ShaunR
-
Posts
5,008 -
Joined
-
Days Won
312
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by ShaunR
-
It's been a long, long time but I did spend a week trying to get one to work so I'm emotionally scarred. Part 1 — P2P viability: With no stubs and both devices transformer-coupled internally, is the coupler genuinely redundant? Or are there signal integrity concerns I should be thinking about? The internal transformers are for isolation rather than impedance matching. They are required so you can have floating differential signals. If you are only transmitting over a couple of metres then you can get away with no external isolation. But you should really be using a dual-stub transformer bus coupler inline (or at one end) with terminators. Everyone starts point to point then adds devices! Part 2 — Cable spec: We're specifying a custom cable for this (DB9 female one side, HD-DSUB15 male the other — matching the AIM card's connector). What are the things that matter most in the spec — impedance tolerance, shielding, untwisted length inside the backshell, connector grounding? What's easy to get wrong? Suggestions (in order of importance) #1 You must terminate both ends. Each end should have a 78 ohm resistor across it. Impedance mismatch is the No.1 Killer. You don't seem to have mentioned termination resistors. #2 Check differential pair polarity (A and B lines) and that the correct terminals on the connector are soldered. It's been a while but I vaguely recall that the cable is a crossover cable if you are not using couplers so D1A connects to D2B etc. (I may be wrong on that) #3 Check your cable impedance. It should be 70–85 ohm at 1 MHz. #4 Make sure grounding is good (360 deg). You will get away with crappy grounding in the lab if the distance is very short, though. Aim for a max of 1-1.5 cm unshielded inside the connector shell. Use metal shells grounded to the chassis, if you can. #5 Put a scope on the lines looking at the waveform if you don't have an analyser. You are looking for rise/fall times of 100–300 ns, overshoot/ringing limits, etc (I don't remember them all-look at the spec).
-
I used to sell a product called the SQLite API For LabVIEW. It supported encryption. It's no longer available as SQLite removed the hooks and forced most people to use the SEE. SEE is a different source tree that they give you access to after you have paid for it. SQLCipher uses a modified source code tree and rewrites the SQLite source - they basically put the hooks back in again. Whichever way you choose, you will have to compile the binaries yourself and support them. You won't be able to just download the binaries from the SQLite website. It's been a while, and I haven't looked at the source recently, but I vaguely remember there were only a small number of API calls (maybe 2 or 3) that you needed to use
-
Available in the new ECL version 4.6.0

-
-
It will eat away at you slowly...at first. Then every time you see the link you will know [it doesn't work]. Drip, drip, drip. It's like those crossed wires on your diagram - you tell yourself it doesn't matter, that it's just cosmetic, that there is no change in function. But eventually you have to do something about it. Send that request to the admin, you know you want to
-
Your fastidiousness with code tells me this is an outright lie.
-
The link is broken for lazy people like me
-
Never used them or had a need for them.
-
They aren't banned. They are just very hard to debug when they don't work and have some unintuitive behaviours. I have Toolbar and Tab pages XControls that I use all the time and there is a markup string xcontrol here. If you are a real glutton for punishment you can play with xnodes too
-
 What's with the text centering? I have 2012 (and 2009) running on a Windows 11 machine. I think I had to turn off the App and Browser Control in the Windows Security.
What's with the text centering? I have 2012 (and 2009) running on a Windows 11 machine. I think I had to turn off the App and Browser Control in the Windows Security. -
Great song.
-
Triggers fall into two categories: software and hardware. Whether you use software or hardware depends on the trigger accuracy required-hardware being the most accurate. For your use-case I would highly recommend hardware triggering and I think those devices support two types: Digital IO and TSP-Link. Both are well documented in the manuals and I would further recommend digital IO as it is the simplest to configure. The way to do this is first to get it all working through the devices' front panels. Connect them up (including the digital IO, configure using the menu's then run a test. That will tell you what commands (and in what order) you need to configure for a successful test as SCPI commands map directly to menu's for most manufacturers. The advantage here is that if your software fails for whatever reason, you can still run tests with a precision digit (a.k.a finger). Once you are getting good results then it will be just the case of sending a single command to trigger the tests and the devices will do the rest. After they have finished you can then read all the data out.
-
The intent was to tell you the software was free (as in BSD licence) and, if had downloaded it, it contains a zlib binary that isn't wrapped.
-
I've never understood the "free (as in beer) or free (as in speech) internet vocabulary. Beer costs and speech has a cost. It's BSD3 and cost my time and effort so it definitely wasn't "free" Rolf's works on other platforms so you should definitely use that, but if you wanted to play around with functions that aren't exported in Rolf's, there is a zlib distribution with a vanilla zlib binary to play with while you wait for a new openg release.
-
Yes. Rolf like to wrap DLL's in his own DLL (a philosophy we disagree on). I use the vanilla zlib and minizip in Zlib Library for LabVIEW which has all the functions exposed.
-
With ZLib you just deflateInit, then call deflate over and over feeding in chunks and then call deflateEnd when you are finished. The size of the chunks you feed in is pretty much up to you. There is also a compress function (and the decompress) that does it all in one-shot that you could feed each frame to. If by fixed/dynamic you are referring to the Huffman table then there are certain "strategies" you can use (DEFAULT_STRATEGY, FILTERED, HUFFMAN_ONLY, RLE, FIXED). The FIXED uses a uses a predefined Huffman code table.
-
How to load a base64-encoded image in LabVIEW?
ShaunR replied to Harris Hu's topic in LabVIEW General
OP is using LV2019. Nice tool though. Shame they don't ship the C source for the DLL but they do have it on their github repository. -
How to load a base64-encoded image in LabVIEW?
ShaunR replied to Harris Hu's topic in LabVIEW General
Nope. It needs someone better than I. -
How to load a base64-encoded image in LabVIEW?
ShaunR replied to Harris Hu's topic in LabVIEW General
While we are waiting for Hooovah to give us a huffman decoder ... most of the rest seem to be here: Cosine Transform (DCT), sample quantization, and Huffman coding and here: LabVIEW Colour Lab -
How to load a base64-encoded image in LabVIEW?
ShaunR replied to Harris Hu's topic in LabVIEW General
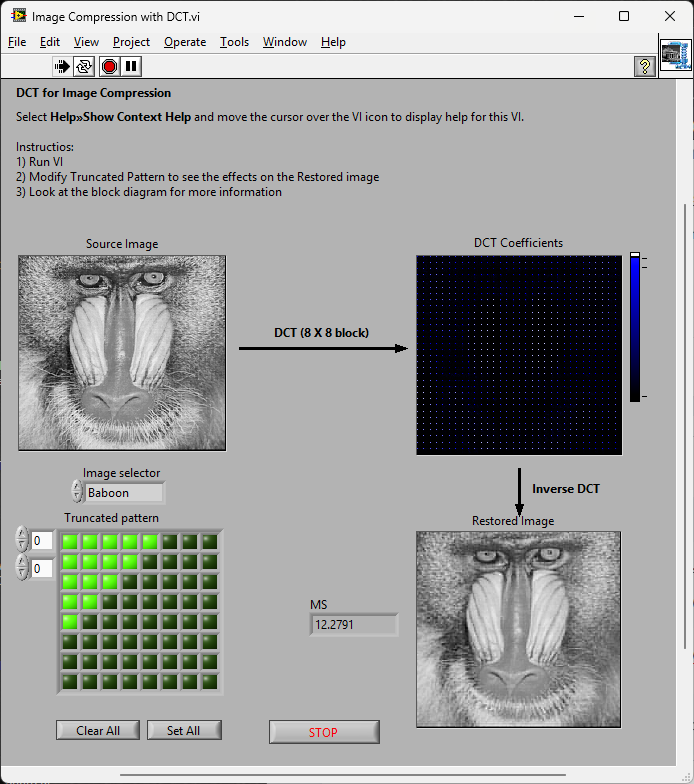
There is an example shipped with LabVIEW called "Image Compression with DCT". If one added the colour-space conversion, quantization and changed the order of encoding (entropy encoding) and Huffman RLE you'd have a JPG [En/De]coder. That'd work on all platforms Not volunteering; just saying
-
How to load a base64-encoded image in LabVIEW?
ShaunR replied to Harris Hu's topic in LabVIEW General
LabVIEW can only draw PNG from a binary string using the PNG Data to LV Image VI. (You'd need to base64 decode the string first) I think there are some hacky .NET solutions kicking around that should be able to do JPG if you are using Windows. -
It just didn't. Like I said. I only got the out of memory when I was trying to load large amounts of data. I suppose you could consider that a crash but there was never any instance of LabVIEW just disappearing like it does nowadays. I only saw the "insane object" two or three times in my whole Quality Engineering career and LabVIEW certainly didn't take down the Windows OS like some of the C programs did regularly. But I can understand you having different experiences. I've come to the conclusion, over the years, that my unorthodox workflows and refusal to be on the bleeding edge of technology, shield me from a lot of the issues people raise.
-
Gotta disagree here (surprise!) Take a look at the modern 20k VI monstrosities people are trying to maintain now so as to be in with the cool cats of POOP. I had a VI for every system device type and if they bought another DVM, I'd modify that exe to cater for it. It was perfect modularisation at the device level and modifying the device made no difference to any of the other exe's. Now THAT was encapsulation and the whole test system was about 100 VI's. They are called VI's because it stood for "Virtual Instruments" and that's exactly what they were and I would assemble a virtual test bench from them. Defintely 3). LabVIEW was the first ever programming language I learned when I was a quality engineer so as to automate environmental and specification testing. While I (Quality Engineering) was building up our test capabilities we would use the Design Engineering test harnesses to validate the specifications. I was tasked with replacing the Design Engineering white-box tests with our own black-box ones (the philosophy was to use dissimilar tools to the Design Engineers and validate code paths rather than functions, which their white-box testing didn't do). Ours were written in LabVIEW and theirs was written in C. I can tell you now that their test harnesses had more faults than the Pacific Ocean. I spent 80% of my time trying to get their software to work and another 10% getting them to work reliably over weekends. The last 10% was spent arguing with Engineering when I didn't get the same results as their specification That all changed when moving to LabVIEW. It was stable, reliable and predictable. I could knock up a prototype in a couple of hours on Friday and come back after the weekend and look at the results. By first break I could wander down to the design team and tell them it wasn't going on the production line . That prototype would then be refined, improved and added to the test suite. I forget the actual version I started with but it was on about 30 floppy disks (maybe 2.3 or around there). If you have seen desktop gadgets in Windows 7, 10 or 11 then imagine them but they were VI's. That was my desktop in the 1990's. DVM, Power Supply, and graphing desktop gadgets that ran continuously and I'd launch "tests" to sequence the device configurations and log the data. I will maintain my view that the software industry has not improved in decades and any and all perceived improvements are parasitic of hardware improvements. When I see what people were able to do in software with 1960's and 80's hardware; I feel humbled. When I see what they are able to do with software in the 2020's; I feel despair. I had a global called the "BFG" (Big F#*king Global). It was great. It was when I was going through my "Data Pool" philosophy period.
-
The thing I loved about the original LabVIEW was that it was not namespaced or partitioned. You could run an executable and share variables without having to use things like memory maps. I used to to have a toolbox of executables (DVM, Power Supplies, oscilloscopes, logging etc. ) and each test system was just launching the appropriate executable[s] at the appropriate times. It was like OOP composition for an entire test system but with executable modules. Additionally, crashes were unheard of. In the 1990's I think I had 1 insane object in 18 months and didn't know what a GPF fault was until I started looking at other languages. We could run out of memory if we weren't careful though (remember the Bulldozer?). Progress!
-
Tell that to Microsoft. Again. Tell that to Microsoft. I'm afraid the days of preaching from a higher moral ground on behalf of corporations is very much a historical artifact right now.