eberaud
-
Posts
297 -
Joined
-
Last visited
-
Days Won
10
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by eberaud
-
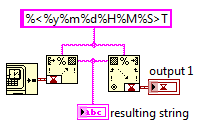
It worked, thanks! I guess a 2-digit year is not enough information to reconstitute a full absolute TS...
-
A part of my code converts a time stamp into a string. Another part will have to read this string and convert it back to a time stamp. However, when I run this quick example I've created, I get an error. Does anybody know what I'm missing? Thanks

-

Strange queue/debugging behavior probably related to race conditions
eberaud replied to _Y_'s topic in LabVIEW General
To me this is not a race condition. A race condition would for example cause the dequeue function to be called before the enqueue function while you intended otherwise. But the fact that a function doesn't time out while it's supposed to is a bigger issue... -
They are all timed loops, so there are no Wait functions. The period of the timed loop is defined as 10ms.
-
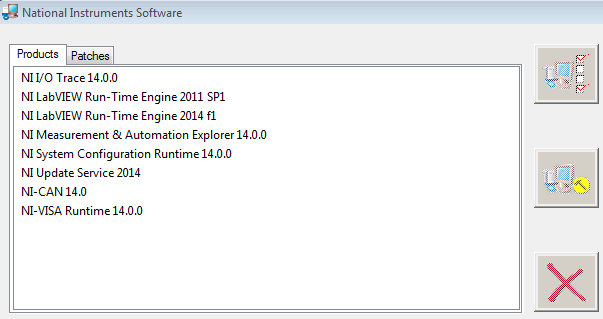
Yes, the 3 CANbus have a 500k Baud rate. On the 3 buses, the application send and receive several messages every 10ms. Each send message has to be prepared, and each received message has to be parsed, so overall it's true that it is an intense process... Well this PC previously had older versions of NI-CAN, NI-VISA, etc. that I upgraded to the 14.0 versions. Do you think I should try to take a "clean" PC with no NI products at all, and install only what I need?
-
Strange queue/debugging behavior probably related to race conditions
eberaud replied to _Y_'s topic in LabVIEW General
By "no timeout" you mean the enqueue element doesn't exit after 30s? -
Sorry. Yes, the whole time I had the following NI products installed:
-
The thing is that it's also the main HMI, so it's full of splitters, subpanels, and so on. Since I already have a workaround, I might wait quite a bit before doing this test. Thanks for the idea though, I'll keep it in the back of my head...
-
I made a new test with no CAN communication at all. CPU and Memory are now identical in LV2011 and LV2014. So it seems the CAN is the culprit...
-
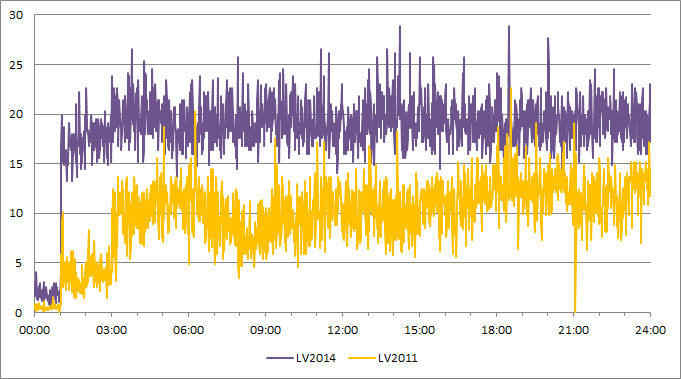
Both LVx32. Settings-wise, I made a copy of all the files - including the project file -, opened the application in LV2014, saved all of them in LV2014, and started the build. So all the settings should be the same. I checked the Advanced page of the build specification, it is the same: Debugging disabled, SSE2 optimization enabled (other settings are the same as well). I understand your point (and Shoneill's), but in my case the application's performances are also worse. At time = 01:00, I start the communication on 3 CAN bus and log the CAN messages in a file. The analysis of this file shows a determinism way worse in the LV2014 version. So the application is kind of chocking in LV2014... FYI, at time = 03:00 I also start some automation, which explains the second rise of the CPU%. As a general comment, I'm not saying LV2014 has bad performances as an absolute statement. I think all of you are correct to say it comes from my application itself. I posted here to see if anybody else had had this issue...
-
I edited my message to mention the scales. The Y-scale is the percentage of CPU used by the application (like the number you can read in the Windows Task Manager), and the X-scale is the time, expressed as MM:SS. The shape of the plots or their absolute values are of little importance (I was performing specific operations at given time). What is noteworthy is the factor 2 between the 2 plots..
-
Before making the switch from LV2011 to LV2014, I ran the exact same test with the 2 versions (2011 and 2014) of my application. I recorded the CPU usage and discovered a huge deterioration of in LV2014. Is anybody aware of any change between LV2011 and LV2014 that could impact the performances like this? I should mention that the unit on the Y-scale is %CPU and the X-scale is MM:SS
-
That's our main VI, its diagram is quite complicated, so recoding the whole VI is not really an option unfortunately
-
I do rock climbing, the GPS tracking might be boring
-
I fixed my problem by adding twice the same property node right at the beginning of the VI execution: Read the Window Bounds property and Writing it with the exact same value. It's transparent to the user so that's acceptable, but of course I'd prefer a real fix than a workaround...
-
Good to hear it's not just us... Even if you couldn't pinpoint the cause, do you by any chance have any idea how to fix this?
-
I'm not sure I really understand what you want to do. If all you need is to be able to monitor events and update the value of any table, just pass the reference as the input of your VI, then register the events you want to monitor and pass the registration refnum to the dynamic input of the event structure (you need to right-click on the frame of the structure first and select "show dynamic event terminals"). Then you can use the "Value" property node to update the value of the table, instead of feeding the value directly to the terminal...
-
For the last 3 years our application has been maintained in LV2011. We have recently decided to migrate it to LV2014 so I am currently testing the sources (and executable) in LV2014 to make sure everything still works. I noticed that when I run the application in the sources, the main HMI (which is the start vi) displays the menu and tool bars even though the appearance settings are such that it shouldn't be displayed. Plus it's not like they are really activated either since I can't click on anything, it looks like a pure display glitch. In addition, as soon as I resize the vi, they disappear and the HMI looks the way I expect it. The same thing happens with the executable, except the area corresponding to the menu and tool bars displays the Windows desktop instead, like if you could see through the VI... Once again, things get back to normal when I resize the VI. I've never seen that with previous versions of LabVIEW. Could it be a bug introduced in LV2013 or LV2014? Have you ever heard of somebody having a similar issue? Thanks!
-
Real-time acquisition and plotting of large data
eberaud replied to wohltemperiert's topic in LabVIEW General
Well lately I have been digging quite deeply into TDMS, and after a few struggles, I now have it working quite nicely for a need quite similar to yours I believe. There are a lot of considerations to take into account when choosing between a database solution and a TDMS solution, so I wouldn't advise you to switch to TDMS just yet, but this is something you could look into... -
Real-time acquisition and plotting of large data
eberaud replied to wohltemperiert's topic in LabVIEW General
Is there a reason why nobody is suggesting TDMS files? Wouldn't they be appropriate? -
Thank you Shirley for confirming what I've been guessing these past few days. My application writes data "by bloc", writing N samples for each channel in one write operation. I have successfully written a Read function that will iterate through several blocs one by one by re-positioning the pointer (Set Next Read Position) and adjusting the number of samples to read in each bloc (Count input of Advanced Read). Then this function just needs to concatenate the samples read from each bloc...
-
I did. The Application Engineer I had on the phone said she was also surprised by this behavior and is supposed to get back to me after she gets a hold of a coworker of hers who knows more about TDMS. But long story short, I think I figured it out: The Advanced API is a low-level API that is more efficient than the standard one, but has less smarts built in it. So when using it to read a channel, we need to know the exact layout of the data in the file and perform several elemental reads and concatenate their outputs. When setting the layout to Non-Interleaved (=Decimated), writing 4 samples for channel 1 and for channel 2 each time at each write would result in the layout described in the attached picture. My first understanding was that the Set Next Read Position would configure the Advanced Read (no matter if Synchronous or Asynchronous) to return samples for the specified channel only. I was wrong. Actually Set Next Read Position only places a pointer that specifies the location of the first sample to read. Then the Advanced Read reads samples sequentially until it has read the number of samples corresponding to its Count input, without caring about the channel those samples belong to! So by knowing the layout of the file (that depends on how many samples we write each time we call the Advanced Write), we can keep re-positioning this pointer and adjust the Count input of the Advanced Read. So let's say I need to retrieve 8 samples from channel 1, from sample no. 2 to sample no. 9 included. I need to perform 3 read operations: a) Offset of Set Next Read Position = 2, Count of Advanced Read = 2 (gives me samples 2 to 3) b) Offset of Set Next Read Position = 4, Count of Advanced Read = 4 (gives me samples 4 to 7) c) Offset of Set Next Read Position = 8, Count of Advanced Read = 2 (gives me samples 8 to 9) The attached VI demonstrates how that works. tdms advanced synchronous read.vi Test TDMS Read.vi
-
So either I really don't understand how TDMS VIs work, or there is an issue with the examples shipped with LabVIEW. If you open TDMS Advanced - Finite Asynchronously Read.vi you'll see that it asks to run TDMS Advanced - Asunchronously Write.vi first. I ran it and understood that channel 1 was being given the following values: 0,2,4,6,... which is confirmed when the Viewer opens. (and channel 2 takes 1,3,5,7,...) However when I then ran the Read example, the values for channel 1 became 0,1,2,3,4,... so it fetched samples from channel 1 and from channel 2. So is there a bug, or did I misunderstand how the Set Next Read Position works? I thought the channel name in input allows me to specify what channel I want to read samples from... Your insights would be much appreciated!
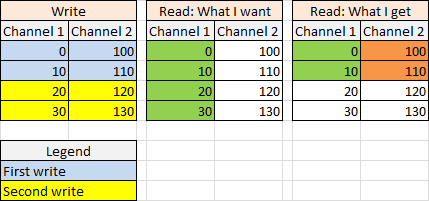
-
All my channels stream at the same rates. It's just that the user might add a new channel or delete a channel at any time, and this shouldn't have any impact on the other existing channels. I will deal with that later, probably by starting a new TDMS file, since I already plan to spread the huge amount of data over several files anyway. New headache: In my application, the read and write operations use the same reference obtained from a single Open file. I let the Advanced Synchronous Write VI buffer the data (I don't control when the data is actually flushed to the file). Reading a property (like NI_ChannelLength) gives the value corresponding to the current situation (includes the data from the latest write even though the data hasn't yet been flushed in the file - I know it by opening the file in Excel). That's good. However the Advanced Synchronous Read operation only sees data that has been flushed in the file, it doesn't see the data from the latest write. That's a big issue since I use NI_ChannelLength to compute the count and offset I want to feed to the Read, and the Read gives me bad data for the non-flushed samples. I do not get an End Of File error though, which shows that I'm not asking for non-existing samples... Is anybody aware of that issue? I tried to force the flush with the corresponding VI, but this just wrote junk in the file... Edit: If I ask for a short amount of samples (less or equal to the number of samples I write in the Write VI), then the Read is actually successful. It's only when I ask for an amount of data that would be spread over the flushed data and the buffered data that I get a bad reading. That means I need to perform 2 distinct read operations: one to retrieve flushed samples, one to retrieve buffered samples. The problem is: how does my program know what has been flushed and what hasn't? Edit2: So actually it does it also if I ask for "old" data (that has been flushed a while ago) so it had nothing to do with "buffered data" versus "flushed data". Bottom line: this happens when I retrieve data that have been written by different write operations. Look at the picture below to know what I mean. If I use the standard API, it works! With the Advanced API I get the exact same behavior, no matter if I use Synchronous or Asynchronous mode. I attached the VI I used for this test. I start to strongly suspect that I am misunderstanding the use of the Set Read Position VI... It actually doesn't guarantee that I will get only samples from the channel I wire in the channel name in input, does it? Test TDMS Sync Async.vi
-
I'd appreciate some advice again about this new issue I've been having: I want to see if I can add and remove channels on the fly. One of the channel is always there: the timestamp (just a simple index in this example). This is inportant since I need to be able to align the data when I retrieve them (to be displayed in an XY graph). To describe the issue I'm having, look at the attached image, that explains everything... I'm attaching the VI I used (very simple, made in LV2011). Thank you! Test TDMS change channels simple.vi