Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
Wow, talk about pressure. I've actually thought about how handy that would be. Deleting selected entries to reduce .lvclass file is trivial. Creating a tool that allows users to build a history from scratch is trickier. I think core code is managable, but I've been stuck on the UI. (I say "stuck" like I've actually written code. I haven't. All I've done is think about the problem.) I can imagine a user interface that would make it fairly intuitive to build a history. Unfortunately I have absolutely no idea how to implement it. --A little later-- Looking through this again I'm not sure your vi exposes all the information I'd need to build a mutation history from scratch. In particular, I see the Old Name Index is incremented every time the class is renamed, but there's no information about what those names actually are. Isn't the actual former name necessary information in the mutation history?
-
Thanks to everyone for responding. There are lots of good ideas here. I'm going to have to talk to the client again and get more details about how they expect use the station administrator mode before I implement anything. Tim and Jeff (**crosses fingers hoping my memory hasn't failed me**) both raised valid concerns and their discussion prompted another question I hadn't considered before: In corporate environments where IT locks users out of the windows administrators group, is it still possible for plain vanilla users to create custom user groups and control access to them on a per-user basis? (This station will be deployed on Win 7.) It's been well over 10 years since I've worked for a company that paranoid of protective of the users. I've done it many times myself, but then I'm always an administrator on my machines. I ran your snippet (well, recreated it since I can't drag it to a block diagram using Win7 and IE09... probably more permission issues...) and I'm not getting the right answer out of it. It tells me I'm not an admin, even though clearly I am. Help files recommend using CheckTokenMembership instead of IsUserAnAdmin, but if I go that route there a lot more stuff I need to understand. And in a mostly unrelated side note, I stumbled across this little oddity... (I have this nagging feeling that there is a significant difference between the yellow node and the orange node, but for the life of me I can't remember what it is.)

-
Last Thurs I found out a client wants the test system to have protected "administrator" functions such as station calibration routines and setting up the system for new DUTs. They'd prefer station security tie in directly to the operator's windows logon. The simplest thing I can think of is to restrict write permissions to the config file directory and attempt to write a dummy file if any administrator functions are invoked. If the write succeeds, allow the process to continue. If not, disallow it. The upside is that this also prevents non-authorized users from modifying the config files outside of the application. The downside is that it's all controlled through Windows admin utilities. Has anyone ever done anything like this?
-
[Hmm... how to respond without giving the impression that I think I'm a "better top-end LV programmer?" I guess I'll just say I don't think I'm a "better" programmer than others here on LAVA... I just have a different skillset than many others. I'm confident in my ability to architect a modular application and create reasonably good reusable components, but when it comes to, say, complex scripting, I think of Jon (JGCode.) For unit testing advice I go to Omar. When I need highly optimized code I think of Ben. If I'm wondering about low level interactions between LV and the operating system or c code I think of roflk. Want details on LV and .Net interactions? Talk to Brian Tyler. LVOOP? Stephen Mercer. Well architected non-oop systems? ShaunR. The list goes on and on...] IMO, your cause and effect is out of order. You don't join a top consulting firm or NI so you can become a good developer. You become a good developer so they will want to hire you. (Assuming that is your goal.) If your goal is just to improve yourself as a developer, you can do that without quitting your current job. Here are some of the things I've done: Easily the number one thing you *have* to do is write lots of code. Lots. And I don't mean different flavors of the same app you've always done. Be curious. Try different things. Experiment with a new way to solve a problem. There's absolutely no substitute for implementing code and learning first hand what problems you run in to, what solutions you can use to work around the problem, and see how the final product meets your original goals. Second most important step is to discuss ideas with other people. Nobody at work to discuss them with? Post them on Lava--that's what I do--or the dark side. Present at a user group meeting. Undoubtedly not every one will be enamored with your idea. Don't worry about it. What's important is getting lots of different eyes on it and generating a discussion. Even if that idea is bad, the discussion can trigger new ideas that may be good. Third, start your own library of programming books. (And read them.) There aren't a lot of good LV texts out there. But you know what? There are tons of good programming books available in other languages and many of the things they teach are good programming concepts, not just good .Net or Java concepts. It will be confusing at first trying to figure out which concepts apply to LV and how to translate them to a dataflow language. The process of finding the answer will naturally improve your understanding of LV and help you develop better applications. You can of course use public libraries to check out the books you want to read. Personally I'll read through books I purchased 7 or 8 years ago and still get something new out of them because my perspective and level of understanding has changed. Fourth, commit to it. It unrealistic to expect your exployer to pay you for all the time you spend learning. Plan on spending a lot of personal time writing code, exploring new ideas, reading books, posting to Lava, etc. For example, over the holidays I spent three full days working with one of my projects trying to figure out how to write and organize unit tests. (And I still have a long ways to go before I feel like I'll really understand it.) ------ But as to whether or not you're qualified for the job, that's a question only the hiring manager can answer so don't worry about it too much. Job requirements usually list the "ideal" candidate and the person hired almost never has all the skills listed. If you're interested in the job throw your resume into the mix. All they can do is say no.
-
I've seen that before. IIRC it occurs when I have a Windows Explorer window open displaying the folder where the built application is going to be saved. Close the window or move one directory up and the error goes away.
-
I had not seen this video before... http://www.wimp.com/japanesetsunami/
-

Intra-process signalling (was: VIRegister)
Daklu replied to Steen Schmidt's topic in Application Design & Architecture
Personally I haven't run into situations in my code where the only solution is to use a named queue. I'll mention it every so often as part of my standard disclaimer, but I haven't had the opportunity to work on any real time systems yet and I know there are different constraints and concerns in that environment. (Don't know what they are though... Steen's comment about the FP being a bad communication interface on RT interests me.) My experience is almost completely in the desktop application space and my comments and ideas are directed at that platform. The one situation I've seen where a named queue was required is (IIRC) in AQ's Actor Framework. I think it had to do with the launcher, but my memory is fuzzy. Actually, I rarely use dynamically called code anymore. I don't know if that's because my projects don't require it, or my dev approach leads to different solutions, or some other unknown reason. Dynamically called code is harder to understand and debug, so I tend to avoid it unless it's clearly the best option. When is it the best option? I dunno. My working theory is it is the best option when I need to have a large or unknown number of identical parallel processes executing. True story: ~8 months ago I was showing a coworker some of my code so he could tie into it. I started explaining the part where I launched an active object (essentially a dynamically called object) and he kind of gave a condescending chuckle and said, "you're calling it dynamically?" A few minutes later he left. Yeah, initially I was a bit irritated at his attitude. But it did prompt me to reexamine my code and I realized he was right--in this situation there was no need for dynamic instantiation. I had gotten too deep into the weeds and had lost sight of the bigger picture, and as a result spent a lot of time implementing unnecessary complexity. He came back the next day and apologized for his chuckle. I tried to explain I was glad he did it, but I'm not sure my message got across. (On the off chance he's reading this, thanks J, it was an important lesson for me.) Like Tim, I'd pass the input and output queue references in through a fp control. Can you explain more about the use case where unnamed queues won't work? Are you referring to RT systems? If I do need to use a named queue, such as for an Actor Object, I'll use it only to cross that boundary where it's needed. An ideal solution would use the named queue just long enough to pass in a permanent unnamed queue reference, then the named queue would be released. A less-ideal-but-still-reasonable-for-some-people solution would be to use the named queue permanently, but only obtain it in the two locations where the named feature is explicitly needed. In other words, once the dynamic vi has the named queue reference, always treat it as an unnamed queue. At least when someone searches for the queue name they'll only come up with two hits. I make a distinction between a reference and reference data. Queues, notifiers, etc., are examples of references. FGs, globals, DVRs, etc., are examples of reference data. References are necessary to pass data between parallel processes. Reference data is not. Why not use copies? In the case of a stop signal, rather than using a reference boolean that is universally read by all the loops, each loop receives their own copy of a Stop message. Is reference data sometimes needed? Yep. In my current app I'm using a global to pass high capacity video from one component to another to meet performance requirements. We might also need to use reference data if we're working under very tight memory constraints. My rule of thumb is to use reference data because it's necessary, not because it's convenient. Another true story: In my current project I have a class encapsulating data loaded from a config file on disk. Each config file contains thousands of lines of .csv data. There are two unrelated components that need to use this information. I struggled for a bit trying to figure out how to make the information in the object available to both components. Good spot for reference data, right? In the end I decided to just create a copy of the object and send one copy to each component. The additional memory used is insignificant in this case and the code is much simpler. If memory use was an issue or they needed to modify the object's data, I would have put the config file object in a loop accessible to both components and used messaging to set/get data. --------------------- Incidentally, the master/slave organization I described above doesn't necessarily work in all situations. Kugr and I have been talking about systems designed around dynamically launched observer and observable objects. Each observer receives messages from one or more observables. There are a couple options for implementing observer-type behavior into this system, but I'm not sure which is best or, in fact, if any of them are any good. -
Ahh... I understand your concern and I can see how obfuscation would be a critical part of maintaining your ip. I have always assumed compiling into an executable provided a reasonable amount of protection from reverse engineering, though I do now vaugely recall prior discussions about how easy it was to dig into an exe to rev eng source code. BTW, I found this on your site: Win7-64, IE9.0.1.
-
Brief diversion... Do you mind if I ask what environment you work in that requires you to obfuscate your code?
-
Nope, I don't think you are. I will add two points of clarification: 1. I think state machines are good--it's queued state machines (or any architecture that uses queue-like constructs to control sequential processes) that I don't like. 2. The difference between a QSM and a message handler is not well defined. IMO, it's all in how it's used, not what it looks like.
-
I think the reason you're not seeing a hit to UI performance is that you're not loading up the event queue. You're throwing a lot of events at it, but the queue is staying pretty clean. I suspect you'll see performance issues if you have one event case fire off a bunch of value signalling events (say, 100) before exiting. The performance issues won't be in moving the window around--that's managed by the os. It will be in the responsiveness of other fp controls. (Changing tabs, pressing the exit button, etc.) Alternatively you could increase the wait time in states 1-3. The scenarios I suggested are contrived to expose the weakness of serialized UI events, but once understood can be avoided. The bigger problem with this architecture (which the QSM also suffers from) is the danger of injecting an unexpected "state" in a chain of states. In the attached project, I've increased the number of states to 5 and lengthened the state wait time to 500 ms to make the issue easier to see. Start it up, then hit the Restart button and watch what happens. Interesting, huh? Now try activating the other tabs or exiting. How "easy" is it going to be for a LV newbie to avoid creating this kind of situation or understand what is going on once he has run into it? Objectively it looks like your argument is a bit thin. Unfortunately not everything of value can easily be measured. There are several comments from people who have used the pattern and reported having difficulty understanding and debugging the code. It doesn't matter how easy the code is to write; if you can't read it then it's value is limited. At least with the QSM you can work around the problem in this example by clearing the queue when the Restart button is pushed. The issue as a whole still exists though, and while there are solutions to specific scenarios I believe this in an inherent flaw in the strategy of queueing up sequential process steps that cannot easily be resolved. ESSM+VSB Modified.zip
-
I don't remember the error code, but I know I received an error when trying to write an empty array. My solution was to delete everything in the existing array except for the last one.
-
Intra-process signalling (was: VIRegister)
Daklu replied to Steen Schmidt's topic in Application Design & Architecture
Quick response--short on time. Will add more later. No, it is not a point of view that is widely adopted, at least among advanced developers. (It's okay... I'm used to holding a minority viewpoint. ) We're tech geeks and we like to play with the latest toys: DVRs, shared variables, etc. It's intellectually stimulating, fun, and if I'm being completely honest I have to admit it strokes our ego to some extent. (I know I have an inherent desire for intellectual stimulation that comes out as a tendency to make things more complicated than they need to be because it's more interesting. I'm contantly battling against that desire, trying to make the "best" decision instead of the "most interesting" decision. Sometimes I win... sometimes I don't.) I can't speak to how people think inside NI; I haven't talked to enough of them. I know Stephen has been discouraging references for quite some time. It was a combination of his comments and the things I discovered while developing the Interface framework that encouraged me to minimize references and "embrace the wire." Having spent the last several years learning and discovering how to do that, I do believe my programs are less buggy and more sustainable than they would be otherwise. The downside? My architectures seem overly complex (especially to standard QSM developers) and I always encounter a boatload of "Why didn't you just...?" questions. [Edit - Also, my experience is almost completely in desktop applications and my comments reflect that point of view. I have not yet had the opportunity to work on cRIO or any real-time targets.] -
Intra-process signalling (was: VIRegister)
Daklu replied to Steen Schmidt's topic in Application Design & Architecture
I don't think we disagree on much here. Mmm... didn't mean to imply that it was black and white, or that my opinion is the only valid opinion. For the most part, yes. Limiting the scope of components and controlling the interactions between them is at the heart of how we bring order to the complexities of a large system. Globally available data violates the order we're trying to establish and, IMO, is best avoided when possible. I don't have any issue with references in and of themselves. I just prefer to avoid them if possible as I think it can easily add uncertainty to the system. Do I go to great lengths to avoid them? Not really... but I do try to use patterns and architectures where they aren't necessary. Perhaps... but it doesn't mean we shouldn't use wires when we can. Faced with the choice of implementing a solution with wires versus a solution without wires, I'll choose the solution with wires unless there are extenuating circumstances that make the wire-free option the better technical solution. I confess, your apparent lack of concern for code maintainability confuses me. Am I misunderstanding what you're trying to say? Do you work in an environment where you and only you ever look at your code? In my mind, the main difference between them is readability and confidence. When I'm looking through new code there's far more work involved in understanding and verifying the behavior of a named queue versus an unnamed queue. With a named queue I have to search for the queue name to find all the vis that use it, trace each vi's calling tree back to figure out where it fits in the calling tree, and then figure out how all the components relate to each other. I have to put the puzzle together using a random assortment of apparently unrelated pieces. With an unnamed queue I can look at the block diagram and see which other components use the queue because it's connected via a wire. I start with the puzzle completed and can examine each section as interest or need dictate. For me to gain confidence the components are going to work together correctly, I have to trace through the code and make sure unexpected things can't happen due to all these asynchronous loops obtaining and releasing the queue on their own schedule. I have to figure out all the possible timing variations that the parallel loops can execute with. I've seen code by very good developers where a parallel loop may obtain a named queue, send a message, and release the queue before the message receiving loop has had a chance to "permanently" obtain the named queue. They built race conditions into their code without realizing it. These aren't LV newbies; they're people who have made a living with Labview for a decade or more. They just wanted to take advantage of the "convenience" of named queues to reduce the number of wires on the screen and have a cleaner block diagram. (FYI, I succumbed to the "convenient and clean" siren song for a while too.) Please don't take that as a dig on you--I don't mean it that way. There are things that can be done to reduce or remove the risk of named queue race conditions. From a practical standpoint I think named vs unnamed queues is largely a matter of style. (In the situations I saw I believe it is unlikely the race condition would have been an issue during execution.) I personally don't like them for the reasons I explained earlier. It's harder for me to use named queues to discover the relationships between loops, and even if the race condition is unlikely to ever occur during execution, I still have to go through the work and convince myself that's the case. Unnamed queues might take a few minutes longer to implement but remove both of those issues. It's a worthwhile trade, IMO. Ahh.... security through obscurity. We all know how well that works. (Joking. I realize the risk of somebody trying to hack into your application via a named queue is probably very, very, low.) Maybe this is a stupid question, but can you explain exactly what you mean by sharing data? Is it data multiple components both read from and write to? Do you consider data created by one component and consumed by another "shared?" I ask only because I'm not sure I agree with your assertion references are required to share data, but my disagreement hinges on what you consider shared data. Agree 100%. I've mentioned it before on the forums, but it's never my intent to tell someone their implementation is wrong. (Unless, of course, it doesn't meet the stated objectives.) All design decisions carry a set of consequences with them. Experienced developers understand the consequences of the decisions and make choices where the consequences are most closely aligned with the project goals. Your goals are different than my goals, so your "right" decision is going to be different than my "right" decision. I share my implementations as a way to explore the consequences of the different design decisions we are faced with so we all can be better informed. It's not my intent to preach the 'one true path.' -
I agree. I'm just saying I would have a hard time making a good business case (with real dollars and cents) for doing it. Regarding competing languages, I've seen C# and VB in places where Labview could be used, but I haven't seen Java used in the test & measurement industry. Has anyone else?
-
Intra-process signalling (was: VIRegister)
Daklu replied to Steen Schmidt's topic in Application Design & Architecture
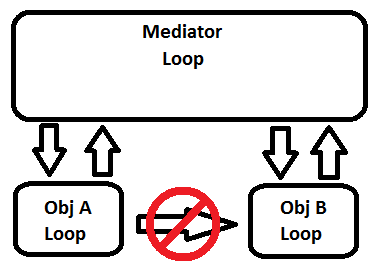
Preface: I'm assuming there are unstated reasons obj A and obj B must run in separate loops. This implementation pattern is overkill if the A and B need not be asynchronous. Publish-subscribe is one solution to that problem. PS establishes the communication link between the two components at runtime. That is useful primarily when the communication links between components are not well-defined at edit time. For example, a plug-in framework where the number of installed plugins and the messages each plug-in is interested will vary is a good candidate for PS. Usually I don't need that level of flexibility, so using PS just adds complexity without a tangible benefit. To keep A and B decoupled from each other I combine them together in a higher level abstraction. What you are calling a "message clearing house" I call a "mediator loop" because it was inspired by the Mediator Pattern from GoF. The mediator receives messages from A and B and, based on the logic I've built into the mediator loop, forwards the message appropriately. A couple things to point out in the diagram above: 1. Each mediator loop is the "master loop" for one or more "slave loops" (which I've mentioned elsewhere.) "Master" and "slave" are roles the loops play, not attributes of the loop. In other words, the Obj A loop may actually be another mediator loop acting as master for several slaves, and the Mediator Loop on the diagram may be a slave to another higher level master. 2. The arrows illustrate message flow between loops, not static dependencies between components (classes, libraries, etc.) Instances of slave components only communicate with their master, but in my implementations they are not statically dependent on the component that contains the master. However, the master component is often statically dependent on the slave. (You may notice having master components depend on slave components violates the Dependency Inversion Principle. I'm usually okay with this design decision because a) I want to make the application's structure as familiar to non-LVOOP programmers as possible to lower the barrier to entry, and b) if I need to it is fairly straightforward to insert an inversion layer between a master and a slave.) In practice my applications have ending up with a hierarchical tree of master/slave loops, like this: The top loop exposes the application's core functionality to the UI loops (not shown) via the set of public messages it responds to. Each loop exposes messages appropriate for the level of abstraction it encapsulates. While a low level loop might expose a "LoadLimitFileFromDisk" message, a high level loop might just expose a "StartTest" message with the logic of actually starting a test contained within a mediator loop somewhere between the two. Slave loops--which all loops are except for the topmost master ("high master?") loop in each app--have two fundamental requirements: 1. They must exit and clean up when instructed to do so by their master. That includes shutting down their own slave loops. 2. They must report to their master when they exit for any reason. These two requirements make it pretty straightforward to do controlled exits and have eliminated most of the uncertainty I used to have with parallelism. A while back I had an app that in certain situations was exiting before all the data was saved to disk. To fix it I went to the lowest mediator loop that had the in-memory data and data persistence functionality as slaves and changed the message handling code slightly so the in-memory slave wasn't instructed to exit until after the mediator received an "Exited" message from the persistence slave. The change was very simple and very localized. There was little risk in accidentally breaking existing behavior and the change didn't require crossing architectural boundaries the way references tend to. Final Notes: -Strictly speaking, I don't think my mediator loops are correctly named. As I understand it a Mediator's sole responsibility is to direct messages to the appropriate recipient. Sometimes my mediators will keep track of a slave's state (based on messages from the slave) and filter messages instead of passing them along blindly. -Not all masters are mediators. I might have a state machine loop ("real" SM, not QSM) that uses a continuously running parallel timer loop to trigger regular events. The state machine loop is not a mediator, but it is the timer loop's master and is responsible for shutting it down. -The loop control hierarchy represents how control (and low speed data) messages propogate through the system. For high-speed data acquisition the node-hopping nature of this architecture probably will not work well. To solve that problem I create a data "pipe" at runtime to run data directly from the producer to the consumer, bypassing the control hierarchy. The pipe refnum (I use queues) is sent to the producer and consumer as part of the messages instructing them to start doing their thing. Final Final Note: In general terms, though not necessarily in software engineering terms, a mediator could be anything that intercepts messages and translates them for the intended recipient. Using that definition, any kind of abtraction is a mediator. An instrument driver mediates messages between your code and the instrument. Your code mediates messages between the user and the system. I don't know where this line of thought will lead me, but it's related to the vague discomfort I have over calling it a "mediator loop."
-
It would have to be based on the sample exam to avoid violating NI's privacy terms. In principle the "real" exams could be made different enough to force users to change the structure while still allowing them to use the framework components. Alternatively, they could restrict it to free code available on the Labview Tools Network. Well then, maybe this would provide some motivation to make them so. (Or maybe not... I'm not sure there's a good business case for putting work into making it easier for competitors to obtain their CLA.)
-
In principle I agree with you. As a practical matter, the simple architectures don't allow for the kind of flexibility that accomodates the changes customers commonly request, so I don't use them and don't practice them. Maybe customers do exist who have well defined requirements and don't ask for changes partway through development. If so, I haven't encountered them.
-
Intra-process signalling (was: VIRegister)
Daklu replied to Steen Schmidt's topic in Application Design & Architecture
I agree with both Shawn and Stephen. My loops only have one way to receive messages; adding more for special cases creates unnecessary complexity. I only use user events to send messages to "user input" loops. (Loops with an event structure to handle front panel actions.) Sometimes I'll use notifiers for very simple single-command loops--a parallel loop on a block diagram that starts up and run continuously until instructed to shut down. Usually I just stick with queues though, since the consistency is convenient and queues are a lot more flexible. Polling or junk messages are the only ways I've been able to figure out how to deal with the problem. LapDog's PriorityQueue class uses polling simply because it's easier to implement and understand. I believe it would be possible to do the more efficient junk message implementation that allows for an arbitrary number of priority levels by wrapping the dequeue prim in a vi and dynamically launching an instance for each queue in the PriorityQueue's internal array when PriorityQueue.Dequeue is called. It's a fairly complex solution, but at least it's all wrapped in a class and hidden from the end user. I don't think it would be hard to implement what you describe. The aforementioned LapDog PriorityQueue class is an example of how to implement message priority functionality in a queue. There are several ways to make a custom "queue" class have the same one-to-many behavior as a notifier. You could have one input queue and an array of output queues, one for each message receiver. You could call it a queue but under the hood use a notifier instead. Combine the two and you're good to go. NI may not discourange their use, but there are many of us (admittedly a minority) who believe they are a quick solution instead of a good solution. Here's a quote taken from Stephen's excellent article, The Decisions Behind the Design: I remember not agreeing with that when I first read it. After all, data obtained in one part of an application is often needed by another part of the application. Isolation makes it harder to get the data from here to there, right? (As it turns out, not really, as long as you have a good messaging system and a well-defined loop control hierarchy.) Unfortunately it's really easy to miss the key sentence in that paragraph, and there's no explanation about why it is important. IMO, that sentence is, As is usually the case when I disagree with Stephen, over time I began to see the why until eventually I understood he was right. The guarantee of data consistency pays off in spades in my ability to understand and debug systems. Any kind of globally available data--named queues, functional globals, globals, DVRs, etc.--breaks that guarantee to some extent. When I'm digging through someone else's code and run into those constructs, I know the amount of work I need to do to understand the system as a whole has just increased--probably significantly. There's no longer a queue acting as a "single point of entry" for commands to the loop. Instead, I've got this data that is being magically changed somewhere else (possibly in many places) in the application. It is usually much harder to figure out how that component interacts with the other components in the system. Named queues are especially bad. We have some control over the scope of the other constructs and can limit where they're used, but once we create a named queue there's no way to limit who interacts with it. "Good" application architectures limit the connections between components and the knowledge one component has of another. Flags usually, imo, reveal too much information about other components and lead to tighter coupling. Suppose I have a data collection loop and a data logging loop and I want the logger to automatically save the file when data collection stops. A flag-based implementation might have the collection loop trip a "CollectionStopped" boolean flag when it stopped collecting data, while the logging loop polls the flag and saves the data when it switches to true. Quick and easy, right? Yeah, if you don't mind the consequences. For starters, why should the logging loop even know of the existence of a collection loop? (It does implicitly by virtue of the CollectionStopped boolean.) It shouldn't care where the data came from or the conditions under which it should save the data, only that it has data that might need to be saved at some time. Maybe the data was loaded from a file or randomly generated. Maybe I want users to have the option to save the data every n minutes during collection to guard against data loss. How do I save that data? I could trip the flag in other parts of my application to cause the logging loop to save the data (if we optimistically assume the flag doesn't also trigger actions by other components,) but why is a timer loop way over on this side of the app tripping a "CollectionStopped" flag when it doesn't have any idea if collection has started or stopped? To clarify the code perhaps we rename the flag to "SaveDataLog." Better? Not really. Why is the collection loop issuing a command to save data? What if I'm running a demo or software test and don't want to save the data? Another flag? How many flags will I have to add to compensate for special cases? Each time I make a change to accomodate a special case I have to edit the collection loop or the logging loop, possibly introducing more bugs. Contrast that with a messaging-based system, where the collection loop starts when it receives a "StartDataCollection" message on its input queue and sends a "DataCollectionStopped" message on its output queue when it stops. Likewise the logging loop saves data to disk when it receives a "SaveData" input message and sends a "DataSaved" output message when it has finished saving. Both loops send and receive messages from a mediator (or control) loop that does the message routing. Once implemented and tested the collection and logging loops don't need to be revisited to handle special cases. Separating the code that performs the collection and logging from the logic that controls the collection and logging makes it far easier (again imo) to build robust, sustainable, and testable applications. Acquiring data and saving data are two independent processes. Directly linking their behavior via flags or any other specific reference type leads to long term coupling and makes it harder to extend the app's functionality as requirements change. Do I use reference data and flags? Yep, when I have to, but I think they are used far more often than they need to be and I've found I rarely need them myself. -
-
That makes sense. I've noticed the mutation history size increases much faster when a class contains other classes as private members. The other problem class has 3 member classes and grows ~1.5 mb with each save. Does a class extract and store the mutation history of all member classes as well? This also explains a lot of the edit-time performance issues I've had in LV 2009. Any operations on the two 25 mb classes that required saving or applying changes took several minutes to complete. Once I removed the mutation history the problem went away. (Note to others: The vis in the folder AQ mentioned operate on the class, not on the object. It alters the .lvclass data in a way that affects all instances of the class from that point forward.) Since I refactor a lot and rarely persist objects to disk using built-in functions, I'd like to script a tool that automatically clears the geneology. My thought is to delete all but the most recent item in the array. Other than not being able to load persisted objects from disk, are there any gotchas you know of that I should watch out for?
-
Thanks for the tip. I discovered renaming the class doesn't clear the mutation history in 2009. There was still 46 or so entries in the list. However, I was able to use the Set Mutation History vi to clear the list and reduce the file size back down to where it should be.
-
I disagree--rule changes aren't inherently unfair. In professional competitions rule changes are made to restore competitive balance. (Though admittedly, they are not often changed while the game is in progress.) A game is unfair when the players don't play by the same set of rules. Adults and children operate under a different set of rules; therefore, the microcosm of parent-child interaction is indeed unfair. I might argue that unfairness by and large goes away when looking at the larger picture of interactions between all parents and all children. (i.e. All parent-child interactions are subject to the same set of rules imposed on them by societal norms. B being subject to the decision of his dad isn't unfair because all teenagers are subject to the decisions of their parents.) I think, however, this line of reasoning wouldn't find anchor in his hormone-addled brain. Regardless, I often heard the same thing from my mother as Cat did, "life isn't fair." I agree, but why is that something we have to learn? Why do we expect life to be fair? Why do we teach fairness to young children and expect them to behave fairly, only to turn around and destroy their understanding of the world when they're older? For me, thinking of life as a game implies winners and losers. Megan, my 13-yo, is very much about winning--especially wrt verbal confrontation. She refuses to be the first to stop arguing because then she feels like she has lost. I'm trying to teach her there are no winners in a fight. Dragging it out just makes everybody lose more. My personal view is life is a series of experiences. Winning and losing are experiences, but we don't typically say an experience wins or loses; it just is. The change in perspective helped me stop deriving my sense of self worth from the events that happened in my life and has allowed me to be much happier overall. Oh, of course. (If I knew what a transitive verb was and could pick a direct object out of a lineup, I'm sure I would agree with you.) I was 29 years old when I first discovered I could no longer will my body to do things it didn't want to do. It's been downhill ever since. I was hoping he would he would make the connection without having to spell it out for him. I prefer letting my kids "discover" why their reasoning is flawed rather than pointing it out to them. It's not always possible, but I think they learn better that way.
-
I tried opening the file using Notepad++ but it choked. What did you use? I was very surprised to see a 25mb text file compress into 200 kb. Makes me wonder if there's a huge amount of white space embedded in there somewhere. I don't mind that LV tracks it automatically, but I do wish there were a way to hook into the process and override the default behavior.
-
I should clarify that he wasn't being whiney and childish. He was laughing and quite happy during our conversation. Still, the basic truth Not getting what you want != unfair apparently was not only a new idea to him, but appeared to be completely beyond his comprehension. On the other hand, he could have just been being a normal teenager trying to express his individuality by arguing with me, though if that's the case he picked a poor point to argue. Either way, he's a smart kid--he'll figure it out. He just made the unfortunate mistake of commenting about fairness at a time when I've just about reached the limit with my younger (10 yo) daughter's complaints about the same thing.