Cat
-
Posts
817 -
Joined
-
Last visited
-
Days Won
15
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by Cat
-
I've posted to serverfault.com. Hopefully someone there will have an answer. You mean use pcfs and not ufs format for the Solaris disks? And then theoretically there shouldn't be a problem reading the disk in either a Solaris or a Windows box? Hmm, that's an interesting concept. I've just made my Unix guy happy by giving him this as his Science Project of the Day.
-
So close, so close and yet... (From what I can tell after installing it and getting it up and running) SFU will allow a Windows box to map to drives on a Solaris box without having to install something like Samba on the Solaris side. Still can't read a Solaris drive sitting in a Windows box. (But this might be useful on an entirely different project) I'm going to check out stackoverflow.com and serverfault.com next. Thanks!
-
Yes, I've looked at both of those. The first (IIRC) was for linux, not solaris, and the second was one of those that will copy a file from the disk, but doesn't actually map a drive letter to the disk. I've tried several things from SourceForge, and they all fell into one of those 2 categories. But thanks for looking!
-
You'd think, wouldn't you?? I can't be the first person to want to read a Solaris formatted disk in a Windows machine. I tried some UNIX forums, and the reply was generally, "This is a windoze problem. Go ask them." The response from the Windows forums was, "who wants to read a Solaris disk?" Of course, there are so many forums out there, I probably just didn't hit the right ones. I'll keep trying. This can't be all that difficult. In the meantime, I'm going to look at pushing a 2 machine system again, one Solaris, one Windows, and use Samba to map to the data. It may be more upfront cost, and one more box to haul around, but there will be a significant time/labor $ savings, not to mention the data will be ready in about 25% of the time. Hopefully that's worth something to somebody.
-
Apologies first: I originally posted this in info-LabVIEW about a month ago. Unfortunately no one could come up with a solution there (Uwe and Bruce, if you're here, thanks again for trying!). Hopefully the wider audience here might include someone who has experience with this. ________________ Short story: I need some way to map a UFS Solaris drive (ie, assign a drive letter to it) while it is in a Windows XP box. Long story: I have finally convinced The Powers That Be to get rid of our very small SCSI drives on our Solaris 10 boxes and replace them with SATA drives. Due to the small size of the SCSI drives, we have to offload data to tapes, and often generate upwards of a hundred tapes on a test. The SCSI tape drives are very problematic, very expensive, and random access does not exist. My thought was that if we went to Tbyte SATA drives, we could replace those tapes with 30 disks. Much cheaper, much more reliable, and separate runs of data are easily accessible. But... All that data needs to be read, processed, and transferred to a Windows-based storage system. In other words, I will pull those UFS format disks out of the Solaris box and put them into my multi-bay disk drive Windows box. At that point I need to be able to access the files, via an assigned drive letter to the UFS disk, as if it were a Windows disk. Of course, I will be doing all of this in LabVIEW (just to keep this post slightly on topic :-) I (and a couple cow-orkers) have done a pretty extensive search on the web. I have downloaded and installed several utilities, hoping they would work, to no avail. They either only work with Linux-flavored disks, or they allow the user to copy UFS format files to a Windows box using their own interface -- not a true map to Windows; no drive letter assigned. Copying the files this way would be a last choice solution, as it takes about 3 hours to perform this operation on a full Tbyte disk. And then another 3 hours to read the copied data, process it and copy it back to disk. This will double the overall processing time. And I will have 30 disks to do this on... Our fallback is to put a bunch of the disks in some multi-bay Solaris box, run Samba on it, and map the drive on a Windows box that way. But now it requires 2 machines to do this instead of 1. And as we need multiple test setups, this could be cost-prohibitive. Any solutions, suggestions, thoughts, words of sympathy, snorts of laughter, etc? ____________________ Follow-up: The boss chose the (short-term) cheaper, longer way -- copy the files using an app that can read UFS and write NTFS, and then (using LabVIEW) read/process/write the data. The data processing lab is entirely Windows-based, and I think they're scared of having a Solaris box in the same room... I purchased UFS Explorer, which at first looked like a nice little package. Unfortunately the translation is taking much longer than I expected. It runs at around 25MB/s. At that rate, what I thought would only take 3 hours, takes 9 hours to translate a 1TB drive, and that's not including processing time. I'm not sure why this is, since just FTPing a full drive drive across the network would only take 4 hours. I've got an email into their tech support to see if it normal to go that slow, but I'm not holding much hope out for a faster solution. So I'm still stuck with my original 2 solutions, neither of which are very good. Any one out there have a better idea? Something that would let me read a UFS file formated disk in a Windows box, so I can then process the data, and write NTFS, without having to go thru an intermediary write/read NTFS step? Cat
-
And here I thought LAVA Lounge was just for alfa threads. I've tried various other forums to no avail. I'll post it to LAVA Lounge.
-
Over the years, I have occasionally had a technical but non-LabVIEW related problem I couldn't seem to solve. And every once in awhile I've gotten so frustrated that I've posted it to a LV forum (here, or info-LabVIEW) anyway. With all sorts of apologies for being off-topic appended, of course. There are a lot of smart people on this forum who know a lot about non-LabVIEW related things. I was wondering how The Powers That Be (and the rest of you guyze) would feel about having an actual sub-forum for technical, but non-LabVIEW related topics? Or is there already some tacitly agreed upon place to post this sort of thing? Or is it really a Big No-No that we should discourage? (and yes, this is a bit self-serving, since I do have a technical but non-LV related problem I need help with ) Cat
-
Just the two. English and Electrical Engineering. Even better, they bought me a whole bunch of margaritas.
-
My boss just asked me if there was any LabVIEW training I wanted to take next year. I told him probably, but I did know of something that would be even better to attend than just regular training. You see, I told him, NI holds a conference every year, and it's not just a conference, there are all sorts of lectures and seminars that address high level issues in LabVIEW that would be very professionally beneficial for me to attend. And he bought it! He said to remind him a few months before so he could make sure he set aside the funding. NI Week, here I come! (in 11 months and 2 weeks ) Cat
-
True confessions: my first degree was in English, so I don't have the usual aversion to the written word that most engineers have. Of course not! The glasses are generally thick black-framed, with masking tape around the nose bridge. They wouldn't get me on a submarine, otherwise. We're a bunch of low-paid government engineers here. And until a year or so ago we would "max out", ie work for free, after an increasingly small number of OT hours. One test I was on a sub for 7 days. After day 4, I was working for free. I remember sitting across a table in the crew's mess from two contractors (Electric Boat) who were discussing how they got paid OT 24 hours per day while they were on a sub. I told them they were buying me dinner when we finally got off the boat.
-
It is a bit concerning. I don't use Mathscript, but lots of people around here use MatLab, and it's always been nice to be able to say that LabVIEW comes with hooks into MatLab. I guess I'll now (or in a year) have to add, "for an additional cost." But what is *really* concerning is that someone stated that old code using mathscript wouldn't work until you activate the new license. And when LV2010 comes out, old code won't work unless you shell out even more $$ to renew the Mathscript license. I couldn't find a denial of this in any of the NI responses. If this is true, it is a Bad Thing. Cat
-
I work for the American taxpayer. She just happens to be the one who cares enough to ask. Wow! That could even handle my aggregate data rate of +300MB/s. Wow again! I think that we will at some point in the future go to SSD if only because of durability. Zeros and ones tend to fall off of regular drives if you drop them, and losing data from a several hundred thousand dollar test is a Bad Thing. SSDs, at least the ones currently out on the market, can handle that sort of thing. I think I'll need to get a trampoline for the office tho, so I can thoroughly test them.
-
Well, actually it took me all of 5 minutes to put my own notes into a more formal format and plonk it in his lap. I understand what you're saying. However... Throughout this thread, I've been flashing back on a design meeting that we had with one of our user groups about a year into a major project. We had released the beta version of the hardware/software and they had come back to us and told us it was missing a key feature. Something that would take a few months and lots of $$$ to add at that point. This project actually did have several hundred pages of design documents, but nowhere did this feature appear. No, it wasn't our fault it had been overlooked, but it didn't matter. These users couldn't do their job without that feature. So we added it. This sort of thing happens (albeit at a much smaller level) all the time. No, you just sound like an actual engineer. My team leader goes on accasional rants about how despite all our college degrees, none of us operates as a true engineer. I just tell him to put his money where his mouth is. That may have lead to the request for the SOWs. Wow, you deliver User Manuals?!? Dang! We delivered a $2M data acquisition system a couple years ago, and then had to go begging for money to get users trained up on how to install/operate it. We had put together a training manual, but no one wanted to pay our technicians/analysts for a couple days worth of time to take the training. The culture here is for on-the-job training, which was fine for older systems that weren't very complicated. This one had been designed by a committee of several different user groups and was full of all sorts of esoteric functions. The fact that most of the hardware was bleeding edge technology and prone to needing fixing at first (talk about a configuration management nightmare), didn't help, either. So, here we are two years later, and we're still having to go out with the system when it's deployed. I'm a system developer, not an analyst or a technician. Some of my cow-orkers love the overtime, but as long as my software is working, I personally want to spend as little time as possible on submarines (the usual test platform). We're starting design of the next generation of our system, and I am finally in a postion to influence that. User-level Documentation will be a deliverable. There will be money for training. As we always say before a new project, "This time we're going to do it right!"
-
Interesting idea! However, I'd have to get 4 SSDs to replace my 1TB drive. And I'm delivering the system with 2 drives... I may go ahead and buy an SSD just to see if they're as fast as they say they are. My *real* application (the Big Project) would need to replace 70 Tb drives, about 6 times a year. I don't think that's happening any time in the near future! I'd have a hard time justifying that to my mother when she asks me if I've been spending her tax dollars wisely.
-
That's a good idea. I had a project a few years back where I had to create tip strips for 1024 indicators. After that I never wanted to see a tip strip again. I should probably give them another chance.
-
If there is a discrepancy between code and docs, I'm going to believe the code. Assuming it worked at one point, the code doesn't lie. And the only thing worse than no documentation is incorrect documentation. I agree the unbundle/bundle of a state is great internal documentation. That's my second pic in my original post. But the problem comes when you're an anal-retentive coder (like me) and insist on everything being neat and tidy. In this instance that means everything in a BD having to fit on one screen. All the wraps around the state machine take up lots of screen room (my development computer is 1024x768) so I tend to turn each state into a subvi to get more wiring space. So now that self-documentation is buried down another layer. When I'm first looking at the code again after a couple years, I have to click in and out of all the state subvis to figure out what gets read/written where. I'm doing that now with a piece of code, and looking at ways to make that process easier in the future is what started this whole thread. Either that, or I need to get therapy for my anal-retentiveness, and then this wouldn't be a problem anymore.
-
I just about went off on another rant about my job. Two mornings in a row would be too much. Reader's Digest version: I do have the luxury, and the pain, of being a "team of one". Everyone else here is working in some variant of C. I interface to a lot of different systems, and those interfaces I insist on documenting. With external documentation. What I was trying to address in my original post is internal documentation for *me* when I have to go back 3 years later and remember what I was doing to reuse code. Unless I get hit by a bus on the way to work someday, the odds of anyone else ever looking at my code are pretty slim, so any code cleanup/documentation of my own software is entirely for my own benefit. The culture here is to do everything on-the-fly. Mid-range projects ($250k+) and up have SOWs and appropriate top level design docs, but after those pass review, all bets are off. "Design meetings" consist of me and a user sitting down in front of a computer and them telling me something like, "I want a button that will export all this spectra data to Origin." Delivery dates are nebulous as testing is continually ongoing and code can often be delivered at any time. All my customers are internal, and while I can't say money is no object, if someone wants something badly enough someone can generally be found to fund it. The good side of all of this is there is a very strong sense of support for the concept of "do whatever it takes to get it done", but unfortunately it's often accompanied by "just don't bug me about the details until it's done and then I'll let you know if it needs to be changed". That's just the way things work around here. The good news is that my (relatively new) team leader came to me the other day and suggested we start generating SOWs for even our little 2 week tasks! I got all wide-eyed and he thought I was going to protest, but I happily agreed. It's not detailed design documentation, but you have to start somewhere.
-
First of all, thanks to Francois and Christian for answering my original question. Ton, your Code Capture Tool looks very useful. Omar, I will definitely take a look at the JKI State Machine. Now, to the trashing of my coding style... That particular piece of code has very few states that automatically follow the one before. It can diverge in several spot and reconverge only at exit. Or it might follow step by step, depending on what the user has requested. Not to mention the fact that there are different error modes that need to be handled differently. Just serially linking the states is not feasible, and I believe a state machine is the best option here. Rolf, I'm trying to wrap my brain around what I *think* you're saying -- you in essence try to decouple your data from your code, so it doesn't matter what form the data is in (I guess this is OOP-like). I can see how this might be a Good Thing, in theory, but I'm not quite sure how it would really save me development time in a practical sense. Yes, I am keeping all the data that pertains to this state machine in the shift register. Since the vast majority of it is not used anywhere else in the code, that seemed the logical place. Using functional globals and file I/O seems unnecessary when I can just string a wire from one state to another. I'm not sure how big is too big for a state machine cluster, but if I'm passing large arrays around, I do it by reference, not with actual data. Shaun, unfortunately I am not developing in a vacuum. No one in my organization has the luxury of externally documenting code to the level you are able to. I tried it when I started working here eons ago, but the reality is that requirements for the projects I work on are an ever-moving target. It used to drive me crazy, until I finally gave up, drank the kool-aid, and just started trying to go with the flow. I code a basic structure, go back to the users, get their input, code a little more, add another function that someone just decided they can't live without, code that up, go back to the users, etc, repeat, until everyone is (relatively) happy. Then I take my project out on the test platform, and discover that in the heat of battle, it's really used completely differently than the users thought they'd be using it, or the data stream something else is supplying to me is full of errors I have to compensate for. I can't just say, "Sorry, that wasn't in the original specification and you're not getting it." One of the benefits of being here for so long is that I can generally anticipate changes/additions that might be requested, but my users are always surprising me. I still do a top-level initial design, but the vast majority of the time the final product is very different, and any detailed design I would have done is obsolete. Oh, and then there's the harsh reality that nobody who's paying me wants to pay for detailed external code documentation. I’m not saying it’s right, but it is reality (mine, at least). So, it's very important to me to make sure I internally document the code as I go along. That is one place I can more-or-less keep up with the infinite changes. Hence my original question. Shooey. It's a little too early in the morning for a my-job-can-be-a-real-pain rant. My head hurts. Cat
-
Wouldn't that be nice! Maybe as soon as they are available in 1Tb versions. For under $150. I'm not holding my breath.
-
I'm ripping apart some code I wrote a couple years ago to "reuse" it for a new project. A main chunk of it is a state machine. When I'm in the midst of programming something, I generally have all the inputs and outputs to the different states more-or-less memorized, but in this case I was flipping in and out of states a lot trying to figure what was where. This led me to trying to come up with a good way to document state machines. I started with a typical SM: Below is how I used to do it. As documentation goes, it's the best way, for programming, however, it's a pain to add/subtract inputs/outputs, negating one of the main reasons to use bundles/state machines. One of my states uses 13 inputs... So I went to this: What I don't like about it is that it loses the color-coding of the inputs/outputs. The colors really help make it easier to find things. And I have to be very anal-retentive about keeping it updated. So I tried this: It's easy to do, just go into the state vi, copy the unbundle and bundle, and paste them in the SM. The problem being, of course, that it breaks the code, and requires disabling the code. It's actually easier to read than it looks like from this pic, but it still is on the "foggy" side. Anyone have other ideas? Or has this one already been solved and I just wasted a half hour making pretty screen shots?

-
Convince a woman from North America to marry you.
-
And all the head honchos who would usually welcome you are having fun at NI week. Damn them all. So welcome from the B list!
-
I work for the US Navy and they are extremely paranoid about network issues. Not necessarily a bad thing, but when it leads to situations like the one here where we're stuck with an 8 year old application, it can become really annoying. When I talked with our head IT guy about this, he said he'd heard rumors upgrade testing is almost done for the next version. Yup, any year now, we should be getting IE 7. As far as going rogue, IT Guy and I discussed that, too. Big Brother nightly scans for changes to IE and other application settings and returns everything to their chosen settings. IT Guy said there is a version of Firefox out there that doesn't require a formal installation. Of course he followed that up with the fact that someone else here had that file just sitting on his computer -- not even running -- and he was cited for a security violation. I really don't want a security violation... Enough ranting! Back to using stone knives and bear skins to get my job done!
-
I would, if Big Brother didn't own the computer I'm sitting in front of. We're not allowed to upgrade or add other applications (ie, Firefox). Thanks for checking it out.
-
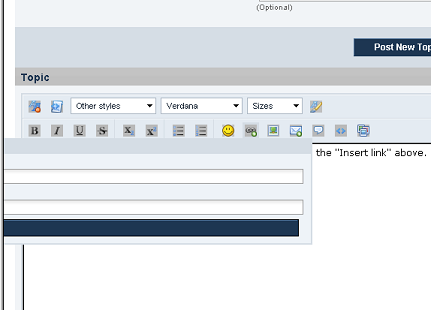
This is what I see when I click on "Insert link": By trial and error, I figured out I'm supposed to enter the URL into one or the other of the white boxes, and then select the blue box, and the link appears in my post. Something similar happens if I click on "Insert image". I'm running on IE6, if that matters. No, I can't upgrade... Cat