

Mark Smith
-
Posts
330 -
Joined
-
Last visited
-
Days Won
5
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Mark Smith
-
-
I don't have a particular microphone to recommend, but if you can attach the microphone to the UUT (with a simple clip or strap or such) then a simple contact mic would work well. You won't have to worry about ambient noise and the vibration, in particular, will be easier to detect if most of the energy from the signal couples directly into the transducer. Also, you can save yourself a lot of headaches by getting a simple commercial mic preamp to condition the mic signal and convert it to audio line level before you send it to the DAQ. I would think you get everything you need for <$150 - maybe a lot less.
Mark
-
Just use the "Shoot Yourself" Assistant - until you get an "insane object" error
-
I'm with you - that's been my entry point and I don't see it anymore either
Mark
-
Thanks for the replies. I decided to go with the division in the consumer loop idea as it seemed the simplest. Having 2 copies of the same queue does not seem very efficient at all.
I don't think the publisher-subscriber link was complete - could you try posting again? Thanks. Id like to look that solution over since I have used it in C#.
One more question: I am trying to use an event structure (in the producer loop) to initialize my output file (set up the header, etc). I then pass the file refnum from the producer to the consumer loop, however since the producer while loop is still running, the refnum gets passed to the producer while loop loop tunnel but goes no further. This causes the consumer loop to NEVER run, I assume since it is missing an input. I have attached my latest code.
Any suggestions? Thanks in advance!
You are correct - the second loop can't start until the first finishes because there's a direct dataflow dependency between an output of the first loop and an input of the second - so, you need to rethink the program flow. Since all of the data saving is handled by the consumer, the file initialization is probably best handled there as well. And since the consumer loop determines whether or not there's data to save, it could create the file when the log data button is operated and then use an uninitialized shift register to handle the file ref between calls. This is a functional global variable (FGV) in LabVIEW terms. See the GasManifold2.vi in the attachment
Mark
-
Hello,
I have an application where I am collecting some data with a DAQ card, doing some simple processing, plotting or otherwise displaying a few parameters (some raw, some calculated) at one frequency and logging a few parameters to a file at another, slower frequency. At first I thought it would be best to use one producer loop and two consumer loops, however once one of the consumer loops de-queues an element it would not be available for the other loop. I ended up dividing the loop counter by the multiple of the two frequencies and feeding the remainder to a =0? block and into a case statement - sorry this is hard to explain in words, please see attached block diagram. Is this the best way to do this?
Also, I have used LabVIEW off and on for years but am by no means an expert so any comments on style/functionality etc of my app would be appreciated.
Thanks in advance for your help and suggestions.
User events can be a good solution to the single producer - multiple consumer pattern. The producer fires the user event with the data that you're now putting on the queue and every consumer that has registered for that event and is listening for it will get the same data. You can have anywhere from 1 to n listeners (I don't really know what the upper bound is but it is bound to be large enough). The caveat is that if you have a queue, you're guaranteed a lossless data transfer - if the queue listener is busy, the producer can just add data to the queue or block until space is available and the consumer will always have access to the data until the queue is destroyed. If a producer fires an event and no one is listening, the data just goes to the bit bucket, as far as I know. So, if you use events and you want data integrity make sure your consumer is faster than your producer. You could also use the event time stamps to tell if you missed a data message.
Other wise, I think two queues as suggested would work.
Also, I can't access the code from this machine but I also think your approach as I understand it is valid as well, where you dispatch the queue data after you dequeue it to the correct case for that loop iteration since you don't really need asynchronous processing.
Mark
-
Actually, that's how you implement GPIB (HP-IB) using HP-BASIC. The messages are SCPI. the 'OUTPUT 717;"*RST"' sends a reset (*RST) to node 17 on output port 7, if I'm remembering that right.
Tim
By my comment that this predates SCPI, from a brief glance at the manual it looked to me that the text commands didn't necessarily follow the SCPI standard (which may well have not existed when this instrument was built) but I could be wrong - actually, I'm probably wrong since I only spent 45 seconds or so looking
 . I agree that's exactly how you would send a reset command (which happens to be SCPI) with HP Basic.
. I agree that's exactly how you would send a reset command (which happens to be SCPI) with HP Basic.Mark
-
Don't think of them as queue element refs. Any array or string wire on a diagram is going to have an allocation of a handle structure, and you will see at least one allocation dot somewhere at the source of that wire. These handles are totally hidden by the implementation of LabVIEW (unless you use CINs), so don't expect to be told "this allocation dot is just a handle, and may or may not become an dynamic object (array or string) on the heap".
Regardless of any queues, pretend instead that your array wire is in a case structure. If that case never executes, nothing should ever happen with the heap; no array should ever be created, but your compile-time handle will still exist, and you'll still see a buffer allocation dot. Unless you have very simple code and there is some constant-folding going on, the dynamic heap stuff can only happen at runtime, so there's no way to show the behavior before your VI runs.
So I believe it's not a correct assumption that a buffer allocation dot is shown, it means that a fresh copy of dynamic data will be generated as that node executes. The dot makes it more likely that your data will be copied, but if the run-time realizes that no one else needs the data it should be able to point the handle at the existing heap object. There is no way to know that at compile-time (in most cases), which is when the dots are drawn, so you will see a dot if a copy might be made.
Jason
I think this explanation makes a lot of sense - the array (or string) handle must exist before the data can exist (the heap gets allocated) and that's what we see as the allocation dot. I do think the LabVIEW tool to show allocations is a little misleading in that the buffer allocation dot that shows LabVIEW just grabbed a 32 bit handle for a possible array looks just like the allocation dot that says LabVIEW is going to make a copy of 200Mb of data from an existing array. No wonder it all seems a little confusing

Thanks,
Mark
-
How does your first snippet "fail at runtime"? If you mean that it throws an error, well sure, but the correct data, an empty 2D array, will still be transferred onto the blue wire, dropped into the buffer allocated for that purpose.
Now here's where I wade into the deep end, exposing near-total ignorance and waiting for AQ to rescue me...
For any queue of variably-sized data, I would expect the queue itself to contain an array of handles, where the handle is some kind of LabVIEW data structure (it used to be defined in the CIN manual, if that's still around). The handle is going to point to your 2D array of data, and the LabVIEW memory manager is going to allocate memory from the heap and store pointers to those dynamic memory object in the handle.
So when you dequeue an item, you have to allocate a new buffer to store the handle, but it's possible that the handle could point to the same memory in the heap. The queue itself is done with that handle because it's been dequeued, and so it needs to live somewhere else, which is in the newly allocated buffer. So just because you have a new buffer to store the handle (which is small and fixed-size), doesn't necessarily mean you have made a copy of the heap object (which is dynamic and might be huge).
However if there is any chance that the 2D array in the heap is needed in some other wire or branch of the same wire, LV will have to make a copy of that part of the heap so that dataflow integrity is assured. So just because you see an allocation dot on the diagram, the question is whether it is 100% required that the heap memory object is also copied. I think using a DVR is a way to try to make sure that the the same memory object is the one in use, but if no other wires are laying claim to the dynamic memory object, it could reuse the buffer at runtime even though your buffer allocations (which is 100% compile-time information) might show a copy.
Waiting to be corrected,
Jason
By fail at runtime I mean the dequeue will fail (set the error out true) if run without first creating a queue. That's just meant to show that the dequeue will compile without any knowledge of whether or not a queue has been created so I was trying a mental exercise to see how a dequeue would know that a data buffer can be reused if it knows nothing about the queue size or even if the queue exists. That's all. I doubt the buffer ever gets created if the queue ref is bad, however.
And I do agree that it was accepted practice in the DBDVR (days before DVR) to use a single element queue as a way to pass data by ref and avoid making copies as you and Ben have pointed out. I'm just trying to make sense of this buffer allocation on dequeue thing at this point - I really am feeling confused.
Also, your argument about creating buffers for queue element refs makes a lot of sense except that the Show Buffer Allocations tool specifically shows an array buffer being allocated in my snippets above - if I do the same thing and replace the the array with a string (and the array size with a string length) the Show Buffer Allocations tool now shows the buffer allocation on the dequeue as a string. So the tool thinks a buffer is getting allocated of whatever type of data the queue holds.
I know this doesn't help explain anything, but I appreciate the discussion!
Mark
-
To avoids the extra data copy LV has to be able to "see" that the original data buffer is no longer required. In that example the data buffer being queued up is a constant in the code. If LV passed that buffer in-place and the consumer inverted all the bits, IN THE ORIGINAL BUFFER (sorry for yelling) then the next time you ran that code it would pass teh inverter version.
I used queues to get data from my DAQ devices. The output from DAQmx is passed to the enqueue and since the wire is not branching, the data gets transfered in-place so the bufer from DAQmx read is the same buffer holding the data after the dequeue operation.
Ben
I still see a buffer allocation here.
I don't doubt that you get exactly the performance you report, but I can't create a dequeue operation that doesn't show a buffer allocation
 . So in order for LabVIEW to "see" a data buffer in a queue is no longer required, LabVIEW has to decide at runtime that the buffer is available? For instance, the first code snippet is perfectly valid at compile time but because no queue exists it fails at runtime. So this means the Show Buffer Allocations can't accurately show the runtime allocations for a queue ? I'm confused!
. So in order for LabVIEW to "see" a data buffer in a queue is no longer required, LabVIEW has to decide at runtime that the buffer is available? For instance, the first code snippet is perfectly valid at compile time but because no queue exists it fails at runtime. So this means the Show Buffer Allocations can't accurately show the runtime allocations for a queue ? I'm confused!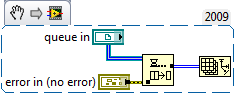
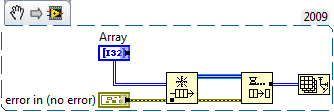
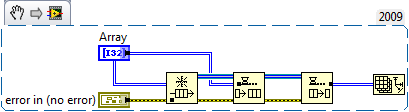
-
Since the output of the init array is used for multiple iterations, that buffer can not be re-used because the consumer loop mod of that buffer could goof what get queued up next time.
I'd expect an "always copy" in the wire after teh init but before the enqueue would let LV transfer the data 'in-place" and eliminate the buffer on the dequeue.
Just my two cents,
Ben
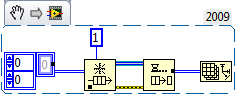
Here's what I'm seeing that makes me think you just can't avoid a buffer allocation on a dequeue - I don't know exactly how you could modify this to eliminate the allocation. But maybe I misunderstood the original question.
Mark
-
Have you checked the instrumentation network on NI's website? You may find the solution already programmed there.
You're asking a pretty broad question. Is this GPIB? RS232 Serial? RS485 Serial? Ethernet? My experience is that Algient/HP uses SCPI commands; the instruction set is listed in their manuals.
I'd start with a simple command like *IDN? (assuming SCPI commands) which returns the devices identifying information. Everything else pretty well falls into place if you can get this command working as it requires you to format a command, send it, receive a response an decode the response.
Tim
Looks like this instrument predates SCPI and is no longer supported by Agilent (and all the documentation referencesHP-IB - not exactly a modern instrument) - here's a link to the manual
http://www.home.agilent.com/upload/cmc_upload/All/04142-90010.pdf
Look at the command sequences in the HP Basic examples and try to figure out how they might work in LabVIEW - good luck, this looks painful.
Mark
P.S - is this just coincidence or a duplicate post?
http://forums.ni.com/t5/Signal-Generators/driver-hp-4142b/td-p/115360
Mark
-
Oh yeah, you are certain to get a copy there. You have that matrix on two totally separate wires on your diagram, so a copy is needed for each wire. Now in your trivial case, those two wires will never execute at the same moment (probably!) but if you make the diagram a little more complicated then they could execute at the same time and would absolutely need to have separate copies in memory of whatever might be in the two wires.
I don't think this is correct - the only wire I see branched is the queue ref, so this ensures you get a copy of the queue ref, not the queue element. I'm not privy to the internals of the queue implementation, but I think I do recall that I have read it is a protected implementation of shared memory. And I don't think the queues could execute at exactly the same time since a mutex or some such mechanism protects them so a queue read or write is always an atomic operation - that's the only way one could guarantee the FIFO behavior.
Also, I built a simple example following the posted diagram - I get a buffer allocation on the dequeue if it wires to anything at all, even an array size function (which I'm pretty sure doesn't require a copy of the data to operate). And this is without even including the enqueue in the producer loop. So the buffer allocation seems to be part of the implementation of the queue and a DVR around the queue wouldn't help.
This seems like a textbook case for DVRs, assuming you really need the producer-consumer pattern. I don't know too much about the internal implementation of DVRs, but it seems likely that dereferencing the DVR would be a very fast operation, and not something to worry about if your app is also throwing around 300kB arrays.
Note that if you branch the wire of the matrix after dereferencing it, LV may still need to copy your data.
Jason
I agree that the DVR would most likely be the most efficient way to go since as I understand it it could be thought of as a "safe" pointer. So you could write data to the DVR location in the producer and read it in the consumer and since the DVR is "safe" in the sense that you don't have to manage access and all operations are still atomic (I think) what you lose is the ability to use non-polling process in the consumer. Now, you'll have to poll the DVR and have some mechanism to determine if the data is fresh. Maybe just include an updated flag in a data structure that includes your array. Then you could operate on the array with an in-place structure and avoid making unnecessary copies.
Mark
-
Hello guys,
I'm a engineer from China, and got a question need your help.
We have a project need TCPIP communication, and run in ths Chinese OS, it's ok. But when changed to English OS, something wrong when excute TCP open function, sometimes ok, and sometimes error occured with the error code 56. The firewall (including the system firewall), and the anti virus software are all closed. I'm confused so much. Anyone could help?
Tom
We need more info before we might be able to help
1) are you using IP in dot notation or hostname as address?
2) are you specifiying the local port or letting the OS select the next available?
3) what is your timeout setting?
4) have you used a network packet sniffer (Wireshark) to look at the actual TCP/IP traffic?
Mark
-
Hi Again!
Well.. Im working on it right now. But I'm implementing some other nice features too. I guess a release tomorrow or early next week could be expected.
Cheers!
//Beckman
What's taking you so long!?
 Seriously, this looks like it could be a really useful toolkit for those of us that learned OOP using C# and have wondered how to apply some of those lessons learned to LabVIEW. Thanks for the contribution to the open source community!
Seriously, this looks like it could be a really useful toolkit for those of us that learned OOP using C# and have wondered how to apply some of those lessons learned to LabVIEW. Thanks for the contribution to the open source community!Mark
-
Property of DAQmx ChannelSpecifies under what condition to transfer data from the buffer to the onboard memory of the device.
Thank you for your comment Mark,
there was something a bit confusing for me in this description. I thought that the buffer was directly on the onboard memory of the device!
I see now that the buffer is in the PC memory.
I still does not understand very well how does it work. When you are on non regeneration mode, does the buffer work as a FIFO?
For instance I haven't found any place where this is well described!
Regards.
Here's the way I understand the buffers - and I don't guarantee this is correct!
The DAQmx driver for AO allocates memory on the host computer's memory - this is the "buffer". If you are in non-regeneration mode, this buffer does act as a FIFO. A typical sequence is 1) LabVIEW program creates a waveform/analog signal and writes that data to the host computer's buffer when the DAQmx Write VI is called. 2) In non-regeneration mode, this data is consumed - the calling program is responsible for making sure there's data in the host computer's buffer as long as the DAQmx write command is requesting it. If the data buffer ever gets empty before the write is complete, DAQmx errors. 3) In regenerative mode, the task will not consume the data in the buffer and instead just re-read from the buffer for the duration of the requested waveform.
The default data transfer mechanism from the host buffer to the on-board memory is DMA. This can be changed to interrupt driven, but there's hardly ever any reason to do so. The DAQmx drive takes care of all the transfer from the host memory to the onboard memory.
Mark
Mark
-
.....
I am missing something here? How does LabVIEW manage the analog output buffer? Does it wait that it is empty before writing to it?
.....
Regards.
I can help answer part of your question - for the analog output buffer, there's a property you can set thru the DAQmx Channel - here's the blurb from the LabVIEW help file. I think the default is Less than Full.
Mark
Analog Output:General Properties:Advanced:Data Transfer and Memory:Data Transfer Request Condition Property<h1>Analog Output:General Properties:Advanced:Data Transfer and Memory:Data Transfer Request Condition Property
Short Name: AO.DataXferReqCond
Property of DAQmx Channel
Specifies under what condition to transfer data from the buffer to the onboard memory of the device.
Onboard Memory Empty (10235) Transfer data to the device only when there is no data in the onboard memory of the device. Onboard Memory Half Full or Less (10239) Transfer data to the device any time the onboard memory is less than half full. Onboard Memory Less than Full (10242) Transfer data to the device any time the onboard memory of the device is not full.</h1>
-
Thanks for all the suggestions - this at gives me a place to start. It looks like 6 PCI slots is no problem if I go the single board computer/expansion chassis route ( up to 14 seem readily available). But no dice if wanted a motherboard with 6 PCI slots - most only have up to two PCI slots with the rest being PCIe.
Thanks,
Mark
-
Anybody have any opinions on suppliers of industrial rack mount (19") computers? I'm upgrading some testers and each uses up to six PCI slots. The current computers are old and need to be replaced but the PCI DAQ cards and instruments still meet our needs so I intend to keep using them. I haven't tried to buy rack mount computers in a long time so I have no idea who might be supplying quality product. And while price is considered, I'd take reliability and support over price any day. BTW, I intend to run Windows 7 and exe's built in LV2009.
Thanks,
Mark
-
I have a GUI with an exit button which generates a value change event to close the application by doing a number of actions including a 1 second delay to allow other loops to end. I realized that the application close icon should also provide the same actions, so I added the application close event to the event handler for the exit button and then discovered that the application does not handle the application close event the same way as the exit button event! It seems that I need to modify the application close behaviour, but cannot see how this is to be done. A hint would really be appreciated.
By Application Close icon, I assume you mean closing the top level VI with the red X in the top right corner of the active window. If so, don't use the Application Close event - instead, use the <this vi=""> Panel Close? event and set the Discard? property to True (the property shows up on the event case after you select this event). What this does is catch the panel close event and filters the actual panel close command. So the panel will not close but you can use the event to fire whatever's in the event case that handles it (could be the same code as your exit button calls) and then use a property node to close your panel after all your clean-up code executes. The only complication to this approach is that the Panel Close? and Value Change? events can't have the same event handling case so you might want to have your cleanup code in a SubVI to make it easy to call from two places. Or another approach (some might consider it a hack but I think it's OK in this particular situation) is to just have the Panel Close? case fire the Exit button's value signaling property to force the Exit case to execute.
Mark<br><br>Edit: OK, Francois types faster than I do
<br></this> -
One thing that works is to create the source VI as a re-entrant VI (instead of VIT) and launch it with the 0x8 flag set in the Open VI Reference function. Then, each copy gets spawned as a unique instance. You can track the instances by unique ref num or use the CloneName property for the spawned VI. I use the clone name to create named queues that I then use to collect/send data from all of the spawned instances running in their own threads. This is similar to what you're doing except LabVIEW names the clones instead of you and this does work in the run time.
Mark
-
I have this configuration and it works fine. In general a 32-bit app doesn't know anything about a 64-bit OS. It's the OS's job to provide a virtual 32-bit environment for the 32-bit app to run in. So 32-bit LabVIEW is going to build you a 32-bit app which will run fine on XP.
Thanks for the first-hand info - that gives me confidence that all will be OK! I suspected as much, but I don't have any experience with 64 bit OS's.
Mark
-
I've looked thru the LabVIEW faqs and dev zone stuff on 32 vs 64 bit LabVIEW but I can't seem to find an answer to this specific question. That is, if I install LV 32 bit on Win7 64 bit and build an exe (from LV 32 bit), does it build an application that I can install on other 32 bit Win OS's (XP SP2 is the one I have in mind)? I'm in the process of finally upgrading (I get a new machine and I get to install LV2009 finally) and I'm trying to make a decision about whether my primary Win7 OS should be 64 or 32 bit. I have to be able to build code I can deploy to WinXP SP2 32 bit machines.
Thanks,
Mark
-
The first (from asbo) will work in either the dev environment or a built exe - it will just give different results. In the dev env, the return path might be something like \myFolder\mySubFolder (for a VI at \myFolder\mySubFolder\myVI.vi) and in the built exe it would return \myFolder\mySubFolder\myVI.vi (for an app at \myFolder\mySubFolder\myEXE.exe that contains myVI.vi - the current VI's path in the exe is \myFolder\mySubFolder\myVI.vi\myEXE.exe)- the VI is contained in the exe. The second (from crossrulz) would return the LabVIEW.exe directory in the dev environment and your exe's directory from the built app. So, a common practice is to use the Application.Kind property to see which environment you're running in (run time or development) and you can handle it from there.
Mark
-
VIs, due to the dataflow design, always block execution until they are complete unless you take specific steps to start and run them in a new thread. You accomplish this using VI server calls - The easiest is to get a static reference to the VI you want to execute, wire that into an invoke node, and select the Run VI method (I think, I'm working from memory and I don't have LabVIEW on this machine). Set the Wait Until Finished argument to false. Now, the VI will start and run in a new thread and the call to start the VI will return immediately. If you want to open the front panel, set control values on call, etc., you'll also need to do those with property and invoke nodes. All of the functions I just mentioned are on the Application Control palette.
Also, if you need to launch multiple copies of the same VI, it will have to marked reentrant and the method to launch is slightly different. You'll have to wire the static ref to a property node, get the VI name, and pass that into an OpenVI (once again, I think that's the name) function because you have to set the optiions flag on that functon to 0x8 to allow launching reentrant VIs.
More info here
http://digital.ni.co...6256C59006B57CC
Mark

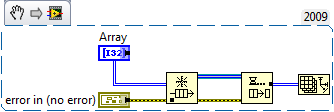
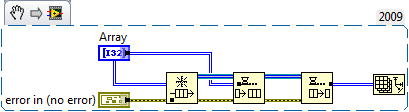
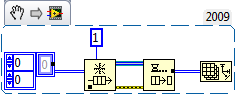
My clever design...is NOT clever
in Application Design & Architecture
Posted
Now might be a good time to download an eval copy of the Execution Trace Toolkit - it's not without its own issues, but it really might be helpful in this instance to see where the memory is actually getting allocated at run time.
Mark