

PaulL
-
Posts
544 -
Joined
-
Last visited
-
Days Won
17
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by PaulL
-
-
Your answer reflects pretty well where I am in my thinking at the moment. I had the feeling I was slowing myself down by taking the "cohesion", "coupling" and "encapsulation" ideas WAY too seriously and trying to do everything without coupling any two classes..... This obviously gets very hard very quick. Interdependency is OK as long as it serves a common purpose I suppose (coherent). So coupling is OK as long as the coupling takes place coherently?
Shane
I should point out that in the configuration files example the View writes the control reference to the Model object (the Command) dynamically at run-time. That is actually an important part of the design. That way I can use any collection of controls I want, without editing the Model code in any way whatsoever. So the Model is still essentially independent.
The alternative is to write the control data to the Model instead of the reference. Then the Model can send updated data (from a file, for instance) to the View, which can handle updating the control in turn. I decided that:
1) since I was using XML it was a little simpler to use the reference
2) since for this application the View will always be the same (just with different controls, which the solution handles gracefully)
it was OK for the View to pass references to the controls to the Model.
Note that in other situations, e.g., where we have a component Controller that may interface with View A, View B, or another Component (which we do all the time) we don't pass references, only "pure data," since the references would not be meaningful in all application contexts.
Paul
-
 1
1
-
-
Are you able to do a real-time execution trace? You should be able to confirm or deny the theories you propose with the information from a trace.
-
Without the free events the DSC module provides everything becomes more complicated.
....
AE's are still restricted in scope to the specific application aren't they? If you're running from source code it will execute in that project's context. If you've compiled an executable the OS executes it in it's own app space. Am I missing something?
I just saw your edited post this morning.
On the RT side we generally poll the current values of the shared variables upon receipt of an interrupt from the FPGA, so we aren't using shared variable events there. It's still quite straightforward. Events offer greater flexibility, however, and using them we can do reads only when we have new messages.
No, you aren't missing something--I was. I ran my tests in the development environment, where the scope of the FGVs included all VIs (applications) in the project. If I build the VIs (myApplication, otherApp, otherApp2) into separate executables then the FGVs don't share the same application space, as you point out. That is a a correction to what I wrote but the point is still the same--someone reading the code must know what all FGVs in scope are doing in order to comprehend what will happen in the application when invoking an action. For instance, if I build largeApplication containing calls to myApplication, otherApp, otherApp2, these all share the same scope.
Paul
-
Shane,
I'm not sure I will quite answer your question, but I will try.
In the case of the configuration files application, when the user clicks "Save" the View application passes data in an object to the controller. You are correct that the object does not (at that point) contain the specific data for the control in the object. In this case I opted to implement this by including a reference to the control in the object, and then I use the reference to read and write the data. (I needed the type as well the data values in order to implement the XML reads and writes.) In this case decoupling isn't absolute, but still nearly so and I think this is a reasonable trade.
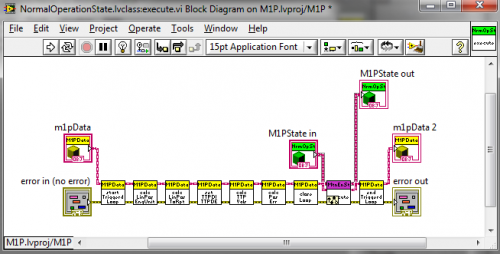
In the State Pattern examples, however, all the actual data is in the <Component>Data Model object. (The object is actually a complex composite.)
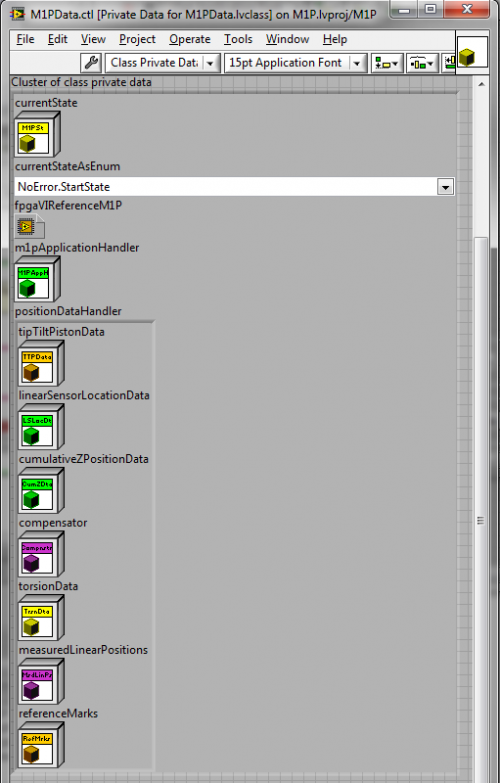
It is straightforward to read or write <Component>Data in the Controller when I need it.
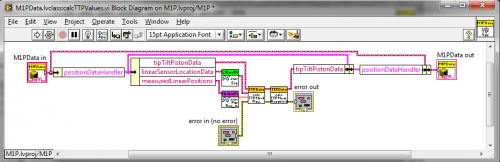
I define external interfaces to share data with the View or external applications. In my implementation the data communication is via shared variables.
[Aside on a fine point I noticed: In the next application I decided I could merge the funcationality in startTriggeredLoop and endTriggeredLoop into one method executing at the end of a loop, which made it easier to inherit and override cleanly.]
Is this kind of what you are asking?
Paul
-
Single process shared variables can be used to communicate between VIs as well as within a VI. Referring to Using the LabVIEW Shared Variable, the key is that the multiple VIs be in the same application instance. This is the feature I'm trying to use.
You are correct. I didn't read the whole sentence correctly and, well, it reveals I don't use single-process shared variables. (We always use the networked versions.)
When we use networked shared variables in two projects we can alias one to the other (so LabVIEW really does deploy two libraries in that case), but I don't know what to do for single-process shared variables. I don't know why LabVIEW wants to deploy multiple instances of a single library if there is only one library (and one application instance) in the project. I would definitely agree it is time to call NI! I wish I knew more!
-
Martin,
I'm not sure I understand everything you are doing, but, yes, using single process shared variables might be a cause of the issue you see. Use single process shared variables only to share data within a VI. (See Using the LabVIEW Shared Variable.)
For the record, you can use networked shared variables to communicate between processes running on the same machine as well as on different machines. (The communication performance will just be better if everything is on the same machine.) (Hmm.... I don't know that you couldn't use networked shared variables to communicate within a process--I think this would work but that certainly is not their purpose.)
(A bit of a tangent: I just realized that pretty much if two things really have to run in parallel and communicate with one another I make them separate processes anyway.)
Paul
P.S. I liked the pun.
-
Jon,
Sorry for the late reply. I think I somehow missed your message while I was at the conference. Probably you've progressed well beyond this point by now! :-) Well, I will answer what I can anyway....
I haven't used the LabVIEW Statechart Module, although I did look at it on-line. I thought it was pretty cool. I've learned to do the same sort of thing manually using the Object-Oriented State Pattern easily enough, so I haven't pursued using the module. (The Statechart Module doesn't use an Object-Oriented solution--or at least didn't in its inital release.) My other concern was that I don't think theStatechart Module lets you see and edit the code it generates (understandably) but maybe this isn't really an issue. (I guess I like to see and edit my architecture code.) Anyway, the Statechart Module impressed me but I don't have any more experience with it.
I found the hardest part of M/V/C is to understand what the Model is. I look at it as the state of the system. Usually I end up encapsulating it in a classed called something like <Component>Data. It (or its member classes) comprise all the data for the component and all the behavior associated with it. The Controller figures out what to do but it delegates all the actual work to the Model, since it has all the state information and associated behaviors. In practice I initialize the Model object at the beginning of the Controller execution, and then update the Model on a shift register on the Controller's loop. The Model isn't a application itself. The Controller invokes the Model's methods.
Paul
-
Jon,
I finally posted my document. See the thread here: examples-messaging-with-objects-command-and-state-patterns-configuration-with-xml.
-
- Popular Post
- Popular Post
OK, I finally finished a version of a document I have been promising to write. We put it on our site: OOMessagingCommandPatternStatePattern.
In it we present examples of the following in LabVIEW:
messaging with LabVIEW objects
Command Pattern (with XML configuration files application example)
State Pattern
Hopefully the examples will be helpful to some readers, and promote further discussion on scalable application architectures.
-
12
-
Exactly! This sets up publish-subscribe communication, in which multiple subscribers can receive the same published data. LabVIEW supports this (though not necessarily using objects) natively with networked shared variables configured to support RT-FIFOs.
-
We use the Unified Modeling Language. I highly recommend Enterprise Architect as a tool.
-
I worked on putting something together this afternoon. There is a lot there but it's not quite done and I need to review it.... I'll put something up soon. (It probably won't be finished but it will be something to start.)
-
Bingo. Absolutely correct. Unfortunately, that trick is not on the roadmap at this time.
I understand the problem here, and agree it is quite challenging. On the other hand, breaking all callers when converting to a library (.lvlib) seems quite undesirable, too. I think it sure would be good to have a solution in mind when planning the future.... (Even if this is a simpler way to relink broken calls that would be good. That might be harder than resolving the actual namespace issue, though.)
-
Personally? I would prefer the fully qualified name be displayed, as in "X.lvlib:Y.lvclass" and alphabatize the list by the entire string.
I think that's fine. I hope classes not in .lvlibs appear before or after, not intermingled, though.
-
1
-
-
Hi Paul
Are you able to, and do you have the time, to post up examples of your Command Pattern and State Pattern using LVOOP?
Cheers
-JG
Yes, I already promised to do this for the Large LabVIEW Application Development forum and I haven't forgotten about it. I will try and find a minute to post something tomorrow; if not, this weekend.
-
My thoughts:
I haven't frequently had classes with duplicate names in the same project--although it has happened in some of my projects and probably will happen more often--so on the rare occasion when I have seen this I don't mind just looking at the Path. Nonetheless, I agree it would be easier to see this information in the tree view.
It's worth noting that classes can only have the same name if they are in different namespaces (e.g., they are in different .lvlib files) so maybe the browser could arrange the classes by .lvlib namespace first? (I don't really know if that will work, but I think it might work pretty well.) [Edit: Ah! I see that jg-code already suggested this as part of the posted idea.]
Or perhaps there could be a check box to show or not show the fully qualified namespace in the tree view. (Which do we want? Both!
 Yeah, that would definitely make AQ's life more difficult.)
Yeah, that would definitely make AQ's life more difficult.) Anyway, I haven't encountered the situation much so that's all I've got.
-
1
-
-
Jon,
OK, I read through your description and I think you are on the right track. Everything sounds good.
I will make a couple comments:
1) Your UI and your controller should be separate applications (Model-View-Controller), not just separate loops. I'm fairly certain from your description that they are thus in your project, but it's worth emphasizing.
2) I understand most of your communication paradigm (I'm a little fuzzy on a couple points) but it sounds solid and I think it approaches something along the lines of the Object-Oriented Command Pattern. On that note, we have implemented the OO Command Pattern in LabVIEW. Messages are LabVIEW by-value objects flattened to strings and sent via a messaging system. In our case, we use networked shared variables for the communication mechanism. The advantages are that the interface is quite simple yet flexible, and that shared variables work over a network. (I personally agree that queued-statemachines--QSMs--offer an unnecessarily complex API at the application level. I think they are a step in the right direction, but there are much better solutions.) Depending on the controller's host (PC or real-time?) and design (hardware-triggered loop or not?) one can even register for shared variable events (but this requires the DSC Module) instead of polling. (We do both, depending on the application.)
3) You haven't stated what the performance requirements of the application are, but neither control references nor variants are likely to cause performance problems except in the most demanding applications. Any performance issues are more likely to result from something in the way the application handles the messages (e.g., missing messages).
4) You might consider using the OO State Pattern for statemachines still to be implemented. We've done this in LabVIEW, too. It wasn't easy for me the first time but now I love it and if you've done this in other OO languages you won't have any major troubles in LabVIEW.
Anyway, I think you're doing great! Good luck with the project!
Paul
-
I agree there's a lot of room for improvement in this area. I don't think it would be a "relatively minor" effort. I've talked to AQ about it in the past and it sounded like decoupling the namespace and library would have a ripple effect deep into Labview's internals.
OK, it could be a good amount of work. On the other hand, I'm not recommending decoupling the namespace and library. I actually kind of like coupling the two, since it means (I think) we can have identically named classes in different namespaces. What I would like is for LabVIEW to be smart enough to relink (or prompt the user to relink) methods after a conversion to a .lvlib (new namespace). This does require support across projects, but LabVIEW already recognizes the change and puts the .lvlib in the project and links the classes, so it's almost there. It just needs to relink the calls. It's not the highest item on my priority list (by far) but it seems like it's almost there, actually. (The last bit could be trickier, of course.)
Paul
-
A similar issue I have encountered recently is when I converted a hierarchy of folders containing classes into a library (.lvlib), since I used these in multiple projects. When I opened the other projects, the calls to the methods now in in the .lvlib broke (although the class hierarchy actually updated to point to the classes in the new .lvlib--it almost works). In this case I just manually linked the broken VI calls.
Note:
I could have avoided this by planning to use .lvlib files from the start.
The namespace really does change, so there is some sense in which this is expected behavior.
Nonetheless, it is another example where a relatively minor improvement could make code reuse more efficient.
-
One thing to keep in mind is a common design paradigm called Model/View/Controller. The idea is to keep each of these distinct. In particular, if the View is distinct from the Controller, it is simple to create alternative Views of the data from the same Controller. This is one reason why the Observer Pattern (a publish-subscribe paradigm) is, well, a Design Pattern.
LabVIEW makes it easy to put an indicator on the front panel of a VI and some control code on the block diagram of that same VI. This is OK for debugging, but it doesn't allow for easily scalable solutions, so, yeah...don't! MVC is much more powerful in this regard!
[This is consistent with two other design principles: loose coupling and tight cohesion. Essentially group things that really belong together in one place (tight cohesion) but separate things that should be independent (loose coupling). Decoupling the View from the Model leads to a system that is much more scalable and maintainable, because one can change the View, the Model, or the Controller without (necessarily) having to change either the other two. I recommend considering this when selecting a design solution, as some solutions offer this and others do not.]
[A brief discussion of MVC does appear in the introduction of the classic Gang of Four Design Patterns book in a discussion of using the Observer pattern and other patterns, but the details of implementation are really outside the scope of that text.]
-
You can also used networked shared variables.
For instance, create a shared variable of the proper type in the project.
Drag the shared variable onto the block diagram where you want to write the value. Change to write mode and wire it up!
Drag the shared variable onto the front panel where you want to view the value. LabVIEW will create a bound control. Change it to an indicator. (If you want to use a chart, you can add a chart and then point it to the shared variable.)
You can customize the properties of the shared variable for buffering and so on. (There is a lot more you can do here, but just doing this will satisfy the need you have expressed.)
Networked shared variables offer an advantage over the other methods thus far proffered (which will all work, by the way) in that the View need not be on the same computer as the Controller. Shared variables also use the NI Publish-Subscribe Protocol, so that it is easy to have multiple subscribers (e.g., multiple Views) for a message. [You can register for shared variable value change events as well, but this functionality (strangely and unfortunately!) is only available with the DSC module.]
-
I just sent a product suggestion to NI and added the same as a comment to an existing topic in the idea exchange:
Idea Exchange Link: Subprojects/Cross project builds
My text:
Introduce subprojects or packages as hierarchical elements in projects
Please introduce the ability to incorporate a project as a subproject or package within another project. This functionality is critical for effective code reuse and maintainability.
As an example of why this is important, I offer the following:
We have created a class ComponentData and a number of associated classes and other files. We neatly package these in a file structure on disk and in virtual folders in a LabVIEW project. [Note that we use virtual folders since in principle, at least, we can use a given class in different ways in different projects.]
Now ComponentData and its associated classes are common classes that we created precisely for reuse between components, each of which we define in its own project. We encounter an issue when we attempt to reuse ComponentData and its associated elements, however.
We can create a project (call it Component.lvproj) and attempt to incorporate this project into a new project for a particular component. This, however, is not useful, since it merely creates a link to Component.lvproj and does not import any of the elements of Component.lvproj into the larger project.
Alternatively, we can copy the virtual folder hierarchy containing ComponentData and its associated classes and other files into the new project. This does explicitly import the elements, but simply copying virtual folders in this manner does not support maintenance needs. While it is true that if we edit the class definition in one project it will update in all callers (each class correctly has a single definition), unfortunately other changes (moving or renaming virtual folders, moving elements between folders, and so on) we make in one project will not reflect in other projects. This approach is wrong in principle as well as in practice because we end up with multiple independent definitions of the same thing. (The definition should exist in only one place.)
What should happen is that we should be able to define a subproject or package and import it into a project, such that:
1) the package elements are now accessible in the larger project (portable)
2) any changes to the subproject or package will appear in all referencing projects (single definition)
3) any part of a particular package may itself become a subpackage itself (hierarchical)
[Note: As I write I realize that using autopopulating folders (which are inappropriate for the reason mentioned above) can satisfy 1 and 2 to some extent but not 3.]
A wonderful example of what I propose exists in a UML design tool we use called Enterprise Architect (and almost certainly within many UML tools). Within a given project we define a hierarchical layer of packages. (In UML each package, like a LabVIEW project, has an XML definition.) At whichever level we choose, we can choose to add a package to version control. (In our case the tool interfaces to the CollabNet client to a Subversion repository. The CollabNet client is open-source, free, and certified, by the way, and is a much better client than the horrible PushOK client currently available for Subversion connections from LabVIEW). When we want to reuse a package in another project, we simply pick the package we want from version control. (We can select a lower-level package if we don’t want the entire hierarchy.) To make sure the package is up to date we simply invoke a command to update the package from the pop-up menu. This works quite well.
Summary: The ability to import subprojects or packages in a hierarchical manner is critical for effective code reuse and maintenance. We consider this a quite essential feature of any project paradigm in any software development environment. The benefits to users (and therefore to NI) are many and the drawbacks are, well, none. Please ensure this becomes a feature of a version of LabVIEW in the very near future.
_____
I am curious to hear what others think.
In particular, I think this functionality is critical and essential, and very definitely belong natively in a LabVIEW project.
I suggest that autopopulating folders are not the solution.
I suggest that the LabVIEW project must support this functionality--natively! (As I write I wonder if VIPM does this. It very well may, but at least the part I am asking for I think obviously belongs in the project itself).
In any case, please comment on the thread at NI Ideas (rather than here)!
Thanks!
Paul
-
My story made NI'sInstrumentation Newsletter Q2 2010
See page 24
Congrats! It is great to see recognition of your contributions on LAVA and to FIRST!
-
Sure there is. Right-click on the chart and select Properties from the pop-up menu. On the scales tab pick the axis and set the options you want under Grid Style and Colors.
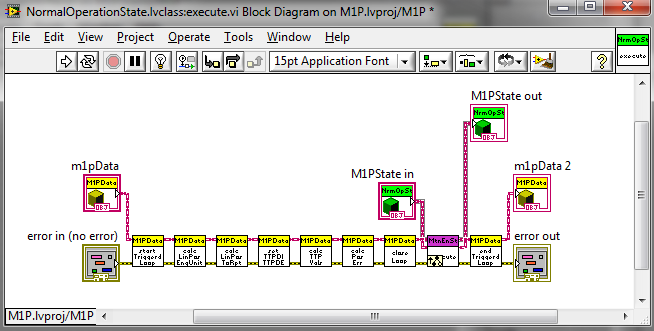

Examples: Messaging with objects, Command and State Patterns, configuration with XML
in Application Design & Architecture
Posted
I've been thinking about this solution. I will make a couple observations:
If the Entry and Exit actions are common to all cases then it makes sense to keep them out of the statemachine, as you have done in your example. We have solutions either way, depending on whether this behavior is state-specific.
For some applications messaging is an advantage because we can separate the View from the Controller not only into separate loops but into separate applications. This means we can create alternative Views that will work with the Controller, and the Controller can work with another component as well. The Controller just knows that it receives messages defined on its interface, and it knows what to do with those data messages. It does not care about the source of the messages. This is very powerful when you need it. (The ability to bind controls to shared variables makes this pretty simple to implement with shared variables, but that's just one solution.)
We use this capability especially since we often want to test a component stand-alone and then integrate it into the system. In the former case we need a local UI, but in the latter case the component usually receives data from another component in the system. Moreover, we use the local UI for local control for diagnostics and an "engineering mode." Of course, the needs of the application will indicate whether this is appropriate or not.
OK, I'm also curious what your State Transition method does exactly....