Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
Actually, you can. I know they say "everything is an object" in C# but it's not really true. What aren't objects? I think some native data types (such as interfaces) and operators (index into array) are not objects. Code blocks aren't objects. Statements aren't objects. If you want to really bend your brain, Smalltalk and Eiffel are two languages that are OOP-ier than C#. (I've done some exploring in Smalltalk. Don't know much about Eiffel.)
-
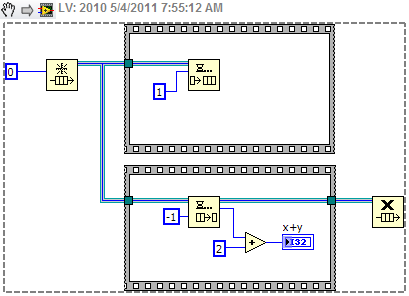
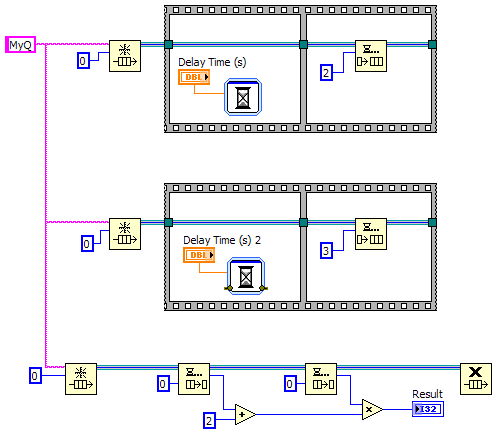
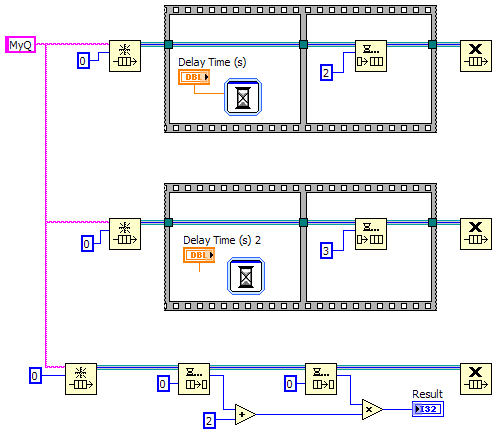
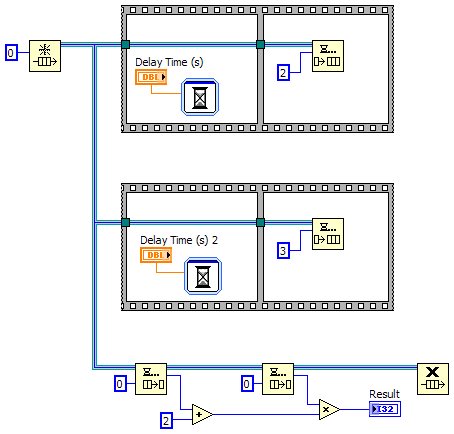
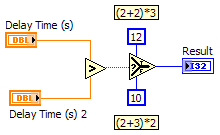
Thanks for the detailed response Jason. Just to be clear, I'm not claiming I'm right and you're wrong. I'm just talking through this and presenting different ideas with the hope that the discussion will help me develop a better understanding of Labview and dataflow. This is more than just an academic discussion. AQ has mentioned in the past that the compiler is able to do more optimization if we don't break dataflow, implying it has more to do with determinism and complexity than whether or not we are using any kind of references. So I'm often left wondering exactly what dataflow means and how I can know if I have broken it. Let me try to explain through some examples... Looking at the same example I posted earlier, (ex 1) even though it uses a queue it is still deterministic. The compiler can (in theory, though perhaps not in practice) reduce it to, (ex 2) The fact that it is possible for the compiler to remove the queue without affecting the output indicates to me that dataflow hasn't really been broken, even though according to the common interpretation it has. Let's add a little more complexity to the diagram. (ex 3) At first glance it looks like the queue can't be factored away, so dataflow must be broken. But a little thought leads us to, (ex 4) - Note: 'Greater Than' should be 'Less Than' which clearly doesn't break dataflow. What about this? (ex 5) On the surface this may appear to be functionally identical to example 3, but it's not. Here it's possible for either of the top two threads to create the queue, enqueue the value, and release the queue before either of the other threads obtains their own reference to the queue. If that happens the vi will hang. This block diagram is non-deterministic, so I'm inclined to think that this does break dataflow. (Incidentally this is one reason why I almost never use named queues.) So let's remove the Release Queue prims from the upper two threads. (ex 6) Just like that, it can once again be reduced to example 4 and dataflow is restored. But if I wrap the enqueue operations in sub vis, (ex 7) I've lost the reduction again since the sub vis will automatically release their handles to the queue when the sub vi exits. Hopefully these examples help explain why I find the common interpretation of dataflow insufficient. [Edit - I just realized examples 3 and 6 can't be directly reduced to example 4. It is possible for the second frame of the sequence with the longer delay time to execute before the second frame of the sequence with the shorter delay time. Probably won't happen, but it is possible. Regardless, my gut reaction is that determinism is broken but not dataflow...] --------------- It appears event driven from our perspective because we don't have to write queue polling code to see if there's an element waiting. Somewhere down in the compiled code there is a cpu thread doing exactly that. So what...? What about the "TimeDelay" or "Wait Until Next ms Multiple" nodes? They're essentially "event-driven" as well, waking up periodically and checking a resource to see if it should exit. But we don't typically consider these to break dataflow. This also raises questions of what happens if we change the timeout value from -1 to 0. Many of the "good" examples above are no longer deterministic without an infinite timeout. Murky waters indeed. I agree using references (queues, dvrs, etc) adds complexity and a certain amount of opacity to the code; however, what you are calling "pure dataflow construction" I think is better described as "by-value construction." In that, I agree with you. By-value construction is easier to follow, has less chance for race conditions, and (ignoring the cost of memory copies) allows the compiler to do more optimizations. ---------- It seems to me "dataflow" is a word that has been used at various times to desribe several distinct ideas. I propose we use the following: Dataflow - This is the idea that a node begins execution only after all its inputs have been satisfied. More precisely, it refers to the execution environment for Labview code, not the development environment. It is what enables Labview's powerful parallelism. We, as developers, do not have the ability to "break" dataflow and only have indirect control over sequencing in the execution environment. Given multiple nodes with all inputs satisfied, it's up to the RTE to decide which one will execute first. Simplicity - Simplicity is reducing the code to the bare elements needed to perform the required action. Examples 1, 3, and 6 can all be simplified as shown. (5 and 7 are just bad code.) That simplification can be done either in the source code or by the compiler. In theory either option will result in the same compiled bits. Simplification benefits the developer, not the compiler or executable. Determinism - If a block of code always gives the same output for a given input, it is said to be deterministic. Mathematical functions are deterministic. Dequeue prims are not. Deterministic code tends to be easier to follow and lets the compiler do more optimizations, so we should code deterministically when it makes sense to do so. However, even though a dequeue prim is not deterministic in and of itself, it can be used in a chunk of code that is deterministic, such as all the examples above except for 5 and 7. (Perhaps AQ was referring more to determinism than dataflow with his comments regarding optimizations?) ----------- I can always count on Yair to know the arcane exception to the rule...

-
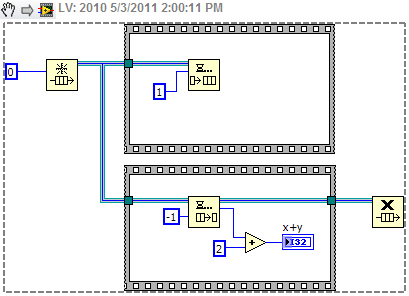
(This is me thinking aloud, not me preaching from a soapbox...) I'm curious, how do you define "dataflow" and what does it mean to violate it? Personally I've struggled to come up with a definition I felt adequately explained it. Usually we (me included) associate "dataflow" with visible wires, so we call queues, notifiers, dvrs, etc, dataflow violations. I'm not convinced that's entirely accurate. Take this diagram for example: Why should this be considered contrary to dataflow principles? Neither flat sequence executes before all its inputs have been filled and a refnum is a valid piece of data for a refnum input to a node. Looks to me like data flow is maintained. To be honest, I'm not convinced it's possible to violate dataflow on the inputs. There's no node/structure I know of in Labview that begins executing before all its inputs have been satisfied. On the other hand, almost every node/structure violates dataflow on the outputs by waiting until all outputs are available before releasing any of them to the following nodes. Refnums and queues can definitely be used to circumvent Labview's predominantly by-value behavior, but in my head dataflow != strict by-value behavior.
-
Interesting thoughts Steve--I see where you're coming from. It would be fun if there were an option to "Inline Everything" on the top level block diagram, just to see the differences. Hmm... thinking about it a little more it occurs to me you can fairly easily create that kind of behavior simply by making sure every node (prim and sub vi) you use has only a single output. Off the top of my head I suspect any most prims with multiple outputs could be broken down into multiple operations with a single output. I'm thinking a "pure" dataflow language would be similar to programming in a lower level language, in that we'd have to manually construct artifacts to control parallel execution sequences (lots more sequence structures) and do a lot more parameter validation, since we couldn't output an error cluster from a node. Seems to me pure data flow is completely asynchronous. When a node has more than one output, holding one output until the other finishes strikes me as an inherent violation of "pure" data flow.
-
The traditional way of doing it is to create a "Tree.vi" and drop every vi in your project on the block diagram. (Don't worry about the broken run arrow.) Then whenever you're working on the project make sure you open the Tree.vi front panel before making any changes. Opening the fp automatically loads all dependencies into memory.
-
One thing to be aware of is "Apply to all" only applies the change to those instances of the enum that are in memory. If a vi that uses the enum isn't loaded into memory (which is not the same as seeing the vi in the project explorer window) when the changes are made Labview applies the changes the next time the vi is loaded. If you've made multiple changes Labview may not update the selected enum value correctly.
-
Yep, well aware of that.
-
NI licensing agreements allows users to install Labview on home computers as well as their work computers. I'd be surprised if your employer balked at that... after all, you'd be developing your programming skills on your own time. I can't help you with the time issue other than to say even if you can only do a few hours a month it would help. (I've learned that if I wait until I have time before I start doing something, I'll never start.) I have other stuff I'd like to release but too much of my time gets spent on the "other" things. Areas where I need the most help right now are writing examples, reviewing the help text to make sure it is descriptive enough, and someone to manage the builds/versioning/packaging.
-
Yep, I did. No rush though... I passed my CLD a year ago and I'm wearing the shirt for the first time today.
-
I agree it is a better architectual decision. (Plus a keypad component like that could be extremely useful in other projects.) (I know you know this stuff already, but it needs to be pointed out.) At the same time, it may not be the correct business decision. One of the primary responsibilities of an architect is to find a way to balance the competing requirements. During the CLA one of the "business" requirements is to be done in 4 hours. I'm not good enough with xctls to make it a viable option given the strict time constraints. (The person who did the sample solution obviously is. Kudos to him/her.) Hopefully your wish will come true and xctls will get a makeover soon. As an aside, what I got most out of the sample exam is the realization that NI doesn't set the bar very high. (Says me while still waiting for my CLA results.) There's way more to being an architect than what is covered in the exam.
-
Cool. Thanks for volunteering. I look forward to seeing what you come up with. (I do have an old example project in SourceForge that needs to be updated, but I don't think I've ever included in the package.) [Edit] The only documentation is in context help. Complete documentation is one of those things that would be nice to have and give the package some more polish, but I just don't have time to do it.
-
I recently posted an example of a programming idiom I frequently use here. That might give you a better idea of how to separate the responsibilities. If you want the framework users to only have to deal with a single top level wire (without branching) then you'll have to dynamically launch a vi to run in parallel to the user's application code. When it's wrapped in a class it's called an "actor object" or "active object." Searching the forums should (if Lava search cooperates) return several lengthy threads.
-
Grr... I was almost finished with a response when I accidentally clicked a link and lost it all. Here's the short version: I'm assuming the framework part of the code is the two classes and the other VIs are the application part of the code. My first suggestion is to move the framework code into an lvlib and give it a meaningful name. That will help developers who are using the framework in their own applications. The biggest issue I see is that the Engine and the application code are mixing responsibilities. The most obvious example is the Engine is responsible for creating the queues, defining the queue messages, and accessing the queue, but the application is responsible for creating the consumer loops and implementing the message handling code. You need to better define the limits of the framework's responsibilities. There are a couple options: Reduce the framework's responsibility to image layout calculations and rendering the image to a picture control in memory. Let the application manage the queues and do the actual UI updates. This provides more overall flexibility in how the framework is used but requires the application developer to write more code. Move the two consumer loops into a new Engine method and call that instead of having them on Main's block diagram. If you do this you'll be able to make a lot of the framework code private members of the library, which helps make the framework easier to use. The downside is that it also restricts what can be done with the framework unless the developer edits the framework code directly, which defeats the purpose of having a framework in the first place.
-
The LapDog team is pleased to announce the LapDog.Messaging 2.0 Beta package is available for download from our SourceForge repository. In addition to the conveniences found in version 1, such as built-in error trapping and priority queues, version 2 introduces a few key time-saving improvements: Simplified Data-less Messaging Sending a data-less message in version 1.x required users to drop a Create Message method on the block diagram, attach a string to the Create Message's 'Message Name' terminal, and finally wire the message object to the EnqueueMessage method. It's not particularly difficult, but it does get repetitive and uses up block diagram space. Version 2.0 streamlines the process and allows users to send a data-less message by connecting a string directly to the EnqueueMessage's 'Message' terminal. Improved Message Renaming One of the principles of good application design is encapsulation. In other words, try to limit the amount of information that passes between distant parts of your application. Changing a message's name as it travels down the message handling chain helps keep information localized and can improve readability. Version 2.0 makes this easier by factoring out the RenameableMessage class and moving the RenameMessage method up to the Message class. Now all messages have the built-in ability to be renamed, eliminating the annoying step of downcasting a Message object to a RenameableMessage object just so it can be renamed. New Namespacing Unfortunately, removing the RenameableMessage class breaks backwards compatibility, making direct upgrades a little more difficult. Since backwards compatibility is already broken, we decided to use this opportunity to change LapDog's namespacing and bring it more in line with modern text languages. Libraries are organized into a "virtual" hierarchy using a dot naming convention. For example, the linked VIPM package contains two different libraries: LapDog.Messaging.v2.lvlib contains the queue classes a few core messages. LapDog.Messaging.v2.NativeTypes.lvlib is an extension library containing message classes for select data types in Labview and is dependent on the core Messaging library. It is hoped that using this naming convention will make it easier for developers to understand how libraries (and packages) relate to each other without having to dig into the source code. The new namespacing also makes it possible to have different major versions installed side-by-side without cross linking or conflicts, allowing you to try out the beta without worrying about breaking existing applications. So what are you waiting for? Download it now and give it a try! (Don't be afraid to leave feedback... positive or negative.)
-
I agree we already have many places that contain reuse code. The problem with posting snippets to the forums is that they (the snippets) are disorganized and get buried on the back pages within a matter of weeks. Snippets themselves are too small to bother submitting them to the Tools Network or the Lava CR. Having some centralized location that allows categorization, tagging, comments, etc specifically for snippets would probably do quite well. Whether that location is a subset of Lava, part of NI's site, or a different site altogether doesn't really matter to me. That said, I'd prefer the snippets stick to stuff like showing elegant, easy to read, or highly optimized algorithms to do certain tasks rather than getting into template-like code blocks. The Flatten Array and Peak SNR examples are examples of what I would hope to find there. The While Loop Starting Point... eh, not so much.
-
The quick solution is to replace the Enclosure Stop Switch terminal in the lower Wait case with a Value (Signaling) property node.
-
Yep. Something like that could be extremely useful. That would be very nice too. My only concern would be having the site flooded with not-very-good snippets, but I suppose if they are wiki-ish and the community gets involved the cream will rise to the top. What would be even cooler than uploading snippets to the site would be some sort of snippet browser available from the IDE.
-
Finally added a new wiki page to capture this info.
-

Extremely Long Load Time with LVOOP, SuPanels, and VI Templates
Daklu replied to lvb's topic in Object-Oriented Programming
I meant that it doesn't matter to Labview. I agree that it may matter to the application developer. In those cases it is important for the developer to understand the conditions that cause the class to be loaded into memory and make sure loading doesn't interfere with execution. No, your mechanics model is wrong. It has the dynamic dispatch table as a separate entity from the objects when in fact each object carries it's own dynamic dispatch table.* The parent class' dynamic dispatch table only contains references to parent class methods. The child class' dynamic dispatch table can contain references to parent class methods (if it didn't override the method) or its own methods (if it did override the parent method or added new dd methods the parent doesn't have.) [*Dynamic dispatch tables are part of the class definition, not the object data, so I doubt each object "carries" around a duplicate copy. I assume each object simply points to the dd table defined for it's class.] Loading a parent class doesn't require loading child classes because the parent's dd table doesn't have any references to child methods. How does the parent class know which child method to call? It doesn't. At runtime if there is a parent object on the wire a parent method will be called. A child method can be called only if there is a child object on the wire. If there is a child object on the wire the child class must have already been loaded, which also loads the child's dd table (since it is part of the class definition.) Clearer? [Edit] The blue box area isn't quite correct either. Whether or not the class is loaded at the blue box depends on what the blue box is. If it is a vi or lvlib that is in memory, then the classes are loaded. If it is a project editor window then the classes have not necessarily been loaded, but may have been loaded depending on what else you've done during that editing session. -
Like the others, I use snippets mainly for posting examples to Lava... maybe a couple times a month at most. Depending on what exactly I'm doing I'll use snippets, take a screenshot and edit the png, or upload the vi directly. Most of my self-made png's could be snippets instead but I haven't gotten in the habit of using them. I've considered creating a folder for "reusable" snippets of boilerplate code but I haven't ever gotten around to it.
-
Yeah, I've been entertaining myself by watch The Office on Netflix too.
-
Extremely Long Load Time with LVOOP, SuPanels, and VI Templates
Daklu replied to lvb's topic in Object-Oriented Programming
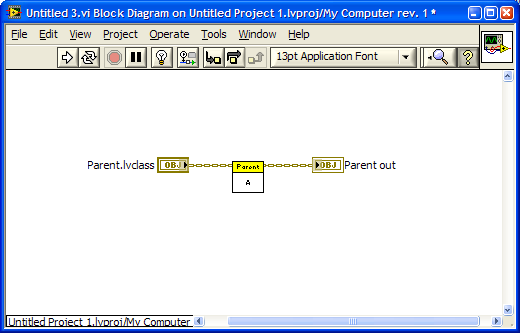
Yep, that is true. But it doesn't imply the child class has to be loaded at compile time. My comments have been in resonse to this... "I believe dynamic despatch (required for overrides) might mean that depending on how you are calling the methods, all classes may have to be loaded even if they are not actually used since it is not known at compile - time which child will be used..." A child class is loaded only if the child class is used (or if it is a member of a project library that has been loaded.) In this context, I'm interpreting "used" to imply there is a direct, static dependency on the child class. IOW, a member of the child class exists on the fp/bd of a vi that is in memory. Probably correct... or close enough for our purposes. This, if I'm understanding what you're saying, is incorrect. The compiler doesn't need to know any of the child classes that can be called because there isn't a universal dynamic dispatch table that needs to be populated; each class has its own dd table that is created/modified at edit time and loaded into memory when that class is loaded. Suppose I have a Parent class and a Child class with a single overridden method A. Then I create a naked vi like this: I can load and unload this vi all day long in the IDE without causing the child class to be loaded. I can add and remove data or methods without loading the child class. I can build it into an executable and still the child class isn't loaded. Through all this Parent:A is still a dynamic dispatch method and will call the child method if it sees a child object on the wire at run time. How? For starters, before a child object can be instantiated, the class must be loaded. It doesn't matter when this loading takes place--it may be when the application starts or it may be right before the object is needed. (Even though we don't have have lazy loading directly available to us, we do have some control over when things are loaded.) Loading the child class loads the child's dd table, along with all the child's members. Then dynamic dispatching injects a small bit of functionality (I'll call it the "dynamic dispatcher") between the connector pane terminal and the block diagram. At run time, after an object arrives at Parent:A's class input terminal, but before Parent:A is invoked, the dynamic dispatcher says to the object, "This is dynamic dispatch method #1. Give me a reference to the vi you have listed in your dd table at index 1." The object returns the reference and the dynamic dispatcher invokes that vi. Parent objects will return a reference to Parent:A. Child objects will return a reference to Child:A. At compile time the Parent class doesn't need to know about Child classes because the children create their own dd tables when they are compiled. (Note that loading a child class does trigger loading all ancestor classes.)
-
Extremely Long Load Time with LVOOP, SuPanels, and VI Templates
Daklu replied to lvb's topic in Object-Oriented Programming
I don't understand... dynamic dispatch and overrides essentially the same thing--two sides of the same coin. Can you explain further? [After thinking about your comment for a while...] Maybe this is what you're referring to as the polymorphic behavior? Suppose I have Parent:A.vi and Child:A.vi. On a new vi I drop a Parent control and Child:A.vi. When I wire them together Child:A.vi automatically turns into Parent:A.vi. (It also works with a Child control and Parent:A.vi.) That isn't the same thing as a polymorphic vi. Even though the vi on the block diagram morphs into a different vi, it's still a dynamic dispatch call. I can send a child object through the parent control at run time and child's implementation will be called. I view that morphing behavior as a developer convenience to help code clarity more than anything. Execution-wise it doesn't change anything. I'm not suggesting a "lazy-load" mechanism, as we don't have that level of visibility or control over Labview's memory operations. All we developers know is that Labview loads things into memory when it needs them and releases them when they are no longer needed. This is correct. Loading a class is an all-or-nothing proposition. If there is a reason for the child class to be loaded into memory, then yes, all of the class' members will be loaded into memory as well. However, loading a parent class isn't a reason to load child classes, even if the child classes have overriding methods.
-
Extremely Long Load Time with LVOOP, SuPanels, and VI Templates
Daklu replied to lvb's topic in Object-Oriented Programming
The two contexts you present don't quite make sense to me in this discussion. First, "loading" is not the same as "opening." Opening a fp or bd will cause the vi to be loaded into memory if it is not already present, but a vi can be loaded into memory without the fp or bd being opened. Loading, not opening, is the operation we're interested in. Second, I'm not sure what you mean by "opening" a .lvclass in the IDE. You can open the class .ctl in Labview or open the .lvclass file in a text editor, but you can't really open a .lvclass in Labview. As I'm sure you're aware, loading a vi into memory also causes all (statically) dependent vis to be loaded into memory as well. That's partly why "VI Trees" were used for so long--to make sure all vis were in memory so changes were properly propogated through the system. Libraries (lvlib, lvclass, xctl, and a few others) added additional loading rules into the mix. Loading a library member (*.vi, *.ctl, etc.) always causes the owning library file (*.lvlib, *.lvclass, etc) to be loaded into memory. Loading a class file (*.lvclass) into memory causes all class members (*.vi, *.ctl, etc.) to be loaded into memory. Loading a project library file (*.lvlib) does not cause all library members (*.vi, *.ctl, etc.) to be loaded into memory. Loading a library file (*.lvlib, *.lvclass, etc.) also causes all sub library files (*.lvlib, *.lvclass, etc.) to be loaded as well. In context #1 above (and assuming you are referring to opening the .ctl) loading the .ctl loads the .lvclass, which in turn loads all member vis. In context #2 above, when you open a class member vi, that triggers loading the .lvclass, which in turn triggers loading all the other member vis. Both actions cause all class members to load. Neither action inherently causes child classes to be loaded into memory. For that to happen one of the two situations I mentioned has to occur. One side effect of the library loading rules above is that if you have many classes contained in a single lvlib, loading any single class member causes all classes and class members in the lvlib to be loaded into memory. Are you using project libraries (.lvlib) in your application? Good link. I'm not really qualified to answer this question as I don't typically use VITs or sub panels in my applications. I'm curious how much code you have on each sub panel's block diagram and what their memory cost is? Since opening a VIT creates an entirely new vi rather than just allocating separate data space, I'm guessing it would be beneficial to keep that vi as small and simple as possible. You could give each signal sub class a "Subpanel UI.vit" method whose sole responsibility is to interact with the user and put all the sub panel's functionality into other class methods marked as reentrant. That might minimize the hit you take when opening a new VIT. Nope, at least that's not my understanding. You don't have to know which child object will be used to override the base class at compile time. "A dynamic dispatch subVI node on the diagram records a particular index number when it compiles. A node that represents an invocation of A.vi, for example, records index 0. A node for an invocation of B.vi would record index 1. At run time, whenever an object comes down the wire, the node will access the dynamic dispatch table of that object. It will retrieve the VI at the recorded index and invoke that VI. The node does not incur any overhead of name lookup or searching lists to figure out which subVI to call. The time complexity is O(1) no matter how deep the inheritance tree gets or how many dynamic dispatch VIs the classes define." If child classes had to be known at compile time many plug-in frameworks would be impossible using LVOOP. -
Extremely Long Load Time with LVOOP, SuPanels, and VI Templates
Daklu replied to lvb's topic in Object-Oriented Programming
On the surface, nothing. Had there been a single class with 419 member vis, *that* would have been a problem. (Your original post wasn't clear on that point.) This part isn't making sense to me. Loading a parent class doesn't trigger automatic loading for the child classes unless: The parent class has source code dependencies on the child classes or, The parent and child classes are contained in the same lvlib. Loading a child class does require loading the parent class, but parents don't require children to be in memory. Why are all the children being loaded when the opening the Signal class? That's the first place I would look to improve performance. Furthermore, loading a child class doesn't automatically load sibling classes. Loading the Digital Input class will also load the Signal class, but it won't load the Analog Input class. Also, if your "templates" are in fact vit files, you might consider changing them to reentrant vis. Jarrod comments on the benefits of reentrancy over templates on this thread. Other than that, I think you're on the right track by separating the UI from the functional code.