAcquisition class.
Notes:
I have made these clusters, instead of classes, since in practice I just need to read and write these from a file and I have developed a library to do this, so I don't need to define any methods on the configuration items themselves. (Using clusters means I don't have to use accessor methods, for instance. These are just data.) I define an init method on the class that needs the data (could be part of the DataAcquisition:configureChannels method, in your case, preferably a separate method, though, even if private) that calls the common method to read the files and casts the results to the cluster types. You could opt to use classes instead of clusters for the configuration items, though, if you wish (just change the definitions of the clusters to classes!).
I initially defined a ConfigurationHandler class outside my main classes, and put the various configuration classes (they were classes at that time) in it (very similar to what you have done). The thought was that the configuration would only exist in one place. This works but it quickly prompted questions about the relationships with the model classes and never seemed to have a proper place. I eventually transitioned to the compositional approach I have described and I am much, much happier with it. I very much like my current approach. It is simple and repeatable, and data is where it needs to be.
-
We decided to sponsor a senior computer science Capstone project at a university this semester. We suggested (but did not require) that the students use LabVIEW for the implementation. The students expressed an interest in LabVIEW and went with it. We gave them a brief tutorial on LabVIEW and Object-Oriented programming in LabVIEW. The students completed an Object-Oriented implementation of the application.
Anyway, the students just gave their final presentation Friday, and in response to questions (and beforehand to us) said they had a very positive experience with LabVIEW and graphical programming. The biggest hurdle they mentioned was learning how to do programming by-value and not by-reference. (I had mentioned Data Value References to them--for full disclosure--even though we have yet to use one ourselves, but they stuck with by-value objects.) Anyway, they did a credible job and I was happy to hear they liked LabVIEW after working with it on a real project.
Has anyone had a similar experience?
Also, we had a positive experience working with the students and the university, and we encourage interactions like this with academia!
-
You can extend your beta as many times as you want, the only thing you need to worry about is some sort of contract such that your executable knows where to look for these extra classes at run time. In the case of the executable I half cheated by having you pick the path, and the exe then looks for a *.lvclass file with the same name as each folder contained in the folder you point to. I'm sure you can dream up something much more sophisticated, but I hope the example gets the point across?
Have fun!
-michael
Michael,
Thank you for the comments, and for taking the time to put together a wonderful example!!!
As I just noted in my comments to Michael A., I especially like that you can exclude Beta from the plug-in builds.
My colleague and I, in the meantime, were focusing on what we could do with LVLIBPs. He sent me the attached file with the following instructions:
"Instructions:
1. Unzip attachment
2. For each lvproj, in the order specified below: open it, run the build, then close it PluginInterface.lvproj Plugin1.lvproj Plugin2.lvproj testApp.lvproj
3. Run pluginArchitecture/applicationBuild/testApp.exe
Notes:
Post-Build-Action VI's remove the unnecessarily created lvlibp files from the Support Directoy.
The build process automatically places them there but the application doesn't actually link to it, instead it seems to keep a relative link from the exe to the original lvlibp."
(Note that he actually created this example to report the LVLIBP linking bug--yes, yet another issue with LVLIBPs--to NI.)
Anyway, my colleague independently arrived at something that looks remarkably like the example you created in most essential ways, except that it uses LVLIBPs instead of source distributions.
What I like about this solution:
1) We can build into a single LVLIBP file (this is a big plus).
2) An LVLIBP is truly compiled and we can distribute it nicely as a plug-in....
What I don't like:
1) We are stuck with all the existing LVLIBP issues (until they are fixed).
2) I'm not sure that some of these issues aren't just bugs, but that LVLIBPs may have ontological issues of their own....
3) The Plug-in Interface is part of the Plug-in build, I think. This isn't actually a big deal in our situation, but it certainly does confuse the situation, if nothing else.
I'm curious to know what you think of this solution....
Paul
-
I would think that source distribution is your best bet. If you don't like the detailed hierarchy then you may use llb as your destination. You can put each class into separate llbs.
If you want to use the EXE method that I think you would need to run the EXEs and communicate to them with an application reference mechanism and VI server calls. Not sure what you did exactly in the EXE implementation.
Michael,
Thank you for the helpful hints.
I'm on the fence about whether a source distribution is really the best answer. It may be we find this is the best answer currently available (I'm still evaluating that), but even if that's true it seems that there should be a better option. I will say what I know about the pros and cons in a moment.
Anyway, I actually had already asked my colleague to try putting Gamma and Delta into LLBs. Note that these are not actually single classes, but hierarchies of classes in LVLIBs. My colleague did this but found that to avoid namespace collisions LabVIEW put some of the files outside the LLBs so the distribution is still quite messy (yuck!).
I think you are quite right about having to use some sort of communication between EXEs if we went with that approach (and I'm intrigued by the method you suggested--we haven't tried that yet). Since we really want one application, I'm thinking this is not the way we want to go*.
*But if we don't find something else...
OK, more about source distributions in this context:
The pros:
1) Works.
2) Can exclude Beta from the distribution (see mje's example), which I will reply to next.
3) Relatively easy to build.
My concerns about doing a source distribution:
1) Performance: I know (especially if we strip the diagrams), the code is compiled, but I'm not sure there isn't a cost. (Actually, I expect there is a load cost, but I'm guessing there isn't a performance penalty in execution once loaded. I'm guessing, though.)
2) Ontological: Even if we strip the diagrams, we are still delivering "source" code in some way, and this just seems undesirable on an existential level. When I install something to run with an executable and the RTE, it just doesn't seem right somehow to make this source. Maybe the distinction isn't all that great in practice....
3) Complexity of distribution: At least in some cases (like ours), it doesn't seem possible to package the source distribution neatly. We always end up with multiple files. (Yuck!) I consider this the biggest issue at the moment....
-
Hmm, I've read through this a few times now, and I must be missing something. Why can't beta be a distribution which alpha, gamma, and delta all depend on? Is there a need for alpha to be aware of gamma/delta (I assume that since beta is an interface, the answer is "No," but I thought I'd ask.
OK, I've been going over your response and every time I think I understand it, I realize I admit I don't.
I will start with the last question first, since it's the easiest! Alpha (the top-level application) indeed does not know about Gamma or Delta, except that it thinks they are instances of Beta.
So... can you clarify what you mean by making Beta a distribution? I took this to mean that I make Beta a packed project library, build Alpha talking to this, and then somehow call Gamma and Delta at run-time (from Beta). Now I'm thinking that is not what you meant, though.
Hmm.... Maybe you mean we build Alpha with Beta (in a packed project library)? Then we build Gamma and Delta, where the parent is Beta inside the first packed project library. I still don't see how Gamma and Delta end up in the application at run-time (without rebuilding Alpha).
Will you be willing to clarify?
Paul
-
- Popular Post
- Popular Post
I have written a paper on the Strategy Pattern (with appendices on Interfaces and the Factory Method Pattern) in the hope that this will be a useful guide to others.
We have published a PDF version of the paper:
and a zip file that also includes the source and model:
StrategyPatternWithLabVIEW--WithModelAndSource.
You can comment on the paper here, if you like.
Paul
-
7
-
OK.
We have a message broker (compiled in C) that we use to send and receive messages to external systems.
We wrote a messaging component (call it Alpha) that connects to the broker (via a dll) to read and write messages. Now the messages are in XML format, and the messaging component delegates the task of translating the messages to another component (call it Beta). Let's say for simplicity that Alpha invokes Beta.readFromXML and Beta.formatIntoXML methods.
This works. Now we want to use this for other subsystems, so we need to include some version of Beta, where the implementation of Beta is specific to the subsystem. Hence we chose to make Beta an interface, and implemented Gamma and Delta classes to handle messages for Subsystem1 and Subsystem2, respectively. Gamma and Delta each include overrides of the Beta.readFromXML and Beta. formatIntoXML methods.
OK, but we only want to release Alpha once (as v1.0). We don't want to rebuild it every time we add a subsystem. (For one thing, the builds take an absurdly long time for reasons under investigation on a support issue with NI. More importantly, we don't want to keep rereleasing a piece of software if it already works, because our project team members will think we never have finished it.) What we want is to run a single application (Alpha v1.0) as an executable and dynamically load the appropriate instance of Gamma or Delta (or maybe a future Epsilon class) that we build separately.
OK, so we (my colleague, actually) have tried the following:
Building Gamma and Delta into executables, exposing the readFromXML and formatIntoXML methods. This hasn't worked to date, although I'm not sure if there is or is not some strange way to make this work somehow. I'm not sure it will since we really want the Beta or Gamma object, not call a top-level VI.
Building Gamma and Delta into packed project libraries. Despite our horrible experiences with lvlibps, we decided to see if they would work here. (We have found packed project libraries are just awful in LabVIEW 2010 but we look forward to using some version of them when they reach a releasable implementation. I'm actually quite surprised they were released in their current state.) Alas, they don't, since when we build Gamma and Delta into a packed project library the build also includes Beta (since it is in the dependencies) and we have no way to reference Gamma or Delta properly from Alpha, then.
Building Gamma and Delta into a source distribution. This works, my colleague tells me, but there are serious drawbacks, I think. First, this is not a proper build with a version number, for instance. So it is not proper to release it. (Yes, it is still possible, but it's a super-messy maintenance option.) Second, the build on disk contains a complex hierarchy with all the dependencies visible, which is highly undesirable. Third, since it is a source distribution it is unclear to me what the performance will be, and performance is important in this application. (Maybe the performance will be just fine. Can someone clarify this for me?)
My colleague has done a variation on this by creating a zip file, and then only temporarily unzipping the file as long as necessary before deleting the unzipped files. This is a really clever approach, but it masks the fact that we are still doing a source distribution instead of a proper releasable build, and the question of run-time performance lingers.
So... has anyone found a good way to do what we want to do?
Thanks!
Paul
-
Thanks guys, I am definitely here to learn too,
Where do I find this option? I can't see it in the Variable Properties Dialog?
It's an optional parameter on NI_DSC.lvlib:Request Value Change Notifications.
-
1
-
Examples: Messaging with objects, Command and State Patterns, configuration with XML
in Application Design & Architecture
Posted
I updated the link in the original post to point to the new location on our server.