eberaud
-
Posts
297 -
Joined
-
Last visited
-
Days Won
10
Content Type
Profiles
Forums
Downloads
Gallery
Everything posted by eberaud
-
Thanks for those tips. I hope those tests and remarks can be valuable to others as well. I had never used TDMS before and it would have been valuable to me to find this kind of thread! I'll post here if I have more findings to share.
-
Thank you for the link. It seems I already have the most efficient way according to this document, since I never separate channels in several write operations. I tried the defragmentation, but I found that it takes a very long time (like 3 minutes) and doesn't improve the read operation's performance enough to make it worth. I also modified my test VI to measure the time more accurately and added extra cases so please take version 2. I start being able to pinpoint where the optimizations I need might be by analyzing the attached table I populated from my tests. Reservation: Comparing 3&6 (or 3&9), we see that reserving the file size makes a huge difference for the Write operation when the file is going to be written often. It makes sense since LabVIEW doesn't need to keep requesting a new space to be allocated on the hard drive. It also optimizes the read operation (less fragmentation since the file size is reserved). However if we compare 6&9 (or 4&7, or 5&8), it appears that reserving the full size is better for the read (again, less fragmentation I suppose) but significantly worse for the write, which I don't understand. Reserving only N samples instead of N*M gives better results for the writes. Writing in blocs: Comparing 5&6, we see that - not surprisingly - writing less often but with more data is more efficient for the writing time. However since the file was fully reserved, there is no difference on the read time! Comparing 8&9, this time both the write and the read are optimized when writing less often, since this time the file was not fully reserved, so more writes led to more fragmentation. Data layout: Comparing 4&5 (or 7&8), we see that the data layout doesn't have an influence on the write operation, but the decimated layout significantly improves the read operation since all samples for only one channel are requested. I would expect the interleaved layout to be more efficient if I was requesting only one or a few samples but for all channels. I didn't test that since it is not the scenario that my application will run. Additional note: Tests 1&2 shows the results one gets when writing all data with a single write operation. Case 1 leads to a super optimized reading time of 12ms, but the write time is surprisingly bad compared to case 2, I don't understand why so far. Those 2 scenarios are irrelevant anyway since my application will definitely have to write periodically in the file. I would conclude that for my particular scenario, reserving the file size, grouping the write operations, and using the decimated layout is the way to go. I still need to define: - The size of the write blocs (N/B) - The size of the reservation, since reserving the whole file leads to bad write performance. Test TDMS v2.vi

-
Thank you Hooovahh as always! Here is a nicely presented VI I created to compare the different scenarios. An enum with 6 items defines how the file is being written. My program will always write samples for all the channels at once, no matter how many samples it writes. On the read side it's the opposite, only one or a few channels (one in this example vi) are retrieved, but a large number of samples is requested. This VI is made with LV2011. Do you mean the file itself (like any file in Windows) is fragmented on the hard drive, or do you mean the layout of the values of the different samples for the different channels is fragmented within the content of the file? Test TDMS.vi
-
Hi, I am investigating the possibility of using TDMS files as a kind of giant circular buffer that would be too big to fit in a live 2D array of some sort. Of course the other reason is to have those data saved for when the application restarts. A single location in the application will be responsible for writing in the file. This would consist of a loop that writes either one or a few samples for all the channels at each iteration. I successfully achieved this with good performance by setting the data layout input of the Write function to Interleaved. On the read side, few locations might need to access the files, but only on event, so this won't be a frequent operation. However it should still be fast enough since I don't want the user to wait several seconds before being able to visualize the data. My tests have revealed that this operation is slow when data are interleaved. Here are the details: # Channels: 500 (all in one group and the file contains only this group) # Samples for each channel contained in the file: 100 000 Data type: SGL floats (I'm not using Waveforms) Read operation: # Channel to read: 1 # Samples to read: all (count=-1 and offset=0) The time to retrieve the data is 1700 ms. (3500 if using DBL, it's quite linear...) If I generate the file with just one Write (feeding a 2D array) in Interleave mode, I also get 1700ms, so this doesn't depend on how the file is written at the first place. If I generate the file with just one Write (feeding a 2D array) in Decimated mode, this time I get 7ms!! It makes sense that the operation is faster since all the data to retrieve occupy a contiguous area on the hard drive. My 2 questions are: - Is there a way to keep Interleaved layout while optimizing - significantly - the Read performance? - If not, i.e. if I need to switch to Decimated, how can I write one or a few samples for all channels at each operation (I haven't managed to achieve this so far). I should mention that I did manage to optimize things a little bit by using the advanced API, setting the channels information, and reserving the file size, but this only reduced the read time by 12%. Thank you for your help!
-
The database is on the local machine, not on the network. Your point about the connection makes sense though, it seems this Open RecordSet method re-opens the connection each time...
-
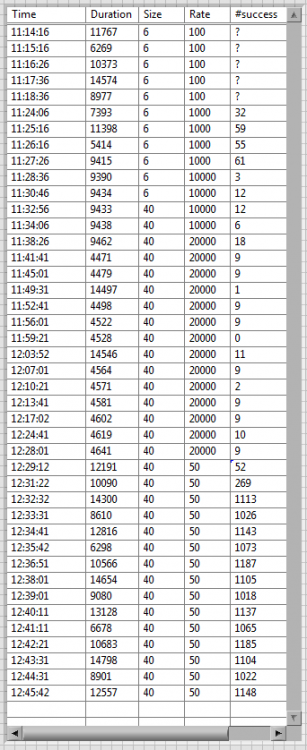
Thanks BBean. After discussion with one of our contractor, it seems this issue is likely to be completely unrelated to LabVIEW, so I guess this is not the right place for this thread. I still wanted to attach this file though. Just look at the 1st and 2nd columns. My test VI inserts a new row in the table each time the RecordSet.Open method takes more than 20ms. The 1st column shows the time at which the "freeze" happens and the 2nd column shows how long the Open method took, in milliseconds. There is definitely a pattern that emerge, either every 60 or every 70 milliseconds. This is very weird, I really wonder what might be happening. And it is not related to how many time I query the database, since the results are similar whatever the rate is (second last column). The database has only 500 records and I query either 6 or 40 of them each time (middle column). I wonder what Windows is up to...
-
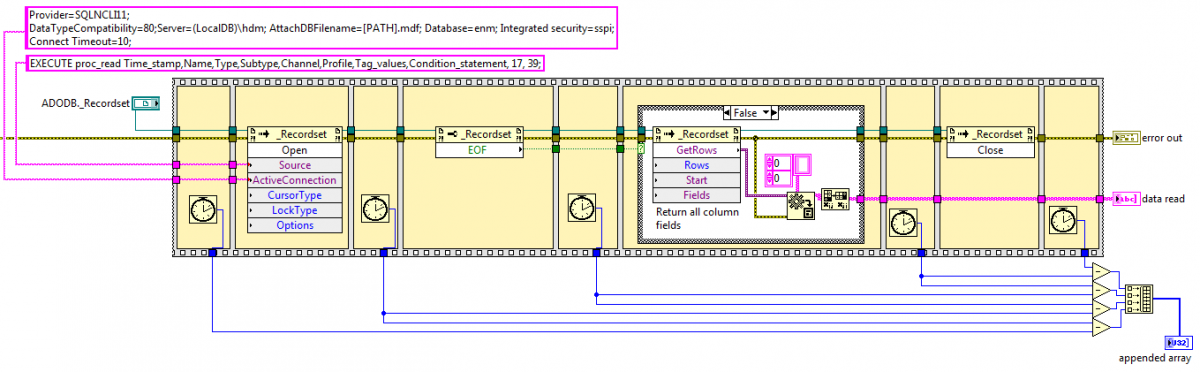
Dear LabVIEW enthusiasts, Our application uses .NET methods to access a SQL Server Express LocalDB database. It works, since we do manage to get the records we want. But on a regular basis, the Open method of the Recordset freezes for several seconds instead of executing within a few milliseconds like it usually does. I was able to determine that it was the Open method (and not the GetRows or the Close methods) by measuring the elapsed time as shown on the attached screenshot. Do you know if there is a known issue? I do have the Database Connectivity Toolkit but I have never used it, is there any chance this would fix my issue? Thank you
-
I agree that the effort doesn't seem to be proportionate to the gain...
-
I like it, but I find the current structure of LAVA really handy (maybe it's a matter of habit) and it might not be worth transitioning...
-
I ran into the same issue and couldn't figure out how to to this, even programmatically. If you managed to do this programmatically, can you guide me through the way to achieve it? Thanks
-
 Thank you. I have performed more tests and found that the problem would only happen with big files (at least 3MB). What happens is that my application loses the write permission only while Excel is loading the file, then it gets it back. So a bigger file means a longer loading time... I changed my code to keep trying for a maximum of 20s, then it gives up. This actually works remarkably well since I already had a queuing system, which means the "file writer" can catch up after having wasted time in this retrying loop. Does Windows somehow lock the file while it is being opened to guarantee the integrity of the data?
Thank you. I have performed more tests and found that the problem would only happen with big files (at least 3MB). What happens is that my application loses the write permission only while Excel is loading the file, then it gets it back. So a bigger file means a longer loading time... I changed my code to keep trying for a maximum of 20s, then it gives up. This actually works remarkably well since I already had a queuing system, which means the "file writer" can catch up after having wasted time in this retrying loop. Does Windows somehow lock the file while it is being opened to guarantee the integrity of the data? -
The thing is that my application is quite heavy (automation, data logging, hardware drivers, etc.) and I don't want to make it heavier by opening/closing the file every time I write into it (which is every 500ms).
-
Hi, I can't get my head around this issue. Let me lay out the scene: My application logs data in a .csv file. The file is created with R/W permissions through the "Open/Replace/Create File" VI. Then it uses the "Write to Binary File" to log the data, keeps the reference opened all along, and only close the file at the end. So far everything works perfectly. If I double click on the file in Windows Explorer, Excel sees that the file is being opened in LabVIEW and shows the typical message giving me the following choice: Read-only, Notify, or Cancel. If I cancel, Excel closes and things keep on going fine. However, if I do click "Read only", the "Write to Binary File" function in my LabVIEW application throws an error 8: File permission error. Somehow opening the file as read-only in Excel steals the write permission of LabVIEW. Have you ever experienced this? What could be happening? Emmanuel
-
I guess the answer is cost. Not only the hardware itself, but we are very tight when it comes to development time, as we are a small team and have a lot on our plate. We are using the standard NI-CAN Frame API. Our problem is not so much on the incoming side. The biggest issue is that if our application doesn't send a specific message at least every 50ms let's say, the customer's hardware enters a fault protection mode... And the data of this message keeps changing, so we can't just set a periodic message and let the low level CAN driver handle it. That really helps, thanks!
-
Our CANbus driver contains 3 timed loops: - #1 prepares and sends outgoing messages - #2 receives and parses incoming messages - #3 handles events and check the communication status Our driver's performance are not satisfying enough (we want it to run at a 10ms rate). It works ok most of the time (11ms, 9ms, 12ms, 10ms, 11ms, and so on) but the gap between loop iterations sometimes jump to 200ms before going back to an acceptable value. Quick tests showed that it is related to a user's request to change what HMI to display in a completely unrelated area of our application. This logically led me to one obsession: making sure our driver never relies on the UI thread. To achieve that, I set the execution thread to "other 1" and the priority to "time-critical". I know setting the thread to "other 1" is not a full guarantee, so I also tried to get rid of everything that would force the VI to go to the UI thread: I got rid of all the indicators and all the property and invoke nodes. The performances have already improved a lot, and the HMI activity in other part of our application no longer seem to influence the timed loop iterations. However I'd like to see what else I could optimize: - I still have a "stop" Boolean control. When it is set to True from another "manager" VI, the driver has to stop. All 3 timed loops poll this control to know whether to exit (one directly through the terminal, the other 2 through local variables). I know polling is not great, but my main worry is: because this is a control, does the VI still go to the UI thread whenever it is polled? Or only when its value change? I should also mention that I am not ever opening the front panel of the VI. - Loops #1 and #2 need to be able to notify #3 that a read or write operation failed, so that #3 can take care of resetting the device and restarting the communication. Right now, #1 and #2 simply write the error in a dedicated error cluster (so I actually still have 2 indicators left I guess) and #3 polls those errors through local variables. Does that mean that at each iteration the VI goes to the UI thread since I am writing to those error clusters at each loop iteration? Any comment on optimization in general is more than welcome! Emmanuel
-
LV Dialog box holds Open VI Reference
eberaud replied to eberaud's topic in Application Design & Architecture
A quick google search led me to this article: http://forums.ni.com/t5/LabVIEW-Idea-Exchange/Change-one-and-two-button-dialog-windows-do-they-do-not-block/idi-p/983941 You're right, the 1-button and 2-button dialog box uses the root loop, but the 3-button does not, so I could work around the issue by replacing my dialogs with the 3-button version. It works great now. Thank you for pointing me to this "root loop", I had never heard of it before, and wouldn't have found that article that easily without this keyword! Regards Emmanuel -
Hi, I am facing a weird situation and would like to get your insights. My application is quite large (>1000 VIs). When I run it, an initialization phase takes place, and around 10 or 20 objects are created (LVOOP). Most of these objects start their engine using the Open VI Reference and then the Run method. If they encounter any warning during that phase, they enqueue a message to display, and a dedicated VI keeps checking this queue and opens a LV Dialog (with just a OK button) when it finds an element. The purpose is to allow the initialization phase to continue instead of waiting for the user to acknowledge the window. Then when the init phase is complete, the user can just acknowledge all the dialogs one after another. (usually there is like 1 or 2, not much more). I ran my code this morning and was surprised to see that the init phase would still wait for me to acknowledge the dialog. A few probes showed me that the application was stuck in one of the Open VI Reference call. After I acknowledge the window, it would process normally. I am wondering what is causing this behavior and whether it is a known issue. Could it be related to the fact that the Dialog is modal and somehow holds the thread in which the Open VI Reference executes? This is weird, because other complex operations (connecting to a database,...) manage to execute while the dialog is open... Thank you very much for your help Emmanuel
-
Buffer maximum advised size - memory issue
eberaud replied to eberaud's topic in Application Design & Architecture
Thanks to all of you. Since execution time is not really an issue and since I don't have much time, I don't think I'm going to change my code. But I'll definitely use all your advices and remarks for my next project that is likely to be using LabVIEW. Bye all -
Buffer maximum advised size - memory issue
eberaud replied to eberaud's topic in Application Design & Architecture
Thank you for your quick answers ! Actually my job is only a display issue. The real data are continuously stored in a file by the acquisition software. If Windows XP crashes, then the data are not lost and a report can still be generated. So I'm not too concerned about that. What I need to know is the reasonable size I can give to my buffer. Let's make the calculation for 48 hours: - Rate = 10s means 6 records per minute, 360 per hour, 8640 for a day. So I need an array of DBL of 100 lines and 17280 columns for 48 hours. What I understand from what you told me is that it's far from the limit. - 100 x 17280 = 1728000 values of 8 bytes meaning = 13 MBytes for 48 hours. I guess it's also far from the limit. Now the graphs: I have 10 graphs with 10 channels maximum. This requires the same memory as the array: 13 MBytes for 48 hours. So finally my whole display system requires 26 MBytes in RAM. Do you reckon it's still reasonable ? We have to take into account that this will run simultaneously with the acquisition system which is a bit heavy. So far I'm not doing any initialization. I start with an empty array and I use the "insert into array" function. Should I rather initialize an array 100x17280 and use the "Replace" function ? In this case, what should the software do after 48 hours of running ? (I don't think this will really happen but we never know) Thanks again ! Manudelavega -
Hi, this message being my first one, please excuse me if it's not at the right location. I really tried to find an existing topic but couldn't find one. This is my question: My application is buffering (it's not a circular buffer) data in a 2D array of DBL values. This array is in a global variable so that other VIs (graphs...) can access it to display some of the buffered channels. My buffer rate is quite slow (1 record every 10 seconds) but I need to be able to display data over at least 24 hours, more if possible. Since the graphs themselves also use memory I guess, I need to define the maximum size of my array (meaning the maximum record time), as well as the history lenght of my graphs. This application is working beside another one made by another guy, handling the hardware acquisition and updating a shared memory. So I can't do any kind of hardware buffer. Could you advise me about - the maximum size in MegaBytes my array can take - the maximum number of elements arrays can accept in LabVIEW (if there is any maximum) Thanks a lot for your help