

Mark Smith
-
Posts
330 -
Joined
-
Last visited
-
Days Won
5
Content Type
Profiles
Forums
Downloads
Gallery
Posts posted by Mark Smith
-
-
Take a look here
http://www.mooregood...iteAnything.htm
This does read/write to ms style config style VI's (not the linux style config VIs) but you can get a lot of insight about how something like you are proposing might be structured. In my opinion, this set of VI's pretty much solves the problem of easy to read, write, and create config files. I've used them quite a while with no problems.
I also use the LabVIEW XML schema a lot but not where I expect the configs to be edited in a text editor
Mark
-
Ben is correct - as long as the math is all U32 and you take the difference of the two the rollover won't matter - to prove it to yourself, create a couple of u32's and set one to 2^32-1 and then subtract that from one set to 1. The answer is 2 - exactly what you need for an elapsed time counter that rolled over (the 1 would be the counter that had rolled over and the 2^32-1 is the start tick count).
Mark
-
 1
1
-
-
Than you for your prompt reply.
Ok, you are right. I attached an immage with my waveform and with its details.
After I built the component of my waveform with LV waveform functions generation, I merge them with WDT Append Waveforms DBL function.
Therefore I give the new waveform to my DAQmx driver but it generate only the first part of total waveform (the sine waveform). I have configured my DAQmx Timing with <Finite samples>, with 1M as rate and with 100k as samples per channel. I use only one channel of the daq-board. What is the best technique for generate one waveform such as the waveform shown in the attachment?
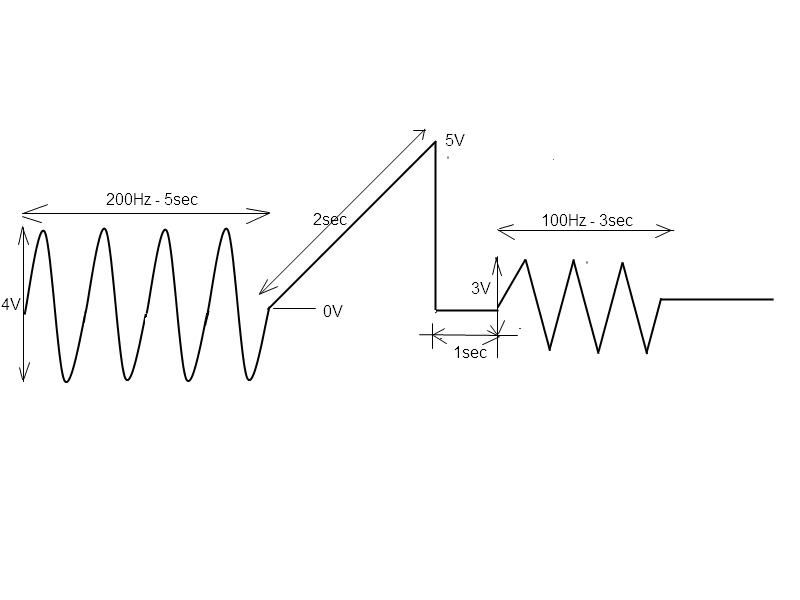
The problem here may be that you're trying to generate 11E6 points of data (11 seconds total waveform at 1E6 update rate) but you're only loading the first 100K points into the DAQ DMA (the samples per channel parameter) - so I would expect you won't see the entire waveform generated and only the first 100k points. Also, does your source waveform have 11E6 points? Was it built with dt = 1/1E6? I don't know if you can load all 11 seconds into the DAQ's DMA at once. You can try - just change the samples per channel to 11E6 and see if it works. Also, which polymorphic DaqMx Write VI are you using (which data type as input?).
The best solution for large arbitrary waveforms (analog outputs) is to write the waveform generator to accept a streaming input - here, read your input waveform in 100k chunks and enqueue it onto a finite queue (length of 4 should be fine - I find greater than one to be necessary so the consumer never has to wait (if the data's not there on time this will fail)- letting it enqueue the entire waveform just eats up memory). This is your producer loop. Set up a finite generation task with the 1E6 rate and 100k samples. Now, put the Dequeue, Write VI and the Start Task VI in the loop - put the Start Task in a case structure so it executes first time only (once you start the task in the loop, you can't restart it until you call Stop Task). The Dequeue gets the first chunk of data (100k) , sends it to the Write VI, on i=0 calls the Start Task, writes the first 100k points, loops, gets the next 100k data from the queue, sends it to the write VI, on i>0 doesn't call Start Task, and so on until the producer loop sends all the data and this loop (the consumer) writes all of it.
Good Luck,
Mark
-
I have a project that I would like to "export" with all of its dependencies (LV8.6.1). This seems like it would be easy but I always get an error "Cannot save class "XYZ.lvclass". Another class in memory is already loaded from that path." If I remove the offending the class, then it just goes till it finds another class to complain about. Anybody got any ideas what's going on here? Can this be done?
I also have problems trying to save to a source distribution if I try to retain my directory structure (flat directory works OK).
Thanks,
Mark
-
Maybe the example mstoeger gave is a bad one for this function. In the way I use these functions, my diagrams are a lot cleaner because I don't have to pass the queue reference everywhere (to several loops, into subVIs, through structures, etc.). I only have one reader of the queue. Notice that I do not use my FGV to read the queue, only get the reference. The benefit here over the FGV holding an array is that the reader will just sit there and use no CPU time. With a single reader I could have commands that come from many different sources (user interface, reactions to outside sources, etc.), often not even on the same diagram (different TestStand calls) or many subVIs down. Yes, I could obtain the queue reference by name, but that is a pain to keep track of my queue's name, obtain the queue, send a quick command, and "close" the reference (not destroy since another thread still has it open). My company had a VI that did that and I eventually said "Why not just keep the reference here?" Hence the FGV given above. I noticed a good performance boost, no hard data on it, but I could definitely tell.
LabVIEW gives us lots of tools that we can use where appropriate. I typically use named queues because I don't often have the same use case you describe where I would open a ref and then enqueue a single argument and then close. More typically, I'll have a VI that will run asynchronously and either produce or consume data. I get the ref to the named queue when the VI starts and then close it when the VI exits. There's a little overhead but it's negligible in the grand scheme of things. I can see where if you just need to grab a quick queue ref and then put a single arg on the queue your method makes sense because there's less overhead per enqueue operation.
Mark
-
The advantage - in my opinion - is:
- queue used as a command-construct does not "lose" elements (a FGV could be more often filled then read-out)
- in this way I hope to get the ability to place the VI on different loops/threads and for example get even multiple previews of queue elements (I haven't done this in the previous attached example).
Well, I think queues are widely usable ....
Don't get me wrong - I think queues are one of the most useful and efficient of LabVIEW's data sharing mechanisms. But it still sounds to me like your use case is better suited to a simple collection (a LabVIEW array) rather than a queue. A FGV with an array could hold any number of elements (never gets full till you run out of memory), you could easily "preview" the elements (they are always available, all you have to do is iterate through the array), you can retrieve a single value by index, and you can search or sort the collection. You can do the same thing with a queue but I just don't see the reason for the added complexity.
Mark
-
I'll take a look at these sources, here again my problemcase in LV8.6 version --> thank you
Martin
the problem is that the queue.vi blocks in the read mode (since nothing is on the queue) and it gets a request to read first and there's nothing on the queue. Add a timeout to the read function that's not -1 (wait forever). But I'm not seeing the advantage of this to a standard FGV. If I want to share queues between threads/loops, I use named queues and just get references by name to the queue when I need access. I'm sure there's some overhead, but typically I need to get the ref once and then read many times as some other operation puts data on the queue so the overhead is negligible. If I just wanted to share data between many threads (rather than "stream" data) I'd just use a FGV or a class that behaves like a "by ref"and get the data through an accessor.
Mark
-
Working with a large app that spans several parallel running VIs (a master VI and a couple dynamically called VIs) and trying to implement a quality error handling/logging functionality (the previous version didn't have one and I hacked something into it as an intermediate update!)
Currently, I have a produce consumer, that has a small error VI that triggers and event that is handled in the producer loop...the action can be handling/logging etc.
Anyone have any clever error handling architectures or ideas that might be of use?
See if this helps (LV 8.6.1)
Mark
-
This most likely has nothing to do with VISA and the PC/GPIB controller side and everything to do with the state the instrument is left in after the last command - it's not really ready to accept another command string. I'm assuming this is a SCPI instrument (I really know nothing of this specific instrument but all of the Agilent stuff I worked with has been SCPI). If so, after you read the data, can you send an error query (:SYST:ERR? or something like that). If that doesn't work, then maybe you have to handle errors by reading the status byte and finding out if anything in the error or event queue is set. This stuff is all very specific to the instrument, so you'll have to dig through the documentation to find out exactly how the 8504B operates. That or just call a *RST command and start your entire routine from a known state every time (this would be the nuclear option
 )
)Mark
-
Write a custom probe for a VI Refnum type. In the diagram of that custom probe, put an Open FP method call. Then probe the wire coming out of your Open VI Reference call.
If you have scripting knowledge, you can go further and have the custom probe open the panel and open the diagram and put a breakpoint on the top-level diagram, or some other point within the diagram of your choosing, so that when the VI actually gets called to run, it'll trip the breakpoint.
Q. Why didn't I think of that?
A. Because I'm not AQ
I'm off to create my custom probe now....
Mark
-
Opening the front panels of the clones and then the block diagrams is most direct way to debug. The only other thing that I find helpful is to put the property node that opens the panel in a conditional disable structure and then create a DEBUG_REENTRANT flag that an be true or false (or mutiple flags for different circumstances). That wah, you can just modify the conditional symbols in the project when you need to debug and you don't have to make explicit code changes. I also have a utility that I use to debug reentrant VIs that runs a daemon in the background and a VI that enqueues messages for that daemon. I can drop the "send message" VI anywhere I want to see what's on a wire and when that wire carries data the message pops up on the daemon.
Mark
-
2
-
-
I don't know what your specific problem may be, but just for comparison I'm attaching a very simple .NET (VS2005) project that builds a DLL I can call from LabVIEW. Maybe you can compare your project and figure out where the differences are. Also, have you lloked at your assembly with ILDASM and confirmed that the constructor/functions are indeed getting built as expected?
-
I know, I haven't actually written the enqueue part in, but for the sake of argument, assume that the results of the calculation in each loop (the average frequency values) are enqueued into a single queue, what will happen?
I don't claim to have any knowledge of how the LabVIEW queue is coded under the hood, but my experiance tells me the enqueue operation is atomic. That is, if you have two operations writing to the same queue, one write will complete before the other begins. For example, if you're writing arrays to the queue, you don't have to worry that some queue entry will contain a mixture of array data from two attempted writes. You will not, unless you take extra steps (like including a source tag/time stamp on the data), have any idea in which order the elements were enqueued.
Mark
-
anyone willing to hurl insults at my code??
If you can post in LV 8.6, I'll throw in my two cents...
Mark
-
LabVIEW RT used to come in two flavours: ETS (the way it is now - RT running on a target) and ETS (the method you linked to above).
But they were really hard to tell apart....
 ?
?Mark
-
I have tried to search for this but have found many broken links.

How do you set the svn:needs-lock properties for use in a Lock/Unlock model in TortoiseSVN?
Thanks
Dan
Add these properties to C:\Documents and Settings\<username>\Application Data\Subversion\config
[miscellany]
enable-auto-props = yes
[auto-props]
*.vi = svn:needs-lock=yes
*.ctl = svn:needs-lock=yes
*.vit = svn:needs-lock=yes
*.ctt = svn:needs-lock=yes
*.rtm = svn:needs-lock=yes
*.llb = svn:needs-lock=yes
*.lvproj = svn:needs-lock=yes
*.lvlib = svn:needs-lock=yes
*.lvclass = svn:needs-lock=yes
Now, all of these file types will get created with the lock enabled - I think - it's been a while since I looked closely at this
Mark
-
According to the R. Stevens book on Network Programming the TIME_WAIT state is 2 MSL and every implementation of TCP must choose a value for MSL where the recommended value for MSL is 30 secs to 2 minutes which means TIME_WAIT is between 1 and 4 minutes. I don't know what NI is setting this to, but on our server side there is a standard socket option called SO_LINGER that allows us to set what we want which, for our application is very short (1 minute). I would like to do likewise at the server end since the 'active close' will be initiated from LabVIEW if the client has to be shut down and then restarted a short time later. This scenario would occur if a user accidentally closed the NI program and we needed to immediately reconnect to the server.
This is good info that I will look into. And yes, we are using Wireshark to monitor the messages, so I am pretty sure I have to adjust the socket options and will definately look at the raw socket stuff. As for changing ports, the server code is hard coded into a custom kernel using WindRiver and the appropriate BSP for the MVME5600 board, so we really have to keep the code small and fixed on the embedded side.
OK, so maybe I'm getting confused here - the IP address/port that defines your server address is fixed - correct? This would be common practice. When your client disconnects from the server, it sends a close message to the server and the server closes the connection and sends the close handshake and the client goes into the TIME_WAIT state. The protocol says that only one end of the connection is required to go to TIME_WAIT (which is a default 4 minutes on Windows) and common socket implementation lets the server side (the accept socket) release the socket immediately and makes the initiate socket (the client side) go to TIME_WAIT (edit) - this probably should say the endpoint that initiates closing the connection is required to go to TIME_WAIT which in this case is the client - (end edit). So, the server can now immediately accept a new connection on the same port. The client cannot initiate a new connection on the same port until the TIME_WAIT completes. Here, most clients (like LabVIEW's default behavior) just use the socket library's ability to auto-select the client side port to allow immediately reconnecting to the server by just grabbing the next available port. Since the client initiates the connection, it knows 1) the socket handle and 2) the server/port it's connected to so it has full control and access to the stream. There's seldom any need to worry about which client side port to use or even which is in use. Of course, your situation may be different and you may really need to re-use the same port. Then, you're right - you need to force the TIME_WAIT to something other than 4 minutes.
Mark
-
I had to solve a very similar problem. The application is a little different from the multiple clients/single server (which is more common) since you need a single client that connects to multiple servers. My app did not require UDP, but it does manage TCP/IP connections to 54 unique ports on 9 IP addresses. The approach I took was to create a collection of clients and then manage that collection. Each client is responsible for managing the connection to one socket. That connection can come and go without interrupting or interfering with any of the other connections. Each client consists of a TCP/IP connection VI that has a write queue and a read queue running in separate loops. There's also a UI VI that has a read loop that pops messages from the TCP/IP connection VIs write loop. In my case, I have the read VI write to an indicator property node since I've got to get all 54 streams displayed on the front panel and the wires would be a nightmare. Then, the UI uses an event structure to respond to message send requests from the user - this event structure just puts messages on the appropriate TCP/IP write queue.
Like Black Pearl said, these VIs are all re-entrant and launched dynamically. When I launch, I use the clone name of the TCP/IP connection VI to create unique queue names for each instance. I keep the queue names to manage the connections. When I need to close a connection, I force the release of that queue and that stops the TCP/IP connection VI and the UI listener. It doesn't affect any other connection.
So, to the user the applications appears as a single client but it's really a collection of completely asynchronous unique clients for each socket.
Mark
-
In vi.lib\Utility\tcp.llb there's a VI called TCP Get Raw Net Object that will return the current socket handle. You could then use the socket handle as an argument into a CLN call into a DLL that could then call the Winsock DLL (assuming you're on Windows) and set the TIME_WAIT value... I think... I haven't done it. Or you could just ask yourself if you really need to reuse the same client side port or just let the client grab the next available one to reconnect to the server. This would be a lot easier.
Also, are you sure the handshaking with the server is happening exactly the way you think it is? Have you looked at the transaction with a port sniffer like Wireshark?
Mark
-
1
-
-

Sorry for the delay, I had lost track of this thread!
That is a wonderful explanation of my Event Logger with some features mine does not have.
I can't ignore the reentrant feature. Nice!
The following is in the interest of learning what others have done about errors on RT tragets...

I have never used my Event Loger on a RT target since the strings of the Error Cluster "Source" is of variable size. In an RT environment, dynamically allocating buffers for the strings when code starts "spewing errors" can crash an RT app. "Bad, Bad, Bad".
IN RT apps I force the Source to empty strings and pass the rest off to a WIndows app to log, whenever possible. So...
Have you tried your LVOOP based solution to RT yet?
TO All:
What are your experiences with logging errors on RT targets and what techniques have helped you?
Thanks again Mark!
Ben
Ben,
Thanks for the compliment - some of my code actually works the way I intend it to, or as we used to say back in Tennessee, "even a blind pig finds an acorn sooner or later". As far as RT targets, I've never actually had an opportunity to work with LabVIEW RT so I can't make any useful comments. I will say that when I've worked with C code on RT targets the errors were always returned as either an index into a lookup table (I16's or such) or as bit arrays so they were always fixed size either way.
Mark
-
You can learn most of what you need to know by decomposing an existing project. Use a property node with the VI Server - Application class and then the Projects.Projects[] property to get a list of all the projects open - iterate thru the projects and get the Name property of the project and see if that's the one you want - if there's only one project open, then it will be easy. Then, from the MyComputer property of the Project, use a property node (it will become a TargetItem property node when wired to the MyComputer ref), you can get a BuildSpecs property and then the children of that ref are the actual build specifications (source dist, exe, installer, etc). Once you get a ref to the right kind of build spec (sounds like an EXE in your case) you can see all the properties for that type of object and the methods you can invoke by wiring property and invoke nodes. Then, it should start to become sort of clear what you need to write to your project file to create a new build spec.
This is all clear as mud, but that's the only way I ever figured out how to programmatically change a project. I've never created a new build spec programmatically, but I do have code that modifies build specs and saves them back to the project. It might be easier to create a "template" build spec in your project and then modify that rather than have to create one from scratch.
Mark
-
I'll throw out another option here - I have found the "Read Anything" and "Write Anything" VI's from MGI to be extremely easy to use for simple ini operations. All you have to do is create the cluster (a type def is best) with the controls you want to write to and read from file. Wire the cluster to the "Anything" input of the "Write Anything" VI and run the VI. There's your ini file. To read the file, wire your type def'd cluster to the "Type Of Anything" control on the "Read Anything" VI and then use the Variant To Data function to convert the returned variant to the original cluster
The VIs are free at
http://www.mooregoodideas.com/File/index.html
Mark
-
This sounds similar to a problem I had (about LV 8.2/8.5 - that's the latest version I was using when I worked on that project) so this info might be useful. What happened is that the exe had a call to some public member of a lvlib. So the exe build, in the interest of keeping the size down, only included the lvlib members that were called and also modified the lvlib "table" or whatever keeps the lvlib info in the executable to only include the members actually called. Then, when I included members for the same lvlib in an llb called dynamically, the exe had already read a lvlib "table" that did not include the members in the lvlib in the llb and decided that those members called were not part of the lvlib and threw a similar error. It was the kind of error that will make you absolutely crazy, since it requires knowing how the exe builder treats the lvlibs. The "fix" was to explicity include all of the lvlib members in the exe build so that "table" would recognize the ones in the dynamically called llb. Kind of breaks the "plug-in" concept since you have to know when you deploy your exe everything you might call in the future that's in a lvlib. I don't know if newer LV versions treat this the same way.
Mark
-
...I've found the licensing limitations and additional software requirements of TestStand and LuaVIEW are really restrictive in the environments that I work in, and a native LV solution is usually easier to handle....
Joe Z.
I know any time one makes a blanket statement about any architecture being "good" or "bad" that there's room for real disagreement - I don't use QSMs but I am sure that there are people (like Joe) who know exactly what they're good for and how to make them work so they shouldn't be dismissed out of hand.

However, I will take exception to the statement about the licensing limitations of LuaVIEW (can't speak to TestStand - I don't use it). With LuaVIEW, the license is per project (or a site license, which I have). At any rate, all deployed apps built under this license are covered under the development license cost - no additional deployment license required - and all developers on the project are covered under the single license. Also, all license management is "honor system" - there's no license management software mucking things up so you don't have to worry about licenses expiring at your customer's site (or for your developers) and getting those angry phone calls. Also, the entire Lua interface is accomplished thru a CIN so there's no additional dll's or run times or anything else that needs to go with the deployment. It's really pretty simple.
Mark
The grass is always greener, etc
in LAVA Lounge
Posted
They had me till they mentioned Kwaj...........
Mark