

jgcode
-
Posts
2,397 -
Joined
-
Last visited
-
Days Won
66
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by jgcode
-
-
I think I remember some discussion about that. Did you ever make it public? I didn't see it in the CR, though there is another entry that appears to do something similar.
Nah, I didn't. I was playing with this last year, and haven't gone back to it due to the fact I have been working mostly in 7.x since the start of this year

(I could be wrong - this is off the top of my head) I have seen the other one in LAVA (by Gavin B I think?) and it was good, I think it could create menu hierarchies (child, parent etc...) but it was static.
I was trying a dynamic approach - i.e. you are coding, you add a data-member, smash the quick drop shortcut and voila! The palette would update with the new VI.
One of the problems I encountered was that the .mnu file would get corrupt once in a blue moon for some reason. I tried to fix it (in my code notes it says I did a workaround). If it still happens I could get around this possibly by deleting then recreating the menu file each time, but I was trying to optimise it.
It just uses a bit of scripting and the MNU API.
I was planning on posting it to LAVA though (one day
 ) so it was in a good state - I just added the readme file today and reran the build script.
) so it was in a good state - I just added the readme file today and reran the build script.When you load the examples make sure they are not read-only. (This is in the readme)
If you (or anyone) could let me know what you think that would be great!
library_palette_manager-1.0.1-1_LV2009.zip
On the flip site, I do find it easier to navigate using the project/library/class layouts because I categorise the layout the way I want with virtual folders. You could mimic this with palettes but it may be a bit of work. Having to look at all VIs in a palette can be a bit harder!
-
and this
are in conflict. You can't reserve all rights of copy and BSD license them simultaneously. I believe the correct notation is
Can someone please clarify this (so I know what to right too!)?
Here is the license template:Copyright © <YEAR>, <OWNER>
All rights reserved.
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
-
Do you remember back in the days (up to LabVIEW 6i) what we had to code before we had the event structure?
You have to go old school using LabVIEW Real Time as well e.g. for a Remote Panel interface.
-
When working on a project I use the project explorer window to drag and drop vis onto the bd I'm working on. If the project is large it can take a lot of scrolling and clicking to get to the VI I need. Has anyone ever implemented a project-specific palette?
Yep, I use the project in the same way and I run into the same problem.
I use the OpenG tool - Locate In Project a lot.
Normally it's for locating a class in the project i.e. if I have a method VI on the BD and I want to get to another method in that class quickly.
I did a Quick Drop tool for auto creating class palettes, that was handy because the palette shows up e.g. if you right click a method on the BD.
But I have not down a project specific one.
-
Ahh... sacred cows make the best hamburgers.
Its time to start hunting...
-
Cons? Well, since I haven't ever had to go back and do anything with the exes or installers from previous builds (other than point people to their location) I haven't run across any cons. What advantage do you get by including the build output as part of the project?
Well when I started here, that what was done.
Aside from the fact everything is together I can't think of any.
Hence, my reason to question... is it 'bad practice' / is there a better way?
-
I think it's too early and my brain isn't fully switched on--this question isn't compiling.
Funny!

Sorry I mean: I (currently) like having the archive (of builds) under the project folder along with the source code, documents etc. Your method is different, but I was asking if there are any cons of having it separated? But you went into more detail below.
All our software is for internal customers and used to support product development efforts. Our requirements are very different than those of a professional Labview contracting shop, especially when it comes to documentation. Our scc directory structure is typically something like this...
<project>\trunk\source - application code
<project>\trunk\documents - documents another developer might need, such as instrument manuals, design documents, etc.
<project>\trunk\resources - stuff that is related to the project but is not Labview code. I'll put ogb and ogpb files here, as well as icons, config files, report templates, etc. We're looking to get a professional installer creation tool and those files will go here too.
We don't store customer-facing documents or project management stuff in source control. We use a Sharepoint server for that. Each project gets its own page on our release server where we post the installer as well as any installation instructions, required 3rd party applications, and user manuals.
Ok, looks like your layout is similar, and we do, do System Integration (you pointed out that you don't).
I keep the stuff you mention with the application code. Essentially anything that is required to create the installer (which is usually the final product). Because usually the (NI) installer needs to point to config files, icons etc... (sometimes user manuals if they are installed). Everything thing else sits a layer up and is project management stuff.
This is unless a project (or release) is under our internal library - then the final product is a package (.ogp/.vip) and there is no project management.
I don't put my .exe in SCC. I do however tag the code that was used to build the exe. This way I can easily look at the state of the code that corresponds to that built exe version.
Me too. But I like to keep an archive of releases so I can get to them easily/quickly (or maybe I am lazy)
Its great hearing what others do. Keep it up!
-
I exclude the exe's from my repository, but I consider it a valid practice to do so. (disc space is cheaper than the time lost just in case I had to get that old exe!).
All the documents go into SCC. External documents won't get changed, so that isn't important to have them under SCC. But design documents (they might not only relate to code but also to electronics, mechanics), roadmaps, user manuals, screenshots are all subject to change, hence they should be SCC'ed.
Felix
Hi Felix
How do you structure your folder hierarchy for your SCC'd documents in relation to your code?
And where to your external documents sit as well?
-
I don't, but I wouldn't call it "bad practice." I think there are valid reasons why one would check in built code in a distributable format, be it exes, installers, or packages.
I do make sure to check in any files associated with building a project. Specifically, OGB and OGPB files are included in my project and checked in to source control. We also have our distributable code hosted on an internal web site with a 14 day backup, so we don't have to rebuild them if somebody needs to reinstall it.
Cool, so you got no worries separating the archive from the code? I thought it would be nice to keep it all together in the one place per project. But the reason I ask about 'bad practice' is I can see some problems with it and was wondering if they is a better way!
What I am looking at is to try clean out the code project line so it is just code and code documentation. So I could branch a whole project, and it would make sense. Because obviously I don't want to branch exes etc... (they are there to get backed-up and retrieve if needed) and I don't want to branch my project stuff (knowledge base, timesheets, project management files etc...)... but I like having revisions of it and (at the moment) I like it being with the project.
So at the moment my folders for a project are like this:
<Repository>\<Client>\<Project> - <main-dev> this is my code line
<Repository>\<Client>\<Project> - <rev1.0> if I need to branch
<Repository>\<Client>\<Project> - <project management>
<Repository>\<Client>\<Project> - <knowledge base>
<Repository>\<Client>\<Project> - <archive> deliverables (e.g. exe's)
etc...
...So my next question is how to people manage their documents?
Do you use the same SCM provider as that as your code?
How do you store it (folder structure) etc... relative to your code
I am not looking for examples on how a repositry is managed (by versions vs by project etc..) but more on what do you do with non-code files (documents etc...)
-
Thanks, I also did that. Am I correct in assuming this only works if you have DSC Module installed?
Miha
Yes, the DSC allows programmatic access to shared variables, creating SV etc...
LabVIEW 2009 has a Shared Variable API but it is no where near as powerful as the DSC nor can it do what you are asking.
-
To add to DJed's post:
In the particular example posted, you don't need the Merge Errors.vi at all because there's no reason to merge a guaranteed "no error" with the other error stream.
Or, to phrase it another way: BOTH "ERROR OUT" TERMINALS RETURN THE SAME VALUE. So you never have to merge these two error streams. Automatic error handling is satisfied if you wire either one of these two error terminals.
Cool - I did not know that.
If we only have to merge once - should we choose the In or the Out (is there any benefit of one over the other)?
And what about the case with multiple DVRs on a single IPE?
-
Shared reentrancy is a different beast. Only one clone is in memory. If two subVI calls to that clone try to happen at the same time, a second clone is allocated. Once allocated, that clone stays allocated (I think as long as the VI stays in memory without being edited, but it might only be as long as the VI stays running... I'm not sure which). What this means is that you take a performance hit when that second clone gets allocated, but thereafter you get most of the benefits of parallel execution. There's slight thread friction each time the caller VI accesses the clone pool at the start of the subVI call, but that's minimal compared to the friction of being entirely serialized. Shared reentrancy appears in empiric tests to be a good compromise.
Yes that is interesting!
I have been talking about using Shared Reentrancy for my classes.
What bothers we know is that my reuse library is in 8.2 so the only option is Preallocated Reentrancy (which I use).
Would a better choice be None?
Therefore some uses cases for Preallocated Reentrancy would be:
- Where state must be maintained for each instance
- When non-blocking calls are required and we require better determinism - e.g. on a RTOS Shared Reentrancy could increase jitter.
Are there anymore?
- Where state must be maintained for each instance
-
Do you other people archive their exes/packages in their SCM?
I have read this can be deemed bad practice - you should only check in non-generated files.
-
I'm about to move to a new SCC system and want to do it right from the start, one of the things I am always a bit fuzzy about is which files to ignore when using SCC.
I have the opinion that compiled code should not be inside an SCC, so I think about ignoring the following files:
- built*\
- *.ogp
Apart from that I think the followin LabVIEW specific files should be ignored:
- *.lvlps
- *.aliases
Any other opinions/ideas?
Ton
I am of the same school of thought as you, for my applications I do not include my dist (build) folder into SCC.
However, I do have a zip (archive) folder where I will store deliverables that are milestones (released to the client). Usually this is a zip file containing files for a CD installable.
For my reusable code I also do not include the dist folder, but I will checkin my .ogp and .vip packages in my zip folder if they are releases (not for internal testing).
As for the project, I too, do not bother with the .lvlps and .aliases files as they seem to get regenerated on .lvproj launch just fine.
I also do not include any test files that get generated during (manual) testing, although I am conscious that removing these from under my SCC tree would make it a little cleaner.
- built*\
-
Well, even though there's no error for the input, I still merge because if I recall there are some legacy VIs can issue a warning...error is false but a code exists. Hence I think it's always important to propagate a no error condition (or am I imagining things?).
Great point, but for me I don't normally have a system in place for trapping, reporting and logging warnings though, only errors.
So I guess after more careful consideration, I think the nodes are designed exactly the way they have to be designed.
Yes, there are designed correctly, IMO that same design should be used when a DVR is connected to a class method, but (the merging etc) should all take place behind the scenes. This is a specific use case, but that has come up frequently for me.
-
I don't know what happened but I cannot find anything anymore.
Even a simple search on 'ton' (which should trigger approximatly 1000 posts), or 'git', 'rss' return anything.
EDIT: it seems the minimum search length is 4, could that be fixed
Ton
I prefer to use Google, for NI's site as well.
-
I'm trying to recreate Factory pattern provided by NI (Aristos Queue if I'm not mistken), but I've tried everything and I cannot create a Strictly typed VI Rev to a lvclass. Can someone please explain to me how to do that? I'm using LV 2009.
Thanks in advance, Mike
Hi Mike
You can also just browse to a path on a VI Refnum constant to get want you want.
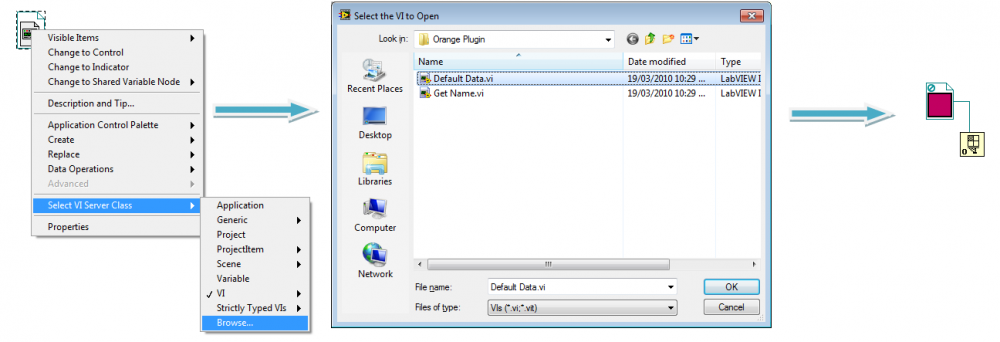
-
Your question is, I think, a variation of the tradeoff between writing bigger, more complex code that can be used in many different situations and writing smaller, simple code with more limited applicability. (The difference being that this decision adds to debugging complexity rather than code complexity.)
Well no, not really, (for the first part) and yes (for the second part)
I just want to know if I should set re-entrancy on my class methods.
The reason being I believe it will effect debugging by the developer (not functionality).
Its just that if you (can) write a resuable function, document it well, have a good interface to it (descriptive controls labels etc..), chances are the user does not have to go into the VI to work out what it does (or that would be the point).
However, with classes, I am sure you may want to get in there and have a looksy because it is more complex than a single function.
And being re-entrant can make that process a little harder (although it can sure sharpen up your debugging techniques).
My take-away is I can't write code that is going to fit all future use cases, so I don't bother trying. I write code that meets my immediate needs with some wiggle room for predictable and likely future needs. When I run across a use case that violates the assumptions I based my reuse module on, it's time to write new code. (Could be app-specific code to deal with the special case, a new version of the reuse module, or a completely new reuse module.)
I like your style! Right now I am looking to release code that e.g. serves as a base each thing I do all the time for my apps. So my use cases are well defined for extending the class.
The other thing I do is password protect these distributions on release which serves to hide the private methods (in any library) and no one can accidentally edit those classes.
This posses the same problems as the re-entrancy by decreasing the ease of debugging , (if you don't know the password) you can't see block diagram.
Does anyone do this? and how do they find it?
-
Not unless they need it as part of their functionality or if I would have reason to suspect their performance would be improved by it. As far as I can tell, this is also NI's policy with vi.lib (you'll note that most VIs there are not reentrant).
Thats interesting I thought NI would recommend re-entrancy and use it too!

I thought if I was calling a lot of functions in parallel (i.e from reuse library (vi.lib, OpenG, my library) it would be good to use re-entrancy?
Interesting!
-
I'm just finally getting enough time on my hands that I can explore DVRs. I think I'm missing something with respect to error handling and I'm hoping someone can enlighten me. See below:
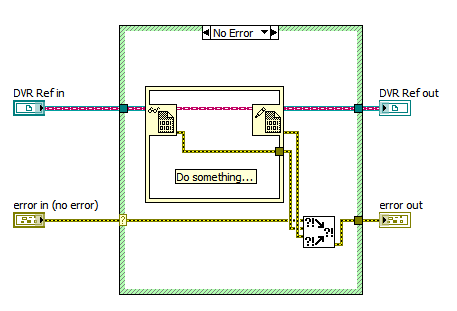
My first thought when I tried wiring this up was of the whiskey tango foxtrot variety, and well...it still is.
The process of taking in a DVR, checking for an error, deserializing contained value, operating, then reversing the process is inherently...serial. Why is the error handling so discontinuous? Why doesn't anything have error in terminals which forces me to bundle 3 values together each time I need to operate on the DVR? This seems unnecessarily messy and inelegant. Am I missing something?
Well technically you don't have to merge the error in wire as you have the case structure catching any errors... but I know what you mean.
I would like a single class method to accept DVRs.
That way I would only have to create one method for ByVal that I can use ByRef
If I wanted to string together a bunch of methods inplace then I would use the IPE and suffer the wrath of size on the BD and the error handing
Right now I have create another VI just if I want to read one method and it is a PITA.
I understand about the consequences, and I want the option.
Please vote here to get this one through into 2010!
-
You should note that reentrancy does not necessarily mean improved performance. When you have reentrant VIs, there needs to be memory allocation and book keeping for each instance, something which will have a greater impact the more reentrant VIs you have (although I don't know how pronounced this effect is).
....Obviously, you also won't gain performance if your non-reentrant VIs aren't actually blocking.
Thanks Yair.
Yes, it will be dependent on the application.
I do not (currently
) have performance issues that I am looking to solve.But I am trying to find out what other people do/how other people distribute their reusable LVOOP classes!!
This is supposed to be mitigated if you use the shared pool for clones option available in 8.5 and later (since only N instances are allocated for each reentrant VI).
FWIW, referring back to my original post (RE: DD methods), a dynamic dispatch VI cannot preallocate a clone for each instance, so it must be set to shared re-entrancy only.
Given you post, do you not use reentrancy for you reusable VIs?
Cheers
JG
-
The Dynamic Load Example in the Example Finder works exactly like I want with the exception that I want to be able to open either ideally a vi from within an lvlib (which it seems I can't do) or call an exe. I've found one way of opening the exe using .net constructors and an invoke node which has the feeling of being the hard way of doing things & therefore probably wrong.
Hi Martin - below are a few notes on dynamic process' and building executable that may be of interest.
One easy way to launch a dynamic process (whether it is a daemon or a GUI) is to have a launcher VI in the library that has a static reference to the process.
This will mean that the process is always included in the build.
Otherwise you must specific it under include dynamic VIs as part of the build spec for the executable (or it won't be included).
The other reason for doing this is that finding the VI is easy, you do not need to specify a path, as you already have a reference.
This is handy as in 2009 the way an executable's internal structure is composed is not like an llb (although there is an option to do that).
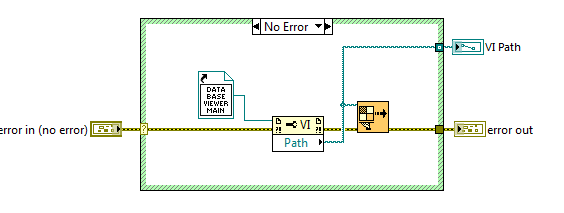
In the above png I don't have to worry about specifying a path, it is all taken care of by the static ref (the subVI just call the VI Run Method using the path as an input)
Additionally the front panel of a VI will get stripped in a build unless otherwise specified.
If your process is only a daemon (no Front Panel) this is ok, if it is a GUI then it is a problem.
One way to deal with this is to include a property node to a Front Panel control (even if it does nothing), that should guarantee FP inclusion in the build.
Additionally I am a big fan of the subpanel design where appropriate.
It does depend on screen-to-screen interactions.
Do no subpanel screens need to be opened at the same time (i.e. only one can be seen at any one time)?
Do all screens have common run-time-menu and/or tool bar options?
If yes then IMHO it can be a good candidate for a subpanel design.
All main screens are contained in the one top level screen - so I find this to be neat.
More work though, but it depends on the application.
-
If it works for VIs generally, then you should keep the same policy for methods of the class. Classes are just a system for organizing the VIs you'd write anyway. And being reentrant does mean all overrides have to be reentrant, but that shouldn't be a problem. For one thing, method overrides are generally adjustments to the parent's behavior, so if the parent didn't need synchronization, neither will the override. And if it really needs synchronization, the override can call a subVI.
Thanks for your reply AQ.
As always I like to know what others are doing to make sure I am on the right track.
I will keep as is, and stick with reentrancy.
-
When developers release their reusable LVOOP libraries, do they make all their method VIs reentrant?
My other reusable code (functions etc... ) are reentrant unless for a specific reason. But when I create applications that use classes, on a whole, I don't normally have to make those classes' methods reentrant, and I don't feel I have any performance penalties (on a PC target) because of this decision. And these reusable classes are usually a replacement for those classes.
One of the quirks of LVOOP is that the dynamic dispatch code must have the same reentrancy level throughout the hierarchy. So the developer who is extending the class is forced to use reentrancy on those overriding methods in their application code.
I am trying to weigh up the need for performance versus ease of debugging (as it might not be just me who is using them). I know you can probes wires outside of the class normally, debug clones with breakpoints, and unit tests should be used to validate code etc... so is this really a big issue?
Anyone got anyone thoughts on this?
Cheers
JG

shift register in sequence structure
in Development Environment (IDE)
Posted
I am sure this has been debated many a time, here is one link to another discussion