

Matt W
-
Posts
63 -
Joined
-
Last visited
-
Days Won
7
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Matt W
-
-
I thought about this a while back.
Labview has no concept of "NULL" string. We can neither create it nor check for it. If we put a string control / constant down, we can only have an empty string (and any of our VIs that accept a string will have a string control).
So the choice becomes do we allow a write to a NOT NULL field to always succeed (which is what will happen with your suggestion) or do we define an empty string in LV as being the equivalent to a NULL string. I think the latter is more useful.
[/size][/color]
Good job I cannot take back the rep point eh?

I have a variant interface for differentiating nulls and empty strings when needed (which I need in my case). But with a pure string interface, making an empty string null is more useful.
[edit] this seems to be wrong
If you want an empty string to be written as NULL then you need to make sure the value passed doesn't point to null (just replace the 0 in my fix with any other number).
[/edit]
It seems an empty arrays are pointer to 0 which is why SQLite makes it null, not that it doesn't point to a /00 character.So you don't need to fix your current version to keep empty string as null.
-
I get error code 19 with your 1st snippet
Abort due to contraint violation
SQLite_Error.vi:2>SQLite_Bind Execute.vi>SQLite_Insert Table.vi:2>Untitled 1
If the field is not declared with NOT NULL it succeeds.
Exactly, without the fix the empty string is bound as a NULL (unless the pointer passed to the dll happens to point to a \00), which fails the constraint. With the fix it get's bound as an empty string and passes the constraint.
I figured out the 2x size 32 bit example slowed down. I had left the speed test front panel open, without the front panel being open it doesn't slow down.
-
Found a bug while optimizing mine that affects yours as well.
If you insert a blank string it'll probably be bound as a NULL.
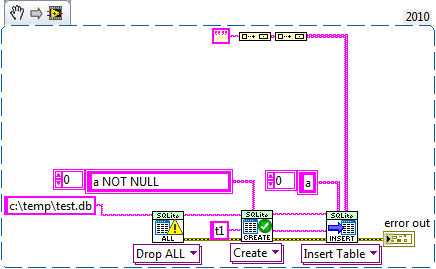
It can be fixed if the empty string passed to sqlite3_bind_text is null terminated (I'm not sure if this is a bug with sqlite or a undocumented feature to allow writing nulls with string binding).
Inserting as a string instead of a byte array also fixes it since LabVIEW will null terminate all strings passed to the CLN.
-
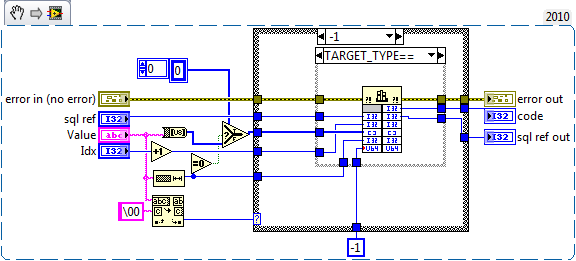
Indeed. It was an oversight. It should have been -1. I don't think an IPE is really the way forward as I don't see any performace difference between 0 and -1 (KISS).
The speed difference between 0 and -1 it should be more apparent when inserting large data elements.
I consider it as a Labview limitation rather than the API, In theory they should behave identically regardless of the implementation specifics. Differences between compiling in different IDEs is a little disconcerting since I think we all assume that what works in one will work identically in the other. But it looks like one of those "not a bug. not desired" effects.
But good call. on finding a probable explanation (your C experience obviously shining through). I think it will be rare occasions that anyone will be querying that many records at a time and it is still an order of magnitude faster than other DB implementations (like Access). You never know, they might optimise it in LV 2011 2015.
There's limits on how much of the hardware details one can abstract away before you start losing performance. NI could double the chunk size in 64bit, but then you get a difference when working with arrays not containing pointers. Using exponential size increases is better theoretically but can lead to out of memory issues (This wouldn't be much of a problem on 64 bit). I would be probably lean toward using exponential allocation on 64 bit and leaving 32 bit with the chunk allocator, the code would perform differently (extremely in some cases) between the two but 64 would get a nice speed boost when allocating large arrays from while loops.
-
I'll release the next version a little earlier than planned (later today) since it will eradicate this (well spotted). Funnily enough. It only seems to happen on LVx32. x64 is fine.
My understanding of the problem is that the bound data isn't read until you step the statement, and labview may unallocate the data passed to the dll by that point (in this case it's reusing the data pointer from null terminated copy for both calls), by passing -1 sqlite makes it's own copy of the data before returning.
The next release passes an array of bytes to the bind function, which is faster than passing a string even with the conversion to a U8 array. It also removes the aforementioned "bug".
The conversion should be free (it's just a static type cast). Passing the array avoids LabVIEW making a null terminated copy, which should speed things up. But you need to be certain LabVIEW doesn't deallocate the memory the string data until after you've stepped the statement. I think the IPE can do that (that's how I interpret it's help entry), but I'm not absolutely certain what the IPE structure does at a low level. Without the IPE (assuming it does make that guarantee), your risking the compiler deallocating it. Different platforms, future versions of LabVIEW, and different optimization cases may break it. I'm using -1 just to be safe. I would suggest you at least use an IPE to be sure the relevant string data is in memory. If you can find documentation that the IPE will always delay deallocation, let me know then I'll switch over mine as well .
The API already supports reading strings containing \00 (since V1.1). The field just needs to be declared as a blob. I did agonise about making it generic (just involves a direct replacement of "Fetch column" with "Read Blob"), but decided the performance advantage of not using the generic method outweighed the fact that you just have to define a field type.
I had the requirement on mine that any data I put in comes out exactly the same (which as far as I can tell is true with my variant interface, assuming a columns type affinity doesn't mess with things). And since strings in LabVIEW can contain /00, reading them is a requirement in my case.
Well. I don't think that is the issue, since the later tests should have reduced the allocation to a smaller difference and I would have expected the x32 to be more like the x64 - which it isn't. Sufficed to say, there is a difference and, that LV x64 is vastly less efficient at building large arrays of strings than x32 (which I find surprising).
The problem is LabVIEW is allocating a array (arrays need a continuous chunk of memory) of string pointers in the while loop autoindex. When that array fills LabVIEW makes a new array larger array and copies the old one into it. The copy is the main cause of the slow down. Now LabVIEW seems to increasing the size of the new array in chunks (at least when the array is large). And since in 64 bit the pointers are twice the size the array needs to be resized and copied twice as often. Since the copies cost depends on how much data is getting copied, this leads problem getting exponentially worse with increasing array size.
If I'm correct the size of data elements should not affect when the exponetional error starts showing up, and the 32 bit should look like the 64 bit when reading the twice the number of rows as the 64 bit.
Which is the case.
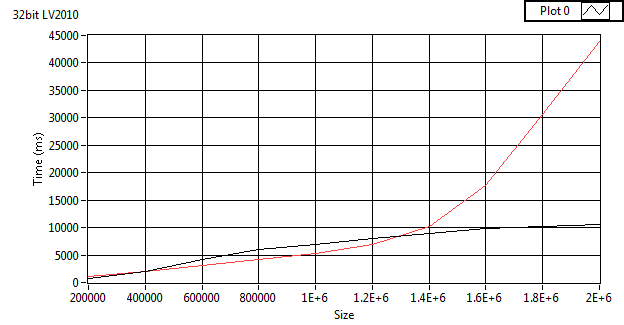
This can be avoided by growing the array exponentially (for example doubling it's size when filled), but you'd have to code that by hand (and it's slower since I used to do that before I saw the autoindex in yours). You could check if the returned array has reached a size, this say number of columns * number of rows read = 500000 (and half that limit in 64bit), then switch to doing exponentional growth by hand.
-
 1
1
-
-
I found that the speed example also has the same problem. It does not write PASS to the first column. It writes the value in both columns in the DB. Please correct me if I am wrong.
Thanks,
Subhasis
You're correct there is a bug in SQLite_Bind.vi change the 0 on the bottom to -1 and it'll work.
The string array is an array of pointers to the individual strings (I wasn't thinking right with my original explanation
 ) so extending the inserted data shouldn't change the performance of the while loop index. The reason the strings need to stored as pointers in an array is because they have unknown lengths. If they where stored in one huge block then to index the array you would have to read all the earlier strings. As an array of pointers you can calculate exactly where the offset is with a single multiplication and addition.
) so extending the inserted data shouldn't change the performance of the while loop index. The reason the strings need to stored as pointers in an array is because they have unknown lengths. If they where stored in one huge block then to index the array you would have to read all the earlier strings. As an array of pointers you can calculate exactly where the offset is with a single multiplication and addition. A little more info here on what I'm talking about
http://en.wikipedia....ide_of_an_array
A lot of LabVIEWs array operations just adjust stride lengths and array pointers which avoids data copies. Off the the top of my head this should include any form of indexing, subset, and reshape array (assuming the new size fits)
I'll try to figure why mine shows the problem in 32bit, since last I checked our implementations of select should be exactly the same on the index memory requirements.
I must of ran my 32 bit test in 64 bit since the problem no longer shows in 32bit.
I think you are describing a **char. When I iterate over the rows and columns, I only retrieve a "C String" type (*char), which I then build into a 2D array. The Labview CLN automagically dereferences this to a labview string (i.e it adds the length bytes and truncates at \00). In this sense, it is a pointer to an array of bytes rather than an array of pointers.
I'm saying that internally LabVIEW string ARRAYS are an array of pointers to pascal strings. The CLN interface has nothing to do with it.
On a side note.
I would suggest just binding everything as a string, then you can speed up the binding by not checking for \00 and just inserting the data as if it was there (string length is constant time in LabVIEW but searching for /00 requires checking each byte of the string). Then you just need to add support for reading strings containing \00.
-
That doesn't make a lot of sense to me. Surely pointers are just references to where the data is stored rather than being stored as part of the data.
But I ran the tests again to make sure. This time inserting 500 chars rather than the <10 as before. Everything else is the same apart from taking an average of 5 to cut down the test time.
Pretty much the same. There must be a difference between the memory managers and the way x64 manages allocation. Surprising really. I would expect LVx64 running on a x64 windows platform to outperform a x32 app.
The string array is an array of pointers to the individual strings (I wasn't thinking right with my original explanation
) so extending the inserted data shouldn't change the performance of the while loop index. The reason the strings need to stored as pointers in an array is because they have unknown lengths. If they where stored in one huge block then to index the array you would have to read all the earlier strings. As an array of pointers you can calculate exactly where the offset is with a single multiplication and addition. A little more info here on what I'm talking about
http://en.wikipedia....ide_of_an_array
A lot of LabVIEWs array operations just adjust stride lengths and array pointers which avoids data copies. Off the the top of my head this should include any form of indexing, subset, and reshape array (assuming the new size fits)
I'll try to figure why mine shows the problem in 32bit, since last I checked our implementations of select should be exactly the same on the index memory requirements.
-
Definitely the former.
If I pre-allocate the array and replace elements rather than auto index, then they perform exactly the same. But what I'm confused by is why there should be a difference between x32 and x64. After all, it should be the same amount of memory being (re)allocated and it is a LV internal implementation.
The desktop trace tool can help figure out how memory is getting allocated if you really want to into the details.
My guess is that since each string includes a pointer there is an extra 4bytes for each string in 64bit, and since each string is rather short in this test, the extra 4 bytes makes a significant difference in the memory needs of the different platforms.
As for working around it, I can think of a couple of options.
Return the data in chunks instead of all at once either through limit/offset, or by partially stepping through the statement to collect each chunk. The later is probably faster since the former may need to reevaluate early rows.
Figure out the size of returned data before allocating it. I think count(*) with the same where clause should work, but SQLite has to run through all the rows twice. You my also be able to use a temporary table to hold the result then calling "select count(*) from temptable" might not need to evaluate every row (I'm not sure).
-
I get the same thing on LV2010 on win 7.
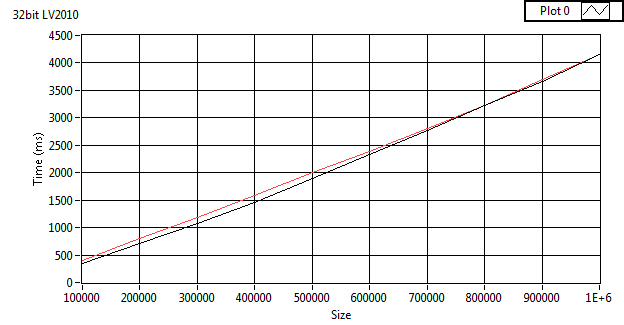
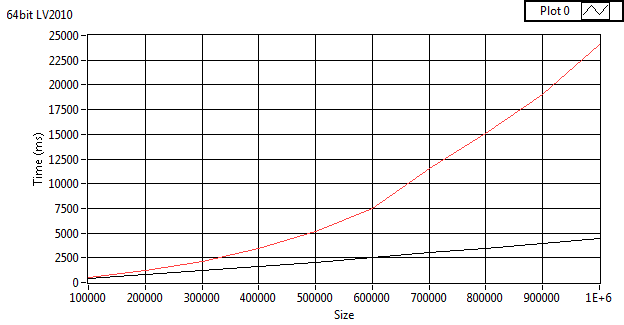
I ran it it on my code, and get the same issue in 32 and 64 bit, although it takes longer to show on 32bit. I'm not sure on the cause. I was doing stuff while testing mine so the results might be a bit skewed.
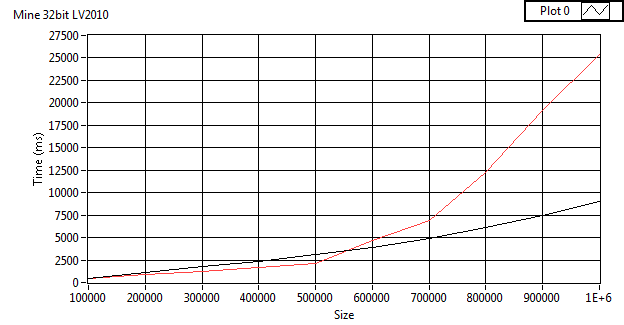
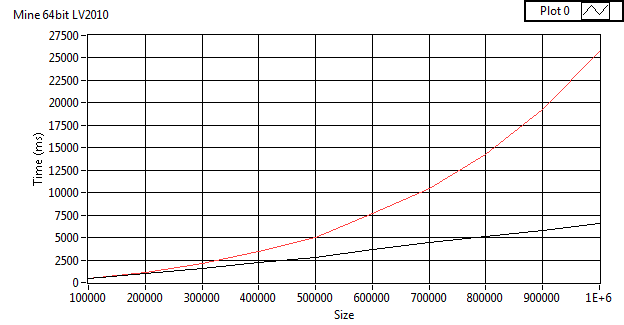
I'm not sure if I have time to help track down the issue. My first guess would be with memory allocation. Perhaps on the autoindexing on the while loop (if the allocation size is increased in limited sized chunks instead of exponential growth this could happen). Or maybe memory fragmentation (I'm not sure what algorithm LabVIEWs garbage collection uses, but I doubt it's compacting). The desktop trace tool can be used to check the while loop. Fragmentation would be harder to figure out.
-
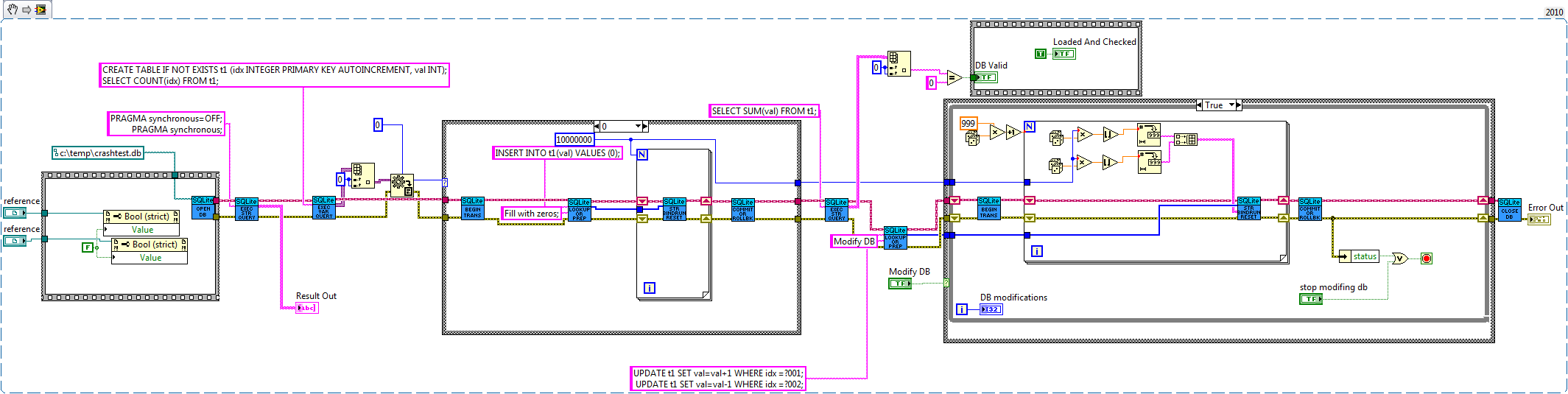
Well. I cannot replicate your test because you haven't released the VIs. But I ran the speed test inserting 1,000,000 rows with version 1.2 and reset the PC. After 12 resets the DB was fine although Labview forgot all its palette settings on the 3rd reset . At that point I got bored since it takes about 1 minute for my PC to boot
Inserting just appends data, which is far less likely to suffer corruption. To have a high chance of corrupting data you need writes for one transaction to be spread around the hard disk (due to the reordering), which is why my test db is 100 megs (my terrible fragmentation is helping for once). Anyway I ported my corrupter to your library, got silent corruption on the first run (a full database check couldn't see it either, which answers one of my earlier questions, this is probably because my test is unlikely to change the database structure unless you let it modify for a very long while). Basically the code fills a database with 10 million zeros. Then if modify data is turned on it continuously selects an amount of value pairs (up to 1000) to change, one member of the pair is increased by one the other decreased by one, all of the pairs changes are done within a transaction. So if all transactions run properly the sum of all the values will be zero (this is how I'm checking for silent corruption).
The library looks much nicer now, with better documentation (and more consistent spelling
 , mind you my grammar and spelling can be quite lacking sometimes). I see your using binding with the inserts now. Now if you add sqlite3_column_bytes and moveblock to your fetch's, and use string length with nbyte on your binds you'll be able to read and write strings containing /00. I could email you a copy of my code if you want to compare (you can pm me an email address). Said copy is only to be used for comparison, and put a mention for any of my tricks you port over to yours. We could mix your high level interfaces with my low level stuff, but our styles probably clash too much for that. I still need to pick a license for mine. I want something like lgpl but I don't think that is usable without dynamic linking.
, mind you my grammar and spelling can be quite lacking sometimes). I see your using binding with the inserts now. Now if you add sqlite3_column_bytes and moveblock to your fetch's, and use string length with nbyte on your binds you'll be able to read and write strings containing /00. I could email you a copy of my code if you want to compare (you can pm me an email address). Said copy is only to be used for comparison, and put a mention for any of my tricks you port over to yours. We could mix your high level interfaces with my low level stuff, but our styles probably clash too much for that. I still need to pick a license for mine. I want something like lgpl but I don't think that is usable without dynamic linking. -
Hi,
I have just started to use SQLite. I downloaded this toolkit and inserted data to a database using the insert function. But it seemed to be too slow. Is there any functionality in the toolkit, where i can do bulk insert into the db. I have never used any db before. So, I don t know about how fast it could be.
My application requires me to write 500 rows and 5 columns of data into one table and about 5 rows and 2 columns into another table in less than 500 milliseconds. Can I do this using bulk insert. Or is there any other way to do this.
Thanks in advance,
Subhasis
To get it to go fast you need to put all of the inserts into a single transaction. By default SQLite does a lot of extra work make sure the data is safely on the disk, that extra work happens per transaction.
With the current release of ShaunR's library the simpliest way is to put all the inserts together into a single query (see the speed example in the library). There are some other ways if that doesn't work for you for some reason.
-
That is an interesting article. But it is very Linux oriented (in particular XSF and changes between kernel versions). I don't know much about Linux file systems. But I do know NTFS does not suffer from this and the only currently supported OSs are windows.
From Microsoft
http://msdn.microsof...28VS.85%29.aspx
With asynchronous I/O support, kernel-mode drivers do not necessarily process I/O requests in the same order in which they were sent to the I/O manager. The I/O manager, or a higher-level driver, can reorder I/O requests as they are received. A driver can split a large data transfer request into smaller transfer requests. Moreover, a driver can overlap I/O request processing, particularly in a symmetric multiprocessor platform, as mentioned in Multiprocessor-Safe.If NTFS didn't suffer from this It would perform far slower than Linux filesystems. Reordering operations for performance is a very common technique. Outside of Disk IO, most non embedded cpus and compilers use instruction reordering.
"fsync" and "write barriers" are not the same thing. The latter is a firmware feature and the former is an OS function. Admittedly, on some OSs (read Linux) you can turn it on or off. But you cannot under Windows (I don't think).
They're not quite the same thing. Write barriers are a concept that apply to more than file io (although most forms I can think of need hardware level support). fsync functions as a heavy handed write barrier. A lighter write barrier probably perform better, recent transactions wouldn't necessarily be on the disk, but you wouldn't get corruption.
That depends. If the programmers are mainly non-windows programmers,then they may not mention it since they use a "cover-all" statements. After all. If they were wanted NTFS to be "utra-robust" and were worried about ll this. then they could have used "CreateFile" with the "FILE_FLAG_NO_BUFFERING" and "FILE_FLAG_WRITE_THROUGH" options. then they would not need "FlushFileBuffers" and not have the overhead associated with it..
I think you'll find the overhead of those two options is far worse than FlushFileBuffers in SQLite. With FlushFileBuffers SQLite is equally ultra robust and faster (baring bugs in the OS/Hardware, that may also affect those two CreateFile options).
Your making a bit of a meal out of this. There are better ways to ensure data-integrity if the data is that important. Don't forget. I'm not "removing" the functionality. If you really feel strongly about it then you can just turn it on. Although I suspect you will never use the API since it is natural to prefer your own in-house solution.
I'm trying save someone a massive headache when they suffer a power outage/os crash and they lose data or at best suffer down time restoring a backup. Corruption is far more likely with a SQLite database with sync=off than most file types, since it involves more write requests in odd orders. The assumption for the average user is that a database is "safer" than normal file io (the D part of ACID compliant). I would much rather the user lookup the options for making his code faster (and learn the risks/difficulties of the different options), than lookup why their data is now trashed, and how they should have turned synchronous to full for their use case. I think this is the majority of use cases, in spite of peoples need for speed. Also they'll only find out about this in your documentation not SQLites. If the user wants to shoot themselves in the foot I'd rather let them load the gun.
Anyway good use of transactions/savepoints can reduce a lot of speed decrease from synchronous=full. Another option is to make a unsafe database, that get's copied over to an attached safe database every so often.
Also I wrote a crash test on Win7, I hit the reset switch on my computer while the modification count was increasing. I got database corruption, first try too. This didn't happen with full sync, of course that ran much slower.
PLEASE at absolute bare minimal put an easy to find warning about how their data is not safe by default, unlike normal SQLite, and how to fix it.
-
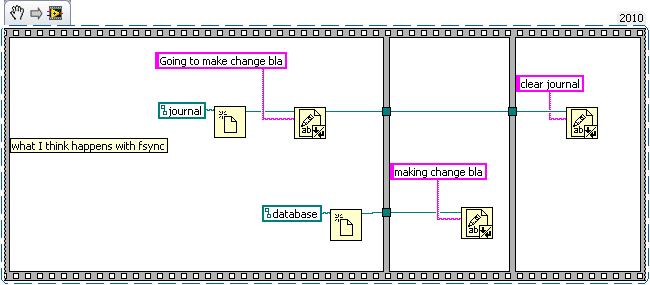
The order is pretty much dictated by the way the application is written and has little to do with the cache.
The order of writes to the hard drive is determined by what how the OSes elevator algorithm wants to sort the write requests in the write cache. The hard drive can also reorder things when they reach its cache. The application order determines when things are put into the cache. From the perspective of the programmer it appears that it happens in order, since the OS keeps the read cache directly in sync with the write cache.
Here's the best description I've found online of some of issues.
http://www.linux-magazine.com/w3/issue/78/Write_Barriers.pdf
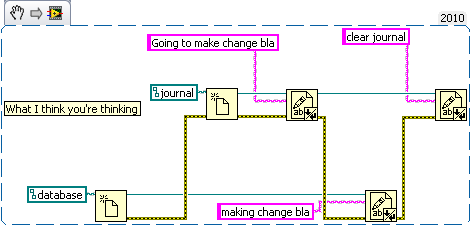
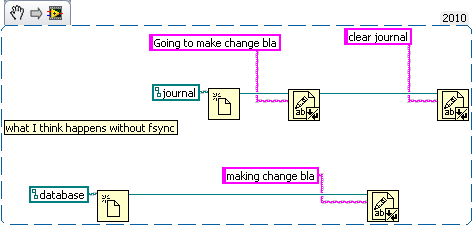
If you write an application as in your second example, then sure, you cannot guarantee the order because you cannot guarantee the order that Labview will execute those functions.
My example code was an attempt at illustrating what happens at the hard drive level (it's not real code, but LabVIEW seemed an good choice for showing order of operation issues). Basically that the implicit order of the application doesn't apply at the hard drive level. But you can enforce an ordering with write barriers (fsync). I was mistaken about needing two files for there to be a problem, since a transaction in sqlite involves more than write request to the journal, and can easily take more than one the database file (so it's worse than I said). After looking more into it, I think that, with synchronous off, database corruption is quite likely if there's an OS/Hardware failure during a write.
Anyway if synchronous=off, on journaled filesystem was safe, you would think somewhere on the sqlite website (or mailing list) someone would mention the safe easy way to drastically improve speed on virtually all modern desktops, workstations and servers.
Also if you really don't want to believe me about the reordering. NTFS only journals the metadata, not application data. In other words the file systems structure is safe from a crash but not files being written to it.
http://en.wikipedia.org/wiki/NTFS#NTFS_Log
As does EXT3 by default (ordered)
http://en.wikipedia.org/wiki/Ext3#Journaling_levels
Although in EXT3 appened and making new files is as safe as the full data journal mode (I don't know if this also applies to ntfs). But SQLite often writes in the middle of the file.
In other words synchronous off is a very bad default setting.
-
Indeed. The OS does see the journal file as just a file (it couldn't see it any other way). But I think we would all be in trouble if we couldn't rely on the OS to write files in a certain order. Imagine overwriting a value in a text file. I don't think it would be very useful if we couldn't guarantee that the second value we wrote wasn't the final value.
I'm talking about the ordering between multiple files not a single file. The write cache handles single files just fine.
I think "integrity_check" is designed to detect database structure corruption. Have you tried to change a non-data byte?
My point was I'm not sure if a lose of power with fsyncing will necessarily lead to a detectable corruption (I think it would catch some if not the majority of cases). Just because the structure is valid doesn't mean the data returned is correct.
Ahhh. You have to be careful here. You are using "stream" functions which are memory resident. SQLite (quite sensibly) uses "WriteFile". Additionally. It uses "WriteFile" in non-overlapped mode.
You're correct that is safe from an application crash (I think the write and read commands used for unix should also be safe). I thought it was using the standard c functions (fopen,etc) which also lose data like the c++ ones.
While browsing the sqlite source I found
**...Transactions still work if synchronous is off,
** and the database cannot be corrupted if this program
** crashes. But if the operating system crashes or there is
** an abrupt power failure when synchronous is off, the database
** could be left in an inconsistent and unrecoverable state.
** Synchronous is on by default so database corruption is not
** normally a worry.
Indeed. As I said previously. "Query By Ref" is synonymous to "exec". So all you need is "Open", "Query By Ref" and "close". There is no need for an intermediate layer since the high level API is just a wrapper around the query functions. (In fact "Query Transaction" uses Query By Ref"). So. Nothing is precluded. Its just deciding what should be elevated to the higher levels.
I was thinking that those three should be put in their own folder (being the only ones outside of the main api that I could see someone using).
-
The journal (either SQlites or the File systems) is always written to before any updates to the actual file(s) and the transaction is removed after the completion of that operation. In the event that something goes wrong. The journal is "replayed" on restart, therefore any transactions (or partial transactions) still persisting will be completed when the system recovers. The highest risk area is that a transaction is written to the DB but not removed from the journal (since if it exists in the journal it is assumed to be not actioned). In this case, when it is "replayed" it will either succeed (it never completed) or fail silently (it completed but never updated the journal). This is the whole point behind journalling. In this respect, the SQLite DB is only dependent on the SQLite journal for integrity. The OS will ensure the integrity of SQLites journal. And SQLite "should" ensure the integrity of the DB.
However. If the file system does not support journalling. then you are in a whole world of hurt if there is a power failure (you cannot guarantee the journal is not corrupt and if it is, this may also corrupt the DB when it is "replayed"). Then it is essential that SQLite ensures every transaction is written atomically.
Without syncing there is no guarantee that sqlite's journal file is written to disk before it's database file. The write buffer isn't a FIFO, it reorders to optimize bandwidth (the harddrive cache may also reorder things).
(LAVAG keeps erroring when I try to link urls so I have to type them out) http://en.wikipedia.org/wiki/NCQ
The OSes journal is an exception since it can adjust the buffers order (or use some kind of IO write barrier).
http://en.wikipedia.org/wiki/Write_barrier
As far as the OS is concerned sqlite's journal is just a file like the database.
It ( intergrity_check) would be pretty useless if it didn't. I think it is fairly comprehensive (much more so than just a crc) since it will return the page, cell and reference that is corrupted. What you do with his info though is very unclear. I would quite happily use it.
I just hex edited a string saved in sqlite database, it still passes the integrity check, a crc would catch this kind of corruption. The question is whether it's catches errors caused during crashes with sync turned off (my guess is it gets some but not all).
I could not detect any difference in performance between any of the varieties.There are no extra DLL calls (you just use the different syntax) or lookups (its all handled internally) and, as I said previously, it is persistent (like triggers). Therefore you don't need to ensure that you clear the bindings and you don't have to manage the number of bindings. It's really quite sweet
 In my high level API, I now link to variable name to the column name (since the column name(s) must be specified).
In my high level API, I now link to variable name to the column name (since the column name(s) must be specified).Then I must be missing something because all the binding functions take a parameter index not a name. To use a name I need to call the dll to figure out what name is bound to that parameter index.
http://www.sqlite.org/c3ref/bind_blob.html
http://www.sqlite.org/c3ref/bind_parameter_name.html
I think here you are talking about an application crash rather than a disk crash. If the disk crashes (or the power disappears), its fairly obvious what when and why it happened. For an application crash, the fsync (flushfilebuffers?) is irrelevant.
Try it yourself.
#include <iostream>#include <fstream>using namespace std;int main(){ std::ofstream fout; fout.open("example.txt"); for (int i=0; i<100000; i++){ fout << i << "\n"; } fout << "input done" << "\n"; //replace "\n" with endl which flushes. then the last input before the crash will be there, currently on my system the last 5 lines are lost if I don't sync. int *nullptr = 0; *nullptr=1; //crash before closing fout.close(); return 0;}Excellent example.
The more I think about this. The more I think it is really for power users. My API doesn't prevent you (the user) from using save-points with the low level functions, after all it's just a SQL statement before and after (like begin and end). However. It does require quite a bit of thought about the nesting since a "rollback To" in an inner statement will cancel intervening savepoints so you can go up, down and jump around the savepoint stack.
In terms of bringing this out into the high level APIs. I think it wouldn't be very intuitive and would essentially end up being like the "BEGIN..COMMIT" without the flexibility and true power of savepoints. Maybe a better way forward would be to provide an "Example" of savepoints using the low level functions.
One way of doing my example without save points is to have the subvi's concatenate strings into a query that is run separately (this work around can't replace savepoints in all cases though).
Savepoints are easy for users to implement as long as there's an easy way to keep the database connection open between different calls. A midlevel api might work well in your case just something that handles preparing, stepping and column reading. The low level open and close vis and can be raised to the mid level api.
-
A good quality hard-disk will guarantee that data held in cache will be flushed on a power failure or brown-out condition (50 ms is required for CE approval). Which is probably longer than a couple of disk revs. From then on its up to the OS to re-construct using the journal. I think the real risk is if the file-system doesn't have journalling and therefore can exit in the middle of a write operation..
I think the problem is that journal only maintains consistency (well not quite) on a single file while sqlite needs two files to be consistent with each other. Without syncing (which acts as a write barrier) the data may be written to the database before modifying sqlites journal. Now the OSes journal can be protected from that (since the OS can control the write buffer) but SQLite doesn't have such a protection. I'm curious how SQLite would perform if it used Transactional NTFS instead of syncs and an on disk journal.
I would be tempted to maintain 2 databases in this scenario (write to 2 one directly after the other). The probability that both would be corrupt (due to the reasons discussed previously) would be non-existent. And with the performance improvement of turning of Synch; you would still be in net profit.
That would be doable but the tricky part would be determining which is corrupt. The easy solution of storing the check sum of the database in another file suffers from the same out of ordering you can get without fsyncing (ie both databases are modified before the check sum is actually written to the disk). I'm unsure if pragma intergrity_check can catch all problems.
If you don't "clear bindings". then the statements will be re-used. this is one of the good reasons for using named statements as opposed to the question mark or an integer.
I check that the number of input values is equal to the largest number of parameters used by a single statement. So all binding's must be overwritten in my API. The single question mark is confusing for multistatement queries. I could make an interface for named parameters (the low level part of my api exposes the functions if the user really wanted to use them). But I decided against it since I didn't think the lose in performance was worth the the extra dll calls and variable lookups. But named variable may be faster in some corner cases since my code will bind parameters that aren't used, but it's easy to minimize the impact of that (by optimizing the order of the parameters).
I think that's more of a case that you have coded to use a feature (I'm not saying that that's a bad thing!). There are many ways to skin this squirrel, even without using a database. I have thought about using SQlite for preferences (and also things like MRU lists). But for most applications I don't see much of a benefit (based on the fact that DBs are designed for mass storage and retrieval). Perhaps in your specific case this is appropriate. But I don't think most people think of preferences when they think of a DB. I see it being used more for logging, look-up tables and data that has to be viewed in a number of ways....all of which SQLite excels at.
I just see composability to be a key feature of database interaction.
You'll probably want logging to be synced at least (a log of crash isn't useful use if the important piece never reaches the disk).
Can you think of any other scenarios?
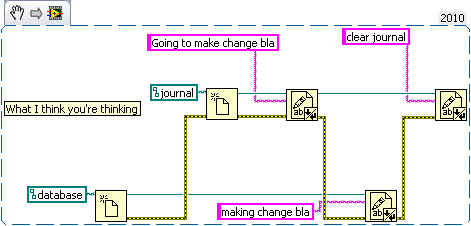
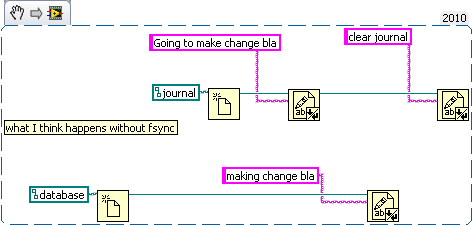
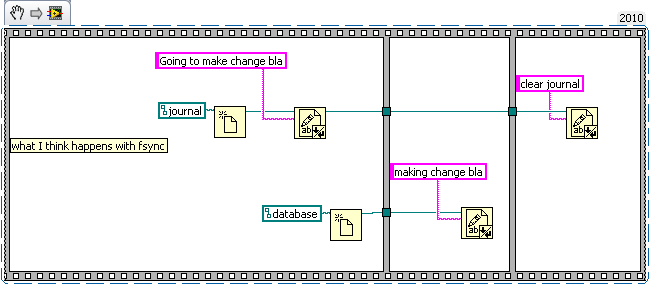
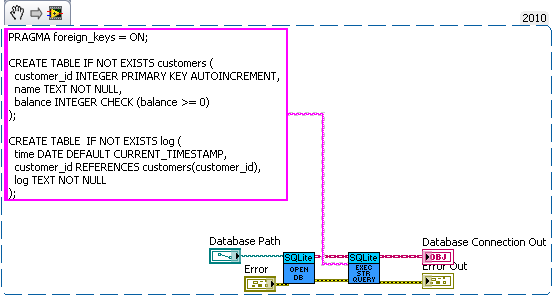
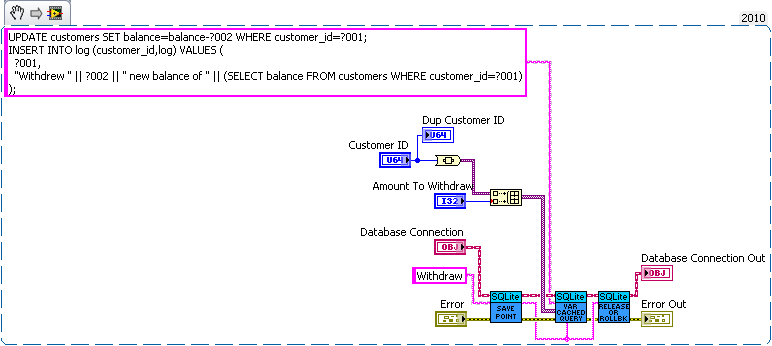
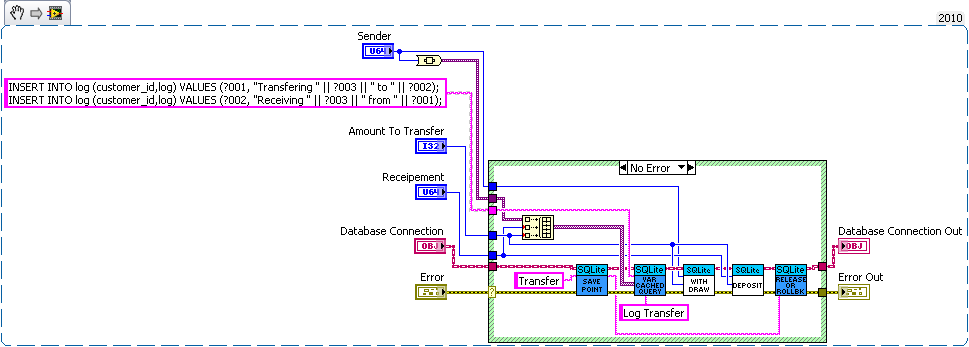
How about a bank example. Lets say you're writing a database for a bank. So we need a table for bank customers and how much money they have, and a second table for logging all the interactions on different accounts (so we can make bank statements). The following code is just hacked together for example so there likely are bugs in it.
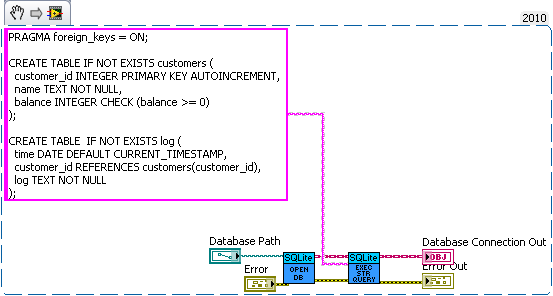
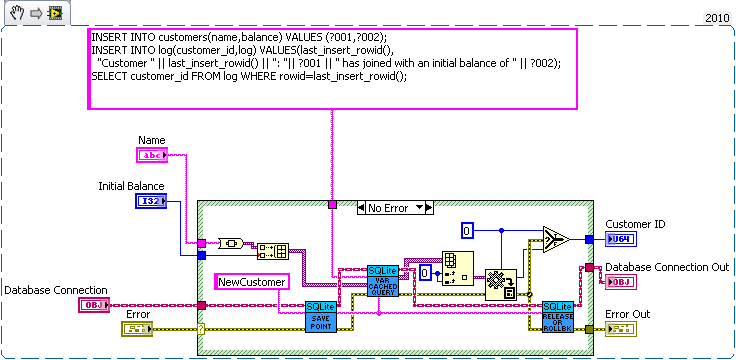
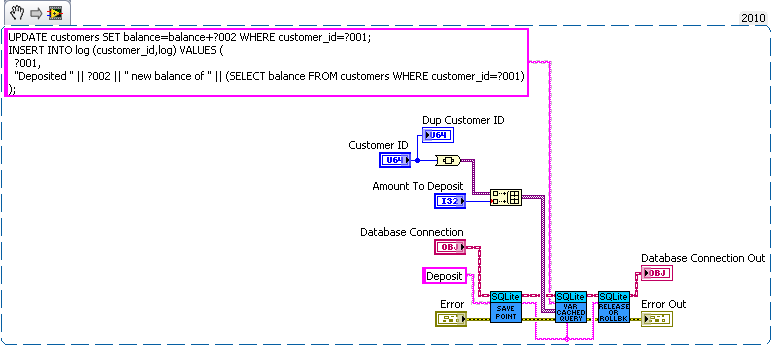
We have three sub vis for our API, create customer, withdrawal and deposit. Now withdrawal subtracts money from the account and logs the withdrawal, and deposit does the same but increases the amount instead of decreasing. We want to make sure the logs match the amounts so we'll wrap all the changes in savepoints.
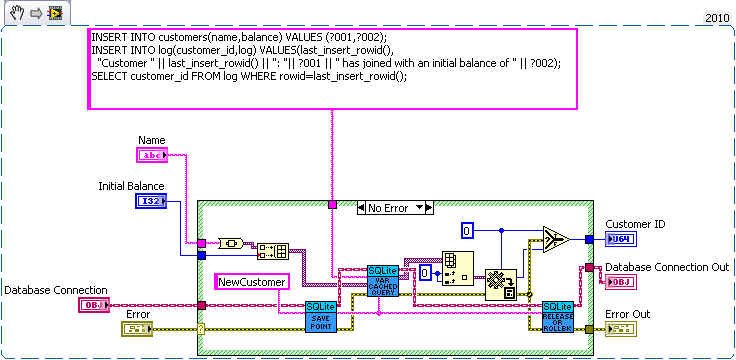
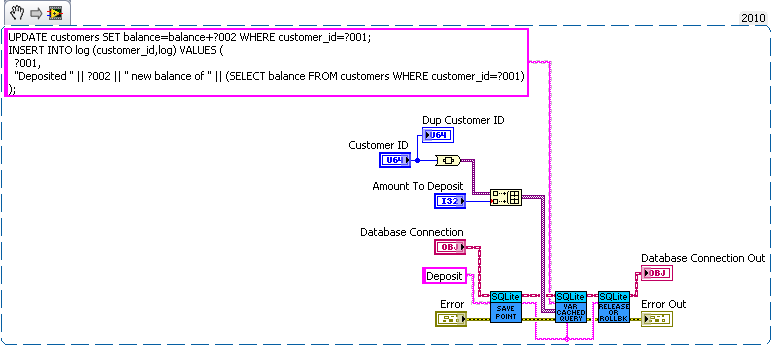
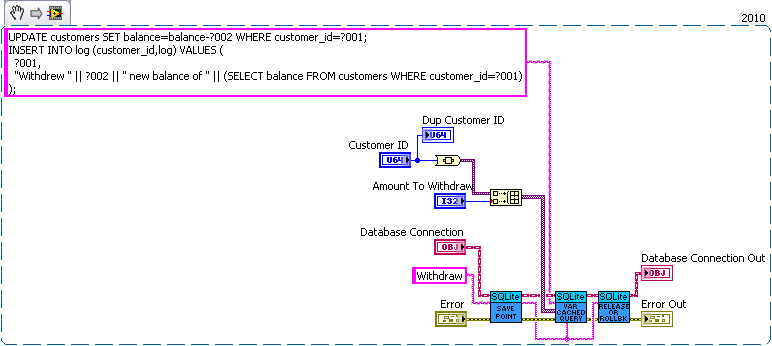
But this say we want to add a transfer subvi. Since we used savepoints we can safely implement in with the withdraw and deposit subvis we previous added (saving us code duplication).
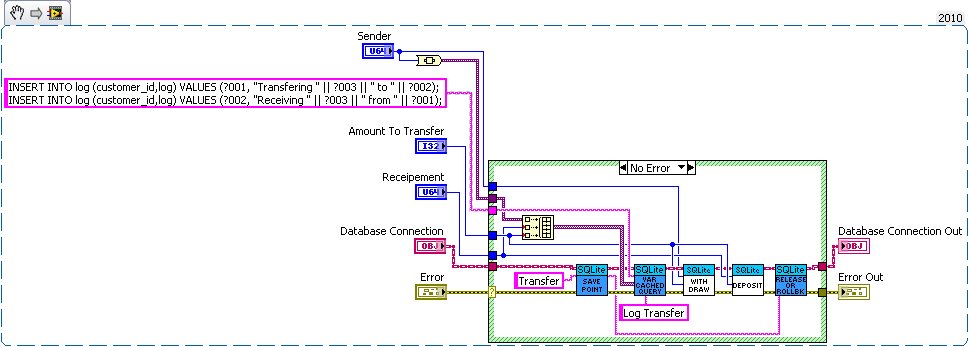
As for why this is useful consider what happens if I need to change the withdraw (maybe take cash from a credit account if it goes below 0 instead). Or I want the ability to lock an account (so no changes in balance). What happens if there are multiple connections to the database. If I wasn't in a transaction in the transfer the receipt account could be locked before the money is deposited which would error then I'd have to write code to undo my withdraw (now what do I do if that account get's locked before I can deposit it back). If I wanted to setup a automatic bill pay I could use the transfer vi in an automated billpay vi. In short savepoints allow for programmer to avoid code duplication by allowing composability of transactions.
-
2
-
-
How do I programmatically get the path to a global VI? You cannot use get this VIs path because global VIs don’t have block diagrams.
So how do I get the path to a global, from inside a top-level VI that uses that global?
Just how there is a “Current VI’s path” function, I need a “That VI’s path” function
Make a static VI reference to the global vi then use the path property of the reference.
-
fsynch is only used on unix-like OSs (read linux, Mac). Under windows "FlushFileBuffers" is used. It also states at the end of the paragraph that
"These are hardware and/or operating system bugs that SQLite is unable to defend against.
I was using fysnc and FlushFileBuffers synonymously, since they perform the same job. There's probably some subtle difference between the two though.
And again in Things that can go wrong section 9.4 it states:
"Corrupt data might also be introduced into an SQLite database by bugs in the operating system or disk controller; especially bugs triggered by a power failure. There is nothing SQLite can do to defend against these kinds of problems."
I'm trying to minimize risk with the things I can control. For instance neither of us is using a memory journal since a crash in our programs in the middle of a writing transaction would very likely trash the database (even though it should be a little bit faster). I just like extending that safety to help mitigate hardware and os failures.
The main issue seems to be cantered around old consumer grade IDE drives. I remember a long time ago reports about something like this. I haven't, however, read any articles about SATA drives having similar problems (much moe prevalent nowadays). But synchronous mode seems to be an attempt to "wait" a few disk revs in the hope that the data in the cache is finally written to a drive if its still in the drives internal write cache. (Still. Not a guarantee). And I think probably not relevant with many modern hard-disks and OSs (windows at least). Additionally. Putting SQLite (as a single subsystem) through our risk assessment procedure reveals a very low risk.
There should be a flush cache command for the harddrive controller that the doesn't return until the cache has been written (this can be saftely ignored when the drive system has a battery backup, since it can guarantee that it will be written).
My view is that if the data is really that important, then classical techniques should also be employed (frequent back-ups, UPS, redundancy etc).
I work in an academic setting,so UPS and redundancy are often out of budget. I mainly using sqlite for settings, that if corrupted may cause serious problems. So backups don't help until there's been a problem. I would assume the extra durability would be good for embedded equipment in harsh environments.
You can. You just compose them as a string and use the transaction Query". That is its purpose. Although in the "Speed example" it's only used for inserts. It can also be used for "Selects, updates, deletes etc".
The API is split into 2 levels.
1. The top level (polymorphic) VIs which are designed as "fire-and-forget", easy DB manipulation, that can be placed anywhere in an application as a single module.
2. Low level VIs which have much of the commonly used functionality of SQLite to enable people to "roll-your-own". You can (for example) just open a DB and execute multiple inserts and queries before closing in exactly the same way as yours and other implementations do (this is what "query by ref" is for and is synonymous to the SQLite "exec" function)..
If my transaction can't be written purely in one sqlite query (I put an example lower down in this post), then I need to keep the connection open. The low level stuff would work as well. Anyway in my library I need to keep the connection open to cache prepared statements.
In benchmarks I ran initially, there is little impact in opening and closing on each query (1-15 us). The predominant time is the collation of query results (for selects) and commit of inserts. But it gives the modularity and encapsulation I like (I don't like the open at the beginning of your app and close at the end methodology). But if that "floats-your-boat" you can still use the low level VIs instead.
Fair enough. I need to maintain the connection for statement cache, and for how I write the code the uses my library.
I did look at savepoints. But for the usage cases I foresee in most implementations; there is no difference between that and Begin / End transactions. OK you can nest Begin / End but why would you? Its on the road-map. But I haven't decided when it will be implemented. If yo can think of a "common" usage case then I will bring it higher up the list.
The main use is to write composable transactions (in other words you can build a higher level api of subvi's that can be put together into a single transaction).
I my case I have a database of samples I'm keeping track off (this example is bit simplified). Now a sample has various properties, different classes of samples require different properties.
Now if the users wants to change a property a dialog vi pops up, this vi checks the type of property. For instance this says it's a ring it's so we call a subvi to update a list control of acceptable values that the user can select from. But the user wants to add a new possible value to ring. So the user clicks the insert new ring value button, types in a value and the new value is inserted in the database. So we recall the subvi to update the acceptable value list control. But the user changes his mind and clicks cancel, so we now need to remove the value(maybe multiple) he added. A very simple way to way to do this is to have the property editing dialog wrap every thing it does in a transaction, and just roll back if the user changes clicks cancel.
But what if the user wants to add a new sample. So the new sample dialog pops up, asks the users what class of sample to add. We look up which properties are required for that class, put that in a list of properties the users has to set (which might have default values). Now the user may cancel out of this new sample dialog so we're going to wrap this all up in a transaction as well. But we want to call our change property dialog to set each of the properties, but that was already wrapped in a transaction (and you can't begin a transaction within another transaction). Now an easy way to fix this is to switch from "begin transaction" to save points, since those can be put within each other, and they're functionally the same as begin transaction, when not within another transaction.
I've had a quick perusal of the Mac framework link you provided (many thanks).
Sheesh! What a pain. It looked initially like the best way forward would be to link into the SQLite framework that is shipped with the Mac. But as LV for the Mac is 32 bit; you cannot guarantee that the SQLite will be 32 bit.
It looks like Mac users are going to have to wait for me to complete the learning curve if there are no LV Mac gurus around to offer guidance (no response so far from my question in the Mac section). Or maybe it's a sign that it isn't that important (and the API is not that useful to the few Mac users there are ) and divert my attention to other things.
-
It's more to do with data loss than corruption. Don't forget, its not turning off journalling in SQLite. Its just returning as soon as the OS has the info (and therefore is present in the OSs journal). The worst that can happen (I believe) is that during a crash, changes to SQLites journal aren't transferred to the OSs journal therefore some piece of data might not be written to disk when restarted. On restart, the OS will ensure that incomplete transactions (file system transactions) are resolved. And when SQlite is started, it will ensure incomplete SQL transations are resolved. Additionally. I open and close the file on every query which automagically causes commits on every query which (in my mind) is safer. But I have made it an option so it's up to the user to decide.
I think guaranteeing no corruption is a rather subtle. On SQLite's How to corrupt your database. the first possible problem beyond the uncontrollable is the OS/Filesystem not fsyncing properly. The next is ext3 (a journaled file system) without the barrier=1 option (which to my understanding breaks sync with write caching). I think the problem (there could be more) is that writes to the hard drive can be reordered ( which I I think can happen when write caching and NCQ don't properly fsync, also an active sqlite database journal normally two files). You might be able to work it without a write cache on a journaled file system, or by modifify SQLite3 to use a transactional interface to the underlining filesystem (I think reiser supported something like that). Anyway I would suggest keeping sync full or at least normal,since it's easy for someone to pragma anyway the safety. The sqlite doc recommend normal for mac since on OSX it works around lying IDE controllers by resetting, which really slows things down.
The problem with committing on every query is that you can't compose multiple query's. Which is something I do since I want the database to always be consistent, and a lot of my operations involve reading something from the database and writing something that depends on what I just read,
Instead of reopening the file by default you could wrap all query's in a uniquely named savepoint that you rollback to at the end of the query. Then you have the same level of safety with composability, and you gain performance from not having to reopen the database file. The only trick is to have separate begin transaction and rollback vi's (since those can't be wrapped in save points), which I'd recommend as a utility functions anyway (those are among the main VI's in my library).
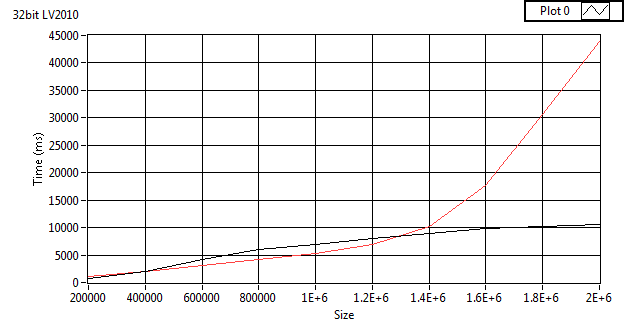
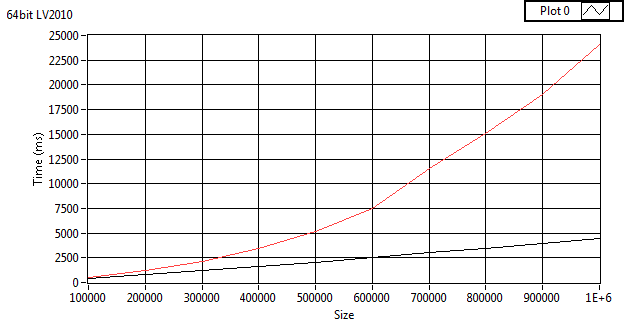
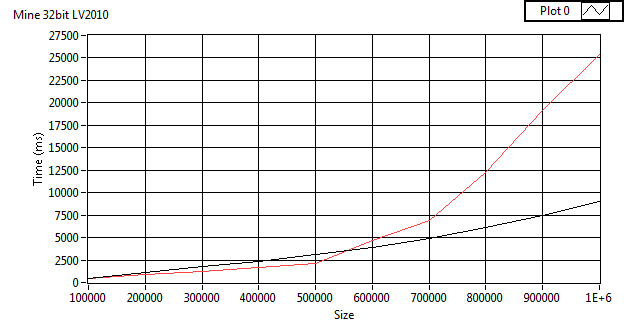
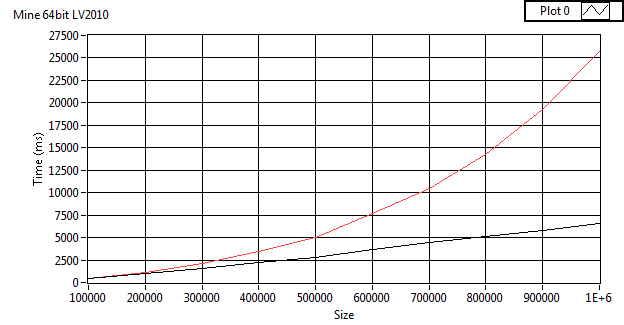
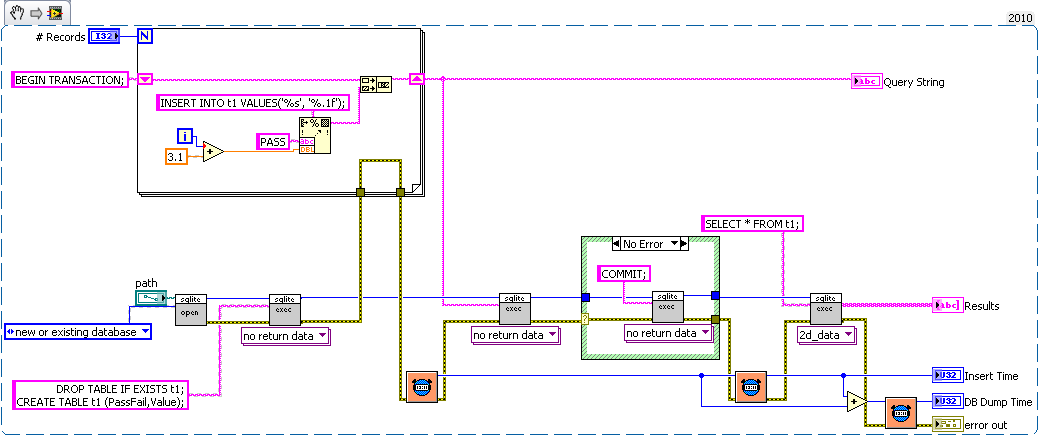
Nope.I'm using NTFS (write cacheing enabled). But something is different since (as you can see from the images) the insert time of the get_table is more in tune with inserts of my implementation when Synch is FULL (~200 ms). The only way I can get the same results as your benchmark is to use in-memory temp tables then I'm at the same insert times. What are the compilation options for your DLL?
Yes. This I'm not sure about. Since I can also find little difference between an in-memory DB and a "temporary" DB. It doesn't state it, but what could be happening is that the journal and temporary tables are created in-memory when the db name is blank giving rise to similar performance to an in-memory DB.
I think I figured it, my work computer is winxp and has write cache enabled which breaks fsync to some extent (I think). Now I see a difference on my WIn7 home computer which uses supports write cache buffer flushing (a proper fsync). Now I may need to get an additional hard drive at work just to run my database on if I want to guarantee (as best as possible) no database corruption.
I think the difference between a Blank DB and :memory: db is that the blank is a data base with sync=0 and journal_mode=memory (the pragma's don't indicate this though), while with :memory: all the data in the database is stored in memory (as opposed to just the journal).
On my home computer with my code on Win7 LV 2010 64bit all averages of 100 runs with my code.
Full Sync:
Insert 123.79 Dump 34.18
Normal Sync:
Insert 104.02 Dump 34.24
No Sync:
Insert 41.15 Dump 36.39
Full Sync memory journal:
Insert 85.44 Dump 36.69
No Sync memory journal:
Insert 82.59 Dump 36.54
No Sync memory journal:
Insert 39.72 Dump 36.28
Normal Settings Blank file
Insert 40.17 Dump 36.45
Normal Settings :memory:
Insert 38.23 Dump 36.50
Your 1.1 speed test (averaged over 100 times) with sync modification hacked in
Full sync
Insert 444.65 Dump 75.86
Normal sync
Insert 424.96 Dump 75.49
No Sync
Insert 362.09 Dump 76
-
1
-
-
That's cheating
 Thats like me getting 60 ms on LV2009
Thats like me getting 60 ms on LV2009 I want it all; The extra functionality and the speed (eventually)
Well I'm keeping the null handling so I'm at 57.
If you're talking about parallelising in terms of for loops across multiple processors. Then there's not much in it. A good choice of non-subroutine execution systems and subroutines yields better results.
I'm not too happy about using the xnode (not keen on Xnode technology in its current form anyway). I will probably knock up a more raw version using moveblock since I don't need the polymorphism and who knows what other stuff locked away inside.
I was thinking more along the lines of a unrelated function updating a bunch of property nodes in my UI loop, slowing down my data collection loop.
I'm just using the Pragma command to switch synch. I've made it so a simple change in a project conditional statement means you can switch between them all.
I don't think synchronisation is necessary on already journeled systems (e.g NTFS, and ext3). I think its more appropriate for FAT32 and other less robust file systems.So the shipped setting on the next release will be OFF.
I prefer being certain the data can't get corrupted (the main reason I'm using SQLite). I'm not convinced having a journaled file system permits me to avoid syncs.
Here's some results from my latest incarnation showing the effect of the turning off synch.. I've switched to testing by averaging over 100 iterations since there is a bit of jitter due to file access at these sorts of times. You'll probably notice the difference between the average insert time and insert time from the last iteration. With Synch OFF they are much more in agreement.
With this benchmark, turning off sync makes very little difference (maybe 5 ms) on my system (are you using something exotic for a hard drive or filesystem?). If I test a large amount of transactions the difference is enormous.
Just to note it turns out if you use a blank path the database performs like you had sync off (since it's temporary it doesn't need durability).
So my insert time is really 74ms not 68ms (path now has a default value in my test code, since forget to set it the last time).
-
Sweet. Nice work on that.
I think perhaps blobs my be an issue with this as they are with straight text. But still, its definitely worth exploring further. You've shown me the way forward, so I will definitely be looking at this later.
I'm not sure why you think its not much of an improvement. For select queries its. ~60% increase on mine and ~40% increase on yours (using your benchmark results) . I wouldn't expect much on inserts since no data is returned, therefore you don't have to iterate over the result rows.
Incidentally. These VIs run faster on LV 2009 (for some reason). Your "get_table" example on LV64/32 2009 inserts at ~220ms and dumps at ~32 ms (averaged over 100 executions). On LV2010 I get roughly the same as you. Similarly, my 1.1 version inserts at 220 ms and dumps at 77 ms (averaged over 100 executions). Again. I get similar results to you in 2010. Of course. Dramatic insert improvement can be obtained by turning off synchronization. Then you are down to an insert speed of ~45ms.
My next goal is to get it working on the Mac. I have a another release lined up and am just holding off so that I can include Mac also. So I will have a go with your suggestion, but it looks like a lot of work if you cannot simply select the lib. Do you know of a web-page (for newbies) that details the "Framework" directory details (e.g, why it needs to be like this. What its purpose is etc)?
If I don't handle strings containing null mine takes 60ms to dump, and If I don't try to concat results from multiple statements I can get down to 50ms (I think I'll remove this feature, the only real use I can think of is checking pragma settings). So I'm just as fast at the same functionality (at least in LV2010). With handling strings containing null but not concatenating I'm at 57ms. Apparently SQLiteVIEW is handling select slightly better than me, since they're still faster. At least I'm winning the insert benchmark by a good margin:D.
I haven't checked but the GetValueByPointer.xnode may call the UI thread, if it does it won't parallelise too well.
I surprised that the dump is that much faster in 2009, my best guess is that it the GetValueByPointer is different somehow (maybe the old one doesn't call the UI thread).
How are you turning off synchronization, and which SQLite library get's down to an insert of 45?
-
- Popular Post
- Popular Post
I haven't tried porting mine to mac yet, but I figured out how to get the calls to work. If I remember all this right (don't have access to mac right now and it's been a couple of weeks) you need to create a "sqlite3.framework" folder and copy a sqlite3.dylib file into it (you can get one from the user/lib or extract it from firefox). You set the CLN in LabVIEW to point to the framework directory, and you have to type the functions names in (the function name ring didn't work for me).
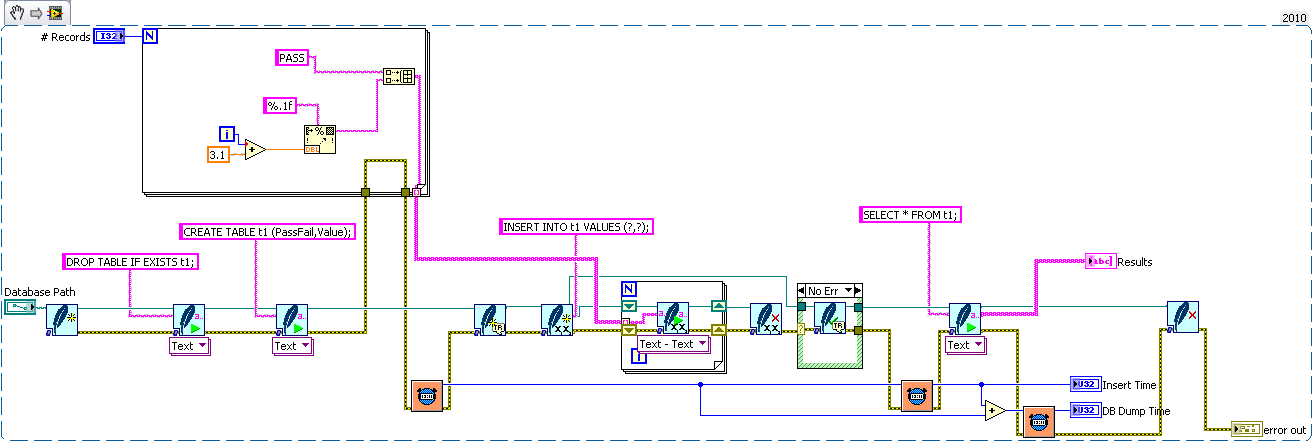
I hacked together (barely tested on LV2010f2 WinXP and not documented) a gettable implementation to see if there was any speed improvement. There wasn't much since get table is just a wrapper around all the other functions.
GetTable
Insert 141
Dump 49
-
3
-
I finished up the last (hopefully) pass through my library a week or two ago. I got permission from my employer to post my SQLite library (I need to decide on a license and mention the funding used to create it). and when I went to try to figure out how to make a openg library (which I still haven't done yet) I saw the SQLiteVIEW library in VIPM. Which is similar to mine. But mine has a few advantages.
Gives meaningful errors
handles strings with /00 in them
can store any type of of LabVIEW value (LVOOP classes, variant with attributes),
can handle multistatement querys.
has a caching system to help manage prepared querys.
As for benchmarks I modified your speed example to use my code (using the string based api I added to mine since to the last comparison), and the SQLiteVIEW demo from VIPM. This is on LV2010f2 winxp
Yours
Insert 255 Dump 107
This no longer available library that I've been using up until my new one (I'm surprised how fast this is, I think it's from having a wrapper dll handling the memory allocations instead of LabVIEW)
Insert 158 Dump 45
SQLiteVIEW
Insert 153 Dump 43
Mine
Insert 67 Dump 73
The differences in speed between mine and SQLiteView I suspect (since I can't open their code) is that I inlined heavily called VI's (the lose on insert), and handle strings with /00 in them (the decrease on dump). If I changed the benchmark to repeatedly called query's that took longer to prepare, I could make yours and the old library appear slower relative to SQLiteVIEW and mine.
I attached snippets of the modified code.
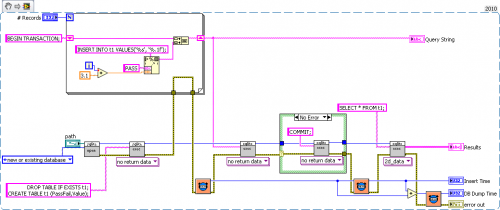
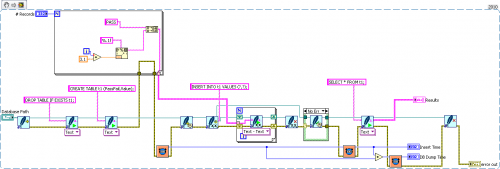
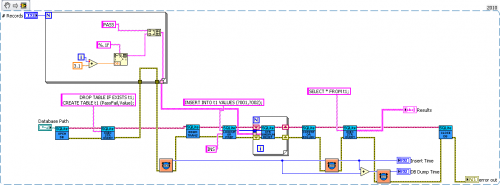
Anyway I've been debating with myself on posting mine now since it seems kinda of dickish of me to make a free lib when someone recently released one for sale. Also if I wasn't using an academic licensed version of LabVIEW, I might have put mine for sale as well, so I could easily be in their position. The main reason I was posting it was to add back to the community and have something out there to show for possible future employers as an example of what I can do. Being in an academic research lab I don't get payed well and I have no long term employment guaranties, fortunately I love everything else about my job.
Anyway my options I can see now.
Don't post it. (If I thought SQLiteVIEW was better than mine then I would be leaning to this route more. I do have some other libraries I considering posting but they have a smaller audience).
Just post it how I originally intended. (Since I don't have any association with SQLiteVIEW, their actions shouldn't affect me. There's already been two free SQLite libraries anyway).
License mine for non commercial use. (Yours is licensed that way if you didn't notice. but that really limits the legal uses of my code. Also I don't have the interest in defending that limitation. So it's practically the same as putting it there with a bsd or lgpl based license like I originally planned on).
Contact the makers of SQLiteVIEW, and either
Give them a version of my code so theirs can at least reach feature parity with mine. Then wait some period of time before posting mine in the wild.
Offer to consult with them on how to improve their version, so I get my name on their version and some amount of money (This feels like blackmail though).
-
2
-
-
Are you sure about that memory leak? I thought one should only close refnums which you explicitly open?
I'm certain. The explicitly open is generally true in my experience, but Owning VI is an example of when it's not true. The desktop trace confirms it, if you cast the ref to an integer, its value changes for each call, and if you run it in a tight loop memory use will grow without bound (no super fast though, it's only leaking a pointer sized int).
The desktop trace toolkit could be better (like tracking which event in the event structure was triggered). The tracing is good for debugging heavily multithreaded code. The ability to find unclosed references and check how LabVIEW is really allocating memory make it uniquely useful.
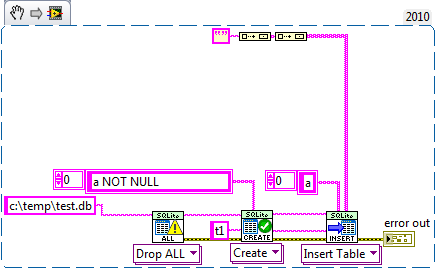
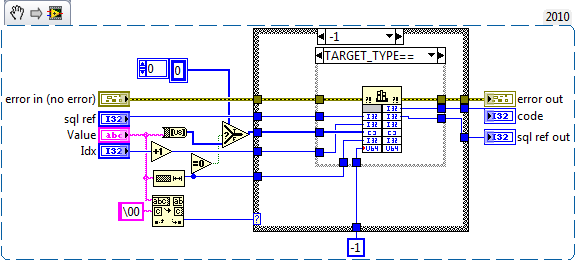

[CR] SQLite API
in Code Repository (Certified)
Posted
Just replace the terminals with shift registers (generally a good rule with for loops anyway).
But I was talking about the byte array from the string that gets passed to the bind string (it seems that empty arrays are passed as pointers to 0 in CLNs).
Is there a reason you're clearing bindings before finalizing the statement. It's my understanding the clear just sets all parameters to null, and since you're closing it doesn't matter what the bindings are.