Leaderboard




Popular Content
Showing content with the highest reputation on 09/22/2009 in all areas
-
View File UI Tools UI Tools v1.4.0 Copyright © 2009-2016, François Normandin All rights reserved. Author:François Normandin Contact Info: Contact via PM on www.lavag.org LabVIEW Versions: Created and tested with LabVIEW 2012 Dependencies: OpenG Application Control Library >= 4.1.0.7 OpenG Array Library >= 4.1.1.14 OpenG File Library >= 4.0.1.22 OpenG LabVIEW Data Library >= 4.2.0.21 OpenG String Library >= 4.1.0.12 LAVA Palette >= 1.0.0.1 Description: This package contains tools for designing user interfaces. A first palette helps create special effects using transparency of front panel. Using them allows to quickly create fade-ins or outs using linear or exponential variation of the intensity. A second palette contains VIs to calculate the position of GObjects for many purposes like alignment, snap, mouse follow, etc. A third palette contains VIs to create dialog boxes based on class instances. "Simple Error Dialog" and "Simple Selection List" are featured with or without backrground blackening effect. A fourth palette includes some VIs to move objects programmatically on the front panel, using a basic deceleration algorithm to provide an impression of a smooth movement. The packaged VIs are all namespaced using a suffix “__lava_lib_ui_tools” which should not conflict with any of your own code. Includes: Front Panel Transparency (Fade In & Fade Out) Utilities (Alignment, Snap) Dialog (OOP based, extensible) Engine (Beta) for object movement Instructions: This package is distributed on the LabVIEW Tools Network (version 1.3) and updates are on LAVA (1.4). It can be installed directly in the addon folder of any LabVIEW version from 2012 to now. The addon installs automatically under the LAVA palette of the addon submenu. License: Distributed under the BSD license. Support: If you have any problems with this code or want to suggest features, please go to www.lavag.org and navigate to the discussion page. Submitter Francois Normandin Submitted 09/21/2009 Category LabVIEW Tools Network Certified LabVIEW Version
 1 point
1 point -
I found a problematic issue with the behavior of LVOOP class constant values. LVOOP constant values get cleared when the default default value of the class private data is changed to the same value as the constant value. Let's make some definitions: Class default value: The default value of class private data Default value class constant: LVOOP class constant, that has a specific default value flag. The constant behaves as by-reference object that refers to the class default value global. When the class default value is changed, the default value class constant is changed in synchrony. Non-default value class constant: LVOOP class constant with non-default value. The value behaves as any by-value object. It has its own value that does not depend ony the default value of the class, except in the problematic case described below. The LVOOP class constant can get a non-default value when you paste a previously copied value to it using Data operations -> Paste from shortcut menu. Class developer: An organization or developer that is responsible for developing and maintaining a class. Class user: An organization or developer that is using the class developed by some class developer. Consider National Instruments (class developer) has developed a class representing an IP connection to some IP address. Internally the class represents the IP connection with a IP address string constant in class private data. NI has initially set the "default value" of the class private data to be 0.0.0.0. Assume you (class user) as a non-NI developer have used a class constant of this connection class labeled loop back on block diagram and the value of it is non-default 127.0.0.1 representing a loop-back connection. Now NI decides they want to change the class default default value from 0.0.0.0 to 127.0.0.1. The issue here is that this change by NI will clear the value of your non-default value block diagram class constant and replace it by a default value class constant.Now NI decided that 127.0.0.1 is not a good default default value for the connection class and sets it to be 0.0.0.0 again. How this affects your program. Well, LabVIEW will not recover your initial value to your loop back class constant, i.e. 127.0.0.1, but instead keeps the default value. As a result, your loop back class constant no longer represents a loop back connection but a connection to non-existing IP-address 0.0.0.0. The behavior I expect would be that the value of loop back class constant on block diagram would always remain 127.0.0.1, even when the class private data default value is changed to the same value. You can replace the roles NI and you with you and your client. The issue here is, the constant values should never be cleared. If they really need to be cleared for some reason such as the class private data having changed structure, LabVIEW should definitely warn the developer that the constant values may no longer represent the data they used to. What happens here really is that when LabVIEW notices that a non-default class constant has the same value as the default value of the class, it replaces the constant value with a reference to the default value object. So the constant no longer is a constant representing its initial state but becomes a constant that stays in synchrony with the default value object. Once the default value object is changed, the constant value will also also changed. I think that LabVIEW should follow the principles below Theorem 1: A block diagram constant with a non-default value should always represent the same state that it initially had, irregardless of what changes has been made to the default value of the private data. Initially a red apple should always stay a red apple and not implicitly become a green apple even though the default color of apples is changed to green. This is what is currently happening in LabVIEW. Apple block diagram constants explicitly specified to be red apples are turning into green apple constants under certain changes of the default value of the class private data. Theorem 1 is broken by the fact that class constant state can change from red to green apples. Theorem 2: Initial and final revision of a class A,call them A1 and A3, are identical, but an intermediate state of class A, call it A2, is not identical to A1 and A3. Code compiled using class revisions A1 or A3 should execute identically irregardless if the code has been compiled against intermediate state A2. Theorem 2 is broken as you can revert the class to its initial state, still the changes in the class between initial and final state change the code using the class. Theorem 3: There should be no difference if code using a class has or has not been in memory when editing a class, if the class interface does not change.Once the code using a class is loaded in memory together with the latest revision of the class, the code should be updated always to the same state. Theorem 3 is broken as if code has been loaded in memory when a private data default has been changed twice, then the state of the code is different than the state of the code that has only been loaded into the memory when the class has reached its final state. So what I propose is that a class constant always has either a default value or a non-default value. The non-default value can equal to the class default value, but as far as the constant is concerned, the value is still called a non-default value. That is the value of a constant does not change from a by-value state to a by-reference state, unless explicitly changed by the class user. When the default value of the class private data is changed, the values of block diagram constant remain untouched. That is constants that already contain default value still contain the default value in the future. The constants that contain non-default value still contain a non-default value even if the new class default value equals to the constant non-default value. The important thing here is that the constant with non-default value has been explicitly set by the developer to be at some state and this state should be persistent no matter what (possibly another) developer does with the default value of the class private data. Once you paste data to a constant, it automatically gets a non-default status. The same would apply to indicators, once LabVIEW have written data to an indicator(control), the value of the indicator (control) would be non-default irregardless if the value actually equals to the class default value. Only when you want to clear the value back to the class default value, there could be a right click menu option Data Operations -> Reset to class default value. Let us take still another example of the current behavior. We are developing an natural number class. Initially we set the class default value represented by integer to be 0. We add a method +1 to the class and implement it by adding a class constant with non-default value 1 together with input data using another class method Add. We then accidentally change the default value of the class private data integer to 1. Accidentally! This clears the non-defaultness from out constant on +1 method block diagram. The constant gets the flag default value. Now we immediately notice out accidental mistake and correct the mistake by returning the default value of the class to0. Immediately. But the harm has already been done. The +1 method no longer functions as expected but now becomes +0 method instead. Is this really what we want? No warnings. Nothing. Just somewhere under the hood things implicitly change and we know nothing at all that we just broke our code. Everything that here applies to class constants applies to class controls and indicators, I think. I want to raise discussion. Should current behavior be changed in LabVIEW or do you think the present behavior of class constants is correct?1 point
-
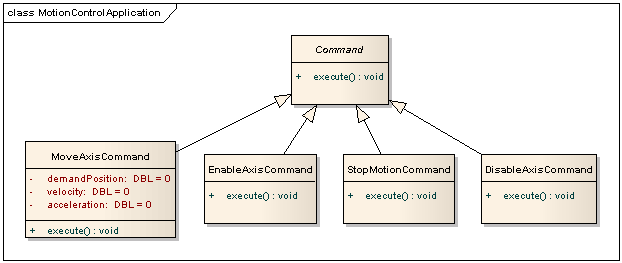
Well, first I will mention that for full details you will want to check out the classic GoF Design Patterns book and the more conversational Head First Design Patterns book for all the details and more insight than I could ever offer. Nonetheless, the heart of the Command Pattern involves making commands into objects. So, for instance, we might have the following. The top-level Command class is an abstract class. (Really, it would be an interface but the closest thing in LabVIEW currently is an abstract class. The important thing is that we never instantiate a Command object.) It has a single method, execute(). The actual commands are concrete classes that inherit from Command. Each concrete command class implements the execute() method. Note that a particular command can contain attributes (i.e., command parameters, or more abstractly, state). I don't show in the diagram the Client (e.g., a UI, but multiple Clients can invoke the same command, so that we could have a UI Client and a Command Line Client), a Receiver (a component that knows what to do with the commands; again the Receiver is decoupled from the Command classes so the framework can support different Receivers), and an Invoker (determines when--may be immediately--to call the Command::execute() method). Note that the Invoker calls Command::execute; dynamic dispatching determines which execute() method actually, um, well, executes. Notes: One can assemble commands into composite commands (with the Composite Pattern) to implement macros. (Essentially a MacroCommand executes a sequence of Commands.) One can combine the Command and Memento patterns to support undo. One can easily log Commands (and read back the log!) simply by writing and reading the objects (e.g., as flattened strings) in a file, all by thinking of them at the code-level as instances of Command. Most importantly, again, the Command pattern decouples the Invoker and the Receiver! An example from our experience: The Command Pattern is precisely a pattern so many variations are possible. In one of our subsystems we send Commands from a UI or external subsystem. The Invoker is really just a message passing system (we send objects flattened to strings over a CommandSharedVariable) combined with a an event structure that fires upon receipt of a message and calls Command::execute. The Receiver is simply the Controller and it knows what to do with each Command. (Note that in our case how the Receiver responds to a particular command depends on its current state, so it implements the State Pattern as well.)
1 point
-
This is probably occurring because you have two instances of MATLAB open: the one you are editing, and the one LabVIEW is using to communicate with MATLAB and run the .m file. Try this: 1) Start with all applications closed. 2) Open the VI that has the Matlab Script Node and run it. You should notice a MATLAB Command Window in your taskbar as well. 3) Instead of double clicking test.m to open it, or opening MATLAB yourself to edit it, switch to the MATLAB Command Window and type 'open test.m' and hit enter. You should get test.m up in an editor. 4) Edit test.m to say a=a+2 as you mentioned above and save it. 5) Run the VI again. Because you edited the .m file in the same instance that will execute it, MATLAB knows that it needs to recompile it before it runs it. Apparently MATLAB does some caching when it compiles scripts into runnable code, and multiple instances of MATLAB don't talk to each other about which cached versions have been invalidated and should be recompiled. Editing in the same instance that will be doing the execution should fix that for you. I hope that helps.1 point
-
Sorry, this kind of duplicates what Jim just said. I think that Jim would consider only implementing the lock-unlock on an as needed basis. I am not sure that all transactions can be generalized as atomic. The approach of the class as a DVR or always using a semaphore for data access clearly serializes access to the class which defeats the parallel nature. Sure this will protect the programmer from potential pitfalls of non-synchronized access, but it can also bottle neck other threads. 'Atomic' transactions are not just limited to intra-class operations. What about an accounting system where assets have to equal liabilities. Adding an asset then has to have a comparable increase in liability. If I were to implement an OO hierarchy on an accounting system, assets and liabilities would not be one class, but I would need to be able to 'freeze' access to the system while a transaction is completed. In those cases I would probably have some 'token' that I can grab from the accounting system and return when my transaction was done. I would implement the same approach for intra-class transactions. This could get pretty complicated as some transactions are independent (multiple transactions and on semaphore) and others are interleaved (one transaction multiple semaphores - if that is possible). Or I can make my life simple and have only one semaphore for the entire class - invoking as needed. If LV2009 supported some form of dynamic dispatch on a DVR, I do not think we would be having this discussion. It would probably be the opposite - how do I let other threads have asynchronous access to other (read only) methods in my DVR'd class hierarchy. I choose to go to the DVR'd data member route because the programming overhead (time and complexity) to implement a framework that uses class DVRs that supported dynamic dispatch was not appealing. And dynamic dispatch was more important to me than protecting myself from the complexities of multi-threaded programming.1 point
-
So you would always, when using DVRs, place a semaphore to the class on the top of the hierarchy and when ever accessing any data in the hierarchy you would lock the whole hierarchy using semaphore? Why you would not rely on the IPE structures when ensuring transaction atomicity? Sometimes we just need to place class methods inside the locking mechanism. If semaphores are used for locking and not IPE, then we can place class methods outside IPEs. Otherwise there are situations where we simply need to place the inside the structure.1 point
-
Here's a little jing video to show the FadeIn - FadeOut effects. Check out the example built with a JKI QSM to see how simply it's done. FadeIn FadeOut1 point
-
I am joining this discussion quite late but here is my 5c. LabVIEW is a parallel programming language. DVRs allow accessing shared data across parallel processes. Now the most important thing we need to pay attention to is to make sure that in no case, the data referenced by DVR is in a temporary state. That is state transitions of the DVR referenced data must always be atomic. There should never be an operation where operation leaves a DVR referenced state into an intermediate temporary state even for a fraction of a second. If the DVR referenced data can at any time be in an intermediate state, then there is always a possibility that a parallel process accesses the data at that moment and this results in the application malfunction that is close to impossible to debug. So how this relates to LVOOP by-ref design patterns? Well, it means that the lock for the DVR data across all the inheritance hierarchy must always be kept for the entire period of the whole atomic transaction being processed. Let's consider the consensus solution on this thread of adding a DVR into the private data of a class. Say class Parent private data contains DVR of some cluster data. Class Child inheriting from Parent contains another DVR of another cluster data. This is in accordance with Kurt's (SciWare's) examples. The problem with this scheme is that DVR's are accessed using in-place memory structure (IMS). In this scheme of holding DVR in classes private data, IMS does not allow us to lock both child DVR and parent DVR at the same moment. As a result we cannot guarantee atomicity of a transaction. Let's assume Parent has two data fields A and B with initial values a0 and b0. It is not possible for a child method to execute the following sequence as an atomic transaction: read field A of parent data by executing a parent data accessor method Read A, get value a0. do some data processing based on the parent data a0 read on step 1. modify parent private data field B by writing a value b1 using a data accessor method based on the result of processing of step 2. At the end of step 1, the parent data becomes unlocked again as the IMS locking the parent data is within the parent accessor method. As a result a parallel process can modify the parent data during step 2 destroying the atomicity of the process 1-3. Say a parallel process can modify parent field A during step 2 to be a1. The parent data is no longer in the state the child method assumes it to be. The final state of parent data would be (a1,b1) and not (a0,b1) as expected by the process 1-3. The state (a1,b1) may not at all be a valid state of the object. As a result of our implementation our object state have become invalid representing possibly something unreal. You can also have dead-locks with the concensus implementation. Assume a parent method locks parent data, then calls calls a dynamic dispatch method of the parent class that has been overridden by the child class and finally writes data back to DVR unlocking the data. Now the parent method is already locked at this point. The child override method may then try to relock parent by calling parent accessor method. However parent is already locked and dead-lock occurs. Dead-lock can occur even if child method doesn't call parent method. A parallel process may be trying to lock first the child and then the parent data in inverse order. As the order of the locking is inverse from the order of the locking of the first process, we may end up in a situation where one process has locked parent and is waiting for access to child data and another process has locked the child and is waiting an access to the parent data. Dead-lock. So I would not recommend embedding DVR's to classes private data. Instead I would make all atomic methods to contain DVR's to the class on the input and output terminals, lock the entire hierarchy by a single IMS and do all internal processing using by-value wires. You get the performance of by-value classes. You get the benefits of LV natural parallelism within the class methods. And you can always guarantee transactionality of the DVR referenced state. Conceptually one can consider DVR referenced states as functional globals with a reference to particular subVI clone instance holding the shift register with some state. As we functional globals, we do not want parallel processes to be able to modify the state at the same time. With DVRs only one transaction VI may be modifying the DVR state at any moment of time. With functional globals only one case of the functional global may be executing at any single moment of time. So when using DVRs, make sure you always modify the DVRs transactionally a singe VI at a time. You need to lock the entire data hierarchy in a single transaction to guarantee this behavior. Well, at least immutable variables could be used as well, where the variable is never written. For example a file class could contain a path field in addition to file reference. A path field for the file path remains the same until the file is closed, so it would not cause even if it is not a reference. And accessing file path would not require locking any DVRs.1 point
-
You can check out the code here. I have also attached some code to calculate the XMODEM CRCs as well as the normal CRC-16.I have also attached the XMODEM-VISA.llb that I used. I am pretty sure this is the same llb referred to in the link I posted but if I recall I added the support for 1K transfers. Calculate CRC-16 (File input).vi Calculate CRC-16.vi Calculate XMODEM CRC-16 (Buffer input).vi Calculate XMODEM CRC-16 (File input).vi Get CRC-16 Table.vi Calculate CRC-16 (Buffer input).vi Xmodem VISA.llb1 point