Daklu
-
Posts
1,824 -
Joined
-
Last visited
-
Days Won
83
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Daklu
-
Is now a good time to discuss it? If you're using a calculated quality metric to determine when the quality is acceptable, how did you determine what the cutoff is between "good enough" and "not good enough." I'm also curious what you consider a "defect." Obviously a bug is a defect. I assume anything that doesn't adhere to your coding standards, such as no documentation on the block diagram, is also a defect. Doesn't categorizing them both as "defects" essentially give them the same weight and importance in the quality metric? I assume we agree a bug causing customer data loss is far more important than a block diagram without documentation. If so, then what value is the metric providing? I don't mean to be hammering on you about this--I'm genuinely curious. I did a lot of Six Sigma work from 1997 through ~2005 in manufacturing-related business, but I've never quite grasped how to apply the principles to software development.
-
Just wanted to throw my $.02 behind Paul's comments. I've used a variation of the GoF State Machine pattern for several components and I'm quite liking it. (Is anyone surprised...?) One of the big problems I had with QSMs is that they don't really stay in any one 'state.' Even when there is no transition to another state the SM is exiting and re-entering the same state. Same thing, you say? Not when you start adding more strictly defined behaviors to your state machine. Every state in my SMs can define any of four different kinds of actions: 1. Entry Actions -- These are actions that are performed exactly once every time this state is entered from another state. 2. Execution Actions -- These are actions that are performed continuously while the SM remains in the current state. 3. Exit Actions -- These are actions that are performed exactly once just prior to this state exiting. 4. Transition Actions -- The are actions that are performed exactly once when this state exits and are unique for every 'current state-next state' combination. When looking at a state diagram, these actions are associated with the arrows. By recognizing these four different types of actions, it is much, much, easier for me to design and implement a state machine that does what I want it to do. I spend far less time fighting the implementation when trying to add an arbitrary new action. You can create a QSM that recognizes these four types of actions (my first experiments did) but I found it got pretty ugly pretty quickly and is error prone. Entry Actions and certain kinds of Execution Actions get particularly messy in a QSM. (Waiting actions do too.) I switched over to an object-based state machine and haven't looked back. I fully agree, and that is another major issue I have with the QSM. When you look at a state diagram the arrows not only define the transitions the SM does make, but also defines the transitions the SM is allowed to make. The SM defines and restricts it's own behavior; it doesn't depend on an external entity to know details about what states are "valid" to call from its current state. If there's no arrow, the SM simply won't transition from one to the other regardless of the command it received, because it's an invalid command. Leaving that responsibility to the external entity is error prone. QSMs allow far too much external control over the SM's internals. (In fact, I try to write my components in such a way that the SM client isn't even aware the implementation uses a state machine.)
-
Labview is a graphical language, so we have a unique opportunity to measure quality: 1. Print out all your block diagrams in full color. 2. Rent an art gallary. 3. Have a showing. Quality = Gross Receipts - Expenses (I'm curious though, are any business decisions made on the basis of the quality metric, or is it just something for managers to fuss over?)
-

Data allocation under OOP design patterns
Daklu replied to Jubilee's topic in Application Design & Architecture
To expand a bit on what Felix and Mark said, The question doesn't quite make sense in the Labview world. When a child object is instantiated during run-time it is an independent object with internal memory space for all the data associated with the parent class. It is not "connected" to any other objects nor does it's lifespan depend other objects. The only way to deallocate the memory associated with the parent object is to destroy the child object. This is true regardless of whether you're using by-val or by-ref classes. -
My bad LV habits acknowledged, a short list
Daklu replied to MoldySpaghetti's topic in LabVIEW General
Hold down ctrl-shift to bring up the hand tool and use the mouse to move around the block diagram. Much faster than using scroll bars. Why is this bad? Meh... that's not a bad habit; it's a personal preference. Is your hack & check used to figure out what the bug is, or a semi-random guess at fixing the bug without fully understanding it? If the former, no big deal. If the latter... yeah, you might want to rethink that. I agree with Felix. This is probably the change that will benefit you the most. When I have functionality that is a reuse candidate I do several things before adding it to my reuse library: 1. Create a library for the component that exposes that functionality. 2. Decouple the library it from my app code. (Make sure the library isn't dependent on any app-specific code.) 3. Copy the component source to a couple more projects and use it there as well. Only after I've used the component in a couple different projects (which almost always results in some changes to better generalize it) will I add it to my reuse library. -Writing block diagrams that don't fit on one screen -Routing wires behind structures -
As a programming practice I don't think there's anything wrong with it. The DVR and the SEQ are essentially equivalent. As Felix said, the DVR is usually favored over the SEQ, but there are advantages to the SEQ. For example, when you lock a DVR using the IPE, the nature of the IPE requires the DVR to be unlocked before exiting that vi. With a SEQ you can lock (dequeue) access, do whatever you want (including exiting the vi,) and unlock (enqueue) access when you're ready. There are ways to work around this by implementing lock/unlock methods in the class that uses the DVR, but it is easier to create arbitrary locking/unlocking scenarios with a SEQ than with a DVR. Which one you decide to use should depend more on the structure of your application than a desire for source code purity.
-
I come from a VB6 background as well. If you have the choice, I would recommend C# over VB.Net. Functionally they are nearly identical, but there are a few things that gave C# the edge when I was making the choice. -Personally I think the object syntax is easier to follow in C# than in VB. -As a language it has a bit more flexibility in that it has the ability to run unsafe code blocks. -There is still a perception that VB is not a language for serious programming. (Reality doesn't matter if the hiring manager believes it to be true.) -There are more C# resources available than VB resources. -The C# user base is larger than the VB user base. (Meaning more C# jobs.) The difference appears to be growing. -C# syntax is closer to that of other mainstream programming languages (Java, C++) making it slightly easier to make those transitions. Practically speaking the differences are minor so it really comes down to personal preference.
-
Thanks for the link Yair. I wasn't aware the event structure flushed the queue and disposed all the events it doesn't specifically handle.
-
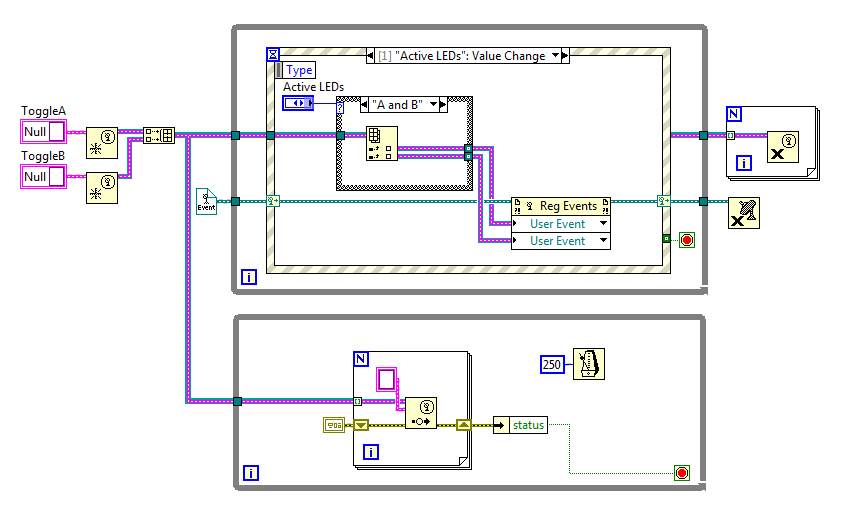
[Edit - Ah, the curse of being a slow writer...] I see where you're going with this. I've written a few components that use user events as the primary means of communication to other components. I decided using user events like that is usually more trouble than they're worth. Still, the exercise is worthwhile and I'll be interested in your thoughts on the matter. A couple things to think about... -Are the subjects going to have multiple observers? Multiple observers is the primary use case for user events (though that still has issues that need to be carefully considered.) If the subjects only have a single observer the main benefit of user events is unused. -Who creates and owns the events, the subject or the observer? If the observer creates the event and passes it to the subject, then (in the case of multiple observers) the subject has to maintain a list of event refnums from all the observers. What happens if an observer closes down without notifying the subject? If the subject creates the event and makes the refnum available to the observers, what happens when one of the observers closes the refnum? -Your comments imply the subjects are interacting directly with the user interface. What happens when you want to reuse one of the subjects in a non-UI component? What is that code going to look like? You'll need one loop with an event structure to handle messages from that subject and another loop to handle the queue-based messages from other threads in the component. These aren't insurmountable obstacles; just a few things to consider if you're creating an event-based architecture. Like I said, I found it to be more trouble than it's worth. YMMV. Now all my communication between components is done strictly via queues. The one place I do use user events is on the block diagram of UI components, and that's strictly for allowing the mediator loop to send messages to the event handling loop. Yeah, you'd hope that's the case. Labview R&D guys are smart, so I expect they've anticipated this potential problem. Still, without knowing the details of how the Register For Events and Generate User Event prims work together we can't know an event won't be missed. If I were to put on my speculator's hat (I love this hat) here's my guess as to how it's implemented with respect to user events. (This model doesn't fully explain all the design-time or run-time behavior, so I know it's not complete. And please 'scuse the inconsistent pseudocode. Structs don't have methods associated with them...) struct EventRegistrationRefnum { ptr eventStructure // not visible to Labview users ptr userEventRefnum [ ] } struct UserEventRefnum { ptr eventStructure [ ] // not visible to Labview users var userEventData } When the Reg Events prim is called it compares the input UsrEv refnums to it's list of currently registered UsrEv refnums. If an input refnum is already registered, there's no need to register it again. If it's not registered, then it calls UserEventRefnum.Register() and passes the UsrEv refnum a reference to the event structure. When the Generate User Event prim is called, it iterates through the list of event structures invoking EventStructure.RaiseEvent() on each one. When the Reg Events prim is finished iterating through the inputs, it checks it's current list of user events and calls UserEventRefnum.Unregister() on those that *weren't* present on the input. Then again, maybe I'm way off. *shrug* I'm really interested in what a blue says about this. The question is whether calling Reg Events does a hidden unregistration of all the events before re-regestering the events on the inputs. And if it does, what protection is there to prevent an event from being lost in that time between the hidden unregistration and the re-registration. I've attached a modified example using user events instead of fp events. The question is, when switching from "A only" to "A and B" is there a chance of missing the ToggleA user event? dynamic_reregistration_user_events.vi

-
I don't have a direct answer to your questions, but I did run the vi through the DETT to see if anything interesting popped up. The duration of the Register User Event prim is ~4 us, so if there is a period of time when nothing is registered the event is going to have to be pretty quick to hit that window.
-
I had almost finished composing a message last night when I accidentally hit the "Back" button on my keyboard. Ah, the joys of browser-based text editors. Note that "QSM" means different things to everyone. I don't use what *I* consider the QSM, but I do use queued message handlers. QMHs look a lot like QSMs, but the difference is in how they're used and what's expected of it. In this post I'm primarily referring to a dual loop "producer-consumer QSM" Absolutely not true. The QSM is the most common implementation seen because that's all most people know. And truthfully, it probably is sufficient for most Labview users. There are lots of architectures and patterns available. Though Labview is different from common text-based languages, it's still software. The patterns and architectures that apply to those languages can apply to Labview as well. As an aside (and I'm probably in the minority) I don't think the QSM qualifies as an "architecture," though people often refer to it as such. The QSM is an implementation, not an architecture. Calling it an architecture is kind of like saying my house is built using a screwed butt joint architecture. A "screwed butt joint" (and the QSM) is a construction technique, not an architectural description. So when someone says their app uses a "QSM architecture," I read that as, "My app has no architecture." Usually I'm not far off. There's nothing inherently wrong with state machines. When used appropriately they are very useful. Queued State Machines, however, aren't state machines at all. They're a convenient construct for sequencing code segments. Your question implies you're looking for a single, general purpose design that works across all requirements. So no, there is not *a* architecture that works well. Like Ben said, there are lots of architectures and design patterns, each with their own strengths and weaknesses. The software engineer's job is to pick those that meet the requirements. Pick one that's too complex and you have to implement a lot of useless code. Pick one that's too simple and you have to resort to hacks to support functionality the architecture isn't well suited to provide. My apps are composed of several different architectures/patterns, depending on what level of the code you're looking at. Event based, Model View Controller, object state machines, active objects, etc. Lately I've been moving towards highly decoupled components that use messages to send and receive information with a mediator handling all message routing and translation between the various application components. 1. I got tired of the messes that resulted from using QSMs. 2. They are fragile. Many implementations have inherent flaws that can't be fixed. 3. They are hard to follow. QSMs are a lot like GOTO statements in text languages. 4. They don't provide any structure. Good architectures are designed with clear extension points for adding functionality. 5. There's often no easy upgrade path to something more suitable when the requirements outgrow the QSM's abilities.
-
Yeah, I haven't found a way to do this in LV that I'm happy with. Same for me. In fact, the only time I use nested libraries is when I'm creating a library (A.lvlib) that needs some functionality provided by another library (B.lvlib) and no part of B will be exposed from A publicly. Then I copy B over to the directory containing the code for A and make the new B a private member of A.
-
"Project libraries" refers to .lvlib files. .lvproj files are just "projects." I'm a little confused by the rest of your post--it's not clear to me when you mean "project" and when you mean "project library." To clarify, each open project has it's own application instance, not it's own namespace. Labview creates app instances dynamically when the project is opened or created. Each app instance (open project) has it's own protected memory space that is not accessable from other app instances (open projects.) App instances are a transient construct used to aid souce code development. Project files, as currently implemented, don't really make good containers for distributing reusable code. Libraries (lvlib, lvclass, etc.) do prepend namespaces to all members; however, namespacing is a side effect of library membership, not a reason for library membership. Only put things in the library if it is required by the other members of the library. Labview's namespacing capabilities aren't as advanced as I'd like them to be and I've been crying about it for a year and a half or so. AQ acknowledged the use case for better namespacing but the idea languishes in obscurity on the idea exchange. Yes, it is necessary, and yes, it does prevent sublibraries from being used independently. Libraries are functional collections of related code. In other words, it's a group of vis that are (usually, but not necessarily) interdependent on each other to function correctly. What you're looking for is logical collections of related code you can organize in a hierarchy that makes sense. That's what namespaces are typically used for. Unfortunately Labview's namespacing is tied to library membership. Hopefully they will separate that functionality some time in the near future... What to do in the meantime? One option is to use library names that are self-namespaced. For example, suppose you wanted an "Instrument" namespace with a sub namespace for "Oscilloscope." If you had one library for an Agilent ModelA and another for an Agilent ModelB, you would have two libraries with the file names: Instrument.Oscilloscope.AgilentModelA.lvlib Instrument.Oscilloscope.AgilentModelB.lvlib Personally I don't do that. It's too painful to reorganize the namespaces when the need arises. Instead my libraries are usually flat (no nesting) and I use virtual folders in the project to do the hierarchical organization. That doesn't help much if you have a large set of reuse libraries that are hierarchical in nature as there's nothing inherent to each library that describes its position in the hierarchy. In that case... documentation?
-
I'm really weak on networking technologies and terminologies, but I agree PS is equivalent to broadcasting. "Publish-subscribe" appears to be the terminology favored by the software community. The stuff I've read uses "broadcast" to describe what the component does, not label the abstract interaction pattern. In general though, there's so much variability in what people mean when describing a component as "publish-subscribe" or "observer pattern" that it's hard to infer anything about the implementation other than, "the component sends out updates when something interesting happens." I think you're right that SO is a subset of PS. In Labview it's pretty straightforward to migrate from a general PS model to a SO model. If the component has been decoupled correctly the change can be made in the publisher/subject without touching the subscriber/observer code or any of the client code. Accroding to the producer-consumer wiki, "content-based" and "topic-based" refers to message filtering, or how the producer/subject exposes subsets of updates. It's a decision that can be made independently of the PS/SO decision. So while SO could be a particular flavor of generalized PS interactions, I view content/topic based filtering as chosing the topping to go on the ice cream. ------------------------------ I wrote the previous post last night at home. When I got to work this morning I checked to see what GoF has to say about it: "A subject may have any number of dependent observers. All observers are notified whenever the subject undergoes a change in state. In response, each observer will query the subject ot synchronize its state with the subject's state. "This kindof interaction is also known as publish-subscribe. The subject is the publisher of notifications. It sends out these notifications without having to know who its observers are. Any number of observers can subscribe to receive notifications." (p 294) I thought it was interesting GoF has the observer invoking the Subject.Update method to get the new state information. My implementations have never required that much work from the observer. Instead I just pass the relevant data along with the notification. I can see how requiring observers to call Subject.Update is a more flexible general purpose solution for Labview. By giving observers more control over when they receive updated data you can reduce the number of data copies the subject creates. I haven't run into situations where I have enough observers or large enough data sets to have to worry about that, but it's nice to know what to do in case I ever do encounter that situation.
-
Yeah, I've done it a couple times so I could easily bolt different user interfaces onto my app. (I'm terrible at making UIs look nice so I prefer to let others do that part.) UIs are the most apparent place they can be used, but there are other places where they can be useful. Acquired data usually goes to more than one place... a data logger and the UI. In some situations it might make sense to wrap your data collection component and expose it as an Observable object. (The observed object is usually called the "Subject") It does add a lot of abstraction so it can be very daunting to those not familiar with the concept. After implementing it a few times now I only use it when I am reasonably certain there will be 2 or more observers. If there's only one observer I use a SlaveLoop object instead. It's far easier to understand and the SlaveLoop can easily be wrapped up in an observable class later on if additional observers need to be added. Publish-Subscribe vs Subject-Observer Here's my (quite probably incorrect) understanding of the differences between these two concepts: In a publish-subscribe system, the publisher doesn't know how many, or even *if* any, other components are receiving the updates. It just sends out messages for whoever happens to be listening. Subscribers attach and detatch at will without the publisher knowing or caring that these things are happening. It's a true 1-to-n broadcasting mechanism. In a subject-observer system the observers "registers" with the subject, who maintains an internal list of all observers. When the observer doesn't want to receive status updates anymore, it notifies the subject it wants to unregister and the subject removes it from the internal list. I think of it as n 1-to-1 links. (These definitions seem backwards to me. When I subscribe to a magazine I have to notify the publisher if I expect to ever receive anything. And when I'm watching if I were ever to watch a cute girl crossing the street from the safety of my 3rd floor office, I certainly wouldn't run down there and tell her I'm observing her. But hey, who am I to go against convention?) As near as I can tell they both meet the same high-level goal. One object, the publisher/subject, updates many other objects, the subscribers/observers, when something interesting happens. The differences seem to come out in how they are implementated, and to some extent, what kinds of things you can do with them. Still, I see a lot of gray area between them. I'll compare them using an example of a watchdog timer component that fires every 100 ms. Publish-subscribe (PS) systems are--in principle--easier to develop. A very simple implementation is to create a loop that sends a user event when the timer expires. The publisher defines the user event data type and has a public "Get WatchdogTimerUserEvent" method that returns the user event refnum. To start receiving status updates, subscribers simply use that method to get the user event refnum and register their event structure for it. Contrast that with a simple subject-observer (SO) implementation that preserves a 1-to-1 link with each of n observers. Each observer is going to have a unique user event refnum (or queue, functionally it doesn't really matter) meaning the subject has to maintain a collection of all the UE refnums internally so all observers can be notified. Managing the collection and creating new user events every time "Get WatchdogTimerUserEvent" is called is going to take more code and add some amount of complexity to the app. So if PS is easier to implement, easier to understand, and does the same thing as a SO system, why would anyone bother with SO? There are a few reasons why I prefer it over PS, even though it takes more effort to implement: 1. Done correctly, SO is more robust than PS. PS exposes a single user event refnum to all subscribers. If one of those subscribers happens to incorrectly destroy the refnum *all* subscribers lose their connections. In SO, each observer only has access to its refnum so it can't disrupt communication between the subject and other observers. 2. Subject can self-terminate when they are no longer needed. Usually the components I consider for SO will have observers for the duration of the app. That makes it very easy to write self-terminating code that triggers when there are no observers remaining. (It's quite handy and one less thing for me to worry about during shutdown.) Producers will continue to exist until something explicitly instructs it to terminate. 3. SO systems can use queues for passing messages. PS systems must use user events. Writing apps where some components use users events to send messages and some components use queues to send messages is kind of ugly. In the general case clients need to create separate loops to service each of the queues (to make sure one of them isn't ignored by excessive messages to the other) and then forward the messages to a single common loop. There's nothing inherently *wrong* with writing an adapter loop to translate user events into queue messages; I just find it more convenient to use a single messaging technology. Anyone else have other insights into the differences? Like I said, I don't know if my explanation is correct... it's just an explanation that makes sense to me (except for the backwards definitions) and helps me differentiate between them.
-
Okay... this weekend I spent some time on this project and ended up rewriting all my unit tests. However, I do think I am getting a much better handle on how to develop unit tests. As I was working on it Saturday morning it dawned on me that my concept of what a "test" is was still too broad. After fiddling around for a while I stumbled upon the following process Sunday evening that seems to be pointing me in the right direction: 1. Create a single ListTestCase for testing the List class. 2. Go through all the List methods and add copies of all the input terminal controls to the ListTestCase class cluster. (No need to duplicate terminal controls unless a vi has more than one input of the same type.) This lets me unbundle all of the tested vi's inputs from the test case class. 3. Add public setter methods for each of those cluster elements. This lets me completely set up the testing environment in the test suite. 4. Now, looking at each List method, figure out comparisons that cover all possible output terminal values are for any set of inputs. For example, for the List:Insert method, if there's an error on the input terminal the List out object should be identical to the List in object. If there isn't an error, then List out should be different from List in. Bingo, there's two test cases right there: testInsert_ListObjectIsChanged testInsert_ListObjectIsUnchanged A few minutes of considering that quickly led to more test cases: testInsert_CountIsIncremented testInsert_CountIsUnchanged testInsert_ErrorIsUnchanged testInsert_ErrorOutEqualsRefErrorCode (This verifies Insert raises the correct error when appropriate.) Using the correct combination of 3 of those 6 test methods allows me to test the Insert method under any known set of conditions. Understanding step 4 feels like a significant advance in my overall comprehension of unit testing. After going through that with all the methods (which in fact turned out to be very straightforward and pretty quick) I set to work creating test suites to define test environments. I've only got two so far... ListTestSuite-ErrorIn, which checks the methods for correct behavior when an error is on the input terminal, and ListTestSuite-EmptyList, which checks behavior of the methods when the list is empty. I chose to use the array of strings in my test suites to define which test methods are used instead of auto-populating the list. When I'm setting up the test suite I just open the ListTestCase and look down the list of available test methods. If the name of the test method should be a true condition in the environment I'm setting up, I add it to the list. This part goes pretty quickly too. I am still not quite sure how to organize the tests that use the MockListImp object... I'm thinking it ought to be a separate test case. Still undecided on that one. Collection-List source v0.zip
-
XControls for modifying the dev environment? I know about making xcontrols for customizing an application's user interface, but I'm not familiar with using xcontrols to customize the Labview environment.
-
Using scripting to relink to a different copy of dependencies
Daklu replied to Daklu's topic in VI Scripting
Responded on JKI's thread, since that seems more appropriate for that aspect of the discussion. -
I have a few foundational reuse packages (such as a messaging library) that I use in almost all of my code, including when I'm writing other reuse code. These higher level packages will use the messaging library internally, but it is not exposed to clients. To avoid cross-linking my packages and potential version conflicts I want to include dependent packages as members of my new package's library. What I'd like is a pre-build script I could use in VIPM that would copy my reuse libraries from vi.lib to the project's directory, include them as private members of the project's library, and relink all the project source code to the new, private copies of the reuse code. Relinking needs to update the sub vis called as well as inheritance chains. So... as scripting ignorant as I am I have no idea how big a task this will be to implement or exactly what scripting nodes I should be looking at. The algorithm is mostly pretty straightforward: 1. Traverse the source code dependency trees. When I find a vi (or class) that depends on a reuse library, add the vi ref to a 'depends on' list and the reused vi ref to a 'depended on' list. 2. Iterate through the 'depended on' list, getting references to each unique top-level lvlib. 3. Copy the library's entire directory to the project directory.** 4. Add the reuse library copies to the current package's library. 5. Iterate through the 'depends on' list, replacing all instances of reuse library code with instances of the private copy. (**This might not work. I think it depends on when exactly VIPM calls the build script during the build process. I posted a question about it on JKI's forums.) Any tips or ideas on the easiest way to do this?
-
I am very much aware of that. It also occurs if the namespace changes, such as by changing the library nesting heirarchy if you're into that sort of thing. That's exactly why most people don't depend on automatic serialization. (And mutation history doesn't have any impact whatsoever on the bundle/unbundle nodes contained within class methods.) However, you said, "what happens if you rename a classes VI," not "what happens if you rename a class." Renaming a vi does not affect mutation history. <snarkiness> In the future I'll do my best to respond to what you think you wrote instead of what you actually did write. </snarkiness> You are misunderstanding my intentions. I'm not trying to convince the Labview world to start developing OOP applications. Designing good OOP apps is actually quite hard when first starting out. Designing good single-point reuse OOP code is even harder. This discussion has focused on the contrast between using clusters and using classes to pass data between different parts of an application. Using a class as nothing more than a data container to replace a cluster is dirt simple. My point in the original post and in this discussion is this: 1. There is an issue with typedef cluster propogation that many people are not aware of. 2. Here are situations where one might unwittingly encounter this issue. (Listed earlier.) 3. If these situations are possible in one's workflow using a class instead of a cluster provides protection that prevents this problem from occurring. Your solution to the issue was to set up your workflow so all dependent vis are always loaded into memory whenever you edit the source code. That's fine. It works for you. But there are other equally valid workflows where that isn't an option. For those people, using a class is the only way to ensure they will not encounter that issue. I can't commit to anything right now. It's the busy season at work, christmas is upon us, my wife is recovering from major knee surgury, LapDog is behind schedule, I have presentations to prepare for the local users group, etc. Besides, I honestly do not see the point. Classes clearly provide me with a lot of added value while you get little benefit from them. What would be the goal of the exercise? Additionally, comparing procedural code to OO code using a pre-defined, fixed specification will always make the procedural code look better. The abstraction of classes is a needless complication. The benefit of good OO code is in it's ability to respond to changing requirements with less effort.
-
Insufficient customization options over the development environment. There are lots of actions I'd like to assign keyboard shortcuts to but can't. I'd like to be able to create custom toolbars move them around where I want. Menus (especially right click menus) are overpopulated and I wish there was a way to make them "smart" where they show items that are used frequently and offer a way to quickly expand to see all the options. I actually like the new window better than the old style. When I have a lot of probes going I find it very useful to be able to refer to a single list of probe values that describes the application's state at any one time. That said, the UI definitely needs usability improvements. Resizing the window in particular is implemented all wrong.
-
Lava. Without it nothing else would have mattered for me. Yeah, it's not really an *official* Labview design feature, but it's the best learning/documentation resource that's available. The Blues that freely share their insights here are a big part of that.
-
Just curious Ben, didn't you ever release new versions of your reuse libraries and what did you do when a cluster would benefit from an update? I used to think that too until AQ and someone else (Adam Kemp maybe) straightened me out. Project libraries will check to make sure all the necessary files can be found, but it doesn't actually load them. (Though it does load sub-libraries.) I have no idea if vis are "loaded enough" for cluster edits to propogate through the library. The details of when something is actually loaded seem rather obscure... I saw a post once from a blue referring to something along the lines of, "dependent vis 4 or more levels down aren't loaded..." (I'm sure I've completely misrepresented what the post really said. I didn't pay much attention at the time and haven't run across it again.) Now, Shaun could create a single class and put all his project vis in there, but he might well have an aneurysm if he tried that. Yeah, with a pink slip wrapped around it. You probably could... of course, I'm not wishing NI to give me another solution to a problem they've already solved. Yep, there are. And they all need to have good answers because they are all valid ways in which people use Labview. The question was meant to illustrate the kinds of scenarios people will encounter, not presume that you in particular will do these things. Loading all the vis in the project is a solution to cluster propogation if and only if, 1) Every vi that depends on the cluster is part of the project, and 2) One always open the project before editing your code. If those requirements fit into your workflow, as it appears they do, great! But people do work outside of those limitations. I'm not trying to say your dev habits are wrong; I'm simply pointing out that isn't a very good general purpose solution to the problem of cluster propogation. If copy and paste reuse works for you, it's certainly an easier way to go about it. The tradeoffs aren't workable for everybody. That's right! Sorry, I forgot. We're Labview programmers... we expect NI to write our code for us. Really? You're equating the simple act of replacing a typedeffed cluster with a class to that of writing C++ code? "Fixing" the cluster to prevent the propogation issue is a lot like fixing up the family minivan to compete on the F1 circuit. You might be able to get close to the desired performance, but it's going to take a lot of hacking, duct tape, and it ain't gonna be pretty. Renaming a class vi has no impact on mutation history.
-
No, they aren't immune to mistakes, and I didn't mean to imply they were. But they are more robust to common mistakes than typedeffed clusters. They correctly handle a larger set of editing scenarios than clusters. No it isn't. I believe you're focusing on how it would fit into your specific workflow, not how it would work in the general case. Using Tree.vi loads only those vis you want loaded. Usually it's all the vis in the project. What happens if vis not in the project also depend on the cluster? What happens if people aren't even using projects? Should those non-project vis be loaded too? Fixing this issue using an auto-loading system requires those vis be loaded. What if you've deployed reusable code to user.lib and want to update a typedeffed cluster? You'll have to dig out *every* project that has used that code and put it on your machine before you can update the typedef. No thanks. How should LV react if it can't find some of the dependent vis? Disallow editing? Disconnect the typedef? Two-way dependencies between the typedef and the vi simplifies a certain subset of actions, but it creates far more problems than it solves. Not me. That's death for large projects. 6-10 minute load times are no fun. By "class editor" are you referring to the window that looks like a project window that pops up when you 'right click --> Open' a class from your project? There isn't much difference between them because it *is* a project window. Labview opens a new project context and loads the class into it for you. The reason the "class editor" loads everything is because loading a class (or any class members) automatically loads everything in the class. It's a feature of the class, not the "class editor." [Edit - I was wrong. It doesn't open the class in a new project context. Given that it doesn't, I confess I don't see an advantage of opening the class in a new window?] Okay, so since there's no practical way to ensure ALL dependent vis are in memory, the only way to guarantee consistent editing behavior is to not propogate typedef changes out to the vis at all. I'm sure the Labview community would support that idea. They did fix it. They gave us classes. Any solution to this problem ultimately requires putting more protection around bundling/unbundling data types. That's exactly what classes do. Using classes strictly as a typed data container instead of typedeffed clusters is *not* a completely different paradigm. (There are other things classes can do, but you certainly don't have to use them.) You don't have to embrace OOP to use classes as your data types. You get load errors, which is vastly more desirable than behind the scenes code changes to the cluster's bundle/unbundle nodes. Besides, the risk of renaming a vi is *far* better understood by LV users than the risk of editing a typedeffed cluster. I didn't mean to give that impression. At the beginning of the thread I mentioned I don't pursue OOP for it's own sake. My goal is component-based development and that OOP makes it easier for me to achieve that goal. You can have reasonably well decoupled applications using the structured approach. It is harder to achieve the same level of decoupling with typedefs as you can with classes, but that doesn't mean structured apps are tightly coupled. Disagree. (Surprised? ) Regardless, that isn't all it is used for; it's just one way classes can be used. Or maybe it's time for some "old timers" to discard their prejudices and see how new technologies can help them. You're not far off. Most of our projects are fairly small, maybe 1 to 2 months for a single dev. We do usually have 1 or 2 large projects (6-24 months) in progress at any one time. Since I build tools for a product development group, we don't have the advantage of well-defined requirements. They change constantly as the target product evolves. At the same time, we can't reset a tool project schedule just because the requirements changed. Product development schedules are based around Christmas releases. Needless to say, missing that date has severe consequences. During our rush (usually Sep-Mar) we have to build lots of tools very quickly that are functionally correct yet are flexible enough to easily incorporate future change requests. (The changes can be anything from updated an existing tool to support a new product, to using different hardware in the test system, to creating a new test using features from several existing tests, to creating entirely new test system.) Reusable component libraries give me the functional pieces to assemble the app. Classes give me the flexibility to adapt to changing needs. It could if you built in a hardware abstraction layer.
-
[Edit - After typing all this up, I realized you're asking for a broken vi, not automatic mutation. While that has some similar problems of it's own, it's not the question I was addressing with my response. Sorry about that. I'll leave the text just in case somebody comes along wondering about automatic mutation.] Technically you may be correct, though it still wouldn't give you the user experience it appears you think it would. If you can tolerate my lengthy explanation I think you'll see why. First, the reason classes behave correctly in the example I posted is because all the vis that bundle/unbundle the data are loaded into memory during the edits. NI has taken a lot of flak from users (me included) for the load-part, load-all functionality built into classes, but it was the correct decision. So the first question is, do you want Labview to automatically load all the vis that bundle/unbundle the typedeffed cluster when you open the ctl? I'll go out on a limb and guess your answer is "no." (Besides, implementing that would be a problem. There really isn't a good way for the typedef to know which vis bundle/unbundle the data.) So for this behavior to exist, the ctl needs to maintain a version number and mutation history of all the edits and a that have been made to it. That (theoretically) would allow the vi that bundles/unbundles the cluster, the next time it loads, to compare its cluster version against the current cluster version and step through the updates one at a time until all the changes have been applied. As a matter of fact, NI has already implemented this exact scheme in classes. Not to make sure the bundle/unbundle nodes are updated correctly (that's already taken care of by the auto-loading behavior,) but for saving and loading objects to disk. Consider the following scenario: 1. Your application creates an object containing some data, flattens it, and saves it to disk. 2. Somebody edits the class cluster, perhaps renaming or reordering a few elements. 3. Your updated application attempts to load the object from disk and finds the object's data cluster on disk no longer matches the class' cluster definition. This is where the class' mutation history kicks in. The class version number is stored on disk with the object data, so when the data is reloaded LV can step through and apply the updates one at a time, until the loaded object version matches the current class version. Sounds perfect, yes? As it turns out, automatic class mutation is very error prone and subject to fairly esoteric rules. It is risky enough that most developers write their own serialization methods to manually flatten objects for saving to disk rather than letting LV automatically flatten them. This is not a failure on NI's part. It is simply because there is no way for LV to definitively discern the programmer's intent based on a series of edits. Suppose I do the following edits to the class cluster: - Remove string control "String" - Add string control "String" - Rename "String" to "MyString" Was my intent for the data that used to be stored in "String" to now be stored in "MyString?" Possibly. Or was my intent to discard the saved data that used to be stored in "String" and create an entirely new field named "MyString?" That's possible too. Both scenariors are plausible. There's simply no way LV can automatically figure out what you want to happen, so it makes reasonable educated guesses. Unfortunately, it guesses wrong sometimes, and when that happens functionality breaks. Giving clusters a mutation history isn't a real solution to this problem. It will just open another can of worms that has even more people screaming at NI to fix the "bug." The solution is for us, as developers, to recognize when our programming techniques, technologies, and patterns have reached their limitations. If we have requirements that push those things beyond their limits, the onus is on us to apply techniques, technologies, and patterns that are better suited to achieving the requirements. [/soapbox] I'm not sure why you think that. Most of the code I write is statically linked, yet I consider it reasonably well decoupled. In general, nobody should use a particular technique "just because they can." If you're going to spend time implementing it you ought to have a reason for doing so. But I'm not advocating a plug in architecture so I'm not sure who you're protesting against...?