Leaderboard




Popular Content
Showing content with the highest reputation on 08/19/2011 in all areas
-
I just went though this for my business. I am based in the USA, and I am a small LabVIEW consultant. There are 3 types of insurance you generally need for a business. General Liability, Workman's Compensation and Professional Liability (aka Errors and Omissions). General Liability protects you if someone on your premises falls and wants to sue you. Mine has an additional rider called Baily's insurance. This covers equipment not owned by you. If you drop it, and break it, your Baily's will cover it. This is not expensive insurance and is great value for the money. There is also some product and data loss protection in my general liability policy. Workmans Compensation is if you get you hand chopped off at your customers site or someone working for you. It will pay for your (and employee) medical costs, and protect you from some liability. This is generally what customers want to see you have. Having this insurance protects the customer from getting sued by you if there is an accident (that is why they want to see it). This insurance is based on your payroll. It is not that expensive because computer programmers are at a low risk to get injured. (I got into the accountants category). In the US Workman's Compensation is by state. Michigan workman's comp laws are different than Ohio. If you have employees you MUST have workman's comp Professional Liability (aka Errors and omissions) protects you if you mess up and somebody wants to sue you. The thing you really want is the insurance company to pay for the lawyer. Legal fees will KILL you. I am more concerned about the cost of litigation than the amount somebody would potentially sue me for. Professional Liability insurance is expensive, and most folks in the insurance industry don't understand what we do. I went through IEEE. They spent the time to find an insurance company and explain the risks of our job. That means better and cheaper coverage for us. IMHO it is very rare to get sued. The costs of litigation for both sides usually causes cooler heads to prevail. However it only takes 1 a**hole... Reason does not exist in a legal situation. The judges, jurys, and lawyers have no clue on technical matters, and don't care. You could be totally in the right and be liable. Having a big bad insurance company with an army of lawyers on staff who don't want to pay claims is what you are paying for. Using a building contractor analogy, having LabVIEW certification and insurance you are now "licensed and insured". IMHO this is a very marketable thing.1 point
-
If a page linking these should be created then I suggest one be created on labviewwiki.org.1 point
-
We use CSV files a ton (too much) here too, but be warned: CSVs don't like Europe (or Europe doesn't like CSVs) - any country that uses commas as a decimal separator can't use commas as a column separator. After being bitten by this years ago all my text logging code allows for a re-configurable separator and file extension. Jaegen1 point
-
I know NI's answer to #2. My answer would have been a CSV file. It's readable by anything, Excel included. And has the benefit that the character that is separating your data is obvious in any text reader. But that's just me... While we love to help here, we get a fair share of posts from people who don't want to learn, but just want us to do their school project for them. Sorry if I misunderstood your intent.1 point
-
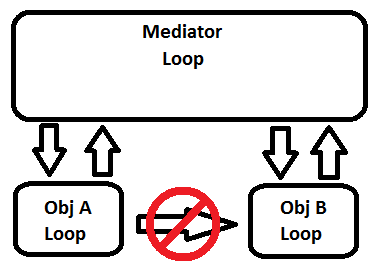
Preface: I'm assuming there are unstated reasons obj A and obj B must run in separate loops. This implementation pattern is overkill if the A and B need not be asynchronous. Publish-subscribe is one solution to that problem. PS establishes the communication link between the two components at runtime. That is useful primarily when the communication links between components are not well-defined at edit time. For example, a plug-in framework where the number of installed plugins and the messages each plug-in is interested will vary is a good candidate for PS. Usually I don't need that level of flexibility, so using PS just adds complexity without a tangible benefit. To keep A and B decoupled from each other I combine them together in a higher level abstraction. What you are calling a "message clearing house" I call a "mediator loop" because it was inspired by the Mediator Pattern from GoF. The mediator receives messages from A and B and, based on the logic I've built into the mediator loop, forwards the message appropriately. A couple things to point out in the diagram above: 1. Each mediator loop is the "master loop" for one or more "slave loops" (which I've mentioned elsewhere.) "Master" and "slave" are roles the loops play, not attributes of the loop. In other words, the Obj A loop may actually be another mediator loop acting as master for several slaves, and the Mediator Loop on the diagram may be a slave to another higher level master. 2. The arrows illustrate message flow between loops, not static dependencies between components (classes, libraries, etc.) Instances of slave components only communicate with their master, but in my implementations they are not statically dependent on the component that contains the master. However, the master component is often statically dependent on the slave. (You may notice having master components depend on slave components violates the Dependency Inversion Principle. I'm usually okay with this design decision because a) I want to make the application's structure as familiar to non-LVOOP programmers as possible to lower the barrier to entry, and b) if I need to it is fairly straightforward to insert an inversion layer between a master and a slave.) In practice my applications have ending up with a hierarchical tree of master/slave loops, like this: The top loop exposes the application's core functionality to the UI loops (not shown) via the set of public messages it responds to. Each loop exposes messages appropriate for the level of abstraction it encapsulates. While a low level loop might expose a "LoadLimitFileFromDisk" message, a high level loop might just expose a "StartTest" message with the logic of actually starting a test contained within a mediator loop somewhere between the two. Slave loops--which all loops are except for the topmost master ("high master?") loop in each app--have two fundamental requirements: 1. They must exit and clean up when instructed to do so by their master. That includes shutting down their own slave loops. 2. They must report to their master when they exit for any reason. These two requirements make it pretty straightforward to do controlled exits and have eliminated most of the uncertainty I used to have with parallelism. A while back I had an app that in certain situations was exiting before all the data was saved to disk. To fix it I went to the lowest mediator loop that had the in-memory data and data persistence functionality as slaves and changed the message handling code slightly so the in-memory slave wasn't instructed to exit until after the mediator received an "Exited" message from the persistence slave. The change was very simple and very localized. There was little risk in accidentally breaking existing behavior and the change didn't require crossing architectural boundaries the way references tend to. Final Notes: -Strictly speaking, I don't think my mediator loops are correctly named. As I understand it a Mediator's sole responsibility is to direct messages to the appropriate recipient. Sometimes my mediators will keep track of a slave's state (based on messages from the slave) and filter messages instead of passing them along blindly. -Not all masters are mediators. I might have a state machine loop ("real" SM, not QSM) that uses a continuously running parallel timer loop to trigger regular events. The state machine loop is not a mediator, but it is the timer loop's master and is responsible for shutting it down. -The loop control hierarchy represents how control (and low speed data) messages propogate through the system. For high-speed data acquisition the node-hopping nature of this architecture probably will not work well. To solve that problem I create a data "pipe" at runtime to run data directly from the producer to the consumer, bypassing the control hierarchy. The pipe refnum (I use queues) is sent to the producer and consumer as part of the messages instructing them to start doing their thing. Final Final Note: In general terms, though not necessarily in software engineering terms, a mediator could be anything that intercepts messages and translates them for the intended recipient. Using that definition, any kind of abtraction is a mediator. An instrument driver mediates messages between your code and the instrument. Your code mediates messages between the user and the system. I don't know where this line of thought will lead me, but it's related to the vague discomfort I have over calling it a "mediator loop."
 1 point
1 point