Matt W
-
Posts
63 -
Joined
-
Last visited
-
Days Won
7
Matt W's Achievements
")
Newbie (1/14)
16
Reputation
-
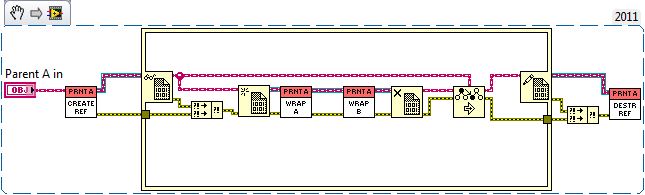
All CLN's are configured to run in any thread (it runs very slow without that). I am calling a CLN for the strings proper size in either case. I agree that the performance seems odd but that is how it acts. Perhaps when reading a string LabVIEW doesn't have to make an immediate copy of it. So maybe the string allocation is masked into a later data copy. But I don't see how LabVIEW could determine that optimization is safe (it would be in my case). Maybe DETT can explain what's going on.
-
My adaptive method with 20000 small strings (5-8 bytes) takes 46.21 ms with the 3 apis method it takes 54.77 ms so mine is 18% faster. Of course if the strings have /0 in them then things slow down drastically. If every string has a \0 then the 3 api calls is 54.5, while mine is 68.1, so the 3 api method is 25% faster. But I consider \0 to be an exceptional case and I am adding a different interface to handle those if really needed. If the strings are longish (~100 bytes no /0) then mine takes 66.5 ms, the 3 api call takes 75.85 ms so even with the worse strlen overhead mines still 14% faster. The strings need to be about 1700 bytes long before the 3 api and mine are the same speed. At that length with /0 on the end (worst case) mine takes 323 ms instead of 273 ms (18% faster without /0). The ideal solution would be a C wrapper where you could preallocate the string.
-
I thought your's had /0 support (maybe it did way back when I wrote mine). I'm not sure where the difference is then (maybe inlining vs subroutine). You still have far nicer icons than does.
-
I'm not exactly sure why but there was a speed improvement from it. A few possible reasons string's copy is inlined and doesn't have the slight overhead of the cln call. Or it might use some form of memory copy instead of move (copy doesn't handle overlap so it should be faster). I don't think I can read directly into a byte array. The size of the data is a separate CLN, and the pointer to the string data is the return value. So there no way (that I can see) to size the byte array, which is why I use move block. I was referring to this particular typecast, since byte array's and string have identical memory layouts and don't require swaps (at least on windows, I'm unsure if alignment is different between the two on other systems), I assumed that have the same performance (I believe I have tested that assumption at some point as well). I wasn't aware that typecasting between i32 and float being so costly. I don't see why they don't just do what C does and simply interpret it differently, it sounds like the two method's produce the same results.
-
If I saved the number with the variant interface it will not be stored as a null (that's why nan's are flattened). My variant interface does return the type as stored in sqlite, in case it's being used for something more complicated than a data store. I can write and recovery invalid UTF-8 data fine, so I think the encoding only matters if you start using the UTF-16 functions since it would have to convert encoding or if you set sqlite to use utf-16 as it's default encoding since the length would have to be even. Also adding a collation sequence more intelligent than memcmp may mess things up. There are differences between blob and text, but I think they're more meaningfully when your language uses c style strings or you start getting fancy with how you handle text. I had forgotten that text is considered earlier than blob (even though by default they use both use memcmp to sort). When I read text the CLN's return value is a string, if that strings length doesn't match the expected number of bytes (can only happen if it contains \0) then I reread it using the moveblock method. So if the string doesn't contain /0 I can read it faster, but if it does mine is slower. This optimization is the reason my select is faster than Shaun's. I would suggest using Byte Array to String instead of type cast, they're the same speed and the Byte Array will error if it's input type get's changed some how. Just seems like a lot of work to fix a rare, non critical bug. And locking every function seems like it'll have a performance hit. Personally I would just add something to the documentation that the error description can potentially be wrong if two errors occur nearly simultaneously, and not worry about. The hard part in my mind is verify that whatever you did actually fixed the bug. For now I would suggest adding the errmsg (it's really helpful with syntax errors), and make fixing the race condition a low priority. I don't know the OpenG standards well enough to say. Maybe they'll be ok with careful use of subroutines (binding's, column reads and stepping should be prime candidates). The issues with subroutines and blocking are why I use inlining instead. When I start activating Inlining on VI's based on performance analysis, it tends to get applied liberally on low level functions. I typically don't add it to high level functions so I don't drastically slow down their recompile times of their callers. Dead code elimination and inlining open up some options for making efficient interfaces. In one of my VI's if you didn't wire one of the VI's outputs a lot of the code to generate it would be thrown out. We're talking about extended error information (a common use is a string description of syntax errors). Basic error codes are returned without problem. SQLite is very well designed, so the only non friendly function parameters I can think of are function pointers for extending SQLite. By default the connections lock themselves (the error case is the only exceptional bug I know of that might get through those locks). Although efficiently doing selectable dlls would require a C DLL. I assume user refnums are one of those not publicly documented LabVIEW apis. I was looking at how hard it would be to make SQLite into a scripting node, the only example of scripting Nodes I know of is LabPython, which apparently you wrote. Is there documentation for adding scripting nodes beyond that source code (lvsnapi.h). My main issue was how to link separate script nodes to the same database connection, ideally passed around via wire (I guess making a particular data type for getting and setting may work). Also how do you return descriptive errors.
-
Acting as a data repository is one of the things I set mine up for. I have functions similar to opengs "write panel to ini" and "read panel from ini" but far faster (since they don't have to convert to readable text). Mine handles null fine, how it handles it depends on the mode it's in. In string mode it get's zero length strings, In variant mode the variants are null, the newer typed reading depend on the particular type for that column. SQLite text can hold binary data just like LabVIEW strings. In mine Blobs are typically used to hold flattened LabVIEW data (although they don't have to). As far as SQLite is concerned there is very little difference between a blob and text, the only things that come to mind are type affinities and blob i/o. I have an optimization where I assume TEXT rarely contains /0 when reading columns, but that's not a functionality difference. The only way I know of that might work is to have the vi's for savepoints/begin start the lock, and VI's for commit/release release the lock. Otherwise the user cannot compose multiple SQL commands together with out the risk of parallel work screwing it up. Since SQLite is by default in serialized threading mode, I'm not sure if that setup would even gain any protection. There's only so much you can do to protect a programmer from them self. With yours what would happen to the data output if someone made a copy of the statement object and tried to process the two of them in parallel, I think you'd get a really nasty race condition, and I'm not sure if there's a good way to stop them that from happening. I've been meaning to add a non copyable class wires to the idea exchange for stuff like that, but I never really fleshed out the design in my head. Shaun's and mine are both highly optimized, so it'll take some work to catch up to them. I would suggest either inlining the majority of your vi's (mine does this) or use subroutine priority (Shaun's does this) as the first optimization to try.
-
I use the type of the data within sqlite to determine how to read it. When you use "variant to data" with a variant containing 64 bit int (as read from sqlite) it can be converted into a 32bit int without error(as can a double to single). So I store int (all sizes),singles,doubles and strings as their related sqlite types. empty variants as nulls, and every things else (including NaNs) as flattened data . As mine is written anything saved via variant, when read back as a variant will "variant to data" back to it's originally type without loss of data. Which handles all the use cases I could think of. NaN's being flattened was the only iffy part about it. I don't think variant support is critical, but with the way my interface works it gives some advantages. I wouldn't your already "abusing" the property system, but in a way that's close to it's intent. My basic interface doesn't expose step or finalize so it's not a problem I need to deal with. On one of my benchmarks where I write a bunch of string data to the database I'm 12% slower if I pass the path in on just the bind text CLN. It should be worse with numeric data (since those have far less overhead). I remember it being worse the last time I checked so I guess some optimizations were made since then. Unless you're preparing multiple statements where the schema changes, you can prepare all of them before running any of them. If they are changing schema then your "Execute SQL" could be used. I just assumed that the user (me in my case) would never use the same database connection in two places at once. The possible bugs from that are far worse than the rare incorrect error description, so I just considered it back practice and don't try to deal with it's problems. It's not the LVOOP mine uses LVOOP and is faster than Shaun's. On Shaun's benchmark with 100000 points, his is 181.95 insert and 174.82 dump mine is 155.43 and 157.77 I have the Property Node interface working on mine (at least a basic version of what I'm going to do), working on optimizing it currently. Found a new way to confuse LabVIEW in the process. Right now when working with large amounts of data a VI that only returns a LVOOP object for storing parameters (and containing nothing at that point only takes about 40 bytes of memory), can take hundreds of ms to run. I think it's trying to reuse the memory previous runs LVOOP object and has to free the old data I had assigned to it, but for some odd reason it can slow down drastically.
-
I've written my own SQlite implementation making this the fifth I'm aware of. All of them being yours, mine, ShaunR's, SmartSQLView, and a much older one written by someone at Philips. Handling Variants can be done (mine handles them) but there's several gotchas to deal with. SQLite's strings can contain binary data like LabVIEW strings. It looks like your functions are setup to handle the \0's with text so that's not a problem. So you can just write strings as text and flattened data as blobs, then you can use the type of the column to determine how to read the data back. The next trick is how to handle Nulls. As your code is written now NaN's, Empty strings and Nulls will all be saved as sqlite Nulls. The strings are null because the empty is string is passed as a 0 pointer to bind text. So when you have an empty string you need to set the number of bytes to 0 but pass in a non empty string. I never figured out an Ideal solution to NaN's. Since I treat null's as empty variants I couldn't store NaN's as nulls. The way I handled NaN's was to flatten and store them as blobs. I also would flatten empty variants with attributes instead of storing them as nulls (otherwise the attribute information would be lost). Be aware of the type affinity since that can screw this up. I like how you used property nodes to handle the binding and reading of different types. If you don't mind I might try to integrate that idea into my implementation. If you want to improve the performance, passing the dll path to every CLN can add a lot of overhead to simple functions (at least when I last checked). I use wildcards from http://zone.ni.com/reference/en-XX/help/371361H-01/lvexcodeconcepts/configuring_the_clf_node/ If your executing multiple statements from one SQL string you can avoid making multiple string copies by converting the SQL string to a pointer (DSNewPtr and MoveBlock be sure to release with DSDisposePtr even if an error has occurred). Then you can just use prepare_v2 with pointers directly. You might want to add the output of sqlite3_errmsg to "SQLite Error.vi" I've found it helpful.
-
I found some more info http://zone.ni.com/reference/en-XX/help/371361H-01/lvexcodeconcepts/array_and_string_options/ In the section Determining When to Resize Array and String Handles in Shared Libraries It sounds like you're not supposed to use NumericArrayResize for string data. I'm guessing the problem is alignment since it looks like in LV64 on windows the string size would be padded with NumericArrayResize, when it shouldn't be padded. On LV32 on windows there is no padding so I guess it wouldn't make a difference in that case (or in any case where alignment is less than or equal to 4 bytes).
-
I think I found the answer to my second question http://zone.ni.com/reference/en-XX/help/371361H-01/lvconcepts/how_labview_stores_data_in_memory/ Sounds like with strings it is either the handle or pointer that can be null, but with arrays it is just the handle.
-
Thanks, that helps clarify some things. I haven't seen any nulls during my basic testing, so I'll add some code to check for that. Is there a way to encourage LabVIEW to use nulls, I would like to double check that the null handling is correct. Which part of the handle can null? Only the handle, only the pointer or either? If I pass a Handle by value into a CLN can I assume that the passed in handle will not be null (otherwise I can't resize that handle, and I would have no way to return a new handle).
-
I have a method for handling syncing with DVR classes, but it's a bit messy and I haven't used it behind checking that it seems to work. You basically wrap the class in a temporary dvr for the synced operations (It can implemented much cleaner with SEQ Classes). Just throwing it out there in case it gives someone an idea.

-
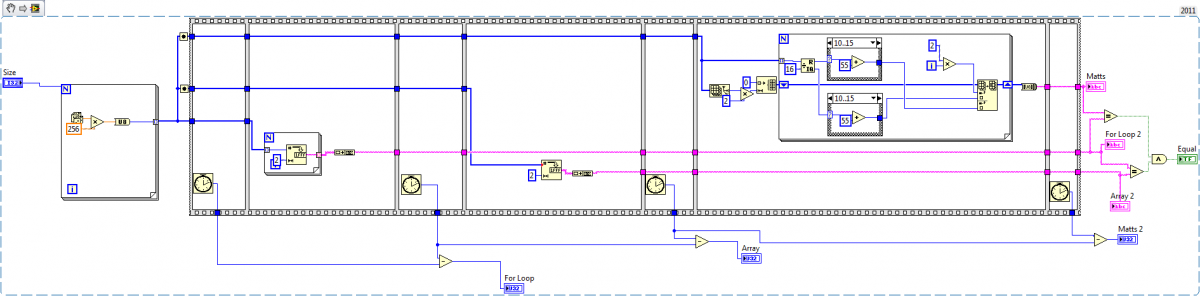
If you make sure the indicators are updated after the benchmark (run their wires through all the remaining sequence frames) then array will win, with your current bench mark the winner will depend on which test is run first (I suspect the difference is due to pressure on the memory allocator). Personally I use also use an always copy node to copy any input data before entering it into the first sequence frame to make sure I'm not measuring a data copy (just wiring into the first frame maybe sufficient but I like being sure). That wont matter in this case since you're not modifying the U8 array. A couple side comments. A string to U8 array can be done in place so that it doesn't take any time (a u8 array and string have identical structures in memory so LabVIEW just has to reinterpret the data) You're greatly underestimating the size of the string array. Each string takes 6 bytes 4 for size 2 for data. An array of strings is an array of handles. 4 bytes (array size)+5.5 million * (4 bytes [string handle]+4bytes[string pointer]+6 bytes [the string itself] ) so a total of ~ 73.4 mebibytes. In 64bit the handles and pointers would double in size, I'm unsure if the sizes would double or not. If you avoid the string array (and it's 5.5 million allocations) things go much faster On the first run with 5.5 million elements I get For Loop: 4725 Array: 2758 Mine: 134 On the second run (where LabVIEW can reuse the large arrays allocated in the first run). For Loop: 2262 Array: 2279 Mine: 127
-
Using DETT and a test VI LabVIEW did deallocate strings that I allocated and put into a LabVIEW allocated array. The deallocation happened before the vi terminated, since all DS* allocated data would have been cleaned up by then anyway. I'm forcing deallocation by reshaping the array. So it looks like LabVIEW will deallocate handles placed properly into aggregate data types. I'm not sure how uncontained handles are dealt with (my guess is that those would need to be removed by hand), but that isn't relevant for my issue. I don't suppose anyone knows where this stuff is documented (I assume the people who used to write CIN's would have experience with this). Testing LabVIEW this way would be good for double checking the documentation does what I think it says, but seems error prone to figuring out what's exactly going without documentation. I'm going to assume my third approach will work, unless someone knows of some issues with it.
-
I'm currently adding a scripting support via LuaJIT to a program I'm working on. The script is working with potentially large arrays (1 million+ elements) of doubles and strings. I pass both types via Adapt to Type Handles by value and I am able to read both of them without issue. I can also modify values within the double array. Now my problem is I want to output arrays of doubles and strings from my script, but their size is unknown until I run the script (I do know a maximum size, but that will be far larger than needed in the majority of cases). I can think of a few approaches but since I can't find a good description of the semantics of the LabVIEW memory manager and especially it's interaction with DS* functions I'm unsure if what I do will produce leaks or deallocate possibly in use data. I'm just going to list some of the approaches I have come up with with string arrays since double's should be a much easier problem. The safe method: Run the script have it store the data separately then read the string array one element at a time into the LabVIEW array. While this is certainly safe it's also horrendously slow. The I think might be safe method: Have LabVIEW pass a handle to a string array that's been preallocated with empty strings, the length of the array is the maximum amount of strings I could possibly need. Now use DSSetHandleSize on all the string handles I'm writing to to make space and write the string data and string size. Next use DSDisposeHandle on all of the unused strings (I assume I'm responsible for deallocating them since I'm throwing them out them), then DSSetHandleSize on the array handle and set the array size. With this method I'm assuming LabVIEW is still responsible for cleaning up all the resized handles. The problem with this that the array is probably several orders of magnitude too large, so I'm putting extra pressure on the memory manager. The method I want to use: Have LabVIEW pass a handle to an empty string array. Use DSSetHandleSize on the array handle to make space for the strings I'll need and set the array size. Then use DSNewHandle to create new strings to fill up and set their sizes. Now typically the thing responsible for allocating is also responsible for deallocating, is this still true when I'm putting the string handles in the array that LabVIEW is already handling (in my previous approach I deallocted handles that LabVIEW made, would LabVIEW do the same when it's done with the ones I allocated). If I need to deallocate the strings myself do I need to be extra careful that LabVIEW isn't currently using that data already (IE use the always copy node on anything that comes out of the string array, before I pass the string array back in to the script to close it). There's a decent change I might end up using arrays of single element clusters of arrays of strings. If there's some reason the concepts from the above wouldn't apply to that. Matt W