Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
Best wishes. Here's hoping your doc isn't of the opiate-partaking kind.
-
Of general interest to future readers is a presentation Tomi did at NI Week 2010. (Link to slides.) Slides 12-14 illustrate the concept of decoupling the UI. Interesting idea. I had never considered skinnable UIs. I suppose as long as your references don't penetrate into the domain layer you're still maintaining a nicely decoupled UI. When you do this, how much code do you have on the UI block diagram? Is the UI still your 'top level' vi in the dependency hierarchy, or is it more of a 'bolt on' component that can be easily swapped out? This comment gave me cognitive dissonance and I've been thinking about it for the past couple days. I agree that flexibility and re-use are not necessarily explicit project goals and all requirements need to be balanced, yet the idea that decoupling would not be a desirable characteristic in any app of reasonable size is... dissonating. Decoupling (in general, not just the UI) does more than just improve flexibility and reuse. Most notably, testing a decoupled component is much, much easier than testing that same functionality in a tightly integrated system. It also (IMO) makes development easier as there is a clearly defined api that can be implemented without worrying about hidden interactions with other components. While I have never has a customer explicitly require decoupling, the requirements they do specify (as well as the implied requirements, such as fixing bugs in a timely manner) always lead to at least some degree of decoupling. I'm not disagreeing with you... just verbalizing (or textualizing?) the way I resolved the dissonance.
-
I've never used background coloring, but I believe you'll have to recolor the cells programmatically. Michael posted an illustration of how they accomplished it in VIPM here.
-
Easily the one virus most responsible for getting in the way of people doing their job. Cross-platform too...
-
The 'ItemNames' property returns a 2d string array of all the data in the mc listbox. Read it, add the row of data to the array, and write it back to the ItemNames property. McListboxExample.vi
-
I dunno Chris... I think you ought to sleep on it a bit. After all, it's only been 4.5 years since the review was posted. We wouldn't want you to be too reactionary... (Haven't read the book, else I would happily review it.)
-

A software engineering approach to labview?
Daklu replied to SteveChandler's topic in LabVIEW General
There was a lot of discussion about this on the LV mailing list last week. Apparently the print quality is restricted to the second printing. If you get one from the first or third printing you'll be okay. Can't comment on content. -
It's all academic until we get paid for it... then it's progressive. <Thinking out loud> I assume you're passing config options to the other executables via command line options? How are you going to dynamically discover the data type each config option accepts? You might be able to extract that information from the 'SupportApp.exe /?' text, but that's an ugly solution. Making your program's operation dependent on a help file author is asking for trouble. I suppose a safer solution is to itemize the options and data types in a config file your base class reads when the app is started. Then your Set ConfigOption method calls the appropriate type checking code based on the config file. 'Course, with this scheme you'll have to add new type checking code any time a new type is added to the configuration options. Or (to complete the circle) you could flatten the data to a variant, extract and store the type information in a dictionary, and check the dictionary every time the Set ConfigOption method is called. (You know, like what you said in the original post. ) The main difference between this and the config file implementation is with this implementation the code that creates dictionary entry also defines the data type associated with the entry. Might be an issue... might not... As far as enforcing types through all levels of the hierarchy, if Set ConfigOption is written so it can handle any arbitrary data type (variant parsing), make it static dispatch. Child classes don't need to override it. (Seems too simple... what am I missing? [See Dak's First Law]) If you were to go with a config file implementation, each class in the hierarchy maintains a list of config options assigned specifically to it and can only check those options, so you need to to override Set ConfigOption. At each level of the hierarchy the class checks to see if it recognizes the input key. If so, it does the type checking and returns the result of the operation. If it doesn't recognize the input key it calls the parent method, which repeats the process. I don't think you need to worry about this. (At least, I can't think of a reason why you would need to worry about it.) I think of it like this... At runtime there are no classes... only objects. Once you instantiate a grandchild object it will always be a grandchild object. It doesn't contain a parent object and a grandparent object within it; it only contains the same data types they use. (Under the hood it might actually contain a parent object, but it isn't accessable to us.) Calling Parent:Set ParamY on the grandchild object doesn't change the parent object because there is no parent object. All the data is "owned" by the grandchild object, even though it doesn't have unfettered access to that data. Why does it matter where exactly within the grandchild object the data is stored as long as it is available?
-
I'm sure NI purposely makes the problems much bigger than what can reasonably be accomplished in the given time. Why? I dunno... maybe to put us under pressure... maybe so we don't have time to experiment/learn how to do something... maybe because they're sadistic bastards...? I think I would prefer that over a coding test. It's much faster sketching out execution diagrams and state diagrams on paper than on a bd.
-
When I took the CLD, what really caught me off guard was how many more requirements there were in the actual exam than there were in the practice exams. Does the CLA practice exam accurately represent the kind and and quantity of requirements I should expect to see on the real exam?
-
Thanks Hoovah.
-
I'm too ^$#%%$ poor! < patiently waiting >
-
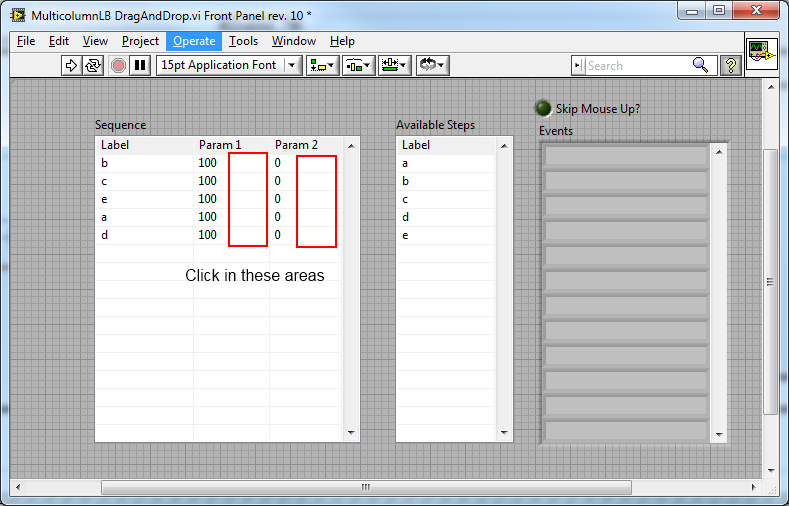
I've been prototyping some UI functionality and ran into something that is causing LV to crash. If anyone has a few minutes would you mind verifying this? (Please save your work before helping me out.) 1. Open and run the attached vi. 2. Click around in the areas indicated by the red boxes at a rate of ~2 clicks/second. 3. Watch LV crash within 5 seconds. If it can be confirmed I'll post on NI's site. Cross posted here. (I'm running LV10 and Windows 7.) MulticolumnLB DragAndDrop.vi

-
First, thanks to all for looking it over and giving me feedback. If anyone does use it, I'd be interested in what you like/don't like about it. Yep. If I'm going to put it in my reuse library I'd like it to be reusable. That's correct. The key difference between this (and string/variant) data-centric messaging system and the kind of messaging system you're talking about (using the command pattern to send data and the process) is where the message handling code resides--which component is responsible for defining how the message is processed. In the command pattern, the message sender determines how the message is going to be processed by choosing which message to send. That's okay for messages coming into a component; the component will always know how to handle its own messages. It doesn't work so well if the component wants to send messages out to an arbitrary receiver. For example, let's say you have a reusable component called WidgetPainter that defines a WidgetPainter.Paint message class to start the process and a WidgetPainter.Error class for returning errors to the caller. Each of these classes derives from a base CommandMessage class that defines an abstract ProcessMessage method. For WidgetPainter to be reusable it has to be independent of any application specific code; however, who should define how a WidgetPainter error is handled? The application, right? So we create a subclass of WidgetPainter.Error and name it App.WidgetError. How does WidgetPainter get an instance of the App.WidgetError object to send back to the application when the error occurs? We want to reuse WidgetPainter, so we can't drop the App.WidgetError class constant on WidgetPainter's block diagram. The app has to somehow 'register' the App.WidgetError object with WidgetPainter. That's a lot of 'stuff' to do just to send an error message. (I know I could have just said "callback" and you would have understood. I spelled it out in case other readers aren't familiar with the concept.) Using a command-based messaging system with callbacks is arguably a "more correct" OOP design. At the same time, it does have significant drawbacks. As you pointed out, each and every specific message has to be a unique class. There's no way around that. Each specific outgoing message also has to have an abstract parent class defined by the component. So now, in addition to the n message classes you need to create anyway, you have to add somewhere between 1 to n more message classes. Creating a handful of message classes is pretty painless. Creating say... 50... message classes gets old very fast. During active development when things change frequently in my environment, I have found the "one class for each message" approach to be an obstruction. It interrupts my flow too much and slows me down significantly. A command-based messaging system has another subtle drawback that requires a lot of complexity to get around. The message data contained in the callback object is set at the time that object is created. There's no easy way for the receiving component to update the messages data before executing the processing code, or for the component to retrieve the results from the message process. There are a couple reasons why I chose this messaging pattern (and prefer it for general purpose messaging) over command-based messaging: 1. A command-based messaging system didn't occur to me. (When I first developed this library a couple years ago I wasn't very familiar with the command pattern.) 2. It's easier to create decoupled components using this system. 3. The implementation pattern is familiar to almost all LV developers, lowering the barrier to entry. 4. My philosophy when designing an api is, "make the simple stuff easy and the hard stuff possible." On point 4, one common and simple use for messaging is to command a parallel loop to stop. With data-centric messaging you can send a dataless message named 'stop' and case out the execution code. Simple. How do you implement that using command-based messaging? On the other hand, if you want to use LapDog's messaging library to send command-pattern messages, it's pretty straightfoward. Derive CommandMessage.lvclass from Message.lvclass and give it an abstract ProcessMessage method. (I'd probably just use LVObjectMessage to carry the command object, but I don't think it matters.) In my opinion, the command pattern is a very good solution to specific problems the meet specific constraints. I don't think it makes a very good general purpose messaging system. However, as with all design decisions, it boils down to a subjective evaluation of the cost/benefit ratio. Yeah, I discovered that about 6 months ago. It's part of the reason I created renameable classes, though that is only a partial solution. Fully qualified names don't completely solve the problem either. It's possible (I think) for a different class with the same fully qualified name to be in memory instead of the intended class. My brain starts to fuzz out when I start thinking about those kinds of scenarios. Regardless, the only foolproof solution I know of is for the developer to be aware of situations where he will receive different messages with the same name. If he can't change the message names, he'd have to set up a secondary loop to receive messages from one of the senders and repackage that data in messages with new names before sending it to the main loop. (This is a simple example of the adapter pattern.) I did consider returning the fully qualified name (though I didn't think of examining the flattened string.) I rejected it for a couple reasons: 1. It requires a lot more typing in the case titles, which means more opportunities for mistakes. 2. It requires more updates when refactoring code and moving things around. Again, more opportunities for mistakes. 3. It can add significant overhead to the DequeueMessage method to address what is ultimately (IMO) a corner case scenario. 4. In keeping with my api philosophy, there's an easy way for developers to get fully qualified names if they want them: Subclass MessageQueue.lvclass and override DequeueMessage. I know we've discussed it before, but I typically only use events for sending messages to my fp event handling loop. I have found the message object to be useful in those scenarios. I'll create a single user event using the Message object as the type. In the event structure I'll wire it directly into the Get MessageName method and case out the message names.
-
I don't disagree with you. However, many small simple solutions put together doesn't necessarily equate a simple overall solution. But that discussion is way off topic so I'll do something really unusual for me... I'll stop.
-
I hope their requirements are fairly simple then.* Complicated requirements require complicated solutions. I haven't found a way around that yet. It's all a matter of how you manage the complexity. (*What do you do when someone asks you to build an F-22 fighter jet, but make it as simple to understand as a bicycle?)
-
It all depends on how much decoupling you're looking for. Injecting control references decouples *that specific* UI from the funcitonal code, but the functional code still requires *a* UI. Ultimate decoupling means you can, for example, attach multiple UIs at the same time, or run the code with no UI at all. It also means you can change the data type on the display without changing the functional code. Reference injection doesn't allow that. "Decoupled" isn't a binary attribute--it's a gradient. If you have implemented an insufficient decoupling strategy for a given change request, you'll end up having to rewrite a lot of code, or at least do a significant overhaul. Personally I like to build my UI's more along the lines of what John (Lokanis) does with a UI component that sends/receives messages and contains UI specific logic. (Practical realities don't always allow it, but I do prefer it.) You've decoupled the process and ui threads. That is a good example of what I called 'simple' decoupling above. More advanced decoupling has it's place, as well as it's costs and benefits.
-
THAT part I got. It's a question of *when* to write that value to get the behavior I'm looking for. It's not harmful, but it will go a long ways toward making the UI intuitive. I've added code to keypress handlers to delete the selected rows in the sequence builder when the delete key is pressed and the listbox has focus. Unselected the rows (or changing the highlighting color) is a good visual indicator for the user to know whether the delete key will work or not. Thanks for the suggestions. I guess I'll have to intercept every event that possibly can change the focus, compare the active object to the listboxes, and set listbox value if it's not selected. I was hoping for something a little more elegant and simple, but it is what it is.
-
Appreciate all the love gang... Somebody put on the Grateful Dead or The Doors. Talk about putting on the pressure...
-
In a single word, "encapsulation." That's not a very helpful answer though... There were a couple things with the string/variant messages that I found difficult. First, changing the name of a message can be difficult or impossible. Since the message name is the only information immediately available I changed it often during development to be appropriately descriptive. Second, in a string/variant message the message name and the message data are inherently different elements. The message sending code can match any message name with any data type. This opens the door to runtime errors that may or may not be found during testing. By creating your own custom messages that derive from Message.lvclass, you have much more control over the both the message name and the message data. The message object is responsible for ensuring the message name and data match up correctly instead of the message sender. I typically create a 'Create MyMessage.vi' for each of my custom messages that accepts the necessary data types and does not have an input for message name. This greatly reduces the risk of message name/message data mismatches. Since any code that sends the message uses the creator it also means I have more confidence if I change a message name to improve code clarity--the message name is (usually) only used in two place, the creator method and the receiving loop. It's important to understand that messages that expose a Message Name input on the creator or inherit from RenameableMessage have inherently 'weaker' type safety. (All messages in the NativeTypes library inherit from RenameableMessage. Message and ErrorMessage do not inherit from RenameableMessage.) You're giving the responsibility of making sure the name and data match up correctly back to message sending code. In that respect they're not much different from string/variant messages (though the creator conpane inputs still give you data type information so you don't have to look it up.) You can create similar protection for string/variant messages by building creator vis for the various message types, but I've never seen anybody actually *do* it. For that matter, I don't think I've ever seen anybody even suggest doing it. There's not enough payoff for the extra effort of making a creator vi that just bundles a cluster. LVOOP *requires* a method to bundle the name and data into a message. For me, building robust code is much more natural (and easier) with the Message Library than with a string/variant messaging system. Not yet, and to be honest I haven't really thought about it. All my message classes have been of the "protected cluster" kind. It's an interesting idea though. For example, with the command pattern you could have Command.lvclass inherit from Message... In general I favor composition over inheritance, but I'll have to think about it for a while. Thanks. To be honest, currently LapDog isn't much of anything except an idea... a hope... a dream. <queue orchestral music> LapDog is intended to be a set of components to assist LVOOP programmers. Originally I envisioned small-ish base class libraries for things like Collections and Data Structures. I've since realized a flexible and robust messaging system is absolutely critical for managing larger projects. I'll still work on the other libraries, but I think this is more generally useful than collections or data structures so it took priority. Also, I use the Message Library far more than I use data structures or collections, so it's easier for me see flaws and make improvements.
-
Best Practices in LabVIEW
Daklu replied to John Lokanis's topic in Application Design & Architecture
I disagree with the statement as it is written, but I suspect we agree on the bigger picture. I think the developer should write unit tests for the code he has developed. (And I know this is common in some software dev environments.) As you said, it helps verify the 'positive' requirements have been met. Well written unit tests also help communicate the developer's intent to other programmers. The very act of writing tests puts me in a different mind set and helps me discover things I may have missed. Requiring at least a basic set of unit tests keeps the developer honest and can avoid wasting the test team's time on silly oversights. However, that set of unit tests should not be blindly accepted as the complete set of unit tests that verifies all (unit testable) requirements have been met. When the component is complete and checked in, the test team takes ownership of the developer's unit tests and adds their own to create a complete unit test suite for that component. And of course, in a "good" software development process the developer never has the authority to approve the code for production. I'm pretty sure we agree on that. -
I'm trying to use a pair of MC Listboxes and drag-and-drop to create test sequences. One listbox has all the available steps listed, the other is where the sequence is assembled and edited. It's slowly coming around to how I want it to work, but I can't figure out how to deselect the rows in either listbox when it loses focus. I can change the selection programmatically, I'm just not sure what set of events I need to watch for before clearing the selection. Anyone have a clue they're willing to share?
-
Best Practices in LabVIEW
Daklu replied to John Lokanis's topic in Application Design & Architecture
I've used both but am expert in neither. Both appear to be capable of doing the job. My impressions... NI's UTF is easier to start using right out of the box and doesn't require any coding. It's more of an application than a framework. Select a vi to test, define the inputs, check the outputs, done. You'll probably need to write code for more advanced unit test scenarios though. Unfortunately I have had some issues that pretty much make NI's UTF unusable. (Link) ("Unusable" is probably too strong a word. "Not worth the effort" is better.) JKI's UTF is a true framework with all the plusses and minuses you might expect. Based on LVOOP, it offers more flexibility in ways that are natural to an OO programmer. On the downside, it's taken me some time to figure out how to effectively design test cases and test suites and there aren't a lot of examples to learn from. (And I'm still not sure I'm doing it "right.") True to form, JKI (usually Omar) has always been quick to respond to questions and helpful. One thing I've learned is unit testing is not a "I'll just quickly bang out what we need" task. It's a separate development effort all on its own, requiring careful planning and forethought along with it's own brand of expertise. I guess that's why software development houses have dedicated teams for testing. Give yourself (or your lacky) plenty of time to experiment with the framework, learn what kind and when the need to write supporting code, how to best reuse test code, etc. Final thought: In the past I've naively viewed unit testing a bit like a magic bullet. Turns out... not so much. It's good at catching certain kinds of bugs, such as when an interface is implemented incorrectly. Ultimately it will only catch bugs you're testing for, and if you've thought to test for them chances are you wrote the code correctly in the first place. Unit testing is only one part of a good test process. User-driven scripted tests (a written list of steps for the tester to do) and exploratory testing are valuable techniques too. -
Hmm... interesting problem. Can I ask what your real-world use case is? This kind of capability appears to be far outside how Labview is intended to be used. My gut instinct is to look for alternative solutions, possibly even using a different language. Still, I am strangely intrigued by this idea...
-
And if I understand correctly you want the base LBO to be able to define new properties at runtime, and force child classes to adhere to the rules of that new property? (Otherwise I don't see what you're gaining by using a variant. If all the interfaces are defined at edit time you can get what you want--as I understand it--and maintain strong type safety. Of course, I strongly suspect I haven't wrapped my head around the bigger picture yet...)