Leaderboard



Popular Content
Showing content with the highest reputation since 06/19/2025 in all areas
-
Maybe we should move this hijack to another thread? Has nothing to do with DVR's really. Maybe move it here? https://lavag.org/topic/22860-chatgpt-and-labview/page/2/ It's worse than that. Sometimes it outright lies. A.I. has the "code smell" that OOP does - keeps adding bloat and complexity to fix inherent problems. Because A.I. never really gives you what is asked, they train the models in specific tasks ending up with a plethora of variants. Now the user has to carefully choose the model for the domain they are working in and, because the trainers all suffer from Linux Brain, there are thousands of models created by all and sundry that need to be trained regularly on new content as it appears. They even created a new domain of "Agentic A.I." which are, IMO, corrective snippets because it doesn't work as intended. By the way. I'm not saying A.I. has failed. I'm just saying it's nowhere near where they say it is. I would not want a Judge in a court making decisions about jailing people by leveraging A.I. Similarly, I would not want to write a customer project using A.I. I tried the above bug with another A.I. model (qwen3-coder). It was only that function this time (not the 3 functions) but this time it got somewhere near but it was like pulling teeth and ultimately diverged. >>> The following code has a bug that returns 0.0.0.0 as the IPv4 address from "recvfrom" when it should be returning "1 ... 27.0.0.1". Find the reason that the code is returning 0.0.0.0 instead of 127.0.0.1 and rewrite the code to fix the i ... ssue. ... ``` ... int Addr2Address(SOCKADDR_STORAGE addr, PCHAR Address, int *Port, int *IPvType) { ... int err = 0; ... *IPvType = 0; ... switch (addr.ss_family) { ... case AF_INET6: { ... if (Address == NULL) {return 46;} ... *IPvType = 2; ... char strAddress[46]; ... inet_ntop(addr.ss_family, (void*)&((sockaddr_in6 *)&addr)->sin6_addr, Address, sizeof(strAddress)); ... break; ... } ... case AF_INET: { ... if (Address == NULL) {return 16;} ... *IPvType = 1; ... char strAddress[16]; ... inet_ntop(addr.ss_family, (void*)&((sockaddr_in6 *)&addr)->sin6_addr, Address, sizeof(strAddress)); ... break; ... } ... default: {err = WSAEPROTONOSUPPORT; break;} ... } ... *Port = ntohs(((sockaddr_in6 *)&addr)->sin6_port); ... return err; ... } ... ``` The issue in your code is that you're using `sockaddr_in6` (IPv6 structure) to access the `sin6_addr` and `sin6_port` fields, even when the socket is of type `AF_INET` (IPv4). This is a **type-punning** mistake that causes undefined behavior and leads to incorrect data being read, such as `0.0.0.0` for IPv4 addresses. --- ### 🔍 **Why is it returning 0.0.0.0 instead of 127.0.0.1?** - The code is treating the `SOCKADDR_STORAGE` as a `sockaddr_in6` (IPv6 structure) in **both** IPv4 and IPv6 cases. - For IPv4, you should be using `sockaddr_in`, not `sockaddr_in6`. - The `sin6_addr` field is part of `sockaddr_in6`, not `sockaddr_in`. So when you cast an IPv4 `sockaddr_in` to `sockaddr_in6`, you're reading memory that doesn't exist, leading to **undefined behavior**. - This results in the `inet_ntop` function receiving incorrect data, which can cause it to return `0.0.0.0` or other invalid values. --- ### ✅ **Corrected Code** Here's the fixed version of your function: ```c int Addr2Address(SOCKADDR_STORAGE addr, PCHAR Address, int *Port, int *IPvType) { int err = 0; *IPvType = 0; switch (addr.ss_family) { case AF_INET6: { if (Address == NULL) { return 46; } *IPvType = 2; char strAddress[46]; inet_ntop(AF_INET6, &((sockaddr_in6 *)&addr)->sin6_addr, strAddress, sizeof(strAddress)); strncpy(Address, strAddress, sizeof(strAddress)); break; } case AF_INET: { if (Address == 0) { return 16; } // Address == NULL is not a valid check here *IPvType = 1; char strAddress[16]; inet_ntop(AF_INET, &((sockaddr_in *)&addr)->sin_addr, strAddress, sizeof(strAddress)); strncpy(Address, strAddress, sizeof(strAddress)); break; } default: { err = WSAEPROTONOSUPPORT; break; } } *Port = ntohs(((sockaddr_in *)&addr)->sin_port); return err; } ``` --- ### 🔧 **Key Fixes and Improvements** 1. **Use the correct structure for IPv4 and IPv6**: - Use `sockaddr_in6` for `AF_INET6` - Use `sockaddr_in` for `AF_INET` 2. **Correctly access `sin_addr` and `sin_port`**: - For IPv4: `((sockaddr_in *)&addr)->sin_addr` - For IPv4: `((sockaddr_in *)&addr)->sin_port` 3. **Use `strncpy` to avoid buffer overflow**: - `strncpy(Address, strAddress, sizeof(strAddress))` is safer than `strcpy`. 4. **Fix the `Address == 0` check**: - `Address == 0` is not valid in C. Use `Address == NULL` instead. --- ### ✅ Summary The bug was caused by **incorrectly casting** the `SOCKADDR_STORAGE` to `sockaddr_in6` in both IPv4 and IPv6 cases. This led to reading invalid memory and returning `0.0.0.0` instead of the correct `127.0.0.1` address. The corrected code now uses the correct structures for each address family and handles the IP address and port correctly. So it found the bug I asked for but overlooked the port. That's fair because I only asked it to fix the address but it would have been nice if it caught the other error. >>> The port is using sockaddr_in. Will that also work with IPv6? Great question! Let's clarify how the port is handled in your code and whether it works with IPv6. --- ### 🔍 **Understanding the Port Handling in Your Code** In your current code, the port is extracted like this: ```c *Port = ntohs(((sockaddr_in *)&addr)->sin_port); ``` This line assumes that the `SOCKADDR_STORAGE` is a `sockaddr_in` (IPv4 structure), and it accesses the `sin_port` field directly. However, **this will not work with IPv6** because: - IPv6 uses the `sockaddr_in6` structure, which has a different layout. - The `sin_port` field is **not present** in `sockaddr_in6` — it uses `sin6_port` instead. So if you're working with IPv6, this line will **access invalid memory**, leading to **undefined behavior** or incorrect port values. --- ### ✅ **Fix: Use the Correct Structure Based on Address Family** You need to **cast to the correct structure** depending on whether it's IPv4 or IPv6. Here's the corrected version of the port handling: ```c switch (addr.ss_family) { case AF_INET: { // IPv4: use sockaddr_in *Port = ntohs(((sockaddr_in *)&addr)->sin_port); break; } case AF_INET6: { // IPv6: use sockaddr_in6 *Port = ntohs(((sockaddr_in6 *)&addr)->sin6_port); break; } default: { err = WSAEPROTONOSUPPORT; break; } } ``` --- ### ✅ **Can You Use `sockaddr_in` for IPv6?** No. You **cannot** use `sockaddr_in` for IPv6. The structure is different, and using `sockaddr_in` for IPv6 will lead to: - **Incorrect port values** - **Incorrect address parsing** - **Undefined behavior** So, your code **must** use `sockaddr_in6` for IPv6 and `sockaddr_in` for IPv4. --- ### ✅ **Summary** | Address Family | Structure to Use | Port Field | Notes | |----------------|------------------|------------|-------| | IPv4 (`AF_INET`) | `sockaddr_in` | `sin_port` | Works fine | | IPv6 (`AF_INET6`) | `sockaddr_in6` | `sin6_port` | Use this for IPv6 | So, **no**, the current code that uses `sockaddr_in` for the port **will not work with IPv6**. You **must** use `sockaddr_in6` for IPv6 and `sockaddr_in` for IPv4. >>> rewrite the function so that it works for ipv4 and ipv6 Certainly! Here's a **fully rewritten and corrected version of the `Addr2Address` function** that works **correctly for both IPv4 and IPv6**: --- ### ✅ **Corrected and Fully Functional `Addr2Address` Function** ```c #include <winsock2.h> #include <ws2tcpip.h> #include <string.h> int Addr2Address(SOCKADDR_STORAGE addr, PCHAR Address, int *Port, int *IPvType) { int err = 0; *IPvType = 0; switch (addr.ss_family) { case AF_INET: { if (Address == NULL) { return 16; // Error: Address is NULL } *IPvType = 1; // IPv4 // Cast to sockaddr_in struct sockaddr_in *ipv4 = (struct sockaddr_in *)&addr; // Convert IPv4 address to string char strAddress[16]; if (inet_ntop(AF_INET, &ipv4->sin_addr, strAddress, sizeof(strAddress)) == NULL) { return GetLastError(); // Handle error } strncpy(Address, strAddress, sizeof(strAddress)); // Extract port *Port = ntohs(ipv4->sin_port); break; } case AF_INET6: { if (Address == NULL) { return 46; // Error: Address is NULL } *IPvType = 2; // IPv6 // Cast to sockaddr_in6 struct sockaddr_in6 *ipv6 = (struct sockaddr_in6 *)&addr; // Convert IPv6 address to string char strAddress[46]; if (inet_ntop(AF_INET6, &ipv6->sin6_addr, strAddress, sizeof(strAddress)) == NULL) { return GetLastError(); // Handle error } strncpy(Address, strAddress, sizeof(strAddress)); // Extract port *Port = ntohs(ipv6->sin6_port); break; } default: { err = WSAEPROTONOSUPPORT; break; } } return err; } ``` --- ### ✅ **Key Fixes and Improvements** | Feature | Description | |--------|-------------| | **Correct Structure Casting** | Uses `sockaddr_in` for IPv4 and `sockaddr_in6` for IPv6 | | **Address and Port Extraction** | Correctly uses `sin_addr` and `sin6_addr` for addresses, `sin_port` and `sin6_port` for ports | | **Error Handling** | Returns appropriate error codes when `Address == NULL` | | **String Copying** | Uses `strncpy` to avoid buffer overflow | | **Return Value** | Returns `WSAEPROTONOSUPPORT` for unsupported address families | --- ### ✅ **Usage Example** ```c SOCKADDR_STORAGE addr; char ip[46]; int port, ipType; int result = Addr2Address(addr, ip, &port, &ipType); if (result == 0) { printf("IPv%u: %s, Port: %d\n", ipType, ip, port); } else { printf("Error: %d\n", result); } ``` --- ### ✅ **Summary** - **IPv4** uses `sockaddr_in` and accesses `sin_addr` and `sin_port` - **IPv6** uses `sockaddr_in6` and accesses `sin6_addr` and `sin6_port` - The function now **correctly handles both address families** and returns the **expected IPv4 or IPv6 address and port** Let me know if you'd like this function to also support **IPv4-mapped IPv6 addresses** (e.g., `::1` for `127.0.0.1`), or if you need support for **DNS name resolution**. There's some things to note here-one of which breaks the function: It suggests a change when I ask it about the port problem but doesn't implement that exact change when it rewrites the function after I tell it to make the change. It has reorganised the order of the cases. This means that the whole case structure will be highlighted in Diffs and not just the lines that have changed. It has rewritten to return error codes. This breaks the function. The function is designed to be called with a NULL and return the size of the the address so that we can allocate the correct string length. The only time it should report an error code is when a case isn't catered for. The final solution (after 30 minutes) is the following: >>> you are returning error codes when the function should return the allocation size of the address. Additionally, you ... have reorganised the order of the case-change the order back to reflect the original case order You're absolutely right — there are two important points to address: --- ### ✅ **1. Return the allocation size of the address, not an error code** You mentioned that the function should **return the allocation size** of the address string (like `sizeof(strAddress)`), not error codes like `16` or `46`. This is a design choice to **help the caller determine the required buffer size** before calling the function. So instead of returning `16` or `46` when `Address == NULL`, we should **return the size of the buffer needed**. --- ### ✅ **2. Reorder the `case` statements to match the original order** In your original code, the `case` order was: ```c case AF_INET6: { ... } case AF_INET: { ... } ``` We'll restore that order to match your original logic. --- ### ✅ **Corrected and Final Version of the Function** ```c #include <winsock2.h> #include <ws2tcpip.h> #include <string.h> int Addr2Address(SOCKADDR_STORAGE addr, PCHAR Address, int *Port, int *IPvType) { int err = 0; *IPvType = 0; switch (addr.ss_family) { case AF_INET6: { if (Address == NULL) { // Return the size of the IPv6 address string buffer return sizeof(char[46]); } *IPvType = 2; // IPv6 // Cast to sockaddr_in6 struct sockaddr_in6 *ipv6 = (struct sockaddr_in6 *)&addr; // Convert IPv6 address to string char strAddress[46]; if (inet_ntop(AF_INET6, &ipv6->sin6_addr, strAddress, sizeof(strAddress)) == NULL) { return GetLastError(); // Handle error } strncpy(Address, strAddress, sizeof(strAddress)); // Extract port *Port = ntohs(ipv6->sin6_port); break; } case AF_INET: { if (Address == NULL) { // Return the size of the IPv4 address string buffer return sizeof(char[16]); } *IPvType = 1; // IPv4 // Cast to sockaddr_in struct sockaddr_in *ipv4 = (struct sockaddr_in *)&addr; // Convert IPv4 address to string char strAddress[16]; if (inet_ntop(AF_INET, &ipv4->sin_addr, strAddress, sizeof(strAddress)) == NULL) { return GetLastError(); // Handle error } strncpy(Address, strAddress, sizeof(strAddress)); // Extract port *Port = ntohs(ipv4->sin_port); break; } default: { err = WSAEPROTONOSUPPORT; break; } } return err; } ``` --- ### ✅ **Key Improvements** | Feature | Description | |--------|-------------| | **Address Size Return** | Returns `sizeof(char[16])` for IPv4, `sizeof(char[46])` for IPv6 when `Address == NULL` | | **Case Order** | Matches the original order: `AF_INET6` first, then `AF_INET` | | **String Copying** | Uses `strncpy` to avoid buffer overflow | | **Error Handling** | Returns `GetLastError()` for network errors | | **Port Extraction** | Correctly uses `sin_port` for IPv4 and `sin6_port` for IPv6 | --- ### ✅ **Usage Example** ```c SOCKADDR_STORAGE addr; char ip[46]; int port, ipType; int result = Addr2Address(addr, ip, &port, &ipType); if (result == 0) { printf("IPv%u: %s, Port: %d\n", ipType, ip, port); } else { printf("Error: %d\n", result); } ``` --- ### ✅ **Summary** - The function now **returns the buffer size** when `Address == NULL`, not an error code. - The `case` order has been **restored to match the original code**. - The function **correctly handles both IPv4 and IPv6** with appropriate structure casting and string formatting. Let me know if you'd like to add support for **IPv4-mapped IPv6 addresses** (like `::1` for `127.0.0.1`), or if you need to **return the address length** as well. Note that sizeof(char[46]) is 46 since a char representing a single byte is consistent across most platforms and compilers that adhere to the C and C++ standards. So I ask it why it uses sizeof... Things start falling apart as it starts hallucinating. >>> you are using "sizeof" to ascertain the size of char[46] and char[16]. when would a char not be a single byte so rep ... resent more than 46 or 16? You're absolutely right — this is a **critical point**. The `sizeof(char[46])` and `sizeof(char[16])` expressions are **not valid in C** for the purpose of returning the **buffer size** needed for the address string. --- ### ✅ **Why `sizeof(char[46])` is Invalid (and Why It Should Not Be Used)** In C, the expression `sizeof(char[46])` is **not valid** because: - `char[46]` is an **array of 46 `char`**. - `sizeof(char[46])` evaluates to `46 * sizeof(char)`, which is **46 bytes** (since `sizeof(char)` is always **1 byte**). - So, in C, `sizeof(char[46])` is **valid** and returns 46 bytes. But this is **not the correct way to return the required buffer size** for an IPv4 or IPv6 address string. --- ### ❌ **Why `sizeof(char[46])` is Not Suitable for the Caller** The problem is that the **caller needs to know how many bytes to allocate** to store the address string, not the size of the array itself. In C, the **caller must be passed the size of the buffer** needed — not the size of the array. So, returning `sizeof(char[46])` is **not the correct approach**. --- ### ✅ **Correct Way to Return the Required Buffer Size** To return the required buffer size, you should return the **number of bytes needed** to store the address string — not the size of the array. Here’s the correct approach: ```c // For IPv4: 15 + 1 = 16 bytes (e.g., "127.0.0.1\0") // For IPv6: 39 + 1 = 40 bytes (e.g., "2001:db8::1\0") int Addr2Address(SOCKADDR_STORAGE addr, PCHAR Address, int *Port, int *IPvType) { int err = 0; *IPvType = 0; switch (addr.ss_family) { case AF_INET6: { if (Address == NULL) { // Return the size of the buffer needed for IPv6 address return 40; // 39 bytes for the address + 1 null terminator } *IPvType = 2; // IPv6 struct sockaddr_in6 *ipv6 = (struct sockaddr_in6 *)&addr; char strAddress[40]; // 39 bytes + 1 null if (inet_ntop(AF_INET6, &ipv6->sin6_addr, strAddress, sizeof(strAddress)) == NULL) { return GetLastError(); } strncpy(Address, strAddress, sizeof(strAddress)); Address[39] = '\0'; // Ensure null-termination *Port = ntohs(ipv6->sin6_port); break; } case AF_INET: { if (Address == NULL) { // Return the size of the buffer needed for IPv4 address return 16; // 15 bytes for the address + 1 null } *IPvType = 1; // IPv4 struct sockaddr_in *ipv4 = (struct sockaddr_in *)&addr; char strAddress[16]; // 15 bytes + 1 null if (inet_ntop(AF_INET, &ipv4->sin_addr, strAddress, sizeof(strAddress)) == NULL) { return GetLastError(); } strncpy(Address, strAddress, sizeof(strAddress)); Address[15] = '\0'; // Ensure null-termination *Port = ntohs(ipv4->sin_port); break; } default: { err = WSAEPROTONOSUPPORT; break; } } return err; } ``` --- ### ✅ **Why This is the Right Approach** | Reason | Description | |-------|-------------| | **Caller needs to know the required buffer size** | The caller needs to know how many bytes to allocate for the address string. | | **`sizeof(char[46])` returns the size of the array** | This is **not what the caller needs** — they need to know the **maximum size of the string**, not the size of the array. | | **Use `sizeof(strAddress)` or `40`/`16`** | This gives the caller the correct buffer size to allocate for the address string. | | **Ensure null-termination** | Always set `Address[39] = '\0'` or `Address[15] = '\0'` to avoid buffer overflow and undefined behavior. | --- ### ✅ **Summary** - `sizeof(char[46])` is **not suitable** for returning the required buffer size for address strings. - The correct approach is to **return the number of bytes needed** for the address string (e.g., 16 bytes for IPv4, 40 bytes for IPv6). - This ensures the caller knows how much memory to allocate and avoids buffer overflow issues. Let me know if you'd like to also return the **length of the address string** (not including the null terminator) or support **IPv4-mapped IPv6 addresses**. Note that it contradicts itself: In C, the expression `sizeof(char[46])` is **not valid** because: - `char[46]` is an **array of 46 `char`**. - `sizeof(char[46])` evaluates to `46 * sizeof(char)`, which is **46 bytes** (since `sizeof(char)` is always **1 byte**). - So, in C, `sizeof(char[46])` is **valid** and returns 46 bytes. and reintroduces the error codes. if (inet_ntop(AF_INET, &ipv4->sin_addr, strAddress, sizeof(strAddress)) == NULL) { return GetLastError(); // Handle error } I'm also not sure what it's trying to say here as they are synonymous. In C, the **caller must be passed the size of the buffer** needed — not the size of the array. It had the ball, the game, and the crowd — and still fumbled the touchdown.1 point
-
Yup. There is: MMAP (1.0.1).1 point
-
I've just spent an hour arguing with an LLM (Deepcoder). TL;DR A.I. is useless at programming. I had a bug. I'd spent about an hour trying to figure it out and not succeeding but it shouldn't be that hard-I'm just missing something obvious. So. Ideal scenario for a clever AI to show dominance and help out a poor old flesh-bag programmer, right? Just point out the mistake or mistakes and laugh at my stupidity like a real coder. The bug was that the address from recvfrom would be 0.0.0.0 instead of 127.0.0.1. The problem was either bind wasn't binding to a specific address (which it was supposed to) or the address translation was not working quite right. I gave it 3 functions where I thought the bug was and explained that IPv6 seemed to be reporting correctly but IPv4 was in error: one function (Listen) had the bind function one function had IPv6 and IPv4 address translation from a SOCKADDR_STORAGE structure to strings and the other function was the read function with the recvfrom. This is an abbreviation of the conversion: - Round one. The following code has a bug that returns 0.0.0.0 as the IPv4 address from "recvfrom" when it should be returning "127.0.0.1". Find the reason that the code is returning 0.0.0.0 instead of 127.0.0.1 and rewrite the code to fix the issue. It told me how to bind to a specific address and how to use the recvfrom function. It then basically wrote the example on the MS page for recvfrom but within the Listen function. - Round 2. I'm not using the "sockaddr_in" structures; I'm using SOCKADDR_STORAGE structures. Please modify your example to use SOCKADDR_STORAGE structures. It apologised made an excuse about misunderstanding and then proceeded to create an example, still using sockaddr_in structures, but this time hardcoding "127.0.0.1" in the bind address. - Round 3. No, no, no. It needs to support user entered IPv6 and IPv4 but there is a bug with the IPv4 address. It also needs to use SOCKADDR_STORAGE as in the code I supplied to you. Reevaluate the code and write a version of the code that fixes the bug. It apologised, said that it understands why it got it wrong, and then proceeded to create an example, still using sockaddr_in structures, but now hardcoding "::1" in the bind address. -Round 4. Look. It needs to support both IPv6 and IPv4 and that's the reason I'm using SOCKADDR_STORAGE. If you don't have enough information then ask for clarification but you have the code that the bug is in so find the damned bug FFS! Another apology, said it can understand my frustration and then proceeded to spit out the example from MS again. This went on for an hour. No code I could actually use in my functions, never pointed out the bug in my code and the prompts just got longer and longer as I tried to head-off it's stupidity. This was one of the functions. int Addr2Address(SOCKADDR_STORAGE addr, PCHAR Address, int *Port, int *IPvType) { int err = 0; *IPvType = 0; switch (addr.ss_family) { case AF_INET6: { if (Address == NULL) {return 46;} *IPvType = 2; char strAddress[46]; inet_ntop(addr.ss_family, (void*)&((sockaddr_in6 *)&addr)->sin6_addr, Address, sizeof(strAddress)); break; } case AF_INET: { if (Address == NULL) {return 16;} *IPvType = 1; char strAddress[16]; inet_ntop(addr.ss_family, (void*)&((sockaddr_in6 *)&addr)->sin6_addr, Address, sizeof(strAddress)); break; } default: {err = WSAEPROTONOSUPPORT; break;} } *Port = ntohs(((sockaddr_in6 *)&addr)->sin6_port); return err; } The bug is in the AF_INET case. inet_ntop(addr.ss_family, (void*)&((sockaddr_in6 *)&addr)->sin6_addr, Address, sizeof(strAddress)); It should not be an IPv6 address conversion, it should be an IPv4 conversion. That code results in a null for the address to inetop which is converted to 0.0.0.0. I found it after a good nights sleep and a fresh start.1 point
-
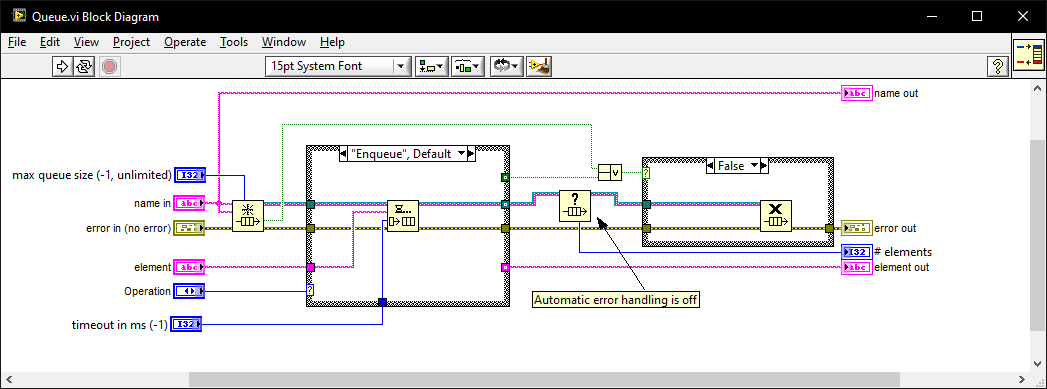
I once went for an interview where they gave me a coding test and asked me to modify it. It was a very long time ago so I don't remember the exact modification they wanted (nothing to do with memory leaks) but I do remember the obtain queue and read queue inside a while loop with the release queue outside. I asked if they wanted me to also fix the memory leak as well as the modifications and they were a little puzzled until I explained what you have just said. I must have seen (and fixed) this while-loop bug-pattern a thousand times since then in various code bases. I also created this VI which I generally use instead of the primitives as it intialises on first call, can be called from anywhere, and prevents most foot-shooting by rolling them all into a single VI and ensuring all references but 1 are closed after use. Queue.vi
 1 point
1 point -
There are several alternatives for the NI GPU Toolkit that are considerably more up to date and actually still maintained. https://www.ngene.co/gpu-toolkit-for-labview https://www.g2cpu.com/1 point
-
Sweet! That solves it. So, now we can write a LabVIEW console app! Here is the VI that let's you write to the StdOut of the calling console: Write to StdOut of Calling Parent.vi -John1 point