

Matt W
-
Posts
63 -
Joined
-
Last visited
-
Days Won
7
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Matt W
-
-
Interesting. Did you get sqlite_column_blob working? You probably saw my note about it in the get column VI. Being able to call that function (instead of my work-around) would have saved a lot of effort).
Strings are the ultimate variant IMHO. I'm not a fan of the variant data type which I consider a poor relation to strings for many reasons. But that's a personal opinion.
I use sqlite_column_text (only different in how it handles zero length blobs), but the trick is to use MoveBlock.
I use variant's since they hold type information, and it's NI job to make sure the it support all types (although there are a few quirks I've had to work around).
You don't need to escape strings with ( ' ). That's a requirement for properly formatted SQL rather than an implementation requirement. The onus is on the user to enforce this rather than as a function of the API. It is was MySQL they would have to do the same.
I don't need to escape strings since I have bound variables, I can also use \00 in string parameters. Bound Variables are also the proper way to avoid SQL Injection attacks.
The dll is the killer. Cross-compiling is real "geeks" territory and I avoid C like the plague unless I'm dragged kicking and screaming like a 4 year-old. But then I have a compiler for the particular target and C programmers are plentiful

I cannot find a definitive list for the functions supported under RTWin. So the only option is to try it. and hope for the best.
Fortunately I qualify for a real "geek", not that I like C but I know it well enough. When I got home I got it cross compiling with LV64. Just involved putting pointer sized int in the right places. I'll try to get it to work on a mac at work on Monday (If I got it set right I shouldn't need to change anything).
I also removed some restrictions from my interface, and removed the need for strlen when preparing strings (that required the use of DSNewPtr, MoveBlock and DSDisposePtr).
Beyond sqlite the only calls I use are DSNewPtr, MoveBlock and DSDisposePtr, all of which are supplied by LabVIEW (so I would hope they are on RTWin).
Anyway with LV2010 64 bit on Win7 with string and doubles(the same as your initial speed test), but modified to including formatting time.
Yours
Insert 401
Dump 72
My Current Version
Insert 277
Dump 151
I don't know why your insert got slower and dump faster from the Win XP LV2010f2 machine 32bit I tested on before (the 64bit computer should be faster CPU and IO wise).
Be careful with this. For in-lining all the in-lined vis must be re-entrant. This can cause "database locked" errors when running concurrently even with shared cache. Choose which ones are in-lined very carefully. (You'll get about another 10 ms by doing this and LV2010 is about 10 ms faster than LV2009 too
 )
)As an aside. I'd love to see the result from using SQLite on an SD drive. I'm very impressed with SQLite and will be using it a lot in future.
I'm familiar with re-entrant vi's. From the testing I did, mine seems to handle concurrent access properly. I'm using SQLITE_OPEN_FULLMUTEX, which should reduce crashing from misusing the API. If you have an example that causes "database locked" errors I'll check if I'm handling it properly.
You can use an In-Memory Database which should be faster than a SSD.
With the above bench mark and an in-memory database I get
Insert 219
Dump 153
So not a huge gain. But if I make every insert a transaction (and knock the test size down to 1000).
Harddisk File
Insert 71795
Dump 15
Memory
Insert 24
Dump 16
So a SSD could make a large difference with a lot of transactions.
-
Funny you should say that. Downland 1.1 I've just posted above.

Using the benchmark (supplied in the update)
Insert ~350ms
Select ~90ms
The initial release was really for me to get acquainted with SQLite map out the feature list. I'm thinking I maybe able to shave off a few more ms in the next release. Its a shame the"convenience" functions are unavailable to us

Indeed. That's the next feature that I will be implementing and I was also thinking that would improve the insert speed.
Good feedback. Not having other (working) implementations to compare against, I really need this kind of input.
What are you running Win x64? LVx64? I don' t suppose you happen to have am RT Pharlap target?
I compared your newer version with your test harness.
If I don't modify the test for fairness
Yours
Insert 251
Dump 112
Mine
Insert 401
Dump 266
If I include the string construction in your benchmark and the variant construction in mine.
Yours
Insert 299
Dump 114
Mine
Insert 504
Dump 257
If I change my select to use the while loop autoindexing like yours (smacks forehead), and fix some execution settings I messed up (and turn on inlining since I'm on LV2010 now).
I get
Insert 352
Dump 181
Considering that mine is handling type information and using varaints, I doubt that I could get mine much closer to yours speed wise. With conversion from strings and to over formats I'd probably do better in some cases (since I can handle blob data directly for instance, and don't need to escape strings that contain ' ).
Some comments on the stuff I noticed poking around your code.
In Fetch All you can put a step before the while loop, then put another step after the fetch. Then you wont have to shrink the Rows by one. Also, I'm not sure if this is true with subroutines, but "rows out" in "fetch record" being within a structure requires labview to cache that indicators value between runs. If you make the change to fetch all this won't matter.
Your multistatement querys can't include strings with ';'.
I worked around that by calling strlen from the standard c library on the pzTail returned from prepare statement (while being careful to make sure the string was required in later labview code). Then subtracting that length from the original length and taking a string subset to be the remaining statements. The proper solution would be to use a helper dll and do the pointer math, to avoid transverseing the string in strlen. But since I use prepared statements it doesn't affect my version much.
And to be nit picky SQLite only has one L.
As for my enviroment, my version currently only works on Win32 based systems. There's no reason I couldn't port it to other things though. I have a 64bit LabVIEW install at home. At work there's an old PXI 1002 box, but I've never used it (I haven't had a good excuse for playing with LabVIEW realtime).
-
 1
1
-
-
Possibly. This release basically does a "GetRow" and has to iterate for each row. There is another method, but it isn't implemented yet. (Still trying to figure out how to do it....if it is possible in LV).
Do you have a real-time target that uses ETS?
Select is slow because you're building the array one element at at a time, you should grow it exponentially and resize it back down.
I wrote my own SQLite wrapper a while ago, I've been debating posting it after I finish up the documentation. Its interface is more difficult than yours,since it assumes knowledge of SQLite. But is built for speed and storing any kind of LabVIEW value object. Anyway for comparison, using the 10,000 insert code you posted, on my computer with LV2010.
Yours
Insert 1202ms
select 6657ms
Mine
Insert 451 ms
Select 251 ms
My select uses the same basic logic as yours (at least for values stored as strings). The main difference is that I prealloc 16 rows (note: it doesn't have to be 16 that just seemed like a good starting number to me), use replace subset to fill the values in and if I need more space I double the array's size (I just concat it to itself), at the end I reshape the array back down. Changing the allocation should make yours faster than mine (since you aren't dealing with type information).
My insert is faster because I'm using prepared statements and value binding. I'm also only opening the file once, which probably accounts for some of the difference.
Matt W
-
I believe the defaults can be set in the XControl's Init ability.
Matt W
-
The generated encompassing circle can be too big when three (or more) of the sub circles touch the edge of the true minimum circle, the one I posted will work with all cases when only two or one sub circles touch the true minimum circle. So while it'll always generate an encompassing circle in many cases it may not generate the minimum encompassing circle.
Matt W
QUOTE (george seifert @ Mar 11 2008, 07:46 AM)
There's an edit saying it doesn't work. I checked it out with some of my data and it looks pretty good to me. Why do you think it doesn't work?George
-
QUOTE(george seifert @ Mar 10 2008, 04:42 AM)
That's an excellent question. I thought they were the same problem, but now that you made me think about it, Apolllonius' problem might not always apply in my case. The smallest circle may not always touch all three of the inner circles. Wow, it sure helps to have a few extra heads involved - and ones with better brains than mine. So it looks like I'm back to my original solution (Use IMAQ Find Circular Edge VI to define the encompasing circle. If the fit isn't prefect, subtract the mass from the circle found to give the area that's not covered and slowly increment the radius of the encompasing circle until the area is 0.) I tried the IMAQ Centroid VI, but that didn't come out anywhere close.Thanks for help. I'd still like to find a mathematical solution if one exists.
George
[edit]Never mind this doesn't work[/edit]
I really surprised noone else has figured this out.
See attached for a VI that should solve your original miniimum radius problem.
Matt W
-
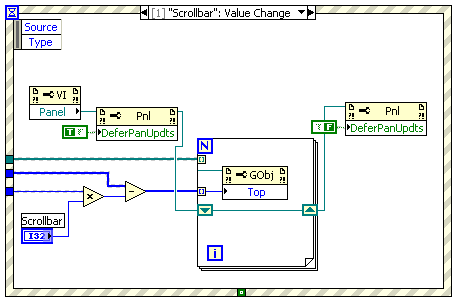
QUOTE(Graeme @ Jan 7 2008, 01:11 PM)
You can also remove the flashing by defering panel updates, during the for loop.
http://lavag.org/old_files/monthly_01_2008/post-7834-1199740584.png' target="_blank">
Matt W
-
QUOTE(jlokanis @ Dec 17 2007, 03:17 PM)
Just an update:It was not memory fragmentation afterall but rather a resource leak cause by this little bugger:
http://lavag.org/old_files/monthly_12_2007/post-2411-1197933305.jpg' target="_blank">

Always always ALWAYS close the reference that this thing returns! :headbang:
So, in the end, as usual the problem was my own creation...

Time to go drink many :beer: :beer: :beer: ....
Thanks for posting the cause, you've saved me from a big headache. Since I made the same mistake.
Matt W
-
QUOTE(Lars-Göran @ Nov 14 2007, 01:06 PM)
Hi Matt!I think there's one problem with your solution. If a statechart continously generates internal triggers, your external trigger will never have the chance to get into the statechart.
What I would like, is to have the InternalQueue exposed to the ouside of the statechart, so that external and internal triggers are handled on equal terms.
(The queue then of course isn't internal anymore, so perhaps it should be renamed to "TriggerQueue").
As mentioned before, we will then also have the benefit of rendering the loop around the statechart superfluous.
And as you pointed out, if we could get triggers to carry data along, that would be great. I think I would prefer a variant instead of a cluster, to avoid sending data that is not of relevance for a specific trigger.
Lars-Göran
I hadn't thought of continuously generating internal triggers. I'm not sure if this would work but you could ignore the internal queue entirely, and send the internal triggers to the external queue. Personally I like the concept of iterations since it seems to makes timing data acquisition used by the statechart easier.
I meant that each trigger would have it's own cluster (or none), and states that trigger off of that it would have access to that cluster. Much like NewVal in the event structure for a value change event, which only turns into a variant if there's multiple controls with incompatible types.
Matt W
-
QUOTE(Lars-Göran @ Nov 13 2007, 12:29 PM)
http://forums.ni.com/ni/board/message?boar...ssage.id=280719
This still requires a while loop, but if you embed it in a subvi you effectively have the same thing. I found the concept of iterations to be helpful once I started using the inputs and outputs of the statechart.
This would be easier if trigger's had built in (and typed) way to pass parameter's with the trigger. Which is a feature that needs to added in my opinion (and can be added onto the current statechart models). Currently I can either use a variant (losing static type checking) or a large cluster (wasting memory).
Matt W
-
QUOTE(LV Punk @ Sep 7 2007, 05:04 AM)
I'm not sure my customer (Uncle Sam) would commit to using this; but it looks good. Most TOE stuff requires a high-end server config (that I don't have).The dual-core (or quad, what the heck!) has been in my mind; I might be able to get my supplier to let me eval and check the performance difference.My main concern with it would be reliability (I heard the early drivers were flaky, I'm not sure if that's still the case,but only way to be sure is to test it). Also the standard (32 bit, 33 MHz) PCI bus only has 133 MB/s of bandwidth (gigabyte has a theoretical peak of 125 MB/s), so if you have anything other than a Gigabyte NIC on that bus you could run out of bandwidth. In older mother boards the hard drive controller would typically hang off the PCI bus, which would be limiting if that's the case on the current motherboard.
Even a Slow 1.8 GHz Core 2 should be faster than a 3.0 GHz p4 in the majority of cases (including running with only one core). Let alone a 2.4 GHz quad core (the cpu only costs ~$280). But I doubt your motherboard supports it (even though it may have the right socket).
You can get an idea of the speed difference here.
-
QUOTE(LV Punk @ Sep 6 2007, 05:26 AM)
I've been slowly adding higher and higher data rates to my multichannel UDP receiver and have pegged the CPU (95-100% while streaming). The effective rate is 3 channels * 4800 messages/sec * 512 bytes/message or ~ 59 Mb/s. I'm looking to free up some cycles for additional features. I recalled reading some time ago about smart NICs that offload some of the TCP processing from the CPU, so I started Googling.The proper term seems to be TCP Offload Engine (TOE). No fetish jokes or links to "inapropriate for work" sites please

Anyone have experience with TOE? So far I've only found PCI-X NICs and references to 64 bit Windows; I'm more interested in a PCI / XP Pro solution. I can't change out my processor or backplane at this time; I'm using a P4 3.0 GHz, 2 GB RAM and in a rackmount PC with passive backplane (PCI only).
In my mind the best option would be to upgrade the CPU, to a Core 2 based one (if possible), but since that doesn't seem to be an option now.
I've never used one, and have no idea how well it would work (it's built for low latency gaming, so I don't know what it'll do in your use case), but a http://www.killernic.com/ goes beyond TOE. It basically runs a linux os on the network card that can offload a lot of the network processing (it could offload the firewall for instance in addition to the tcp stack). Also It's PCI and XP compatable.
Refnum type propagation
in LabVIEW General
Posted
Your code has a memory leak. The reference created by OwningVI needs to be closed. I have a similar bit of code and it took me half a day to track down that memory leak. You can use the desktop execution trace to find hanging references (which didn't exist back then).