

PaulL
-
Posts
544 -
Joined
-
Last visited
-
Days Won
17
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by PaulL
-
-
OK, I will ask again what I think is an obvious question here: Why doesn't NI include a native feature to serialize LabVIEW objects in an exchangeable way? (Alternatively, why doesn't NI provide enough access to allow a third party to develop such a framework?)
For me, "exchangeable" definitely means in a manner that allows the data to shared between platforms. (Hence having "default data" without specifying the values of the default data is not allowed.) Moreover, using a more common format (such as "Simple XML" is appropriate.)
Of course, including the object version number is only meaningful within LabVIEW, but this is useful within LabVIEW thanks to the LabVIEW objects capability to translate between versions. (Note: I recognize the versioning can't avoid all possible issues, but in practice I think that is rarely a practical issue.)
I understand that for security reasons a developer may want to turn off the ability to serialize an object. To support that, I envision a checkbox to allow serialization (default = True) in the class properties dialog.
I think XML is the best option for this for several reasons:
1) It is a common way to serialize objects in different environments. This means that I can exchange serialized data with Java applications, for example.
2) It is readable, albeit not easily readable, by human beings. (I actually don't want humans to read serialized data very often--and really never the operator, but it is good that they can on the rare occasion when they need to do so.)
Why I think NI should implement this:
1) This is relatively straightforward for NI to do since NI can already serialize a class to the current (noninterchangeable) LabVIEW XML format.
2) Having this capability would greatly expand the application space of LabVIEW, since it would make it orders of magnitude easier to interface with nonLabVIEW applications. This is by far the most compelling reason to include this feature.
3) That there is a need for this is quite obvious, given the number of lengthy discussions just on LAVA about this topic.
4) The current situation, in which each class must contain specific code for serialization, is patently inefficient and nonsensical.
5) In other major languages meaningful object serialization is a given, and LabVIEW should include (indeed, must include) this functionality to be competitive.
For the record, to serialize LabVIEW object data for communication within LabVIEW we use either the methods to flatten to string or to XML, and this works fine. I realize it's not theoretically 100% fool-proof, because of potential issues across different object versions, but in practice we use version control, so that we build applications using the same versions of interface code (usually), and we only have one large system, so we can pretty easily control our deployed applications. (I think that versioning an application could achieve the same.) In practice, we've never experienced a version problem with this approach, and it avoids having to write any class-specific code (which, again, a developer should definitely not have to do) to support serialization.
-
 2
2
-
-
Oh, are you "paul.dct" on NI.com?
Yes.
-
I greatly prefer the icons (as James knows) because:
1) They are easy to see. I am very focused on the interface and I want the terminals to stand out.
2) They sometimes contain additional information, and I consider them more aesthetically pleasing.
3) Saving space is not a concern because of the way I design my applications. A class method (and very nearly all my VIs are methods in classes) usually has the terminals for the owning class, error terminals, and maybe an additional input or output (occasionally a couple of each). I have plenty of room for these on the block diagram, and I want them to be highly visible.
-
2
-
-
Hmm..., I'm not sure how much like you will have, at least with the specific term "design pattern," since Gang of Four introduced the term (if not the larger concept) in an Object-Oriented context. In any case, this looks like it might a good place to start: http://en.wikipedia.org/wiki/Design_pattern_(computer_science) .
(It might be easier to learn a little about OOP.)
 You're right, it's nontrivial to get started with OOP. I wouldn't go back, though! Maybe there will be something even better than OOP around the corner?
You're right, it's nontrivial to get started with OOP. I wouldn't go back, though! Maybe there will be something even better than OOP around the corner?It certainly is true that it is possible to implement some of the concepts and some of the patterns in nonOOP terms. I don't know that there will be much literature on that, though....
-
For Agile, we use Greenhopper: http://www.atlassian.com/software/greenhopper/?gclid=COKzjtfI46sCFWwZQgodR3_eMg.
-
Thanks for the responses, gentlemen.
-
Well, I know (at least at the detailed state level) we may have to make system-dependent choices.
On the other hand, I think there can be a consistent approach (at least by having consistent criteria for distinguishing between cases) to high-level states for certain types of systems.
One example:
Component A supervises components B and C. C reports a fault. Does A report that it is in fault state (even if C's state is always visible to the user.) What, if anything, do we do with B in this case?
We are revisiting this because, while we have something that works in one large subsystem, another subsystem presents a different set of issues that we could solve the same way but for which we also can make a strong argument for choosing a different solution. We are looking for a firmer basis on which to discern which is the better solution.
-
We designed our system components with five states: Off, Standby, Disabled, Enabled, Fault. (We didn't base this off a standard, but we did have some examples.)
A given component may have one or more subcomponents. A subcomponent never cares about the state of a supercomponent, but a component may care about the state of a subcomponent. We are actively debating how much so, though. In particular, if one of component A's subcomponents is in FaultState, does that mean that A is also in FaultState? We have to date answered that question one way (successfully) but now we are revisiting this.
I have searched without any real success the last couple days for a great paper, book, example, or standard that will help here, but I haven't found much. Maybe I don't know the right keywords. Does anyone here know of a good reference?
-
Some causes of "dirty dots" of which I know (as of LabVIEW 2010):
1) Calling "system VIs": http://digital.ni.com/public.nsf/allkb/D4032A485C9F18C1862576D6007681F4
2) Opening a copied RT VI (i.e., in a new location on disk) with an FPGA VI reference (nondynamic).
3) A dirty dot appears in the project if you open a library (e.g., class library) where the contents are set to (Custom?) arrangement. Changing to Arrange by Name fixes this.
4) Changing a strict typedef in the private data of a class in one project may keep making you save a different project that uses the class. I usually make a trivial change (e.g., arrange horizontal then vertical again) to force a recompile. Then we're OK.
5) As Ben already mentioned, using autopopulating folders causes this a lot. We only use virtual folders anyway.
I'm not sure any of these apply in your situation.
-
2
-
-
We, too, would very much like to serialize objects more easily.
We actually do serialize objects to XML now, but we write a serialization method for each class (and this method calls the parent method, if applicable). Writing a custom method for each class is a fair amount of work and undesirable when there opught to be a framework that supports this automatically. (Note that the native XML functions do provide a framework that serializes objects, but the XML format is not satisfactory for all purposes, as stated elsewhere previously. In particular, if an object has a default value the generated XML just says that, rather than specifying the actual values, which makes the XML output to any application that doesn't have the exact same class definition. NI could just make a new version of their XML VIs that would format data better--which is probably pretty easy--and that would probably be a fine solution for many of us. In the meantime LabVIEW developers need to do this, and that is I think why we are having this discussion.)
Using a cluster within an object will also work (we do use this approach, actually, with configuration files, although for this purpose we use the native XML VIs), although it doesn't support (I don't think) writing parent data or objects within the cluster. More importantly, there ought to be a way to serialize every object, not just a cluster within the class. (Using a cluster does negate some of the points of using an object in the first place, like maintaning history, although this is more important in some situations than others.) Mostly, I don't think developers should have to do this. It should be easy (trivial, actually) to serialize objects, in my opinion, to an interchangeable format such as XML. (Java and other languages have frameworks to do this. Why don't we?)
-
2
-
-
It seems to me this is exactly what I described, with the exception that technically you can still edit the constant value. You can even make the icon small and everything!
Yes, you and Tim_S both described just using a VI with a constant on the block diagram (wired to an indicator, of course), and I don't see any reason why that wouldn't work fine, especially in-lined. Sounds good to me, at least! I'm just a little slow today! :-)
-
2
-
-
OK, yes, I see and agree.
So, then, we would really like to duplicate the behavior of the constants on the Math & Scientific Constants pallette. Sure, I'd like to know how to do that, too.
-
OK, this might not be the answer you want, but why not use a configuration file (and then wires)? Isn't that really the better answer? (Then you never have to update the value in the code.)
-
1
-
-
I thought a little more about this and realized I missed what I consider to be an important point.
Another reason I don't use default values to set information is that in case the values need to change, I don't want to recompile my code. I put this information in configuration files (XML configuration files, by the way) so that if the values change I only have to update the configuration files, not the code.
Paul
-
I think I am probably saying pretty much the same thing but in different words.
We usually put an object constant on a diagram, but where appropriate the first thing we do is call a MyObject.init() method. This method initializes the object values where required, usually reading the values from some sort of configuration file.
Further, we never explicitly set the default values in an object control. We don't rely on the default values in any way, since there is no easy way to enforce these don't change and really no indication that they did. Therefore we explicitly set values as we need to in an initialization method (otherwise we treat them as undefined). This is much easier to read and far less risky. It is true that we don't have a way to force someone to call this VI, but everyone on our team knows to do so. (It's pretty obvious where and when to use this in our case.)
I realize that it might make sense to do this as part of a constructor, but LabVIEW doesn't support that directly (although jgcode demonstrated a nice way to do just that). We do instantiation plus initialization by convention to accomplish the same goal. I will say jgcode's constructor method approach has the advantage over mine in that one could have the convention that one must only instantiate objects via a constructor method.
-
Am still hoping to tag only VIs that are part of an application being released...
You are correct--Subversion does not know anything about LabVIEW dependencies so the tagging process by itself won't sort this out for you. (I expect it is possible but nontrivial to do this with scripting--I haven't tried.)
For our way of working this is not generally a problem. Since all our VIs or controls are in collections (always in a folder--almost always in a class and maybe a project library) I just need to pick the directories to include. (In your example, I wouldn't choose the "utility" directory but the relevant subfolders.)
...
OK, strictly speaking it can make a difference in that I may later change code (a VI, a class, a library) that is part of the tag but that I don't use in my application, so that I might think I need to do an update when I don't strictly need to do so. I guess the question is how does it affect the use case? For us, not much, but maybe there is a situation where this could be significant.
...
I do think it would be cool if there were a tool that traversed the project and automatically included all the items in the project and the dependencies for tagging. It would also let me work with one version of common items in one application and another version of those same common items in another application simultaneously (which the tagging and externals combination does), and make it easy to branch from the retrieved code.
Hmmm.....
-
We are pondering exactly the same question. We have a Common directory that has code used in various applications.
I did quite a bit of searching on-line and decided the most complete way to handle this in Subversion is with Externals. Essentially, we can add Subversion properties to the directory for each application, where each property is the (absolute) path to an external directory. Subversion puts a copy of the external directory as a subdirectory of the application directory. (Yes, this means the applications need to relink to the files in the subdirectory.) (The new copy still links to the original repository directory.) When we tag the application, we can put a revision number in the externals property so we get the specific version back the next time. (If there is no revision number, Subversion just retrieves the latest version, which is not the idea when we are creating tags.)
There are at least two caveats:
1) Subversion doesn't put the revision number in for you. This is a manual--and error-prone step.
2) If you ever restructure your directories, you will need to redo all the externals properties (I think).
We have concluded that this will accomplish the goal (I tested it with a sample project), and it isn't too difficult to do. It is error-prone, however, so we are discussing whether or not to handle things this way....
-
We just implemented (testing now) the top-level component of the active optics system of a research telescope. This component calculates, based on feedback from a wavefront sensor and other information (mount zenith angle, various temperatures, etc.), demand bending modes for the primary mirror and demand positions for the primary or secondary (depending on the optical configuration). Separate components (which we already completed and tested) actually control the mirrors.
-
One thing that confuses me about your post though:
How does this happen? If for each Model you have a corresponding State (whether the State is contained in the Model itself as in my example, or part of a parent Context as in yours), isn't it the State's instance that is deciding which onInterrupt method to call when the request is delegated to State:onInterrupt? Of course that call could end up working it's way up a State class hierarchy, is that what you are referring to?
All I mean is this:
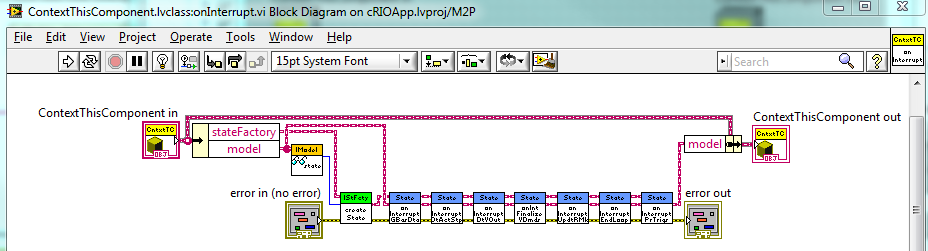
We have appropriate overrides for each of the State methods. This means the Context's version of onInterrupt is slightly more complex, but it allows us to break down the State behavior into smaller pieces, which makes the State methods many times simpler (and hence easier to maintain).
Paul
-
OK, I'm very curious to know where you found the Friends relationship useful (but that is probably a topic for another thread).
Yes, the factory method pattern may use a case structure (ours does) but we are still using dynamic dispatch on the State methods, which is the important thing. We first used the factory because we needed to resolve the build issues, but we found we like it because reducing code dependencies helps separate the code in general. I understand your objection, though. In my experience having one factory method has been a positive trade-off, but in all fairness if the LabVIEW compiler handled interdependencies better I probably wouldn't bother.
You are quite correct that the states do not need to be the place where the application selects the next states (the Gang of Four book lists this as one option), but I think it is important to reduce the interdependencies wherever one puts that decision code. (We found it simplest and most consistent for our applications to put the state decisions in the state methods.)
I also agree that one does need to create rather a few methods to implement an application using the State Pattern. The end result is so clean, though (and each method is so simple), that we have found it well worth the effort.
-
OK, I finally noticed you had attached code.
Right. LabVIEW doesn't like it when State can change Context--there is no guarantee that the class in is the class out. I think that using the Preserve Run-Time Class method might help here, but I suggest instead that you reconsider how you use the states.
When we first implemented the State Pattern, we had just one State.execute method, and then overrode it. Partly this was because we had a loop that executed when an interrupt occurred.
This was a mistake, we discovered. In particular, we realized onInterrupt can be a trigger just like any other trigger. We ended up making multiple methods, something like this:
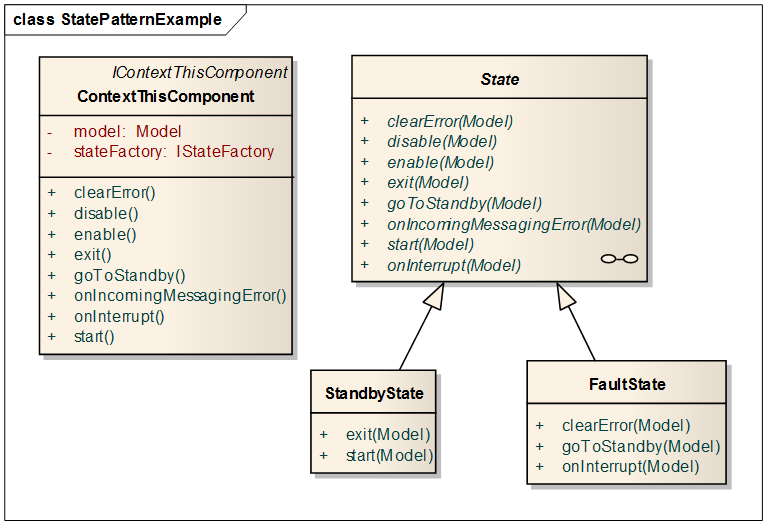
(Simplified version. In an actual system we have more states and a few more methods.)
This is orders of magnitude more flexible and lets each State method do one thing. (We also don't have to repeat code in substates.)
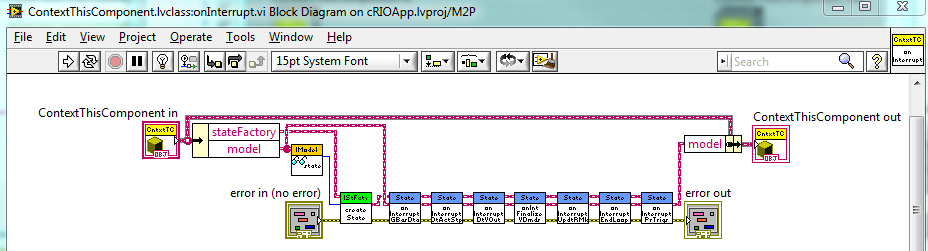
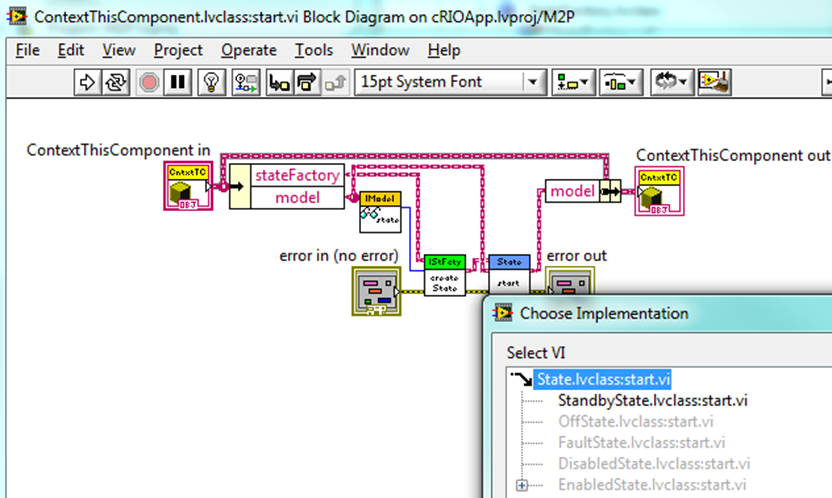
One fine but important point: ContextThisComponent.onInterrupt actually calls several State.onInterrupt methods [onInterruptGetBasicData(), ..., on InterruptEndLoop(), onInterruptProcessTriggers()], which allows for even more flexibility.
The loop runs when an external trigger (a command from the View, or an interrupt--also a command) arrives. In each loop we call the appropriate Context method (which delegates to the State) and it returns directly. Hence we don't need a Return method.
We do need to preserve the Context run-time class, though. Here is how we do it:
Paul
-
As François suggested, you might want to reconsider the class design itself rather than trying to force a specific method to run in some strange manner. If you explain what it is you are trying to do, perhaps we can help devise a straightforward way to achieve the goal.
-
I think you hit on most of the key topics with the State Pattern.
I have a few hints based on what we have discovered:
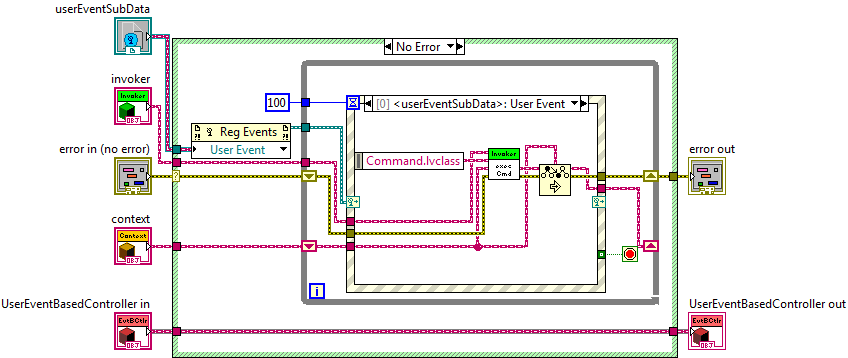
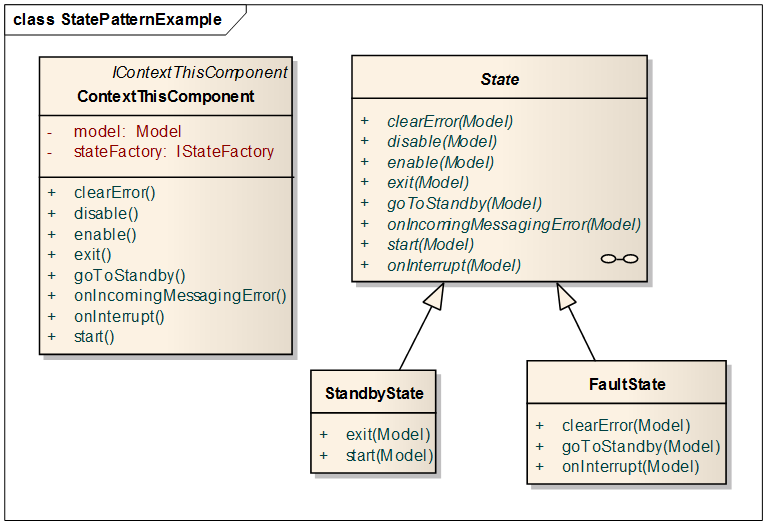
1) We also considered making the State classes friends of Context, but we decided not to do that. (For one thing, one has to set up such a relationship for each concrete State class independently, which is not fun. OK, I will go further and say that I don't think the Friends concept is a good idea in general--I consider it a strange solution to a problem that one can better address other ways, and we don't use it.) We did, however, want to have an IContext interface that had only abstract methods, and we wanted to have some methods the State methods could call, and we didn't want to mix the two. (We wanted to have two distinct interfaces.) In the end we made a separate IModel class (an idea a smart colleague suggested) that we put in the private data of Context, and the State methods invoke IModel methods. We have been quite happy with this approach.
(The image is from one of the slides in my NI Week presentation.)
2) Note that Model stores the current state information, but not as a state object directly. Rather, we store an enumeration and then use the Factory Method Pattern to create the actual concrete state object. By doing this we make sure the different states do not know about each other, greatly reducing code interdependencies. This reduces build times and dramatically improves the robustness of the build process. (We had working code that did not build when we used the objects directly.)
3) Note that we have lots of Context methods, at least one for each external trigger. For each Context method there is at least one corresponding method on State.
After a cursory read of your discussion, I'm not sure I completely understand or like what your Context:Return method is doing. Maybe what you are missing, though, to address your specific concern is a Preserve Run-Time Class function.
Paul
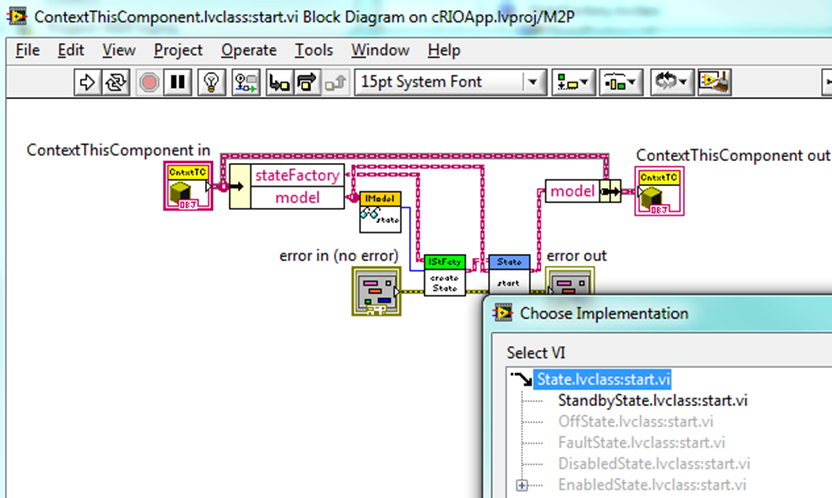
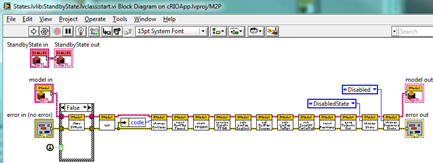
For the record, the StandbyState.start() method looks like this:
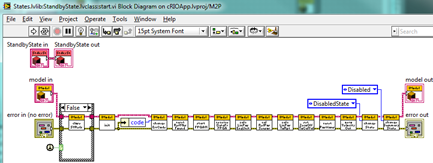
The important points are that the state methods have IModel as input and output parameters and invoke IModel methods to do the actual work.
Paul
-
You could:
Create an acquisition application and run multiple instances of it (on your 3 or 4 computers).
Have each of these publish the data.
Create a View application that runs on another machine. The View subscribes to the data published by the other applications.
Notes:
1) Networked shared variables will work great for this. I recommend putting the published data for each acquisition system in a uniquely named library.
2) If you want to send a message from the View to a specific instance of the acquisition applications, you might consider including an instance identifier in the message. This probably won't be necessary, however, if you create libraries with unique names.
Paul
Serializing aggregated objects?
in Object-Oriented Programming
Posted
By the way, we don't use objects directly to store configuration information any more.
We started out having a Configuration Handler class that contained classes with different specific configurations. We moved away from that since:
1) A LabVIEW class does not have a control (natively) associated with it. A cluster (or any primitive) does. We need the control for the configuration editor view.
2) In practice, configuration data is just flat data. A primitive or typedef is perfectly capable of representing this. The only advantage I can see to using an object is the ability to remember versions, and this is in practice not worth the trade-off given the limitations of LabVIEW objects with respect to 1 and 3.
3) We can easily and directly flatten data to a file (e.g., XML) if it is a primitive or a typedef.
So, what we have for each application is a set of items (almost all are strict typedef'd clusters, but even primitives are just fine) that we write to a corresponding set of files. (Each typedef saves to one file. Each typedef defines a group of closely related values, e.g., compensator parameters.)
Each class that uses these parameters has an an associated initialization method. Thus, Compensator.init() reads compensatorParameters.xml. Each class may read multiple configuration files, and more than one class can read any given configuration file.
Yes, there is a trade-off here because clusters do not have version memory. In practice, though, we have encountered zero issues because of this limitation, and the advantages of this approach have been many.
For clarification, our configuration editor is an Object-Oriented application, but the configuration items are not objects.